Uma arquitetura de Big Data foi projetada para lidar com a ingestão, o processamento e a análise de dados que são muito grandes ou complexos para sistemas de banco de dados tradicionais.

As soluções de Big Data normalmente envolvem um ou mais dos seguintes tipos de carga de trabalho:
- Processamento em lote de fontes de Big Data em repouso.
- Processamento em tempo real de Big Data em movimento.
- Exploração interativa de Big Data.
- Análise preditiva e aprendizado de máquina.
A maioria das arquiteturas de Big Data inclui alguns ou todos os seguintes componentes:
Fontes de dados: todas as soluções de Big Data começam com uma ou mais fontes de dados. Os exemplos incluem:
- Armazenamentos de dados de aplicativos, como bancos de dados relacionais.
- Arquivos estáticos produzidos por aplicativos, como arquivos de log do servidor Web.
- Fontes de dados em tempo real, como dispositivos IoT.
armazenamento de dados: os dados para operações de processamento em lote normalmente são armazenados em um repositório de arquivos distribuído que pode conter grandes volumes de arquivos grandes em vários formatos. Esse tipo de repositório geralmente é chamado de data lake. As opções para implementar esse armazenamento incluem o Azure Data Lake Store ou contêineres de blob no Armazenamento do Azure.
de processamento em lote: como os conjuntos de dados são tão grandes, muitas vezes uma solução de Big Data deve processar arquivos de dados usando trabalhos em lotes de execução longa para filtrar, agregar e preparar os dados para análise. Normalmente, esses trabalhos envolvem ler arquivos de origem, processá-los e gravar a saída em novos arquivos. As opções incluem o uso de fluxos de dados, pipelines de dados no Microsoft Fabric.
de ingestão de mensagens em tempo real: se a solução incluir fontes em tempo real, a arquitetura deverá incluir uma maneira de capturar e armazenar mensagens em tempo real para processamento de fluxo. Pode ser um armazenamento de dados simples, em que as mensagens de entrada são descartadas em uma pasta para processamento. No entanto, muitas soluções precisam de um repositório de ingestão de mensagens para atuar como um buffer para mensagens e para dar suporte ao processamento de expansão, à entrega confiável e a outra semântica de enfileiramento de mensagens. As opções incluem Hubs de Eventos do Azure, Hubs IoT do Azure e Kafka.
de processamento de fluxo: depois de capturar mensagens em tempo real, a solução deve processá-las filtrando, agregando e preparando os dados para análise. Os dados de fluxo processados são gravados em um coletor de saída. O Azure Stream Analytics fornece um serviço de processamento de fluxo gerenciado com base na execução perpétua de consultas SQL que operam em fluxos não associados. Outra opção é usar o Inteligência em Tempo Real no Microsoft Fabric, que permite executar consultas KQL à medida que os dados estão sendo ingeridos.
armazenamento de dados analíticos: muitas soluções de Big Data preparam dados para análise e, em seguida, servem os dados processados em um formato estruturado que pode ser consultado usando ferramentas analíticas. O armazenamento de dados analíticos usado para atender a essas consultas pode ser um data warehouse relacional no estilo Kimball, como visto na maioria das soluções tradicionais de BI (business intelligence) ou um lakehouse com arquitetura de medalhão (Bronze, Prata e Ouro). O Azure Synapse Analytics fornece um serviço gerenciado para armazenamento de dados baseado em nuvem em larga escala. Como alternativa, o Microsoft Fabric fornece ambas as opções - warehouse e lakehouse - que podem ser consultadas usando SQL e Spark, respectivamente.
Análise e relatórios: o objetivo da maioria das soluções de Big Data é fornecer insights sobre os dados por meio de análise e relatórios. Para capacitar os usuários a analisar os dados, a arquitetura pode incluir uma camada de modelagem de dados, como um cubo OLAP multidimensional ou um modelo de dados tabulares no Azure Analysis Services. Ele também pode dar suporte ao BI de autoatendimento, usando as tecnologias de modelagem e visualização no Microsoft Power BI ou no Microsoft Excel. A análise e os relatórios também podem assumir a forma de exploração interativa de dados por cientistas de dados ou analistas de dados. Para esses cenários, o Microsoft Fabric fornece ferramentas como notebooks em que o usuário pode escolher o SQL ou uma linguagem de programação de sua escolha.
de Orquestração: a maioria das soluções de Big Data consiste em operações de processamento de dados repetidas, encapsuladas em fluxos de trabalho, que transformam dados de origem, movem dados entre várias fontes e coletores, carregam os dados processados em um armazenamento de dados analíticos ou empurram os resultados diretamente para um relatório ou painel. Para automatizar esses fluxos de trabalho, você pode usar uma tecnologia de orquestração, como pipelines do Azure Data Factory ou do Microsoft Fabric.
O Azure inclui muitos serviços que podem ser usados em uma arquitetura de Big Data. Eles se enquadram aproximadamente em duas categorias:
- Serviços gerenciados, incluindo Microsoft Fabric, Azure Data Lake Store, Azure Synapse Analytics, Azure Stream Analytics, Hubs de Eventos do Azure, Hub IoT do Azure e Azure Data Factory.
- Tecnologias de software livre baseadas na plataforma Apache Hadoop, incluindo HDFS, HBase, Hive, Spark e Kafka. Essas tecnologias estão disponíveis no Azure no serviço Azure HDInsight.
Essas opções não são mutuamente exclusivas e muitas soluções combinam tecnologias de software livre com serviços do Azure.
Quando usar essa arquitetura
Considere esse estilo de arquitetura quando você precisar:
- Armazene e processe dados em volumes muito grandes para um banco de dados tradicional.
- Transforme dados não estruturados para análise e relatórios.
- Capture, processe e analise fluxos não associados de dados em tempo real ou com baixa latência.
- Use o Azure Machine Learning ou os Serviços Cognitivos do Azure.
Benefícios
- opções de tecnologia . Você pode misturar e corresponder aos serviços gerenciados do Azure e às tecnologias Apache em clusters HDInsight, para aproveitar as habilidades ou os investimentos em tecnologia existentes.
- desempenho por meio do paralelismo. As soluções de Big Data aproveitam o paralelismo, permitindo soluções de alto desempenho que são dimensionadas para grandes volumes de dados.
- de escala elástica. Todos os componentes na arquitetura de Big Data dão suporte ao provisionamento de expansão, para que você possa ajustar sua solução a cargas de trabalho pequenas ou grandes e pagar apenas pelos recursos que você usa.
- interoperabilidade com soluções existentes. Os componentes da arquitetura de Big Data também são usados para processamento de IoT e soluções de BI empresarial, permitindo que você crie uma solução integrada entre cargas de trabalho de dados.
Desafios
- de complexidade. As soluções de Big Data podem ser extremamente complexas, com vários componentes para lidar com a ingestão de dados de várias fontes de dados. Pode ser desafiador criar, testar e solucionar problemas de processos de Big Data. Além disso, pode haver um grande número de configurações em vários sistemas que devem ser usadas para otimizar o desempenho.
- skillset. Muitas tecnologias de Big Data são altamente especializadas e usam estruturas e linguagens que não são típicas de arquiteturas de aplicativos mais gerais. Por outro lado, as tecnologias de Big Data estão evoluindo novas APIs que se baseiam em idiomas mais estabelecidos.
- de maturidade da tecnologia
. Muitas das tecnologias usadas em Big Data estão evoluindo. Embora as principais tecnologias do Hadoop, como Hive e Spark, tenham se estabilizado, tecnologias emergentes como delta ou iceberg introduzem mudanças e aprimoramentos extensivos. Serviços gerenciados, como o Microsoft Fabric, são relativamente jovens em comparação com outros serviços do Azure e provavelmente evoluirão ao longo do tempo. - de segurança do
. As soluções de Big Data geralmente dependem do armazenamento de todos os dados estáticos em um data lake centralizado. Proteger o acesso a esses dados pode ser desafiador, especialmente quando os dados devem ser ingeridos e consumidos por vários aplicativos e plataformas.
Práticas recomendadas
Aproveitar o paralelismo. A maioria das tecnologias de processamento de Big Data distribui a carga de trabalho em várias unidades de processamento. Isso requer que os arquivos de dados estáticos sejam criados e armazenados em um formato splittable. Sistemas de arquivos distribuídos, como o HDFS, podem otimizar o desempenho de leitura e gravação e o processamento real é executado por vários nós de cluster em paralelo, o que reduz os tempos gerais de trabalho. O uso do formato de dados dividível é altamente recomendado, como Parquet.
de dados de partição. O processamento em lote geralmente ocorre em um agendamento recorrente , por exemplo, semanal ou mensal. Arquivos de dados de partição e estruturas de dados, como tabelas, com base em períodos temporais que correspondem ao agendamento de processamento. Isso simplifica a ingestão de dados e o agendamento de trabalho e facilita a solução de falhas. Além disso, as tabelas de particionamento usadas em consultas Hive, spark ou SQL podem melhorar significativamente o desempenho da consulta.
Aplicar semântica de esquema em leitura. O uso de um data lake permite combinar armazenamento para arquivos em vários formatos, sejam estruturados, semiestruturados ou não estruturados. Use semântica de de esquema em leitura, que projetam um esquema nos dados quando os dados estão sendo processados, não quando os dados são armazenados. Isso cria flexibilidade na solução e impede gargalos durante a ingestão de dados causada pela validação de dados e verificação de tipos.
Processar dados in-loco. As soluções de BI tradicionais geralmente usam um processo de ETL (extração, transformação e carregamento) para mover dados para um data warehouse. Com dados de volumes maiores e uma maior variedade de formatos, as soluções de Big Data geralmente usam variações de ETL, como transformar, extrair e carregar (TEL). Com essa abordagem, os dados são processados no armazenamento de dados distribuídos, transformando-os na estrutura necessária, antes de mover os dados transformados para um armazenamento de dados analíticos.
de utilização e de tempo do balanceamento de
. Para trabalhos de processamento em lote, é importante considerar dois fatores: o custo por unidade dos nós de computação e o custo por minuto de usar esses nós para concluir o trabalho. Por exemplo, um trabalho em lote pode levar oito horas com quatro nós de cluster. No entanto, pode ocorrer que o trabalho usa todos os quatro nós somente durante as duas primeiras horas e, depois disso, apenas dois nós são necessários. Nesse caso, executar todo o trabalho em dois nós aumentaria o tempo total do trabalho, mas não o dobraria, portanto, o custo total seria menor. Em alguns cenários de negócios, um tempo de processamento mais longo pode ser preferível ao custo mais alto do uso de recursos de cluster subutilizados. Separar recursos. Sempre que possível, procure separar recursos com base nas cargas de trabalho para evitar cenários como uma carga de trabalho usando todos os recursos enquanto outros estão aguardando.
Orquestrarde ingestão de dados. Em alguns casos, os aplicativos empresariais existentes podem gravar arquivos de dados para processamento em lote diretamente em contêineres de blob de armazenamento do Azure, onde podem ser consumidos por serviços downstream como o Microsoft Fabric. No entanto, muitas vezes, você precisará orquestrar a ingestão de dados de fontes de dados locais ou externas no data lake. Use um fluxo de trabalho de orquestração ou pipeline, como aqueles compatíveis com o Azure Data Factory ou o Microsoft Fabric, para fazer isso de maneira previsível e centralizável.
Esfregar dados confidenciais no início do. O fluxo de trabalho de ingestão de dados deve esfregar dados confidenciais no início do processo, para evitar armazená-los no data lake.
Arquitetura de IoT
A IoT (Internet das Coisas) é um subconjunto especializado de soluções de Big Data. O diagrama a seguir mostra uma possível arquitetura lógica para IoT. O diagrama enfatiza os componentes de streaming de eventos da arquitetura.
diagrama 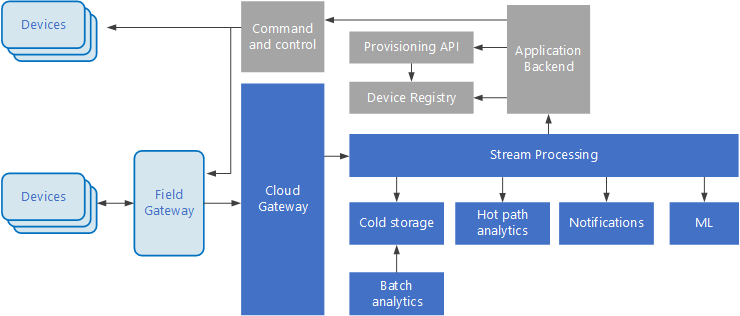
O gateway de nuvem ingere eventos de dispositivo no limite da nuvem, usando um sistema de mensagens confiável e de baixa latência.
Os dispositivos podem enviar eventos diretamente para o gateway de nuvem ou por meio de um gateway de campo . Um gateway de campo é um dispositivo ou software especializado, geralmente colocado com os dispositivos, que recebe eventos e os encaminha para o gateway de nuvem. O gateway de campo também pode pré-processar os eventos brutos do dispositivo, executando funções como filtragem, agregação ou transformação de protocolo.
Após a ingestão, os eventos passam por uma ou mais processadores de fluxo que podem rotear os dados (por exemplo, para armazenamento) ou executar análises e outros processamentos.
Veja a seguir alguns tipos comuns de processamento. (Esta lista certamente não é exaustiva.)
Gravação de dados de evento em armazenamento a frio, para arquivamento ou análise em lote.
Análise de caminho quente, analisando o fluxo de eventos em (quase) tempo real, para detectar anomalias, reconhecer padrões em janelas de tempo sem interrupção ou disparar alertas quando uma condição específica ocorre no fluxo.
Manipulando tipos especiais de mensagens não telemetria de dispositivos, como notificações e alarmes.
Aprendizado de máquina.
As caixas sombreadas em cinza mostram componentes de um sistema IoT que não estão diretamente relacionados ao streaming de eventos, mas estão incluídas aqui para fins de integridade.
O registro de dispositivo é um banco de dados dos dispositivos provisionados, incluindo as IDs do dispositivo e, geralmente, os metadados do dispositivo, como localização.
O de API de provisionamento de
é uma interface externa comum para provisionar e registrar novos dispositivos. Algumas soluções de IoT permitem que mensagens de comando e controle sejam enviadas para dispositivos.
Esta seção apresentou uma exibição de alto nível da IoT e há muitas sutilezas e desafios a serem considerados. Para obter mais detalhes, consulte arquiteturas de IoT.
Próximas etapas
- Saiba mais sobre arquiteturas de Big Data.
- Saiba mais sobre arquiteturas de IoT.