Fase de geração de inserções de RAG
Nas etapas anteriores da sua solução RAG (Geração aumentada por recuperação), você dividiu seus documentos em fragmentos e otimizou os fragmentos. Nesta etapa, você gera inserções para essas partes e todos os campos de metadados nos quais você planeja executar pesquisas de vetor.
Este artigo faz parte de uma série. Leia a introdução.
Uma inserção é uma representação matemática de um objeto, como texto. Quando uma rede neural está sendo treinada, muitas representações de um objeto são criadas. Cada representação tem conexões com outros objetos na rede. Uma inserção é importante porque captura o significado semântico do objeto.
A representação de um objeto tem conexões com representações de outros objetos, para que você possa comparar objetos matematicamente. O exemplo a seguir mostra como as inserções capturam o significado semântico e as relações entre si:
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
As inserções são comparadas entre si usando as noções de similaridade e distância. A grade a seguir mostra uma comparação de inserções.

Em uma solução RAG, você geralmente incorpora a consulta do usuário usando o mesmo modelo de incorporação que seus fragmentos. Em seguida, pesquise em seu banco de dados vetores relevantes para retornar as partes mais semanticamente relevantes. O texto original das partes relevantes é passado para o modelo de linguagem como dados de referência.
Nota
Os vetores representam o significado semântico do texto de uma forma que permite a comparação matemática. Você deve limpar as partes para que a proximidade matemática entre vetores reflita com precisão sua relevância semântica.
A importância do modelo de inserção
O modelo de inserção escolhido pode afetar significativamente a relevância dos resultados da pesquisa de vetor. Você deve considerar o vocabulário do modelo de inserção. Cada modelo de inserção é treinado com um vocabulário específico. Por exemplo, o tamanho do vocabulário do modelo bert é de cerca de 30.000 palavras.
O vocabulário de um modelo de inserção é importante porque lida com palavras que não estão em seu vocabulário de maneira única. Se uma palavra não estiver no vocabulário do modelo, ela ainda calculará um vetor para ele. Para fazer isso, muitos modelos dividem as palavras em sub palavras. Eles tratam as subpalavras como tokens distintos ou agregam os vetores das subpalavras para criar uma única vetorização.
Por exemplo, a palavra histamina pode não estar no vocabulário de um modelo de inserção. A palavra histamina tem um significado semântico como um produto químico que seu corpo libera, o que causa sintomas de alergia. O modelo de inserção não contém histamina. Então, pode separar a palavra em subpalavras que estão em seu vocabulário, como seu, ta e meu.

Os significados semânticos dessas subpalavras estão longe do significado de histamina. Os valores vetoriais individuais ou combinados das subpalavras resultam em correspondências vetoriais menos precisas se comparados a se histamina estivesse no vocabulário do modelo.
Escolher um modelo de inserção
Determine o modelo de inserção correto para seu caso de uso. Considere a sobreposição entre o vocabulário do modelo de inserção e as palavras dos dados ao escolher um modelo de inserção.

Primeiro, determine se você tem conteúdo específico do domínio. Por exemplo, seus documentos são específicos para um caso de uso, sua organização ou um setor? Uma boa maneira de determinar a especificidade do domínio é verificar se você pode encontrar as entidades e palavras-chave em seu conteúdo na Internet. Se você consegue, um modelo de inserção geral provavelmente também consegue.
Conteúdo geral ou não específico do domínio
Quando você escolher um modelo de inserção geral, comece com a tabela de classificação do Hugging Face. Obtenha classificações de modelos de inserção atualizadas. Avalie como os modelos funcionam com seus dados e comece com os modelos de classificação superior.
Conteúdo específico do domínio
Para conteúdo específico do domínio, determine se você pode usar um modelo específico do domínio. Por exemplo, seus dados podem estar no domínio biomédico, portanto, você pode usar o modelo BioGPT. Esse modelo de linguagem é pré-treinado em uma grande coleção de literatura biomédica. Você pode usá-lo para mineração e geração de texto biomédico. Se os modelos específicos do domínio estiverem disponíveis, avalie como esses modelos funcionam com seus dados.
Se você não tiver um modelo específico do domínio ou o modelo específico do domínio não tiver um bom desempenho, você poderá ajustar um modelo de inserção geral com seu vocabulário específico do domínio.
Importante
Para qualquer modelo escolhido, você precisa verificar se a licença atende às suas necessidades e o modelo fornece o suporte de idioma necessário.
Avaliar modelos de inserção
Para avaliar um modelo de inserção, visualize as inserções e avalie a distância entre os vetores de pergunta e trecho.
Visualizar inserções
Você pode usar bibliotecas, como t-SNE, para plotar os vetores de seus blocos e de sua pergunta em um gráfico X-Y. Em seguida, você pode determinar o quão longe as partes estão umas das outras e da pergunta. O grafo a seguir mostra vetores de trecho plotados. As duas setas próximas uma da outra representam dois vetores de trecho. A outra seta representa um vetor de pergunta. Você pode usar esta visualização para entender o quão distante a pergunta está dos blocos.
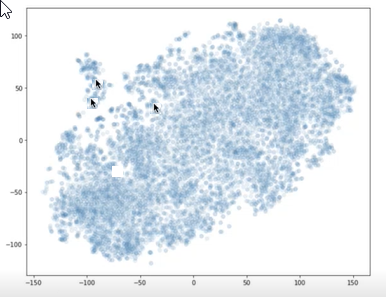
Duas setas apontam para pontos de plotagem próximos um do outro, e outra seta mostra um ponto de plotagem longe dos outros dois.
Calcular distâncias de inserção
Você pode usar um método programático para avaliar o quão bem seu modelo de inserção funciona com suas perguntas e partes. Calcule a distância entre os vetores de pergunta e os vetores de segmento. Você pode usar a distância euclidiana ou a distância de Manhattan.
Incorporando economia
Ao escolher um modelo de inserção, você deve navegar por uma compensação entre o desempenho e o custo. Modelos de inserção grandes geralmente têm melhor desempenho em conjuntos de dados de benchmarking. No entanto, o aumento do desempenho aumenta o custo. Vetores grandes exigem mais espaço em um banco de dados de vetor. Eles também exigem mais recursos computacionais e tempo para comparar inserções. Modelos de inserção pequenos geralmente têm menor desempenho nos mesmos parâmetros de comparação. Eles exigem menos espaço no banco de dados vetor e menos computação e tempo para comparar inserções.
Ao projetar seu sistema, você deve considerar o custo de inserção em termos de requisitos de armazenamento, computação e desempenho. Você deve validar o desempenho dos modelos por meio de experimentação. Os parâmetros de comparação disponíveis publicamente são principalmente conjuntos de dados acadêmicos e podem não se aplicar diretamente aos seus dados comerciais e casos de uso. Dependendo dos requisitos, você pode favorecer o desempenho sobre o custo ou aceitar uma compensação de desempenho bom o suficiente para um custo mais baixo.