Mover dados para o cluster vFXT – ingestão de dados paralela
Depois de criar um novo cluster vFXT, a primeira tarefa pode ser mover dados para um novo volume de armazenamento no Azure. No entanto, se o método habitual de movimentação de dados for emitir um comando de cópia simples de um cliente, você provavelmente verá um desempenho lento de cópia. Uma cópia de thread único não é uma boa opção para copiar dados para o armazenamento de back-end do cluster do Avere vFXT.
Como o cluster do Avere vFXT para Azure é um cache escalonável de vários clientes, a maneira mais rápida e eficiente de copiar dados para ele é com vários clientes. Essa técnica paraleliza a ingestão de arquivos e objetos.
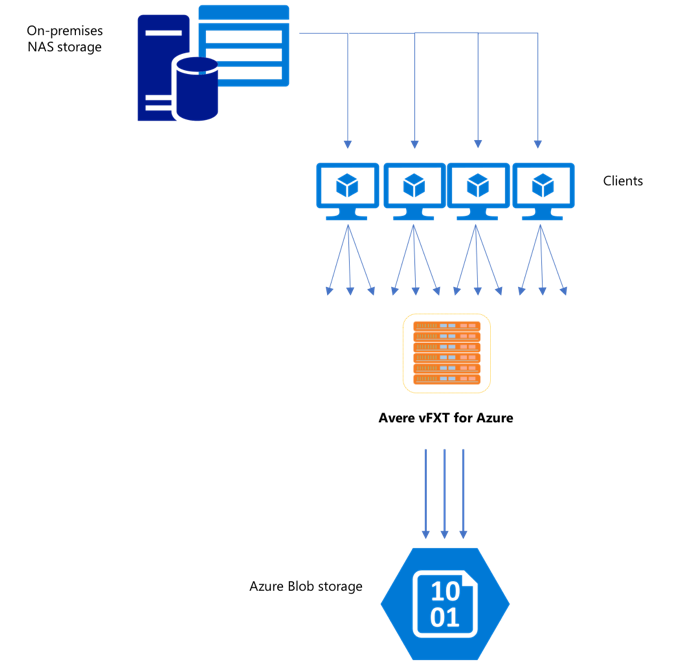
Os comandos cp ou copy comumente usados para transferir dados de um sistema de armazenamento para outro são processos de thread único que copiam apenas um arquivo por vez. Isso significa que o servidor de arquivos está ingerindo apenas um arquivo por vez, o que é um desperdício de recursos do cluster.
Este artigo explica estratégias para criar um sistema de cópia de arquivo com vários threads e vários clientes para mover dados para o cluster do Avere vFXT. Ele explica os conceitos de transferência de arquivo e os pontos de decisão que podem ser usados para cópia de dados eficiente usando vários clientes e comandos de cópia simples.
Também explica alguns utilitários que podem ajudar. O utilitário msrsync pode ser usado para automatizar parcialmente o processo de dividir um conjunto de dados em buckets e usando comandos rsync. O script parallelcp é outro utilitário que lê o diretório de origem e emite comandos de cópia automaticamente. Além disso, a ferramenta rsync pode ser usada em duas fases para fornecer uma cópia mais rápida que ainda fornece consistência de dados.
Clique no link para ir para uma seção:
- Exemplo de cópia manual – uma explicação completa do uso de comandos de cópia
- Exemplo de rsync de duas fases
- Exemplo de parcialmente automatizado (msrsync)
- Exemplo de cópia paralela
Modelo de VM do ingestor de dados
Um modelo do Resource Manager está disponível no GitHub para criar automaticamente uma VM com as ferramentas de ingestão de dados paralela mencionadas neste artigo.
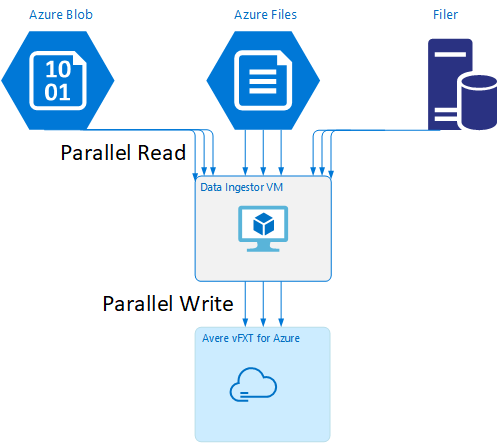
A VM do ingestor de dados faz parte de um tutorial em que a VM recém-criada monta o cluster do Avere vFXT e baixa seu script de inicialização do cluster. Leia Inicializar uma VM de ingestor de dados para obter detalhes.
Planejamento estratégico
Ao projetar uma estratégia para copiar dados em paralelo, você deve compreender as vantagens e desvantagens de tamanho do arquivo, contagem de arquivos e profundidade de diretório.
- Quando os arquivos são pequenos, a métrica de interesse é arquivos por segundo.
- Quando os arquivos são grandes (10 MiBi ou mais), a métrica de interesse é bytes por segundo.
Cada processo de cópia tem uma taxa de transferência e uma taxa de arquivos transferidos, que podem ser medidas pelo tempo o comprimento do comando de cópia e fatorando o tamanho do arquivo e a contagem de arquivos. Explicar como medir as taxas está fora do escopo deste documento, mas é importante entender isso, esteja você lidando com arquivos grandes ou pequenos.
Exemplo de cópia manual
Você pode criar manualmente uma cópia com vários threads em um cliente executando mais de um comando de cópia ao mesmo tempo em segundo plano em relação a conjuntos predefinidos de arquivos ou caminhos.
O comando cp UNIX/Linux inclui o argumento -p para preservar a propriedade e os metadados mtime. Adicionar esse argumento aos comandos a seguir é opcional. (Adicionar o argumento aumenta o número de chamadas do sistema de arquivos enviada do cliente para o sistema de arquivos de destino para modificação de metadados.)
Este exemplo simples copia dois arquivos em paralelo:
cp /mnt/source/file1 /mnt/destination1/ & cp /mnt/source/file2 /mnt/destination1/ &
Depois de emitir esse comando, o comando jobs mostrará se os dois threads estão em execução.
Estrutura de nome de arquivo previsível
Se os nomes de arquivo forem previsíveis, você poderá usar expressões para criar threads da cópia paralela.
Por exemplo, se o diretório contiver 1.000 arquivos numerados consecutivamente de 0001 a 1000, você poderá usar as expressões a seguir para criar dez threads paralelos que copiam, cada um, 100 arquivos:
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination1/ & \
cp /mnt/source/file2* /mnt/destination1/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination1/ & \
cp /mnt/source/file5* /mnt/destination1/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination1/ & \
cp /mnt/source/file8* /mnt/destination1/ & \
cp /mnt/source/file9* /mnt/destination1/
Estrutura de nome de arquivo desconhecida
Se a estrutura de nomenclatura de arquivo não for previsível, você poderá agrupar arquivos por nomes de diretório.
Este exemplo coleta diretórios inteiros para enviar a comandos cp executados como tarefas em segundo plano:
/root
|-/dir1
| |-/dir1a
| |-/dir1b
| |-/dir1c
|-/dir1c1
|-/dir1d
Depois que os arquivos são coletados, você pode executar comandos de cópia paralela para copiar recursivamente as subpastas e todos os seus conteúdos:
cp /mnt/source/* /mnt/destination/
mkdir -p /mnt/destination/dir1 && cp /mnt/source/dir1/* mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ & # this command copies dir1c1 via recursion
cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Quando adicionar pontos de montagem
Depois de ter threads paralelos suficientes em um ponto de montagem do sistema de arquivos de destino único, haverá um ponto em adicionar mais threads não dará mais taxa de transferência. (A taxa de transferência será medida em arquivos/segundo ou em bytes/segundo, dependendo do tipo de dados.) Ou pior, o excesso de threads pode, às vezes, causar uma degradação da taxa de transferência.
Quando isso acontece, você pode adicionar pontos de montagem do lado do cliente a outros endereços IP do cluster vFXT usando o mesmo caminho de montagem do sistema de arquivos remoto:
10.1.0.100:/nfs on /mnt/sourcetype nfs (rw,vers=3,proto=tcp,addr=10.1.0.100)
10.1.1.101:/nfs on /mnt/destination1type nfs (rw,vers=3,proto=tcp,addr=10.1.1.101)
10.1.1.102:/nfs on /mnt/destination2type nfs (rw,vers=3,proto=tcp,addr=10.1.1.102)
10.1.1.103:/nfs on /mnt/destination3type nfs (rw,vers=3,proto=tcp,addr=10.1.1.103)
Adicionar pontos de montagem do lado do cliente permite que você divida os comandos de cópia para pontos de montagem /mnt/destination[1-3] adicionais, obtendo ainda mais paralelismo.
Por exemplo, se os arquivos forem muito grandes, você poderá definir os comandos de cópia para usar caminhos de destino distintos, enviando mais comandos em paralelo do cliente que está executando a cópia.
cp /mnt/source/file0* /mnt/destination1/ & \
cp /mnt/source/file1* /mnt/destination2/ & \
cp /mnt/source/file2* /mnt/destination3/ & \
cp /mnt/source/file3* /mnt/destination1/ & \
cp /mnt/source/file4* /mnt/destination2/ & \
cp /mnt/source/file5* /mnt/destination3/ & \
cp /mnt/source/file6* /mnt/destination1/ & \
cp /mnt/source/file7* /mnt/destination2/ & \
cp /mnt/source/file8* /mnt/destination3/ & \
No exemplo acima, todos os três pontos de montagem de destino estão sendo direcionados pelos processos de cópia de arquivo do cliente.
Quando adicionar clientes
Por fim, quando você tiver atingiu as funcionalidades do cliente, adicionar mais threads de cópia ou pontos de montagem não produzirá mais nenhum aumento de arquivos/s ou bytes/s. Nessa situação, você pode implantar outro cliente com o mesmo conjunto de pontos de montagem que vá executar os próprios conjuntos de processos de cópia de arquivo.
Exemplo:
Client1: cp -R /mnt/source/dir1/dir1a /mnt/destination/dir1/ &
Client1: cp -R /mnt/source/dir2/dir2a /mnt/destination/dir2/ &
Client1: cp -R /mnt/source/dir3/dir3a /mnt/destination/dir3/ &
Client2: cp -R /mnt/source/dir1/dir1b /mnt/destination/dir1/ &
Client2: cp -R /mnt/source/dir2/dir2b /mnt/destination/dir2/ &
Client2: cp -R /mnt/source/dir3/dir3b /mnt/destination/dir3/ &
Client3: cp -R /mnt/source/dir1/dir1c /mnt/destination/dir1/ &
Client3: cp -R /mnt/source/dir2/dir2c /mnt/destination/dir2/ &
Client3: cp -R /mnt/source/dir3/dir3c /mnt/destination/dir3/ &
Client4: cp -R /mnt/source/dir1/dir1d /mnt/destination/dir1/ &
Client4: cp -R /mnt/source/dir2/dir2d /mnt/destination/dir2/ &
Client4: cp -R /mnt/source/dir3/dir3d /mnt/destination/dir3/ &
Criar manifestos de arquivista
Depois de entender as abordagens acima (vários threads de cópia por destino, vários destinos por cliente, vários clientes por sistema de arquivos de origem acessível pela rede), considere esta recomendação: compilar manifestos de arquivo e, em seguida, usá-los com comandos de cópia em vários clientes.
Esse cenário usa o comando find do UNIX para criar manifestos de arquivos ou diretórios:
user@build:/mnt/source > find . -mindepth 4 -maxdepth 4 -type d
./atj5b55c53be6-01/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-01/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-01/support/trace/rolling
./atj5b55c53be6-03/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-03/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-03/support/trace/rolling
./atj5b55c53be6-02/support/gsi/2018-07-22T21:12:06EDT
./atj5b55c53be6-02/support/pcap/2018-07-23T01:34:57UTC
./atj5b55c53be6-02/support/trace/rolling
Redirecione esse resultado para um arquivo: find . -mindepth 4 -maxdepth 4 -type d > /tmp/foo
Em seguida, você pode iterar pelo manifesto, usando comandos BASH para contar arquivos e determinar os tamanhos dos subdiretórios:
ben@xlcycl1:/sps/internal/atj5b5ab44b7f > for i in $(cat /tmp/foo); do echo " `find ${i} |wc -l` `du -sh ${i}`"; done
244 3.5M ./atj5b5ab44b7f-02/support/gsi/2018-07-18T00:07:03EDT
9 172K ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.8M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T01:01:00UTC
131 13M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 6.2M ./atj5b5ab44b7f-02/support/gsi/2018-07-20T21:59:41UTC
134 12M ./atj5b5ab44b7f-02/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
7 16K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:12:19UTC
8 83K ./atj5b5ab44b7f-02/support/pcap/2018-07-18T17:17:17UTC
575 7.7M ./atj5b5ab44b7f-02/support/cores/armada_main.2000.1531980253.gsi
33 4.4G ./atj5b5ab44b7f-02/support/trace/rolling
281 6.6M ./atj5b5ab44b7f-01/support/gsi/2018-07-18T00:07:03EDT
15 182K ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-18T05:01:00UTC
244 17M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-19T01:01:01UTC
299 31M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T01:01:00UTC
256 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T21:59:41UTC_partial
889 7.7M ./atj5b5ab44b7f-01/support/gsi/2018-07-20T21:59:41UTC
262 29M ./atj5b5ab44b7f-01/support/gsi/stats_2018-07-20T22:22:55UTC_vfxt_catchup
11 248K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:12:19UTC
11 88K ./atj5b5ab44b7f-01/support/pcap/2018-07-18T17:17:17UTC
645 11M ./atj5b5ab44b7f-01/support/cores/armada_main.2019.1531980253.gsi
33 4.0G ./atj5b5ab44b7f-01/support/trace/rolling
244 2.1M ./atj5b5ab44b7f-03/support/gsi/2018-07-18T00:07:03EDT
9 158K ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-18T05:01:00UTC
124 5.3M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-19T01:01:01UTC
152 15M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T01:01:00UTC
131 12M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T21:59:41UTC_partial
789 8.4M ./atj5b5ab44b7f-03/support/gsi/2018-07-20T21:59:41UTC
134 14M ./atj5b5ab44b7f-03/support/gsi/stats_2018-07-20T22:25:58UTC_vfxt_catchup
7 159K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:12:19UTC
7 157K ./atj5b5ab44b7f-03/support/pcap/2018-07-18T17:17:17UTC
576 12M ./atj5b5ab44b7f-03/support/cores/armada_main.2013.1531980253.gsi
33 2.8G ./atj5b5ab44b7f-03/support/trace/rolling
Por fim, você deve criar os comandos de cópia de arquivo reais para os clientes.
Se você tiver quatro clientes, use este comando:
for i in 1 2 3 4 ; do sed -n ${i}~4p /tmp/foo > /tmp/client${i}; done
Se você tiver cinco clientes, use algo parecido com isto:
for i in 1 2 3 4 5; do sed -n ${i}~5p /tmp/foo > /tmp/client${i}; done
E para seis... Extrapole conforme necessário.
for i in 1 2 3 4 5 6; do sed -n ${i}~6p /tmp/foo > /tmp/client${i}; done
Você obterá N arquivos resultantes, um para cada um dos seus N clientes que têm os nomes de caminho para os diretórios de quatro níveis obtidos como parte da saída do comando find.
Use cada arquivo para criar o comando de cópia:
for i in 1 2 3 4 5 6; do for j in $(cat /tmp/client${i}); do echo "cp -p -R /mnt/source/${j} /mnt/destination/${j}" >> /tmp/client${i}_copy_commands ; done; done
As opções acima gerará N arquivos, cada um com um comando de cópia por linha, que pode ser executado como um script BASH no cliente.
A meta é executar vários threads desses scripts simultaneamente por cliente em paralelo em vários clientes.
Usar um processo rsync de duas fases
O utilitário rsync não funciona bem para popular o armazenamento em nuvem por meio do sistema do Avere vFXT para Azure, pois ele gera um grande número de operações de criação e renomeação de arquivo para garantir a integridade dos dados. No entanto, você pode usar com segurança a opção --inplace com rsync para ignorar o procedimento de cópia mais cuidadosa se, após isso, você realizar uma segunda execução que verifica a integridade do arquivo.
Uma operação de cópia rsync padrão cria um arquivo temporário e o preenche com os dados. Se a transferência de dados for concluída com êxito, o arquivo temporário será renomeado com o nome do arquivo original. Esse método garante a consistência, mesmo que os arquivos sejam acessados durante a cópia. Mas ele gera mais operações de gravação, o que retarda a movimentação de arquivos por meio do cache.
A opção --inplace grava o novo arquivo diretamente em seu local final. Não há garantia de que os arquivos sejam consistentes durante a transferência, mas isso não é importante se você está preparando um sistema de armazenamento para uso posterior.
A segunda operação rsync serve como uma verificação de consistência da primeira operação. Como os arquivos já foram copiados, a segunda fase é uma verificação rápida para garantir que os arquivos no destino correspondam aos arquivos na origem. Se os arquivos não corresponderem, eles serão copiados novamente.
Você pode emitir ambas as fases com um único comando:
rsync -azh --inplace <source> <destination> && rsync -azh <source> <destination>
Esse método é simples e eficaz para conjuntos de dados até o número de arquivos que o gerenciador de diretório interno pode suportar. (Normalmente, são 200 milhões de arquivos para um cluster de três nós, 500 milhões de arquivos para um cluster de seis nós e assim por diante.)
Usar o utilitário msrsync
A ferramenta msrsync também pode ser usada para mover dados para um arquivista básico de back-end para o cluster do Avere. Essa ferramenta é projetada para otimizar o uso de largura de banda, executando vários processos rsync paralelos. Está disponível no GitHub em https://github.com/jbd/msrsync.
msrsync divide o diretório de origem em "buckets" separados e, em seguida, executa processos rsync individuais em cada bucket.
Testes preliminares usando uma VM de quatro núcleos mostraram a melhor eficiência ao usar 64 processos. Use a opção msrsync-p para definir o número de processos como 64.
Você pode também usar o argumento --inplace com comandos msrsync. Se você usar essa opção, considere executar um segundo comando (como com rsync, descrito acima) para garantir a integridade dos dados.
msrsync só pode gravar de e para volumes locais. A origem e o destino devem ser acessíveis como montagens de locais na rede virtual do cluster.
Para usar msrsync para preencher um volume de nuvem do Azure com um cluster Avere, siga estas instruções:
Instalar
msrsynce seus pré-requisitos (rsync e Python 2.6 ou posterior)Determine o número total de arquivos e diretórios a serem copiados.
Por exemplo, use o utilitário Avere
prime.pycom os argumentosprime.py --directory /path/to/some/directory(disponíveis baixando a URL https://github.com/Azure/Avere/blob/master/src/clientapps/dataingestor/prime.py).Se você não estiver usando
prime.py, poderá calcular o número de itens com a ferramentafindGNU da seguinte maneira:find <path> -type f |wc -l # (counts files) find <path> -type d |wc -l # (counts directories) find <path> |wc -l # (counts both)Divida o número de itens por 64 para determinar o número de itens por processo. Use esse número com a opção
-fpara definir o tamanho de buckets ao executar o comando.Emita o comando
msrsyncpara copiar arquivos:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Se estiver usando
--inplace, adicione uma segunda execução sem a opção de verificar se os dados foram copiados corretamente:msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv --inplace" <SOURCE_PATH> <DESTINATION_PATH> && msrsync -P --stats -p 64 -f <ITEMS_DIV_64> --rsync "-ahv" <SOURCE_PATH> <DESTINATION_PATH>Por exemplo, esse comando se destina a mover 11 mil arquivos em 64 processos de /test/source-repository para /mnt/vfxt/repository:
msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository && msrsync -P --stats -p 64 -f 170 --rsync "-ahv --inplace" /test/source-repository/ /mnt/vfxt/repository
Usar o script de cópia paralela
O script parallelcp pode também ser útil para mover dados para o armazenamento de back-end do seu cluster vFXT.
O script a seguir adicionará o executável parallelcp. (Esse script foi desenvolvido para Ubuntu; se você estiver usando outra distribuição, deverá instalar parallel separadamente.)
sudo touch /usr/bin/parallelcp && sudo chmod 755 /usr/bin/parallelcp && sudo sh -c "/bin/cat >/usr/bin/parallelcp" <<EOM
#!/bin/bash
display_usage() {
echo -e "\nUsage: \$0 SOURCE_DIR DEST_DIR\n"
}
if [ \$# -le 1 ] ; then
display_usage
exit 1
fi
if [[ ( \$# == "--help") || \$# == "-h" ]] ; then
display_usage
exit 0
fi
SOURCE_DIR="\$1"
DEST_DIR="\$2"
if [ ! -d "\$SOURCE_DIR" ] ; then
echo "Source directory \$SOURCE_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -d "\$DEST_DIR" ] && ! mkdir -p \$DEST_DIR ; then
echo "Destination directory \$DEST_DIR does not exist, or is not a directory"
display_usage
exit 2
fi
if [ ! -w "\$DEST_DIR" ] ; then
echo "Destination directory \$DEST_DIR is not writeable, or is not a directory"
display_usage
exit 3
fi
if ! which parallel > /dev/null ; then
sudo apt-get update && sudo apt install -y parallel
fi
DIRJOBS=225
JOBS=225
find \$SOURCE_DIR -mindepth 1 -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$DIRJOBS -0 "mkdir -p \$DEST_DIR/{}"
find \$SOURCE_DIR -mindepth 1 ! -type d -print0 | sed -z "s/\$SOURCE_DIR\///" | parallel --will-cite -j\$JOBS -0 "cp -P \$SOURCE_DIR/{} \$DEST_DIR/{}"
EOM
Exemplo de cópia paralela
Este exemplo usa o script de cópia paralela para compilar glibc usando arquivos de origem do cluster do Avere.
Os arquivos de origem são armazenados no ponto de montagem do cluster Avere e os arquivos de objeto são armazenados no disco rígido local.
Esse script usa o script de cópia paralela acima. A opção -j é usada com parallelcp e make obter paralelização.
sudo apt-get update
sudo apt install -y gcc bison gcc binutils make parallel
cd
wget https://mirrors.kernel.org/gnu/libc/glibc-2.27.tar.bz2
tar jxf glibc-2.27.tar.bz2
ln -s /nfs/node1 avere
time parallelcp glibc-2.27 avere/glibc-2.27
cd
mkdir obj
mkdir usr
cd obj
/home/azureuser/avere/glibc-2.27/configure --prefix=/home/azureuser/usr
time make -j