Entenda linguagens de volume no Azure NetApp Files
A linguagem de volume (semelhante a localidades do sistema em sistemas operacionais cliente) em um volume do Azure NetApp Files controla os idiomas e conjuntos de caracteres com suporte ao usar protocolos NFS e SMB. O Azure NetApp Files usa uma linguagem de volume padrão de C.UTF-8, que fornece codificação UTF-8 compatível com POSIX para conjuntos de caracteres. A linguagem C.UTF-8 dá suporte nativo a caracteres com um tamanho de 0 a 3 bytes, que inclui a maioria das linguagens do mundo no Plano Multilíngue Básico (BMP) (incluindo japonês, alemão e a maior parte do hebraico e cirílico). Para obter mais informações sobre o BMP, consulte Unicode.
Os caracteres fora do BMP às vezes excedem o tamanho de 3 bytes com suporte do Azure NetApp Files. Portanto, eles precisam usar lógica de par alternativo, em que conjuntos de bytes de vários caracteres são combinados para formar novos caracteres. Os símbolos de emoji, por exemplo, se enquadram nessa categoria e têm suporte no Azure NetApp Files em cenários em que o UTF-8 não é imposto: como clientes Windows que usam codificação UTF-16 ou NFSv3 que não impõe UTF-8. O NFSv4.x impõe UTF-8, o que significa que os caracteres de par alternativo não são exibidos corretamente ao usar NFSv4.x.
A codificação não padrão, como Shift-JIS e caracteres CJK menos comuns, também não são exibidos corretamente quando o UTF-8 é imposto no Azure NetApp Files.
Dica
Você deve enviar e receber texto usando UTF-8 para evitar situações em que os caracteres não podem ser traduzidos corretamente, o que pode causar a criação/renomeação de arquivo ou copiar cenários de erro.
No momento, as configurações de linguagem de volume não podem ser modificadas no Azure NetApp Files. Para obter mais informações, consulte Comportamentos de protocolo com conjuntos de caracteres especiais.
Para melhores práticas, consulte Melhores práticas do conjunto de caracteres.
Codificação de caracteres em volumes NFS e SMB do Azure NetApp Files
Em um ambiente de compartilhamento de arquivos do Azure NetApp Files, os nomes de arquivos e pastas são representados por uma série de caracteres que os usuários finais leem e interpretam. A maneira como esses caracteres são exibidos depende de como o cliente envia e recebe a codificação desses caracteres. Por exemplo, se um cliente estiver enviando codificação ASCII (American Standard Code for Information Interchange) herdada para o volume do Azure NetApp Files ao acessá-lo, ele estará limitado a exibir apenas caracteres compatíveis com o formato ASCII.
Por exemplo, o caractere japonês para dados é 資. Como esse caractere não pode ser representado no ASCII, um cliente que usa codificação ASCII mostra um “?” em vez de 資.
A ASCII dá suporte a apenas 95 caracteres imprimíveis, principalmente aqueles encontrados no idioma inglês. Cada um desses caracteres usa 1 byte, que é fatorado no tamanho total do caminho do arquivo em um volume do Azure NetApp Files. Isso limita a internacionalização de conjuntos de dados, uma vez que os nomes de arquivo podem ter uma variedade de caracteres não reconhecidos pela ASCII, do japonês ao cirílico e ao emoji. Um padrão internacional (ISO/IEC 8859) tentou dar suporte a mais caracteres internacionais, mas também tinha suas limitações. A maioria dos clientes modernos envia e recebe caracteres usando alguma forma de Unicode.
Unicode
Como resultado das limitações das codificações ASCII e ISO/IEC 8859, o padrão Unicode foi estabelecido para que qualquer pessoa possa exibir o idioma de sua região de origem em seus dispositivos.
- O Unicode oferece suporte a mais de um milhão de conjuntos de caracteres, aumentando o número de bytes por caractere permitido (até 4 bytes) e o número total de bytes permitidos em um caminho de arquivo, em comparação com codificações mais antigas, como ASCII.
- O Unicode dá suporte à compatibilidade com versões anteriores reservando os primeiros 128 caracteres para ASCII, garantindo também que os primeiros 256 pontos de código sejam idênticos aos padrões ISO/IEC 8859.
- No padrão Unicode, os conjuntos de caracteres são divididos em planos. Um plano é um grupo contínuo de 65.536 pontos de código. No total, há 17 planos (0-16) no padrão Unicode. O limite é 17 devido às limitações de UTF-16.
- O Plano 0 é o BMP (Plano Multilíngue Básico). Este plano contém os caracteres mais usados em vários idiomas.
- Dos 17 planos, apenas cinco têm atualmente conjuntos de caracteres atribuídos a partir do Unicode versão 15.1.
- Os planos 1 a 17 são conhecidos como Planos Multilíngues Suplementares (SMP) e contêm conjuntos de caracteres menos usados, por exemplo, sistemas de escrita antigos, como cuneiformes e hieróglifos, bem como caracteres especiais chinês/japonês/coreano (CJK).
- Para conhecer os métodos de visualização de comprimentos de caracteres e tamanhos de caminho e para controlar a codificação enviada a um sistema, consulte Conversão de arquivos em diferentes codificações.
O Unicode usa Formato de Transformação Unicode como padrão, com UTF-8 e UTF-16 sendo os dois formatos principais.
Planos Unicode
O Unicode aproveita 17 planos de 65.536 caracteres (256 pontos de código multiplicados por 256 caixas no plano), com o Plano 0 como Plano Multilíngue Básico (BMP). Este plano contém os caracteres mais usados em vários idiomas. Como os idiomas e os conjuntos de caracteres do mundo excedem 65536 caracteres, mais planos são necessários para dar suporte a conjuntos de caracteres menos usados.
Por exemplo, o Plano 1 (os Planos Multilíngues Suplementares (SMP)) inclui escritas históricas como cuneiforme e hieróglifos egípcios, bem como alguns Osage, Warang Citi, Adlam, Wancho e Toto. O Plano 1 também inclui alguns símbolos e caracteres emoticon.
O Plano 2 – o SIP (Plano Ideográfico Suplementar) – contém Ideogramas Unificados de Chinês/Japonês/Coreano (CJK). Os caracteres nos planos 1 e 2 geralmente têm 4 bytes de tamanho.
Por exemplo:
- O emoticon "rosto sorridente com olhos grandes" "😃" no plano 1 tem 4 bytes de tamanho.
- O hieróglifo egípcio "𓀀" no plano 1 tem 4 bytes de tamanho.
- O caractere Osage "𐒸" no plano 1 tem 4 bytes de tamanho.
- O caractere CJK "𫝁" no plano 2 tem 4 bytes de tamanho.
Como todos esses caracteres têm >3 bytes de tamanho, exigem que o uso de pares substitutos funcione corretamente. O Azure NetApp Files dá suporte nativo a pares alternativos, mas a exibição dos caracteres varia dependendo do protocolo em uso, das configurações de localidade do cliente e das configurações do aplicativo de acesso remoto ao cliente.
UTF-8
O UTF-8 usa codificação de 8 bits e pode ter até 1.112.064 pontos de código (ou caracteres). O UTF-8 é a codificação padrão em todos os idiomas em sistemas operacionais baseados em Linux. Como o UTF-8 usa codificação de 8 bits, o número inteiro sem sinal máximo possível é 255 (2^8 - 1), que também é o comprimento máximo do nome de arquivo para essa codificação. O UTF-8 é usado em mais de 98% das páginas na Internet, tornando-o de longe o padrão de codificação mais adotado. O Grupo de Trabalho de Tecnologia de Aplicativos de Hipertexto da Web (WHATWG) considera UTF-8 "a codificação obrigatória para todo o [texto]" e que, por motivos de segurança, os aplicativos do navegador não devem usar UTF-16.
Os caracteres no formato UTF-8 usam, cada um, de 1 a 4 bytes, mas quase todos os caracteres em todos os idiomas usam entre 1 e 3 bytes. Por exemplo:
- A letra "A" do alfabeto latino usa 1 byte. (Um dos 128 caracteres ASCII reservados)
- Um símbolo de direitos autorais "©" usa 2 bytes.
- O caractere "ä" usa 2 bytes. (1 byte para "a" + 1 byte para o trema)
- O símbolo Kanji japonês para dados (資) usa 3 bytes.
- Um emoji de rosto sorridente (😃) usa 4 bytes.
As localidades de idioma podem usar o padrão de computador UTF-8 (C.UTF-8) ou um formato específico da região, como en_US. UTF-8, ja.UTF-8, etc. Você deve usar a codificação UTF-8 para clientes Linux ao acessar o Azure NetApp Files sempre que possível. A partir do OS X, os clientes do macOS também usam UTF-8 como codificação padrão e não devem ser ajustados.
Clientes Windows usam UTF-16. Na maioria dos casos, essa configuração deve ser deixada como o padrão para a localidade do sistema operacional, mas os clientes mais recentes oferecem suporte beta para caracteres UTF-8 por meio de uma caixa de seleção. Os clientes de terminal no Windows também podem ser ajustados para usar o UTF-8 no PowerShell ou no CMD, conforme necessário. Para obter mais informações, consulte Comportamentos de protocolo duplo com conjuntos de caracteres especiais.
UTF-16
O UTF-16 usa codificação de 16 bits e é capaz de codificar todos os 1.112.064 pontos de código do Unicode. A codificação para UTF-16 pode usar uma ou duas unidades de código de 16 bits, cada uma com 2 bytes de tamanho. Todos os caracteres em UTF-16 usam tamanhos de 2 ou 4 bytes. Os caracteres em UTF-16 que usam 4 bytes aproveitam pares alternativos, que combinam dois caracteres separados de 2 bytes para criar um novo caractere. Esses caracteres suplementares ficam fora do plano BMP padrão e em um dos outros planos multilíngues.
O UTF-16 é usado em sistemas operacionais Windows e APIs, Java e JavaScript. Como não oferece suporte à compatibilidade com versões anteriores dos formatos ASCII, nunca se popularizou na Web. O UTF-16 só compõe cerca de 0,002% de todas as páginas na Internet. O Grupo de Trabalho de Tecnologia de Aplicativos de Hipertexto da Web (WHATWG) considera UTF-8 "a codificação obrigatória para todo o texto" e recomenda que os aplicativos não usem UTF-16 para segurança do navegador.
O Azure NetApp Files dá suporte à maioria dos caracteres UTF-16, incluindo pares alternativos. Nos casos em que o caractere não tem suporte, os clientes do Windows relatam que um erro de "nome de arquivo especificado não é válido ou muito longo".
Manipulação de conjunto de caracteres em clientes remotos
Conexões remotas com clientes que montam volumes do Azure NetApp Files (como conexões SSH com clientes Linux para acessar montagens NFS) podem ser configuradas para enviar e receber codificações de idioma de volume específicas. A codificação de idioma enviada ao cliente por meio do utilitário de conexão remota controla como os conjuntos de caracteres são criados e exibidos. Como resultado, uma conexão remota que usa uma codificação de idioma diferente de outra conexão remota (como duas janelas PuTTY diferentes) poderá mostrar resultados diferentes para caracteres ao listar nomes de arquivo e pasta no volume do Azure NetApp Files. Na maioria dos casos, isso não criará discrepâncias (como para caracteres latinos/ingleses), mas nos casos de caracteres especiais, como emojis, os resultados podem variar.
Por exemplo, o uso de uma codificação de UTF-8 para a conexão remota mostra resultados previsíveis para caracteres em volumes do Azure NetApp Files, já que C.UTF-8 é a linguagem de volume. O caractere japonês para "dados" (資) é exibido de forma diferente dependendo da codificação que está sendo enviada pelo terminal.
Codificação de caracteres no PuTTY
Quando uma janela PuTTY usa UTF-8 (encontrado nas configurações de tradução do Windows), o caractere é representado corretamente para um volume montado NFSv3 no Azure NetApp Files:

Se a janela PuTTY usar uma codificação diferente, como ISO-8859-1:1998 (Latin-1, Europa Ocidental), o mesmo caractere será exibido de forma diferente, mesmo que o nome do arquivo seja o mesmo.

O PuTTY, por padrão, não contém codificações CJK. Há patches disponíveis para adicionar esses conjuntos de idiomas ao PuTTY.
Codificações de caracteres no Bastion
O Microsoft Azure recomenda usar o Bastion para conectividade remota com VMs (máquinas virtuais) no Azure. Ao usar o Bastion, a codificação de idioma enviada e recebida não é exposta na configuração, mas aproveita a codificação UTF-8 padrão. Como resultado, a maioria dos conjuntos de caracteres vistos no PuTTY usando UTF-8 também deverá estar visível no Bastion, desde que haja suporte para os conjuntos de caracteres no protocolo que está sendo usado.

Dica
Outros terminais SSH podem ser usados, como TeraTerm. O TeraTerm fornece um intervalo maior de conjuntos de caracteres com suporte por padrão, incluindo codificações CJK e codificações não padrão, como Shift-JIS.
Comportamentos de protocolo com conjuntos de caracteres especiais
Os volumes do Azure NetApp Files usam codificação UTF-8 e dão suporte nativo a caracteres que não excedem 3 bytes. Todos os caracteres no conjunto ASCII e UTF-8 são exibidos corretamente porque estão no intervalo de 1 a 3 bytes. Por exemplo:
- O caractere de alfabeto latino "A" usa 1 byte (um dos 128 caracteres ASCII reservados).
- Um símbolo de direitos autorais © usa 2 bytes.
- O caractere "ä" usa 2 bytes (1 byte para "a" e 1 byte para o trema).
- O símbolo Kanji japonês para dados (資) usa 3 bytes.
O Azure NetApp Files também dá suporte a alguns caracteres que excedem 3 bytes por meio da lógica de par alternativo (como emoji), desde que a codificação do cliente e a versão do protocolo sejam compatíveis com eles. Para obter mais informações sobre comportamentos de protocolo, consulte:
Comportamentos SMB
Em volumes SMB, o Azure NetApp Files cria e mantém dois nomes para arquivos ou diretórios em qualquer diretório que tenha acesso de um cliente SMB: o nome longo original e um nome no formato 8.3.
Nomes de arquivo em SMB com o Azure NetApp Files
Quando os nomes de arquivo ou diretório excedem os bytes de caractere permitidos ou usam caracteres sem suporte, o Azure NetApp Files gera um nome de formato 8.3 da seguinte maneira:
- Trunca o nome original do arquivo ou diretório.
- Acrescenta um til (~) e um numeral (1-5) a nomes de arquivo ou diretório que não são mais exclusivos após serem truncados. Se houver mais de cinco arquivos com nomes não exclusivos, o Azure NetApp Files criará um nome exclusivo sem relação com o nome original. Para arquivos, o Azure NetApp Files trunca a extensão de nome de arquivo para três caracteres.
Por exemplo, se um cliente NFS criar um arquivo chamado specifications.html, o Azure NetApp Files criará o nome do arquivo specif~1.htm seguindo o formato 8.3. Se esse nome já existir, o Azure NetApp Files usará um número diferente no final do nome do arquivo. Por exemplo, se um cliente NFS criar outro arquivo chamado specifications\_new.html, o formato 8.3 de specifications\_new.html será specif~2.htm.
Caractere especial no SMB com o Azure NetApp Files
Ao usar o SMB com volumes do Azure NetApp Files, os caracteres que excedem 3 bytes usados em nomes de arquivo e pasta (incluindo emoticons) são permitidos devido ao suporte de par alternativo. Veja a seguir o que o Windows Explorer vê para caracteres fora do BMP em uma pasta criada a partir de um cliente Windows ao usar inglês com a codificação UTF-16 padrão.
Observação
A fonte padrão no Windows Explorer é a Segoe UI. As alterações de fonte podem afetar a forma como alguns caracteres são exibidos nos clientes.

Como os caracteres exibidos no cliente dependem da fonte do sistema e das configurações de idioma e localidade. Em geral, os caracteres que se enquadram no BMP têm suporte em todos os protocolos, independentemente se a codificação for UTF-8 ou UTF-16.
Ao usar o CMD ou PowerShell, a exibição do conjunto de caracteres pode depender das configurações de fonte. Esses utilitários têm opções de fonte limitadas por padrão. O CMD usa Consolas como a fonte padrão.
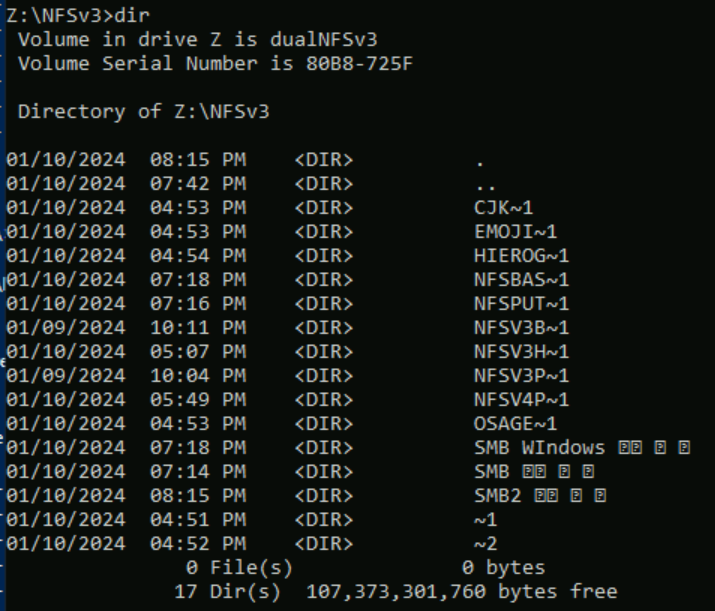
Os nomes de arquivo podem não ser exibidos conforme o esperado, dependendo da fonte usada, pois alguns consoles não dão suporte nativo à Segoe UI ou a outras fontes que renderizam caracteres especiais corretamente.
Esse problema pode ser resolvido em clientes no Windows usando o ISE do PowerShell, que oferece suporte mais robusto a fontes. Por exemplo, a configuração do ISE do PowerShell para a Segoe UI exibe os nomes de arquivo com caracteres compatíveis corretamente.

No entanto, o ISE do PowerShell foi projetado para scripts, em vez de gerenciar compartilhamentos. Versões mais recentes do Windows oferecem oWindows Terminal, que permite o controle sobre as fontes e os valores de codificação.
Observação
Use o comando chcp para exibir a codificação do terminal. Para obter uma lista completa de páginas de código, consulte Identificadores de página de código.

Se o volume estiver habilitado para protocolo duplo (NFS e SMB), você poderá observar comportamentos diferentes. Para obter mais informações, consulte Comportamentos de protocolo duplo com conjuntos de caracteres especiais.
Comportamentos NFS
Como o NFS exibe caracteres especiais depende da versão do NFS usada, das configurações de localidade do cliente, das fontes instaladas e das configurações em uso do cliente de conexão remota. Por exemplo, o uso do Bastion para acessar um cliente Ubuntu lida com a exibição de caracteres de maneira diferente de um cliente PuTTY configurado para uma localidade diferente na mesma VM. Os exemplos de NFS subsequentes dependem dessas configurações de localidade para a VM do Ubuntu:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
Comportamento NFSv3
O NFSv3 não impõe a codificação UTF em arquivos e pastas. Na maioria dos casos, conjuntos de caracteres especiais não devem ter problemas. No entanto, o cliente de conexão usado pode afetar como os caracteres são enviados e recebidos. Por exemplo, o uso de caracteres Unicode fora do BMP para um nome de pasta no cliente de conexão do Azure, o Bastion, pode resultar em um comportamento inesperado devido à forma como a codificação do cliente funciona.
Na captura de tela a seguir, o Bastion não consegue copiar e colar os valores no prompt da CLI de fora do navegador ao nomear um diretório no NFSv3. Ao tentar copiar e colar o valor de NFSv3Bastion𓀀𫝁😃𐒸, os caracteres especiais são exibidos como aspas na entrada.

O comando copiar-colar é permitido no NFSv3, mas os caracteres são criados como seus valores numéricos, afetando a exibição:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
Essa exibição ocorre devido à codificação usada pelo Bastion para enviar valores de texto ao copiar e colar.
Ao usar o PuTTY para criar uma pasta com os mesmos caracteres no NFSv3, o nome da pasta é diferente no Bastion do que quando o Bastion foi usado para criá-la. O emoticon é mostrado conforme o esperado (devido às fontes instaladas e à configuração de localidade), mas os outros caracteres (como o Osage "𐒸") não.

Em uma janela PuTTY, os caracteres são exibidos corretamente:

Comportamento NFSv4.x
O NFSv4.x impõe a codificação UTF-8 em nomes de arquivo e pasta de acordo com as especificações de internacionalização RFC-8881.
Como resultado, se um caractere especial for enviado com codificação não UTF-8, o NFSv4.x poderá não permitir o valor.
Em alguns casos, um comando pode ser permitido usando um caractere fora do BMP (Plano Multilíngue Básico), mas pode não exibir o valor depois de criado.
Por exemplo, a emissão de mkdir com um nome de pasta, incluindo os caracteres "𓀀𫝁😃𐒸" (caracteres nos Planos Multilíngues Suplementares (SMP) e o Plano Ideográfico Suplementar (SIP)) parece ser bem-sucedido no NFSv4.x. A pasta não ficará visível ao executar o comando ls.
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
A pasta existe no volume. A alteração para esse nome de diretório oculto funciona do cliente PuTTY e um arquivo pode ser criado dentro desse diretório.
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
Um comando de estatística do PuTTY também confirma se a pasta existe:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
Embora a pasta seja confirmada como existente, os comandos curinga não funcionam, pois o cliente não pode "ver" oficialmente a pasta na exibição.
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
O NFSv4.1 envia um erro ao cliente quando ele encontra um caractere que não depende da codificação UTF-8.
Por exemplo, ao usar o Bastion para tentar acessar o mesmo diretório que criamos usando o PuTTY no NFSv4.1, este é o resultado:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
NFS4ERR_INVAL é abordado em RFC-8881.
Como a pasta pode ser acessada do PuTTY (devido à codificação que está sendo enviada e recebida), ela pode ser copiada se o nome for especificado. Depois de copiar essa pasta do volume do NFSv4.1 do Azure NetApp Files para o volume do NFSv3 do Azure NetApp Files, o nome da pasta será exibido:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
O mesmo erro NFS4ERR\_INVAL pode ser visto se uma conversão de arquivo (usando `iconv``) para um formato não UTF-8 for tentada, como Shift-JIS.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Para obter mais informações, consulte Conversão de arquivos em codificações diferentes.
Comportamentos de protocolo duplo
O Azure NetApp Files permite que os volumes sejam acessados pelo NFS e pelo SMB por meio do acesso de protocolo duplo. Devido às grandes diferenças na codificação de idioma usada pelo NFS (UTF-8) e SMB (UTF-16), conjuntos de caracteres, nomes de arquivo e pasta e comprimentos de caminho podem ter comportamentos muito diferentes entre protocolos.
Exibição de arquivos e pastas criados pelo NFS do SMB
Quando o Azure NetApp Files é usado para acesso de protocolo duplo (SMB e NFS), um conjunto de caracteres sem suporte por UTF-16 pode ser usado em um nome de arquivo criado usando UTF-8 via NFS. Nesses cenários, quando o SMB acessa um arquivo com caracteres sem suporte, o nome é truncado no SMB usando a convenção de nome de arquivo curto 8.3.
Arquivos criados por NFSv3 e comportamentos SMB com conjuntos de caracteres
O NFSv3 não impõe a codificação UTF-8. Os caracteres que usam codificações de idioma não padrão (como Shift-JIS) funcionam com o Azure NetApp Files ao usar o NFSv3.
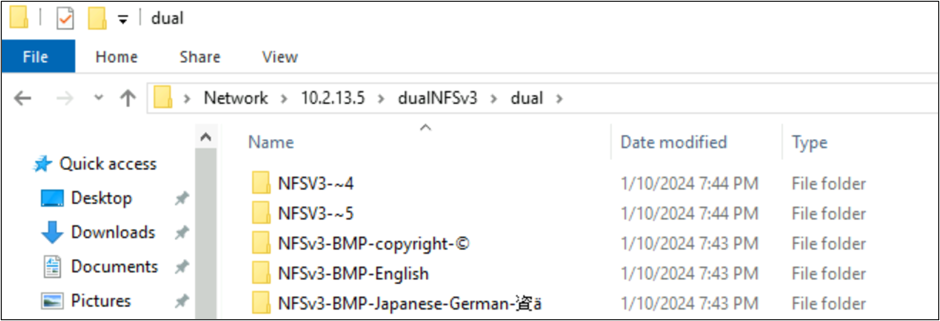
No exemplo a seguir, uma série de nomes de pastas usando conjuntos de caracteres diferentes de vários planos no Unicode foram criados em um volume do Azure NetApp Files usando NFSv3. Quando exibidos do NFSv3, eles aparecem corretamente.
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
No SMB do Windows, as pastas com caracteres encontrados no BMP são exibidas corretamente, mas os caracteres fora desse plano são exibidos com o formato de nome 8.3, devido à conversão UTF-8/UTF-16 ser incompatível com esses caracteres.
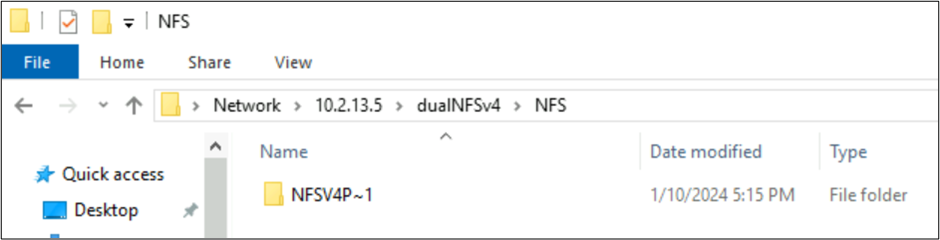
Arquivos criados por NFSv4.1 e comportamentos SMB com conjuntos de caracteres
Nos exemplos anteriores, uma pasta chamada NFSv4 Putty 𓀀𫝁😃𐒸 foi criada em um volume do Azure NetApp Files no NFSv4.1, mas não era exibida usando NFSv4.1. No entanto, ela pode ser vista usando SMB. O nome é truncado no SMB para um formato 8.3 com suporte devido aos conjuntos de caracteres sem suporte criados do cliente NFS e à conversão UTF-8/UTF-16 incompatível para caracteres em diferentes planos Unicode.
Quando um nome de pasta usa caracteres UTF-8 padrão encontrados no BMP (inglês ou não), o SMB converte os nomes corretamente.
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
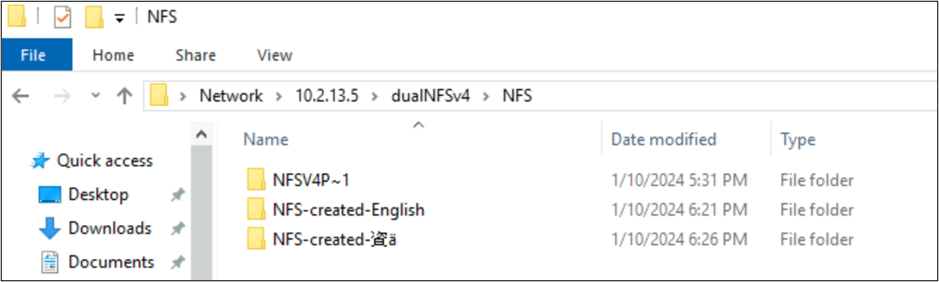
Arquivos e pastas criados por SMB no NFS
Os clientes Windows são o principal tipo de cliente usado para acessar compartilhamentos SMB. Esses clientes são padrão para codificação UTF-16. É possível dar suporte a alguns caracteres codificados em UTF-8 no Windows, habilitando-o nas configurações de região:
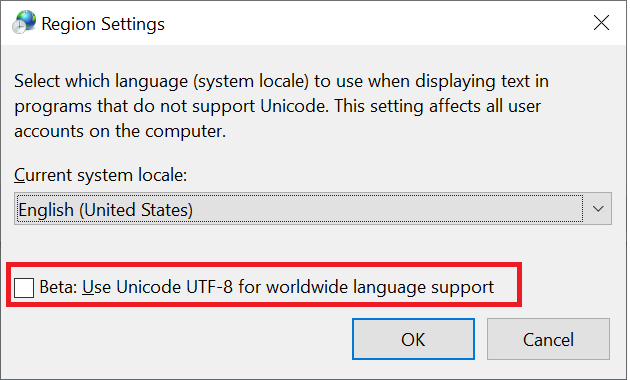
Quando um arquivo ou pasta é criado em um compartilhamento SMB no Azure NetApp Files, o conjunto de caracteres em uso é codificado como UTF-16. Como resultado, os clientes que usam a codificação UTF-8 (como clientes NFS baseados em Linux) podem não conseguir converter alguns conjuntos de caracteres corretamente – particularmente caracteres que estão fora do Plano Multilíngue Básico (BMP).
Comportamento de caractere sem suporte
Nesses cenários, quando um cliente NFS acessa um arquivo criado usando SMB com caracteres sem suporte, o nome é exibido como uma série de valores numéricos que representam os valores Unicode para o caractere.
Por exemplo, essa pasta foi criada no Windows Explorer usando caracteres fora do BMP.
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
No NFSv3, a pasta criada por SMB aparece:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
No NFSv4.1, a pasta criada por SMB aparece da seguinte maneira:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
Comportamento de caractere com suporte
Quando os caracteres estão no BMP, não há problemas entre os protocolos SMB e NFS e suas versões.
Por exemplo, um nome de pasta criado usando SMB em um volume do Azure NetApp Files com caracteres encontrados no BMP em vários idiomas (inglês, alemão, cirílico, rúnico) aparece bem em todos os protocolos e versões.
- Latim Básico "SMB"
- Grego "ͶΘΩ"
- Cirílico "ЁЄЊ"
- Rúnico "ᚠᚱᛯ"
- Ideogramas de Compatibilidade CJK "豈滑虜"
É assim que o nome aparece no SMB:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
É assim que o nome aparece do NFSv3:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
É assim que o nome aparece do NFSv4.1:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Conversão de arquivos para codificações diferentes
Nomes de arquivo e pasta não são as únicas partes de objetos do sistema de arquivos que utilizam codificações de idioma. O conteúdo do arquivo (como caracteres especiais em um arquivo de texto) também pode desempenhar um papel importante. Por exemplo, se houver tentativa de salvar um arquivo com caracteres especiais em um formato incompatível, uma mensagem de erro poderá ser exibida. Nesse caso, um arquivo com caracteres Katagana não pode ser salvo no ANSI, pois esses caracteres não existem nessa codificação.
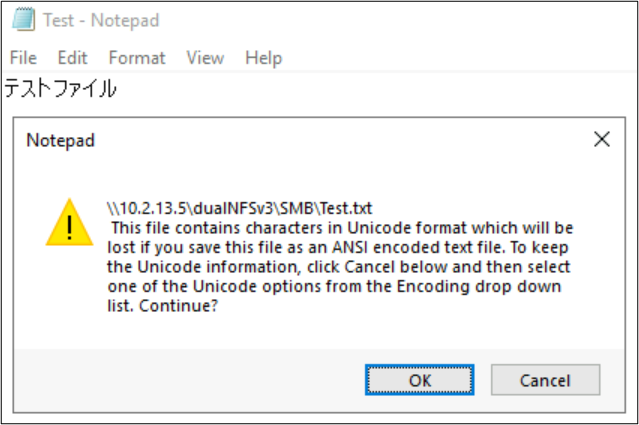
Quando o arquivo é salvo nesse formato, os caracteres são convertidos em pontos de interrogação:
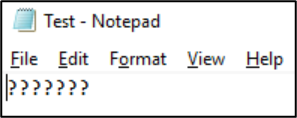
As codificações de arquivo podem ser exibidas de clientes NAS. Em clientes Windows, você pode usar um aplicativo como o Bloco de Notas ou o Bloco de Notas++ para exibir uma codificação de um arquivo. Se o Subsistema do Windows para Linux (WSL) ou o Git estiverem instalados no cliente, o comando file poderá ser usado.
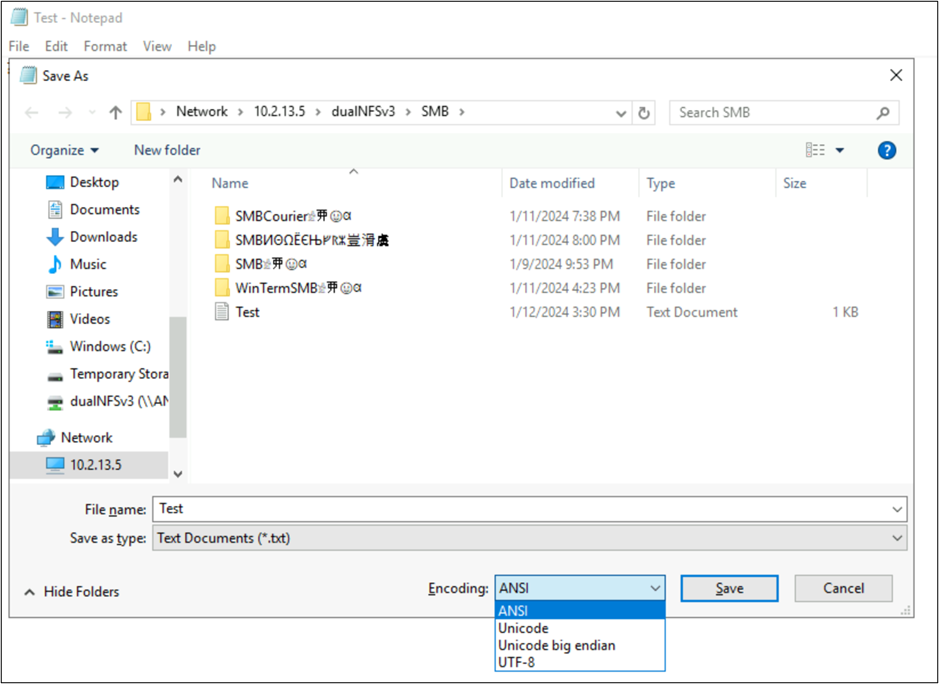
Esses aplicativos também permitem que você altere a codificação do arquivo salvando como tipos de codificação diferentes. Além disso, o PowerShell pode ser usado para converter a codificação em arquivos com os cmdlets Get-Content e Set-Content.
Por exemplo, o arquivo utf8-text.txt é codificado como UTF-8 e contém caracteres fora do BMP. Como o UTF-8 é usado, os caracteres são exibidos corretamente.
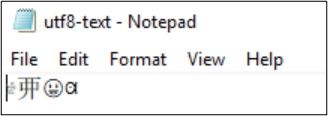
Se a codificação for convertida para UTF-32, os caracteres não serão exibidos corretamente.
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
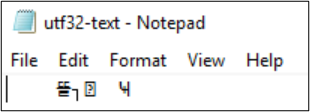
Get-Content também pode ser usado para exibir o conteúdo do arquivo. Por padrão, o PowerShell usa a codificação UTF-16 (Página de código 437) e as seleções de fonte para o console são limitadas, portanto, o arquivo formatado UTF-8 com caracteres especiais não pode ser exibido corretamente:
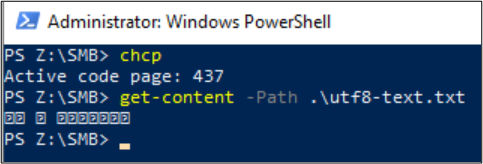
Os clientes Linux podem usar o comando file para exibir a codificação do arquivo. Em ambientes de protocolo duplo, se um arquivo for criado usando SMB, o cliente Linux usando NFS poderá verificar a codificação do arquivo.
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
A conversão de codificação de arquivo pode ser executada em clientes Linux usando o comando iconv. Para ver a lista de formatos de codificação com suporte, use iconv -l.
Por exemplo, o arquivo codificado em UTF-8 pode ser convertido em UTF-16.
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
Se o conjunto de caracteres no nome do arquivo ou no conteúdo do arquivo não tiver suporte na codificação de destino, a conversão não será permitida. Por exemplo, Shift-JIS não pode dar suporte aos caracteres no conteúdo do arquivo.
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
Se um arquivo tiver caracteres compatíveis com a codificação, a conversão será bem-sucedida. Por exemplo, se o arquivo contiver os caracteres Katagana テストファイル, a conversão Shift-JIS será bem-sucedida em NFS. Como o cliente NFS que está sendo usado aqui não entende Shift-JIS devido às configurações de localidade, a codificação mostra "unknown-8bit" (desconhecido-8 bits).
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
Como os volumes do Azure NetApp Files dão suporte apenas à formatação compatível com UTF-8, os caracteres Katagana são convertidos para um formato ilegível.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Ao usar NFSv4.x, a conversão é permitida quando caracteres não compatíveis estão presentes dentro do conteúdo do arquivo, embora o NFSv4.x imponha a codificação UTF-8. Neste exemplo, um arquivo codificado em UTF-8 com caracteres Katagana localizados em um volume do Azure NetApp Files mostra o conteúdo de um arquivo corretamente.
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
Porém, depois de convertido, os caracteres no arquivo são exibidos incorretamente devido à codificação incompatível.
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
Se o nome do arquivo contiver caracteres sem suporte para UTF-8, a conversão será bem-sucedida no NFSv3, mas falhará no NFSv4.x devido à imposição de UTF-8 da versão do protocolo.
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
Melhores práticas do conjunto de caracteres
Ao usar caracteres especiais ou caracteres fora do padrão BMP (Plano Multilíngue Básico) em volumes do Azure NetApp Files, algumas melhores práticas devem ser levadas em consideração.
- Como os volumes do Azure NetApp Files usam a linguagem de volume UTF-8, a codificação de arquivo para clientes NFS também deve usar a codificação UTF-8 para resultados consistentes.
- Conjuntos de caracteres em nomes de arquivo ou contidos no conteúdo do arquivo devem ser compatíveis com UTF-8 para exibição e funcionalidade adequadas.
- Como o SMB usa a codificação de caracteres UTF-16, os caracteres fora do BMP podem não ser exibidos corretamente no NFS em volumes de protocolo duplo. Na medida do possível, minimize o uso de caracteres especiais no conteúdo dos arquivos.
- Evite usar caracteres especiais fora do BMP em nomes de arquivo, especialmente ao usar volumes de protocolo duplo ou NFSv4.1.
- Para conjuntos de caracteres que não estão no BMP, a codificação UTF-8 deve permitir a exibição dos caracteres no Azure NetApp Files ao usar um único protocolo de arquivo (somente SMB ou somente NFS). No entanto, na maioria dos casos os volumes de protocolo duplo não são capazes de acomodar esses conjuntos de caracteres.
- Não há suporte para codificação não padrão (como Shift-JIS) em volumes do Azure NetApp Files.
- Caracteres de par alternativo (como emoji) têm suporte em volumes do Azure NetApp Files.