Lições aprendidas
- Certifique-se de que todas as partes envolvidas entendam a diferença entre alta disponibilidade (HA) e recuperação de desastres (DR): uma armadilha comum é confundir os dois conceitos e incombinar as soluções associadas a eles.
- Discuta com os stakeholders do negócio sobre suas expectativas em relação aos seguintes aspectos para definir os RPOs (objetivos de ponto de recuperação) e os RTOs (objetivos de tempo de recuperação:
- Quanto tempo de inatividade eles podem tolerar, tendo em mente que, geralmente, quanto mais rápida a recuperação, maior o custo.
- O tipo de incidentes dos quais eles querem ser protegidos, mencionando a probabilidade relacionada a tal evento. Por exemplo, a probabilidade de um servidor ficar inativo é maior do que um desastre natural que afeta todos os datacenters em uma região.
- Qual o impacto da indisponibilidade do sistema nos seus negócios?
- O orçamento de despesas operacionais (OPEX) para a solução no futuro.
- Considere quais opções de serviço degradadas seus usuários finais podem aceitar. Isso pode incluir:
- Ainda ter acesso aos painéis de visualização mesmo sem os dados mais atualizados, ou seja, se os pipelines de ingestão não funcionarem, os usuários finais ainda terão acesso aos seus dados.
- Ter acesso de leitura, mas sem acesso de gravação.
- As métricas de RTO e RPO de destino podem definir qual estratégia de recuperação de desastres você escolhe implementar:
- Ativo/Ativo.
- Ativo/Passivo.
- Ativo/Reimplantar em caso de desastre.
- Considere seu próprio SLO (objetivo de nível de serviço) composto para levar em consideração os tempos de inatividade toleráveis.
- Verifique se você entendeu todos os componentes que podem afetar a disponibilidade dos seus sistemas, como:
- Gerenciamento de identidades.
- Topologia de rede.
- Gerenciamento de segredos/chaves.
- Fontes de dados.
- Automação/agendador de trabalhos.
- Repositório de origem e pipelines de implantação (GitHub, Azure DevOps).
- A detecção precoce de interrupções também é uma maneira de diminuir significativamente os valores de RTO e RPO. Aqui estão alguns aspectos que devem ser abordados:
- Defina o que é uma interrupção e como ela é mapeada para a definição de interrupção da Microsoft. A definição da Microsoft está disponível na página Contrato de nível de serviço do Azure (SLA) no nível de produto ou serviço.
- Um sistema eficiente de monitoramento e alerta com equipes responsáveis para revisar essas métricas e alertas em tempo hábil ajuda a atingir a meta.
- Em relação ao design da assinatura, a infraestrutura adicional para recuperação de desastres pode ser armazenada na assinatura original. Os serviços de PaaS (plataforma como serviço), como o Azure Data Lake Storage Gen2 ou o Azure Data Factory, normalmente têm recursos nativos que permitem o failover para instâncias secundárias em outras regiões, permanecendo contidos na assinatura original. Alguns clientes podem querer considerar ter um grupo de recursos dedicado para recursos usados apenas em cenários de DR para fins de custo.
- Deve-se notar que os limites de assinatura podem atuar como uma restrição para essa abordagem.
- Outras restrições podem incluir a complexidade do design e os controles de gerenciamento para garantir que os grupos de recursos de DR não sejam usados para fluxos de trabalho BAU (negócios como de costume).
- Crie o fluxo de trabalho de DR com base na importância e nas dependências de uma solução. Por exemplo, não tente recompilar uma instância do Azure Analysis Services antes que seu data warehouse esteja em execução, pois isso dispara um erro. Saia dos laboratórios de desenvolvimento mais tarde no processo, recupere as principais soluções corporativas primeiro.
- Tente identificar tarefas de recuperação que podem ser paralelizadas entre soluções, reduzindo o RTO total.
- Se o Azure Data Factory for usado em uma solução, não se esqueça de incluir tempos de execução de integração auto-hospedados no escopo. O Azure Site Recovery é ideal para esses computadores.
- As operações manuais devem ser automatizadas o máximo possível para evitar erros humanos, especialmente quando sob pressão. É recomendável:
- Adote o provisionamento de recursos por meio de modelos Bicep, ARM ou scripts do PowerShell.
- Adote o controle de versão do código-fonte e a configuração de recursos.
- Use pipelines de lançamento de CI/CD em vez de operações de clique.
- Como você tem um plano de failover, considere os procedimentos para fazer fallback para as instâncias primárias.
- Defina indicadores e métricas claros para validar se o failover foi bem-sucedido e se as soluções estão em execução ou se a situação voltou ao normal (também conhecido como funcional primário).
- Decida se seus SLAs (contratos de nível de serviço) devem permanecer os mesmos após um failover ou se você permite um serviço degradado.
- Essa decisão dependerá muito do suporte do processo de serviço de negócios. Por exemplo, o failover para um sistema de reserva de salas será muito diferente de um sistema operacional principal.
- Uma definição de RTO/RPO deve ser baseada em cenários de usuário específicos, e não no nível da infraestrutura. Isso lhe dará mais granularidade sobre quais processos e componentes devem ser recuperados primeiro se houver uma interrupção ou desastre.
- Certifique-se de incluir verificações de capacidade na região de destino antes de avançar com um failover: se houver um grande desastre, lembre-se de que muitos clientes tentarão fazer failover para a mesma região emparelhada ao mesmo tempo, o que pode causar atrasos ou contenção no provisionamento dos recursos.
- Se esses riscos forem inaceitáveis, uma estratégia de DR Ativa/Ativa ou Ativa/Passiva deve ser considerada.
- Um plano de recuperação de desastres deve ser criado e mantido para documentar o processo de recuperação e os proprietários da ação. Além disso, considere que as pessoas podem estar de licença, portanto, certifique-se de incluir contatos secundários.
- Exercícios regulares de recuperação de desastres devem ser realizados para validar o fluxo de trabalho do plano de DR, se ele atende ao RTO/RPO necessário e para treinar as equipes responsáveis.
- Os backups de dados e configuração também devem ser testados regularmente para garantir que estejam "adequados à finalidade" para dar suporte a quaisquer atividades de recuperação.
- A colaboração antecipada com equipes responsáveis pela rede, identidade e provisionamento de recursos permitirá um acordo sobre a solução mais ideal em relação a:
- Como redirecionar usuários e tráfego do site primário para o secundário. Conceitos como redirecionamento de DNS ou o uso de ferramentas específicas, como o Gerenciador de Tráfego do Azure, podem ser avaliados.
- Como fornecer acesso e direitos ao site secundário de maneira oportuna e segura.
- Durante um desastre, a comunicação eficaz entre as muitas partes envolvidas é fundamental para a execução eficiente e rápida do plano. As equipes podem incluir:
- Decisores.
- Equipe de resposta a incidentes.
- Usuários e equipes internas afetadas.
- Equipes externas.
- A orquestração dos diferentes recursos no momento certo garantirá a eficiência na execução do plano de recuperação de desastres.
Considerações
Antipadrões
- Copiar/colar esta série de artigos Esta série de artigos destina-se a fornecer diretrizes aos clientes que procuram o próximo nível de detalhes para um processo de DR específico do Azure. Como tal, ela se baseia no IP genérico da Microsoft e nas arquiteturas de referência, e não em qualquer implementação do Azure específica do cliente.
Embora os detalhes fornecidos ajudem a dar suporte a um bom entendimento fundamental, os clientes devem aplicar seu próprio contexto, implementação e requisitos específicos antes de obter uma estratégia e um processo de DR "adequados ao propósito".
Tratar a DR como um processo somente de tecnologia Os stakeholders de negócios desempenham um papel crítico na definição dos requisitos para DR e na conclusão das etapas de validação de negócios necessárias para confirmar uma recuperação de serviço. Garantir que os stakeholders de negócios estejam envolvidos em todas as atividades de DR proporcionará um processo de DR que seja "adequado ao propósito", represente valor comercial e seja executável.
Planos de DR "Definir e esquecer" O Azure está em constante evolução, assim como o uso de vários componentes e serviços por clientes individuais. Um processo de DR "adequado ao propósito" deve evoluir com eles. Por meio do processo de SDLC (ciclo de vida de desenvolvimento de software) ou revisões periódicas, os clientes devem revisitar regularmente seu plano de recuperação de desastre. O objetivo é garantir a validade do plano de recuperação do serviço e que quaisquer deltas entre componentes, serviços ou soluções tenham sido contabilizados.
Avaliações baseadas em papel Embora a simulação de ponta a ponta de um evento de DR seja difícil em um ecossistema de dados moderno, esforços devem ser feitos para chegar o mais próximo possível de uma simulação completa em todos os componentes afetados. Exercícios programados regularmente construirão a "memória muscular" exigida pela organização para poder executar o plano de DR com confiança.
Confiar na Microsoft para fazer tudo Nos serviços do Microsoft Azure, há uma clara divisão de responsabilidade, ancorada pela camada de serviço de nuvem usada:
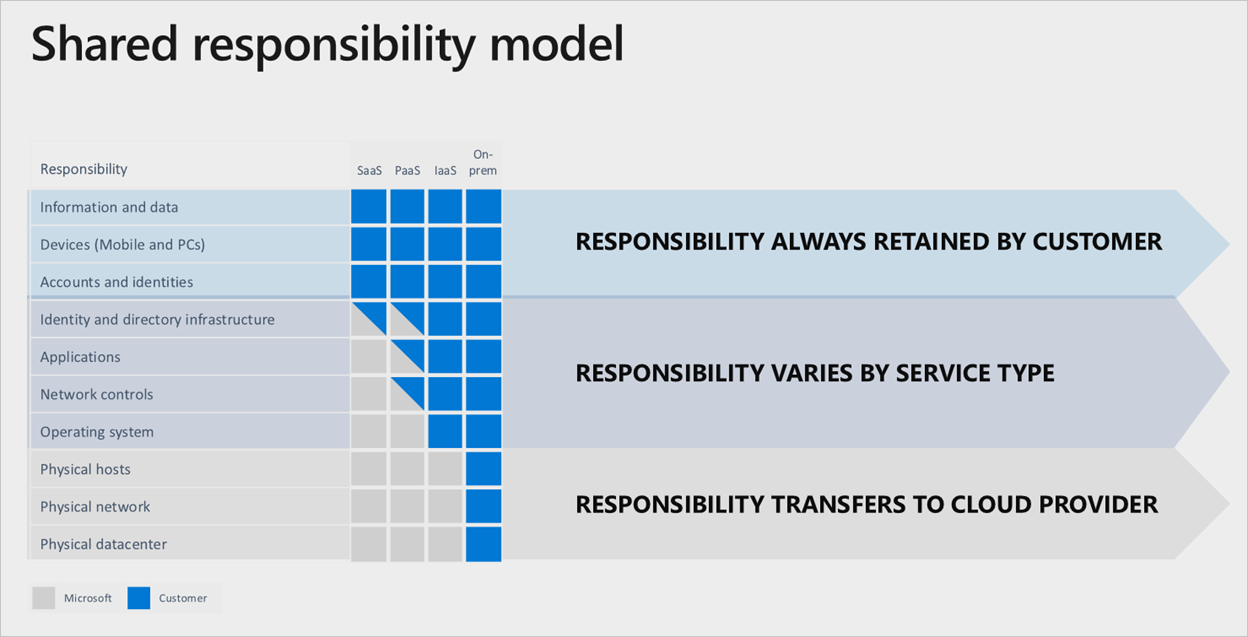 Mesmo que uma pilha completa de software como serviço (SaaS) seja usada, o cliente ainda manterá a responsabilidade de garantir que as contas, as identidades e os dados estejam corretos/atualizados, além dos dispositivos usados para interagir com os serviços do Azure.
Mesmo que uma pilha completa de software como serviço (SaaS) seja usada, o cliente ainda manterá a responsabilidade de garantir que as contas, as identidades e os dados estejam corretos/atualizados, além dos dispositivos usados para interagir com os serviços do Azure.
Escopo e estratégia do evento
Escopo do evento de desastre
Eventos diferentes terão um escopo de impacto diferente e, portanto, uma resposta diferente. O diagrama a seguir ilustra isso para um evento de desastre: 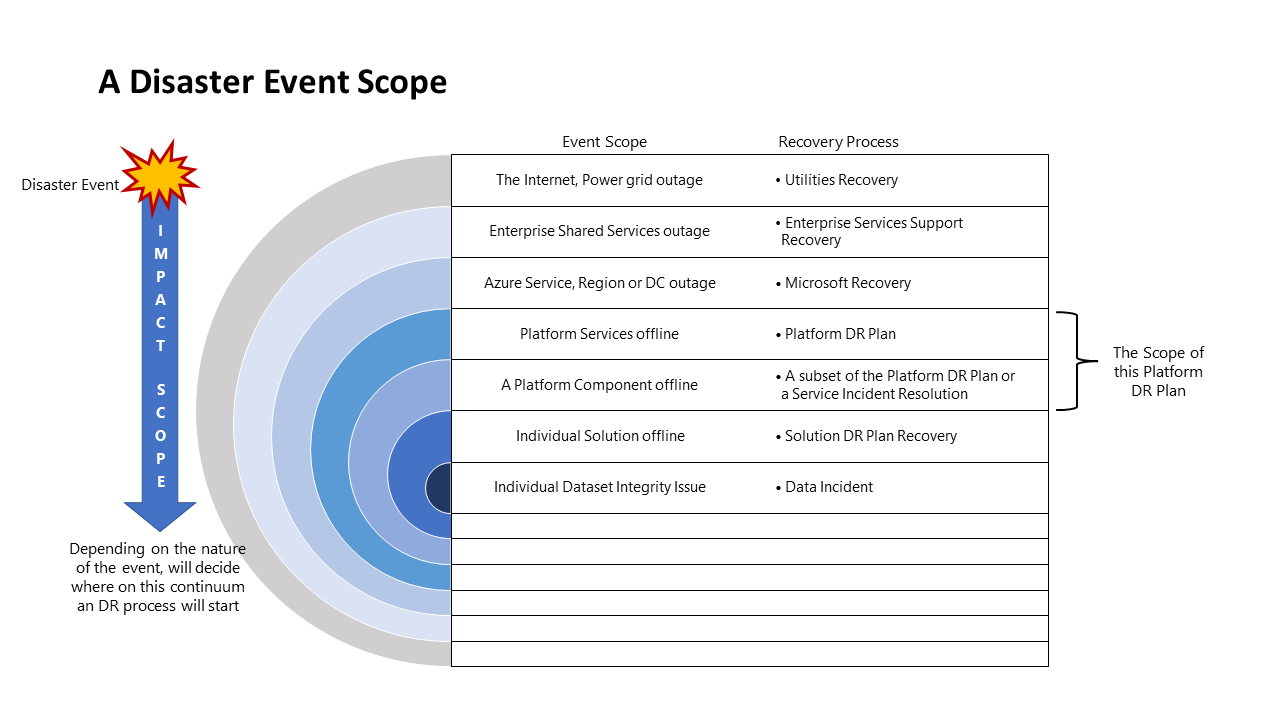
Opções de estratégia de desastres
Há quatro opções de alto nível para uma estratégia de recuperação de desastre:
- Esperar pela Microsoft - Como o nome sugere, a solução fica offline até a recuperação completa dos serviços na região afetada pela Microsoft. Uma vez recuperada, a solução é validada pelo cliente e, em seguida, atualizada para recuperação do serviço.
- Reimplantar em caso de desastre - A solução é reimplantada manualmente em uma região disponível do zero, evento pós-desastre.
- Reposição morna (ativo/passivo) - Uma solução hospedada secundária é criada em uma região alternativa e componentes são implantados para garantir a capacidade mínima; no entanto, os componentes não recebem tráfego de produção. Os serviços secundários na região alternativa podem ser "desativados" ou executados em um nível de desempenho inferior até que ocorra um evento de DR.
- Reposição quente (Ativo/Ativo) - A solução é hospedada em uma configuração ativa/ativa em várias regiões. A solução hospedada secundária recebe, processa e fornece dados como parte do sistema maior.
Impactos da estratégia de DR
Embora o custo operacional atribuído aos níveis mais altos de resiliência de serviço geralmente domine as Principais decisões de design (KDD) para uma estratégia de DR. Há outras considerações importantes.
Observação
A otimização de custos é um dos cinco pilares da excelência arquitetônica com a Well-Architected Framework do Azure. Seu objetivo é reduzir despesas desnecessárias e melhorar a eficiência operacional.
O cenário de DR para este exemplo trabalhado é uma interrupção regional completa do Azure que afeta diretamente a região primária que hospeda a Contoso Data Platform.
Para esse cenário de paralisação, o impacto relativo nas quatro estratégias de DR de alto nível são: 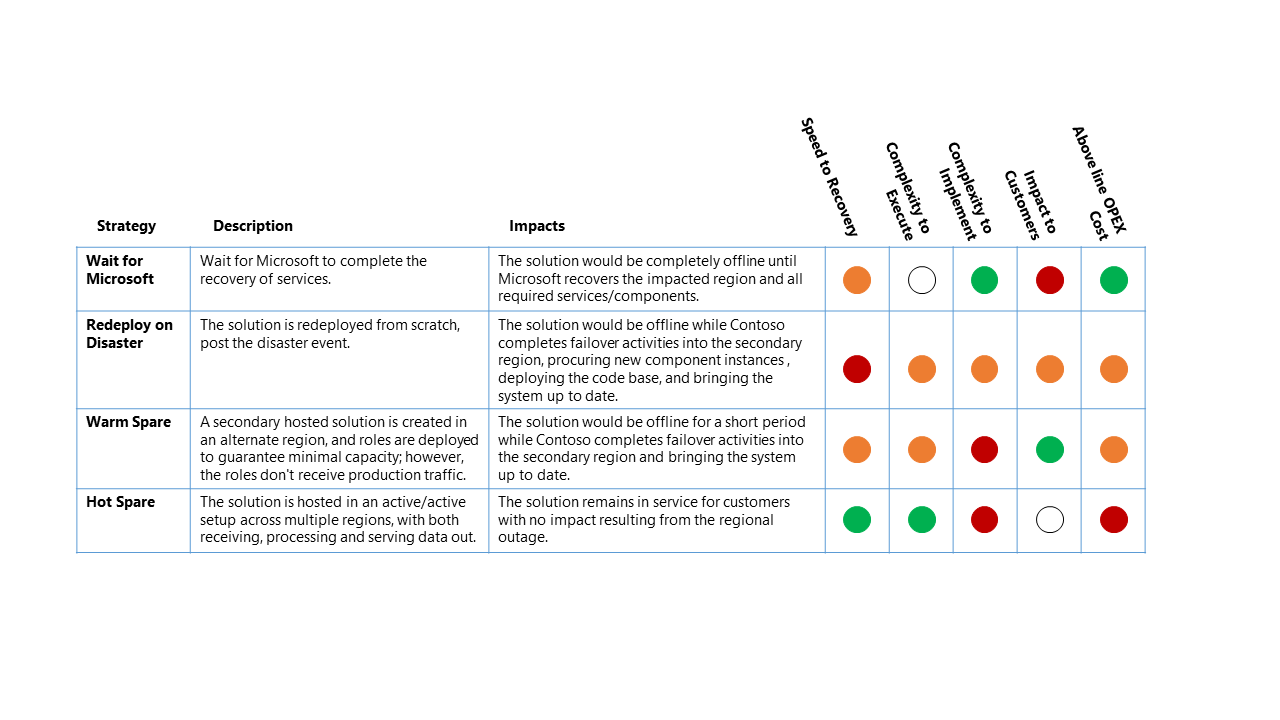
Chave de classificação
- RTO (objetivo de tempo de recuperação): o tempo decorrido esperado desde o evento de desastre até a recuperação do serviço de plataforma.
- Complexidade a ser executada: a complexidade para a organização executar as atividades de recuperação.
- Complexidade a ser implementada: a complexidade para a organização implementar a estratégia de DR.
- Impacto para os clientes: o impacto direto para os clientes do serviço de plataforma de dados da estratégia de DR.
- Custo OPEX acima da linha: o custo extra esperado da implementação dessa estratégia, como o aumento da cobrança mensal do Azure para componentes adicionais e recursos adicionais necessários para dar suporte.
Observação
A tabela acima deve ser lida como uma comparação entre as opções - uma estratégia que tem um indicador verde é melhor para essa classificação do que outra estratégia com um indicador amarelo ou vermelho.
Próximas etapas
Agora que você aprendeu sobre as recomendações relacionadas aos ao cenário, saiba mais sobre como implantar esse cenário