Tutorial: Executar um trabalho do Lote por meio do Data Factory com o Batch Explorer, o Gerenciador de Armazenamento e o Python
Este tutorial explica como criar e executar um pipeline do Azure Data Factory que executa uma carga de trabalho do Lote do Azure. Um script Python é executado nos nós do Lote para obter a entrada CSV (valor separado por vírgula) de um contêiner de Armazenamento de Blobs do Azure, manipular os dados e gravar a saída em um contêiner de armazenamento diferente. Você usa o Batch Explorer para criar um pool e nós do Lote e Gerenciador de Armazenamento do Microsoft Azure para trabalhar com contêineres e arquivos de armazenamento.
Neste tutorial, você aprenderá como:
- Usar o Batch Explorer para criar um pool e nós do Lote.
- Usar o Gerenciador de Armazenamento para criar contêineres de armazenamento e carregar arquivos de entrada.
- Desenvolver um script do Python para manipular dados de entrada e produzir a saída.
- Criar um pipeline do Data Factory que execute a carga de trabalho do Lote.
- Usar o Batch Explorer para examinar os arquivos de log de saída.
Pré-requisitos
- Uma conta do Azure com uma assinatura ativa. Se você não tiver uma, crie uma conta gratuita.
- Uma conta do Lote com uma conta de Armazenamento do Azure vinculada. Você pode criar as contas usando qualquer um dos seguintes métodos: portal do Azure | CLI do Azure | Bicep | modelo do ARM | Terraform.
- Uma instância do Data Factory. Para criar o data factory, siga as instruções em Criar um data factory.
- Batch Explorer baixado e instalado.
- Gerenciador de Armazenamento baixado e instalado.
-
Python 3.8 ou superior, com o pacote azure-storage-blob instalado usando
pip. - O conjunto de dados de entrada iris.csv baixado do GitHub.
Usar o Batch Explorer para criar um pool e nós do Lote
Usar o Batch Explorer para criar um pool de nós de computação para executar sua carga de trabalho.
Entre no Batch Explorer com as suas credenciais do Azure.
Selecione sua conta do Lote.
Selecione Pools na barra lateral esquerda e, em seguida, selecione o ícone + para adicionar um pool.
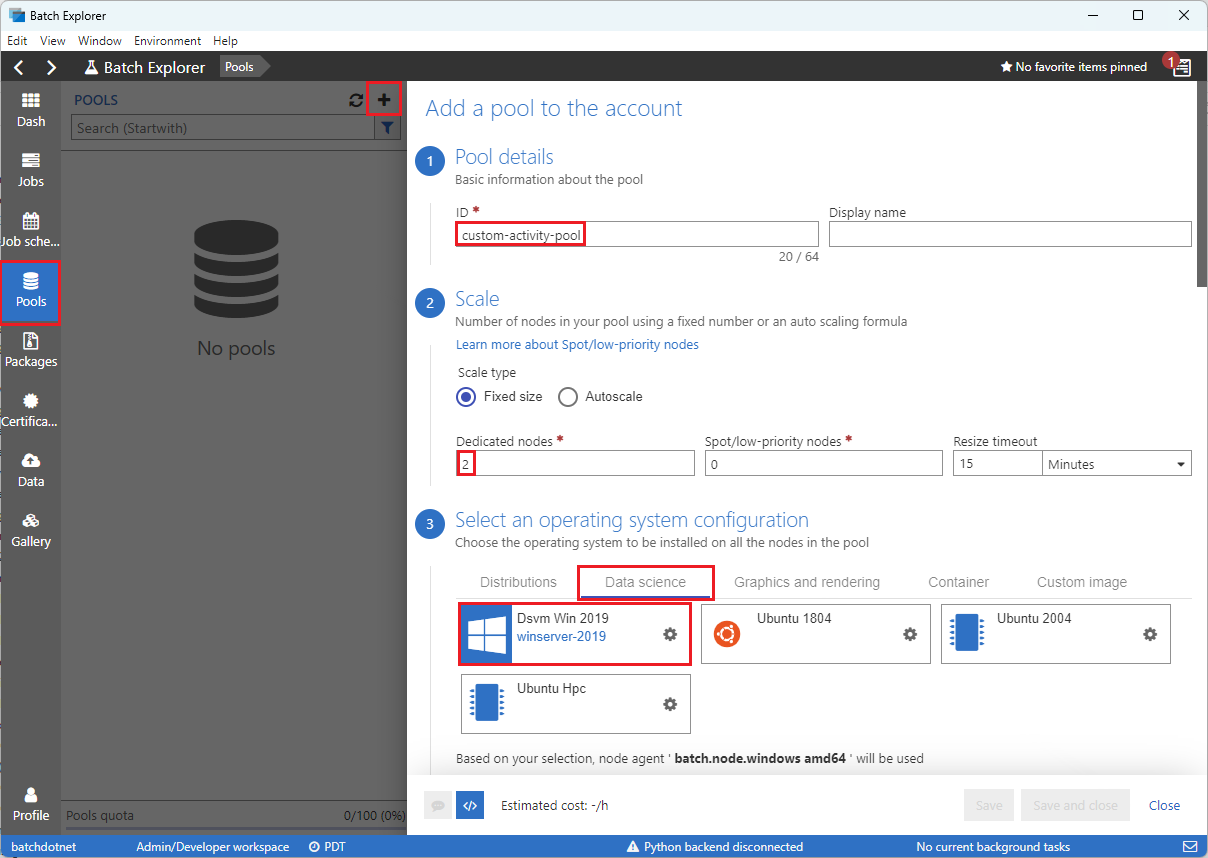
Preencha o formulário Adicionar um pool à conta da seguinte maneira:
- Em ID, insira custom-activity-pool.
- Em Nós dedicados, insira 2.
- Em Selecione uma configuração do sistema operacional, selecione a guia Ciência de dados e, em seguida, selecione Dsvm Win 2019.
- Em Escolher um tamanho de máquina virtual, selecione Standard_F2s_v2.
- Para Tarefa inicial, selecione Adicionar uma tarefa inicial.
Na tela de tarefa inicial, em Linha de comando, insira
cmd /c "pip install azure-storage-blob pandas"e selecione Selecionar. Esse comando instala o pacoteazure-storage-blobem cada nó conforme ele é iniciado.
Selecione Salvar e fechar.

Usar o Gerenciador de Armazenamento para criar contêineres de blobs
Usar o Gerenciador de Armazenamento para criar contêineres de blobs para armazenar arquivos de entrada e saída e carregar seus arquivos de entrada.
- Entre no Gerenciador de Armazenamento com as suas credenciais do Azure.
- Na barra lateral esquerda, localize e expanda a conta de armazenamento vinculada à sua conta do Lote.
- Clique com o botão direito do mouse em Contêineres de blobs e selecione Criar contêiner de blobs ou selecione Criar contêiner de blobs em Ações na parte inferior da barra lateral.
- Insira entrada no campo de entrada.
- Crie outro contêiner de blob chamado saída.
- Selecione o contêiner de entrada e, em seguida, selecione Carregar>Carregar arquivos no painel direito.
- Na tela Carregar arquivos, em Arquivos selecionados, selecione as reticências ... ao lado do campo de entrada.
- Navegue até o local do arquivo deiris.csv baixado, selecione Abrir e, em seguida, selecione Carregar.

Desenvolver um script do Python
O script do Python a seguir carrega o arquivo de conjunto de dados iris.csv do seu contêiner de entrada do Gerenciador de Armazenamento, manipula os dados e salva os resultados no contêiner de saída.
O script precisa usar a cadeia de conexão para a conta de Armazenamento do Microsoft Azure vinculada à sua conta do Lote. Para obter a cadeia de conexão:
- No portal do Azure, pesquise e selecione o nome da conta de armazenamento vinculada à sua conta do Lote.
- Na página da conta de armazenamento, selecione Chaves de acesso na navegação à esquerda em Segurança + rede.
- Em key1, selecione Mostrar ao lado de Cadeia de conexão e, em seguida, selecione o ícone Copiar para copiar a cadeia de conexão.
Cole a cadeia de conexão no script a seguir, substituindo o espaço reservado <storage-account-connection-string>. Salve o script como um arquivo chamado main.py.
Importante
A exposição de chaves de conta na origem do aplicativo não é recomendada para uso em produção. Você deve restringir o acesso às credenciais e consultá-las em seu código, usando variáveis ou um arquivo de configuração. É melhor armazenar chaves de conta do Lote e do Armazenamento no Azure Key Vault.
# Load libraries
# from azure.storage.blob import BlobClient
from azure.storage.blob import BlobServiceClient
import pandas as pd
import io
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Initialize the BlobServiceClient (This initializes a connection to the Azure Blob Storage, downloads the content of the 'iris.csv' file, and then loads it into a Pandas DataFrame for further processing.)
blob_service_client = BlobServiceClient.from_connection_string(conn_str=connectionString)
blob_client = blob_service_client.get_blob_client(container_name=containerName, blob_name=outputBlobName)
# Download the blob content
blob_data = blob_client.download_blob().readall()
# Load iris dataset from the task node
# df = pd.read_csv("iris.csv")
df = pd.read_csv(io.BytesIO(blob_data))
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Para obter mais informações sobre como trabalhar com o Armazenamento de Blobs do Azure, confira a documentação do Armazenamento de Blobs do Azure.
Execute o script localmente para testar e validar a funcionalidade.
python main.py
O script deve produzir um arquivo de saída chamado iris_setosa.csv que contém apenas os registros de dados que têm Species = setosa. Depois de verificar se ele funciona corretamente, carregue o arquivo de script main.py no contêiner de entrada do Gerenciador de Armazenamento.
Configurar um pipeline do Data Factory
Crie e valide um pipeline do Data Factory que usa o script do Python.
Obter Informações da conta
O pipeline do Data Factory usa os nomes da conta do Lote e do Armazenamento, os valores de chave de conta e o ponto de extremidade da conta do Lote. Para obter essas informações do portal do Azure:
Na barra do Azure Search, pesquise e selecione o nome da conta do Lote.
Na página da Conta do Lote, selecione Chaves na navegação à esquerda.
Na página Chaves, copie os seguintes valores:
- conta do Lote
- Ponto de extremidade da conta
- Chave de acesso primária
- Nome da conta de armazenamento
- Key1
Criar e executar o pipeline
Se o Azure Data Factory Studio ainda não estiver em execução, selecione Iniciar estúdio na página do Data Factory no portal do Azure.
No Data Factory Studio, selecione o ícone de lápis Autor na navegação à esquerda.
Em Recursos de fábrica, selecione o ícone + e, em seguida, selecione Pipeline.
No painel Propriedades à direita, altere o nome do pipeline para Executar Python.
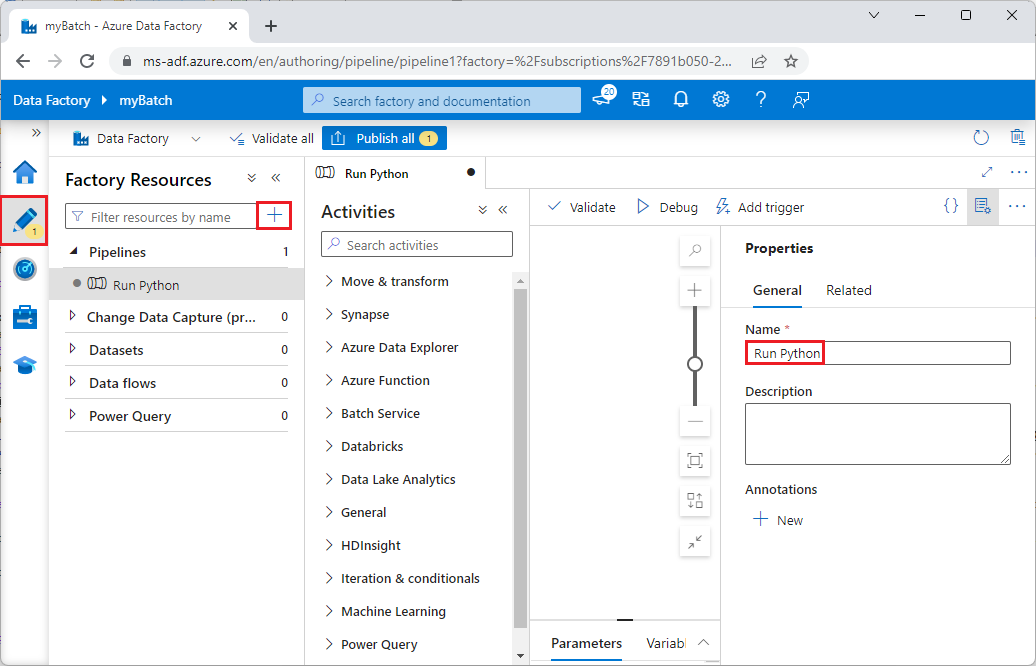
No painel Atividades, expanda Serviço de Lote e arraste a atividade Personalizado para a superfície do designer de pipeline.
Abaixo da tela do designer, na guia Geral, insira testPipeline em Nome.
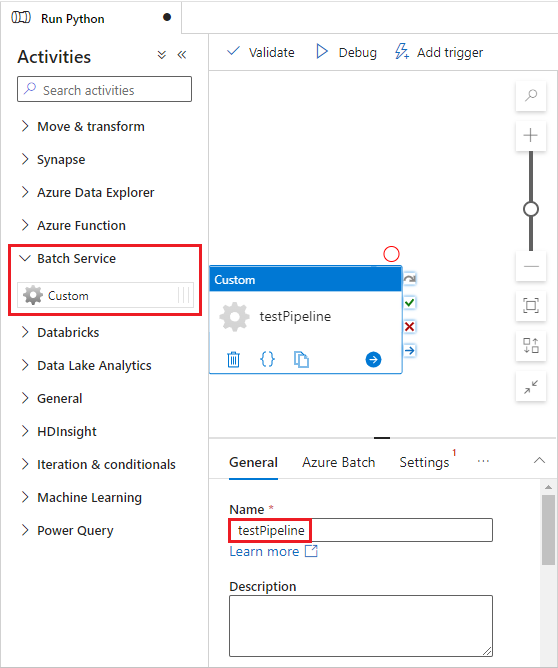
Selecione a guia Lote do Azure e escolha Novo.
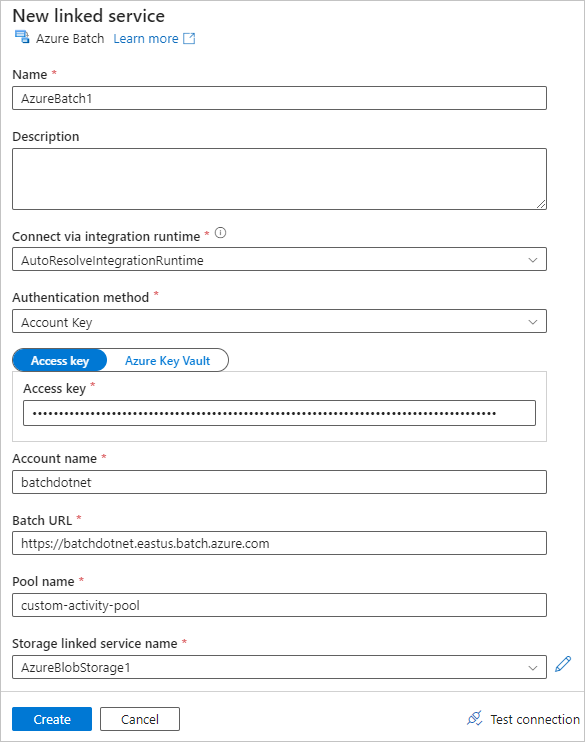
Preencha o formulário Novo serviço vinculado da seguinte maneira:
- Nome: insira um nome para o serviço vinculado, como AzureBatch1.
- Chave de acesso: insira a chave de acesso primária que você copiou da sua conta do Lote.
- Nome da conta: insira o nome da conta do Lote.
-
URL do Lote: insira o ponto de extremidade da conta copiado de sua conta do Lote, como
https://batchdotnet.eastus.batch.azure.com. - Nome do pool: insira custom-activity-pool, o pool que você criou no Batch Explorer.
- Nome do serviço vinculado da conta de armazenamento: selecione Novo. Na próxima tela, insira um Nome para o serviço de armazenamento vinculado, como AzureBlobStorage1, selecione sua assinatura do Azure e a conta de armazenamento vinculada e selecione Criar.
Na parte inferior da tela Novo serviço vinculado do Lote, selecione Testar conexão. Quando a conexão for bem-sucedida, selecione Criar.
Selecione a guia Configurações e insira ou selecione as seguintes configurações:
-
Comando: insira
cmd /C python main.py. - Serviço vinculado ao recurso: selecione o serviço de armazenamento vinculado que você criou, como AzureBlobStorage1, e teste a conexão para certificar-se de que seja bem-sucedida.
- Caminho da pasta: selecione o ícone de pasta e, em seguida, selecione o contêiner de entrada e selecione OK. Os arquivos dessa pasta são baixados do contêiner para os nós do pool antes da execução do script do Python.
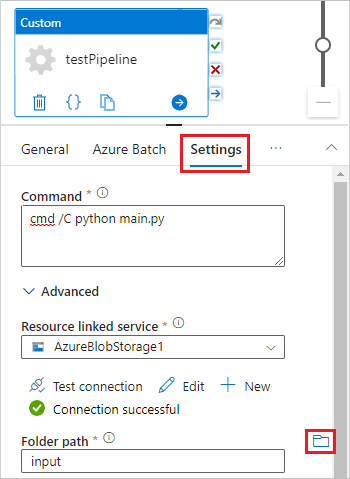
-
Comando: insira
Selecione Validar na barra de ferramentas do pipeline para validar o pipeline.
Selecione Depurar para testar o pipeline e garantir que ele funcione corretamente.
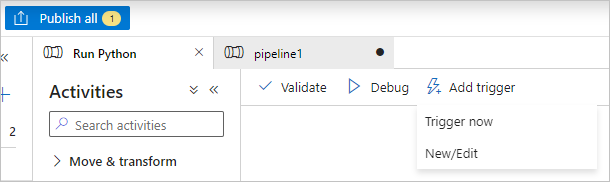
Selecione Publicar tudo para publicar o pipeline.
Selecione Adicionar gatilho e, em seguida, selecione Disparar agora para executar o pipeline ou Novo/Editar para agendá-lo.

Usar o Batch Explorer para exibir arquivos de log
Se a execução do pipeline produzir avisos ou erros, você poderá usar o Batch Explorer para examinar os arquivos de saída stdout.txt e stderr.txt para obter mais informações.
- No Batch Explorer, selecione Trabalhos na barra lateral esquerda.
- Selecione o trabalho adfv2-custom-activity-pool .
- Selecione uma tarefa que tinha um código de saída de falha.
- Exiba os arquivos stdout.txt e stderr.txt para investigar e diagnosticar seu problema.
Limpar recursos
Contas, trabalhos e tarefas do Lote são gratuitos, mas os nós de computação incorrem em encargos mesmo quando não estão executando trabalhos. É melhor alocar pools de nós somente conforme necessário e excluir os pools à medida que os finaliza. Excluir pools exclui todas as saídas de tarefa nos nós, bem como os nós em si.
Os arquivos de entrada e saída permanecem na conta de armazenamento e podem incorrer em encargos. Quando você não precisar mais dos arquivos, poderá excluir os arquivos ou contêineres. Quando você não precisar mais da sua conta do Lote ou da conta de armazenamento vinculada, poderá excluí-las.
Próximas etapas
Neste tutorial, você aprendeu a usar um script do Python com o Batch Explorer, o Gerenciador de Armazenamento e o Data Factory para executar uma carga de trabalho do Lote. Para saber mais sobre o Azure Data Factory, confira O que é o Azure Data Factory?