Recuperação de desastre e distribuição geográfica nas Azure Durable Functions
A Microsoft se empenha em garantir que os serviços do Azure estejam sempre disponíveis. No entanto, podem ocorrer interrupções imprevistas do serviço. Se o aplicativo exigir resiliência, a Microsoft recomenda configurar o aplicativo para redundância geográfica. Além disso, os clientes devem dispor de um plano de recuperação de desastre para lidar com uma interrupção regional do serviço. Uma parte importante de um plano de recuperação de desastre é a preparação de um failover para a réplica secundária do aplicativo e do armazenamento, caso a réplica primária fique indisponível.
Nas Durable Functions, todos os estados são persistentes no Armazenamento do Azure por padrão. Um hub de tarefas é um contêiner lógico dos recursos do Armazenamento do Azure usado para orquestrações e entidades. As funções de orquestrador, atividade e entidade só podem interagir entre si quando pertencem ao mesmo hub de tarefas. Este documento se referirá aos hubs de tarefas quando descrever cenários para manter esses recursos de Armazenamento do Azure altamente disponíveis.
Observação
As diretrizes neste artigo pressupõe que você está usando o provedor padrão do Armazenamento do Azure para armazenar o estado de runtime do Durable Functions. No entanto, é possível configurar provedores de armazenamento alternativos que armazenam o estado em outro lugar, como um banco de dados do SQL Server. Diferentes estratégias de recuperação de desastre e distribuição geográfica podem ser necessárias para os provedores de armazenamento alternativos. Para obter mais informações sobre os provedores de armazenamento alternativos, confira a documentação dos provedores de armazenamento do Durable Functions.
As orquestrações e entidades podem ser disparadas usando funções de cliente disparadas por meio de HTTP ou um dos outros tipos de gatilho com suporte do Azure Functions. Elas também podem ser disparadas usando APIs HTTP internas. Para simplificar, este artigo se concentrará em cenários que envolvem gatilhos de função baseados em HTTP e Armazenamento do Azure e opções para aumentar a disponibilidade e minimizar o tempo de inatividade durante as atividades de recuperação de desastre. Outros tipos de gatilho, como gatilhos do Barramento de Serviço ou do Azure Cosmos DB, não serão abordados explicitamente.
Os cenários a seguir são baseados nas configurações de ativo-passivo, pois são guiados pelo uso do Armazenamento do Azure. Esse padrão consiste em implantar um aplicativo de função (passivo) de backup em uma região diferente. O Gerenciador de Tráfego monitorará o aplicativo de funções (ativo) primário quanto à disponibilidade HTTP. Ele fará failover para o aplicativo de função de backup se o principal falhar. Para obter mais informações, confira Método de Roteamento de Tráfego por Prioridade do Gerenciador de Tráfego.
Observação
- A configuração ativa-passiva proposta garante que um cliente sempre possa disparar novas orquestrações por meio de HTTP. No entanto, como dois aplicativos de funções compartilham o mesmo armazenamento, algumas transações de armazenamento em segundo plano serão distribuídas entre ambos. Portanto, essa configuração incorre alguns custos de saída adicionais para o aplicativo de funções secundário.
- O hub de tarefas e a conta de armazenamento subjacente são criados na região primária e são compartilhadas por ambos os aplicativos de função.
- Todos os aplicativos de funções implantados de forma redundante devem compartilhar as mesmas chaves de acesso de função, caso sejam ativados por meio de HTTP. O Runtime de Funções expõe uma API de gerenciamento que permite que os consumidores adicionem, excluam e atualizem as teclas de função programaticamente. O gerenciamento de chaves também é possível usando as APIs do Azure Resource Manager.
Cenário 1 - Computação com balanceamento de carga com armazenamento compartilhado
Se a infraestrutura de computação no Azure falhar, o aplicativo de função poderá se tornar indisponível. Para minimizar a possibilidade desse tempo de inatividade, este cenário usa dois aplicativos de função implantados em diferentes regiões. O Gerenciador de Tráfego está configurado para detectar problemas no aplicativo de função principal e redirecionar automaticamente o tráfego para o aplicativo de função na região secundária. Este aplicativo de função compartilha a mesma conta do Armazenamento do Azure e o Hub de Tarefas. Portanto, o estado dos aplicativos de função não é perdido e o trabalho pode continuar normalmente. Depois que a integridade for restaurada para a região principal, o Gerenciador de Tráfego do Microsoft Azure começará a rotear solicitações para esse aplicativo de função automaticamente.
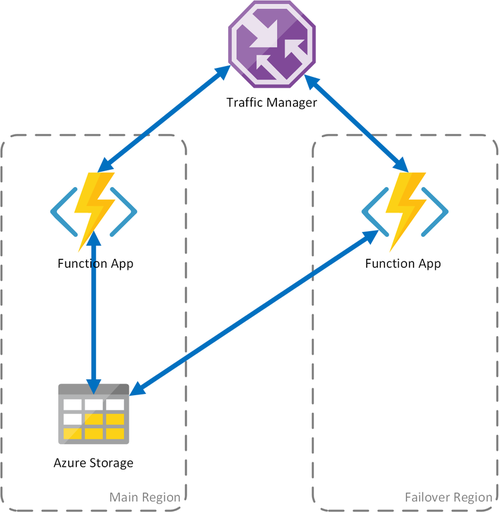
Há vários benefícios ao usar esse cenário de implantação:
- Se a infraestrutura de computação falhar, o trabalho poderá ser retomado na região de failover sem perda de dados.
- O Gerenciador de Tráfego cuida do failover automático para o aplicativo de funções íntegro automaticamente.
- O Gerenciador de Tráfego restabelece automaticamente o tráfego para o aplicativo de função primária depois que a interrupção é corrigida.
No entanto, nesse cenário, considere:
- Se o aplicativo de funções for implantado usando um plano do Serviço de Aplicativo dedicado, a replicação da infraestrutura de computação no datacenter de failover aumenta os custos.
- Esse cenário aborda interrupções na infraestrutura de computação, mas a conta de armazenamento continua sendo o único ponto de falha para o aplicativo de função. Se ocorrer uma interrupção do Armazenamento, o aplicativo apresentará tempo de inatividade.
- Se o aplicativo de função está em failover, haverá um aumento da latência porque ele irá acessar sua conta de armazenamento entre regiões.
- O acesso ao serviço de armazenamento por uma região diferente daquela onde ele está localizado incorre em custos devido ao tráfego de saída da rede.
- Esse cenário depende do Gerenciador de Tráfego. Considerando como o Gerenciador de Tráfego funciona, pode levar algum tempo até que um aplicativo cliente que consuma uma Função Durável precise consultar novamente o endereço do aplicativo de função do Gerenciador de Tráfego.
Observação
A partir da versão v2.3.0 da extensão Durable Functions, dois aplicativos de funções podem ser executados com segurança ao mesmo tempo, com a mesma conta de armazenamento e a mesma configuração do hub de tarefas. O primeiro aplicativo a iniciar adquirirá uma concessão de blob no nível do aplicativo, que impede que outros aplicativos roubem mensagens nas filas do hub de tarefas. Se esse primeiro aplicativo parar de ser executado, sua concessão expirará e poderá ser adquirida por um segundo aplicativo, que continuará a processar as mensagens do hub de tarefas.
Antes da versão v 2.3.0, os aplicativos de funções configurados para usar a mesma conta de armazenamento processarão mensagens e atualizarão os artefatos de armazenamento simultaneamente, resultando em latência geral e custos de saída muito mais altos. Se os aplicativos primário e de réplica tiverem código diferente implantado neles, mesmo temporariamente, as orquestrações também podem falhar na execução correta devido às inconsistências da função do orquestrador entre os dois aplicativos. Portanto, é recomendável que todos os aplicativos que exigem distribuição geográfica para fins de recuperação de desastre usem a v2.3.0 ou posterior da extensão da Durable.
Cenário 2 - Computação com balanceamento de carga com armazenamento regional
O cenário anterior abrange apenas falhas na infraestrutura de computação. Se o serviço de armazenamento falhar, resultará em uma interrupção do aplicativo de função. Para garantir a operação contínua das funções duráveis, esse cenário usa uma conta de armazenamento local em cada região à qual os aplicativos de função são implantados.
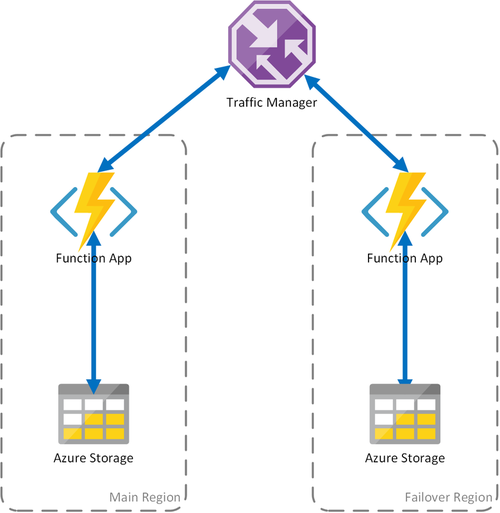
Essa abordagem adiciona aprimoramentos ao cenário anterior:
- Se o aplicativo de função falhar, o Gerenciador de Tráfego cuidará de fazer failover para a região secundária. No entanto, como o aplicativo de função conta com a sua própria conta de armazenamento, as funções duráveis continuam a funcionar.
- Durante um failover, não há latência adicional na região de failover, pois o aplicativo de funções e a conta de armazenamento são colocalizados.
- A falha da camada de armazenamento causará falhas nas funções duráveis, o que, por sua vez, disparará um redirecionamento para a região de failover. Novamente, como o aplicativo de função e o armazenamento são isolados por região, as funções duráveis continuarão a funcionar.
Considerações importantes para esse cenário:
- Se o aplicativo de funções for implantado usando um plano do Serviço de Aplicativo dedicado, a replicação da infraestrutura de computação no datacenter de failover aumenta os custos.
- O estado atual não é de failover, o que implica que as orquestrações e entidades existentes ficarão efetivamente pausadas e indisponíveis até que a região primária seja recuperada.
Para resumir, a compensação entre o primeiro e o segundo cenário é que a latência é preservada e os custos de saída são minimizados, mas as orquestrações e entidades existentes ficarão indisponíveis durante o tempo de inatividade. Determinar se essas compensações são aceitáveis depende dos requisitos do aplicativo.
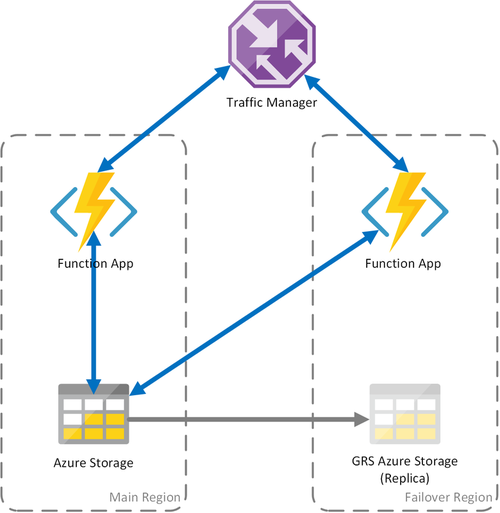
Cenário 3 - Computação com balanceamento de carga com armazenamento GRS compartilhado
Esse cenário é uma modificação do primeiro cenário, implementando uma conta de armazenamento compartilhado. A principal diferença é que a conta de armazenamento é criada com a replicação geográfica habilitada. Funcionalmente, este cenário fornece as mesmas vantagens do Cenário 1, mas permite vantagens adicionais de recuperação de dados:
- O GRS (armazenamento com redundância geográfica) e o RA-GRS (armazenamento com redundância geográfica com acesso de leitura) maximizam a disponibilidade para sua conta de armazenamento.
- Se houver uma interrupção regional do serviço de armazenamento, você poderá iniciar manualmente um failover para a réplica secundária. Em circunstâncias extremas em que uma região for perdida devido a um desastre significativo, a Microsoft poderá iniciar um failover regional. Nesse caso, nenhuma ação sua é necessária.
- Quando ocorre um failover, o estado das funções duráveis será preservado até a última replicação da conta de armazenamento, o que normalmente ocorre a cada poucos minutos.
Assim como acontece com os outros cenários, há considerações importantes:
- Um failover para a réplica pode demorar um pouco. Até que o failover seja concluído e os registros DNS do Armazenamento do Azure sejam atualizados, o aplicativo de funções apresentará uma interrupção.
- Há um custo maior para usar contas de armazenamento com replicação geográfica.
- A replicação do GRS copia os dados de forma assíncrona. Algumas das transações mais recentes podem ser perdidas devido à latência do processo de replicação.
Observação
Conforme descrito no cenário 1, é altamente recomendável que os aplicativos de funções implantados com essa estratégia usem a v 2.3.0 ou posterior da extensão do Durable Functions.
Para obter mais informações, confira a documentação de recuperação de desastre e failover de conta de armazenamento do Armazenamento do Azure.