Monitorar a qualidade e o uso de token de aplicativos prompt flow implantados
Importante
Os itens marcados (versão prévia) neste artigo estão atualmente em versão prévia pública. Essa versão prévia é fornecida sem um contrato de nível de serviço e não recomendamos isso para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
Os aplicativos de monitoramento implantados para produção são uma parte essencial do ciclo de vida do aplicativo de IA generativa. As alterações nos dados e no comportamento do consumidor podem influenciar seu aplicativo ao longo do tempo, resultando em sistemas desatualizados que afetam negativamente os resultados dos negócios e expõem as organizações a riscos de conformidade, econômicos e de reputação.
Observação
Para ter uma maneira aprimorada de executar o monitoramento contínuo de aplicativos implantados (além do prompt flow), considere usar a avaliação online da IA do Azure.
O monitoramento de IA do Azure para aplicativos de IA generativa permite monitorar seus aplicativos em produção para uso de token, qualidade de geração e métricas operacionais.
Integrações para monitorar uma implantação do prompt flow permitem que você:
- Colete dados de inferência de produção do aplicativo de prompt flow implantado.
- Aplique métricas de avaliação de IA responsável, como fundamentação, coerência, fluência e relevância, que são interoperáveis com métricas de avaliação de prompt flow.
- Monitore prompts, conclusão e uso total do token em cada implantação de modelo em seu prompt flow.
- Monitore as métricas operacionais, como contagem de solicitações, latência e taxa de erros.
- Use alertas pré-configurados e padrões para executar o monitoramento de maneira recorrente.
- Consuma o visualização de dados e configure o comportamento avançado no Estúdio de IA do Azure.
Pré-requisitos
Antes de seguir as etapas neste artigo, verifique se você tem os seguintes pré-requisitos:
Uma assinatura do Azure com uma forma de pagamento válida. Não há suporte para assinaturas gratuitas ou de avaliação do Azure para esse cenário. Caso você não tenha uma assinatura do Azure, crie uma conta paga do Azure para começar.
Um prompt flow pronto para implantação. Se você não tiver um, confira Desenvolver um prompt flow.
O RBAC do Azure (controle de acesso baseado em função) do Azure é usado para permitir acesso a operações no Estúdio de IA do Azure. Para executar as etapas neste artigo, sua conta de usuário deve receber a função de Desenvolvedor de IA do Azure no grupo de recursos. Para obter mais informações sobre permissões, confira Controle de acesso baseado em função no Estúdio de IA do Azure.
Requisitos para métricas de monitoramento
As métricas de monitoramento são geradas por certos modelos de linguagem GPT de última geração, configurados com instruções de avaliação específicas (modelos de prompt). Esses modelos atuam como modelos de avaliador para tarefas sequência a sequência. O uso dessa técnica para gerar métricas de monitoramento mostra resultados empíricos fortes e alta correlação com o julgamento humano em comparação com as métricas de avaliação de IA generativas padrão. Para obter mais informações sobre a avaliação de prompt flow, consulte Enviar teste em massa e avaliar um fluxo e Métricas de avaliação e de monitoramento para IA generativa.
Os modelos de GPT que geram métricas de monitoramento são os seguintes. Esses modelos GPT são compatíveis com o monitoramento e configurados como o seu recurso OpenAI do Azure:
- GPT-3.5-Turbo
- GPT-4
- GPT-4-32k
Métricas com suporte para monitoramento
As seguintes métricas são compatíveis com o monitoramento:
| Métrica | Descrição |
|---|---|
| Fundamentação | Avalia o quanto as respostas geradas pelo modelo se alinham com as informações dos dados de origem (contexto definido pelo usuário). |
| Relevância | Avalia até que ponto as respostas geradas pelo modelo são pertinentes e diretamente relacionadas às perguntas fornecidas. |
| Coerência | Avalia até que ponto as respostas geradas pelo modelo são logicamente consistentes e conectadas. |
| Fluência | Avalia a proficiência linguística da resposta prevista de uma IA gerativa. |
Mapeamento de nome de coluna
Ao criar seu fluxo, você precisa garantir que os nomes das colunas sejam mapeados. Os seguintes nomes de coluna de dados de entrada são necessárias para medir a qualidade de segurança de geração:
| Nome de coluna de entrada | Definição | Obrigatório/Opcional |
|---|---|---|
| Pergunta | O prompt original fornecido (também conhecido como "entradas" ou "pergunta") | Obrigatório |
| Resposta | A conclusão final da chamada à API retornada (também conhecida como "saídas" ou "resposta") | Obrigatório |
| Context | Todos os dados de contexto enviados para a chamada à API, juntamente com o prompt original. Por exemplo, se você espera obter resultados de pesquisa somente de sites ou determinadas fontes de informações certificadas, você pode definir este contexto nas etapas de avaliação. | Opcional |
Parâmetros necessários para métricas
Os parâmetros que são configurados em seu ativo de dados determinam quais métricas você pode produzir, de acordo com esta tabela:
| Metric | Pergunta | Resposta | Context |
|---|---|---|---|
| Coerência | Obrigatório | Obrigatório | - |
| Fluência | Obrigatório | Obrigatório | - |
| Fundamentação | Obrigatório | Obrigatória | Obrigatório |
| Relevância | Obrigatório | Obrigatória | Obrigatório |
Para obter mais informações sobre os requisitos de mapeamento de dados específicos para cada métrica, consulte Requisitos de métricas de consulta e resposta.
Configurar o monitoramento para o prompt flow
Para configurar o monitoramento para seu aplicativo de prompt flow, primeiro você precisa implantar seu aplicativo de prompt flow com a coleta de dados de inferência e, em seguida, você pode configurar o monitoramento para o aplicativo implantado.
Implantar seu aplicativo de prompt flow com a coleta de dados de inferência
Nesta seção, você aprenderá a implantar o prompt flow com a coleta de dados de inferência habilitada. Para obter informações detalhadas sobre como implantar o prompt flow, consulte Implantar um fluxo para inferência em tempo real.
Entre no Azure AI Studio.
Se você ainda não estiver em seu projeto, selecione-o.
Selecione Prompt flow na barra de navegação esquerda.
Selecione o prompt flow que você criou anteriormente.
Observação
Este artigo pressupõe que você já criou um prompt flow que está pronto para implantação. Se você não tiver um, confira Desenvolver um prompt flow.
Confirme se o fluxo é executado com sucesso e se as entradas e saídas necessárias estão configuradas para as métricas que você deseja avaliar.
Fornecer os parâmetros mínimos necessários (perguntas/entradas e respostas/saídas) fornece apenas duas métricas: coerência e fluência. Você deve configurar o fluxo conforme descrito na seção dos Requisitos para métricas de monitoramento. Este exemplo usa
question(Pergunta) echat_history(Contexto) como entradas de fluxo eanswer(Resposta) como a saída do fluxo.Selecione Implantar para começar a implantar seu fluxo.
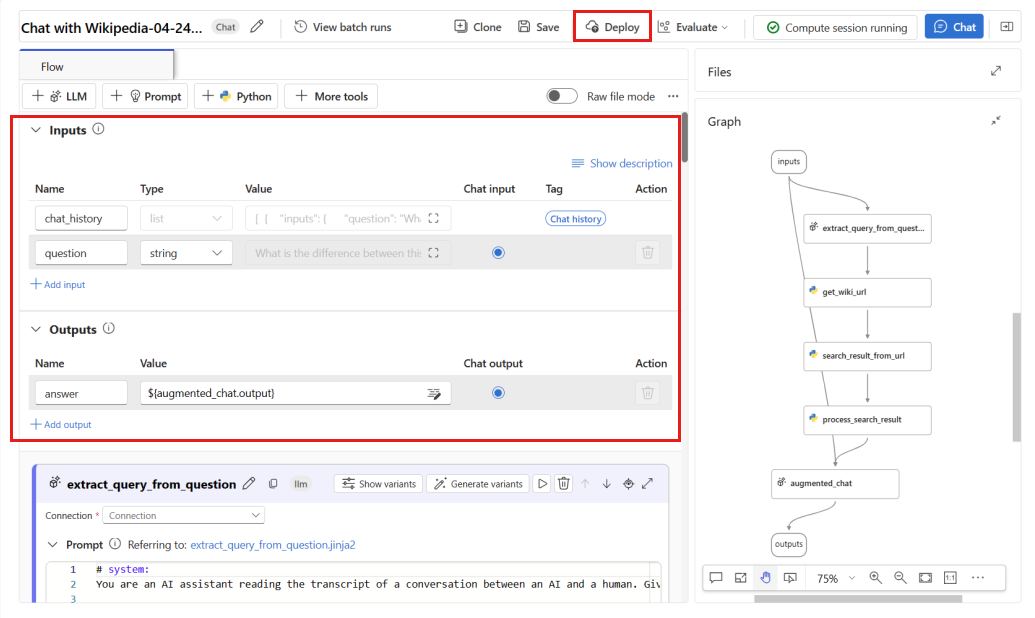
Na janela de implantação, verifique se a Coleta de dados de inferência está habilitada, o que coletará os dados de inferência do aplicativo para o Armazenamento de Blobs de forma ininterrupta. Essa coleta de dados é necessária para monitoramento.
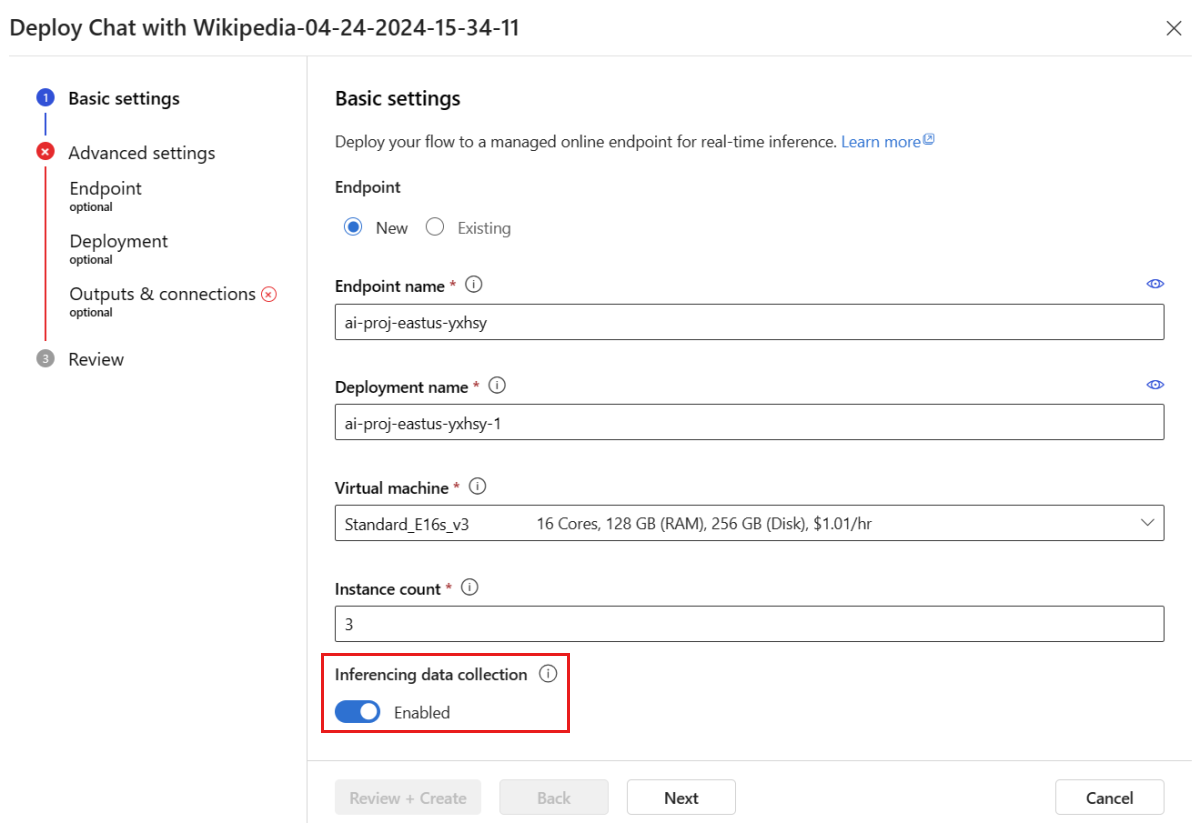
Siga as etapas na janela de implantação para concluir as Configurações avançadas.
Na página "Revisão", examine a configuração de implantação e selecione Criar para implantar seu fluxo.
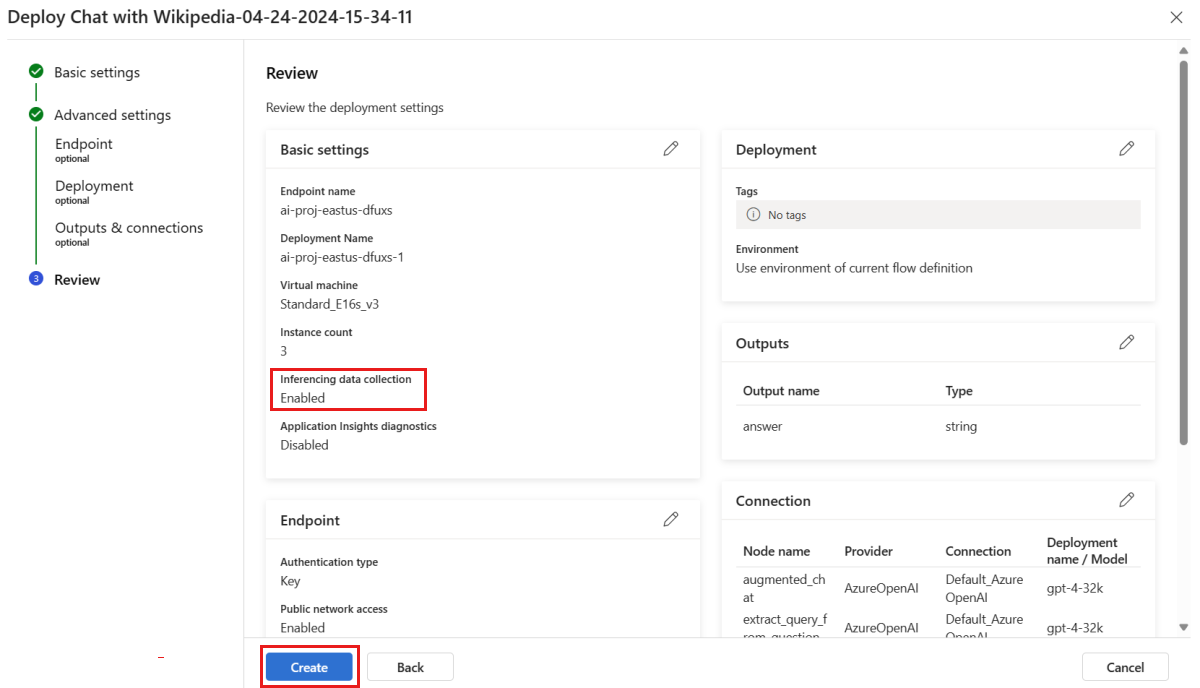
Observação
Por padrão, todas as entradas e saídas do aplicativo de prompt flow implantado são coletadas para o Armazenamento de Blobs. Como a implantação é invocada pelos usuários, os dados são coletados para serem usados pelo monitor.
Selecione a guia Testar na página de implantação e teste sua implantação para garantir que ela esteja funcionando corretamente.
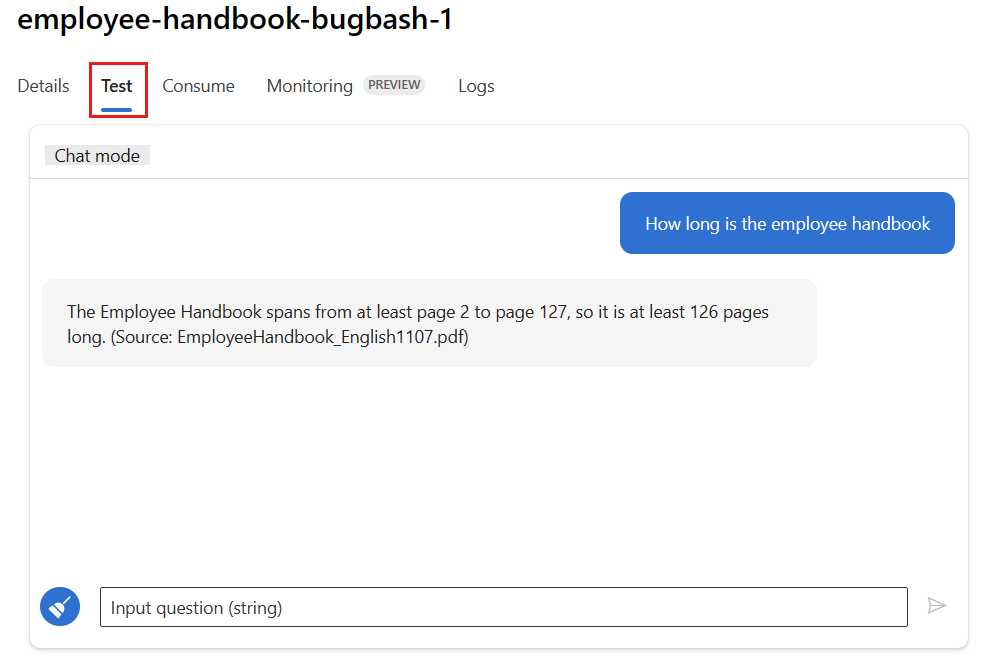
Observação
O monitoramento requer que pelo menos um ponto de dados venha de uma fonte diferente da guia Testar na implantação. É recomendável usar a API REST disponível na guia Consumir para enviar solicitações de exemplo para sua implantação. Para obter mais informações sobre como enviar solicitações de exemplo para sua implantação, consulte Criar uma implantação online.




Configurar monitoramento
Nesta seção, você aprenderá a configurar o monitoramento para seu aplicativo de prompt flow implantado.
Na barra de navegação esquerda, acesse Meus ativos>Modelos + pontos de extremidade.
Selecione a implantação de prompt flow que você criou.
Selecione Habilitar na caixa Habilitar monitoramento de qualidade de geração.
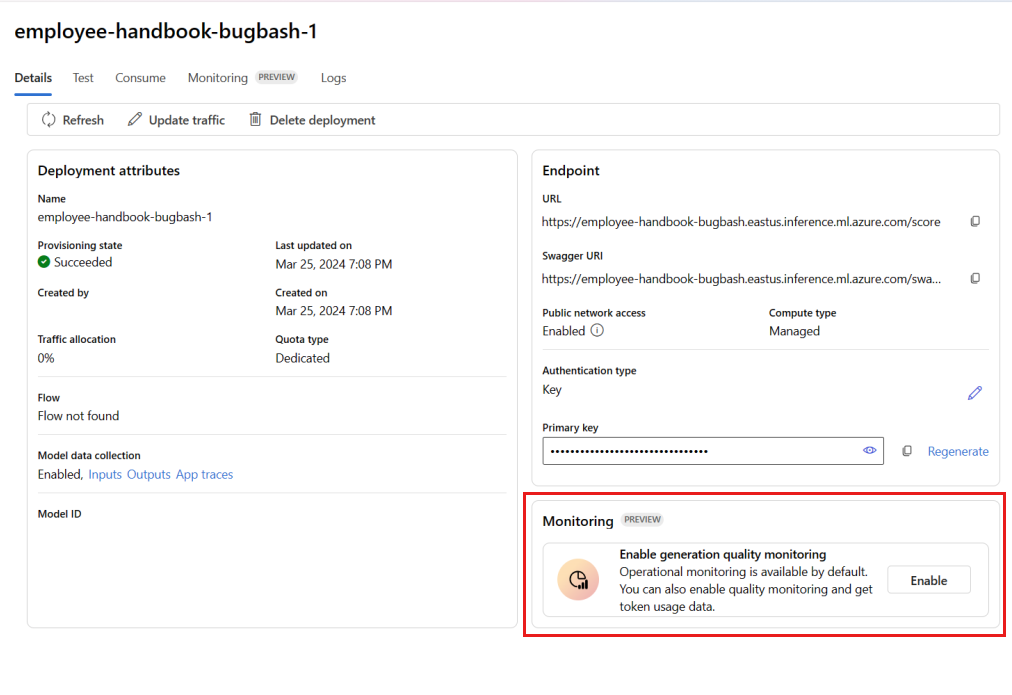
Comece a configurar o monitoramento selecionando as métricas desejadas.
Confirme se os nomes das colunas estão mapeados do fluxo conforme definido no Mapeamento de nome da coluna.
Selecione o Conexão OpenAI do Azure e Implantação que você gostaria de usar para executar o monitoramento do seu aplicativo de prompt flow.
Selecione Opções avançadas para ver mais opções a serem configuradas.
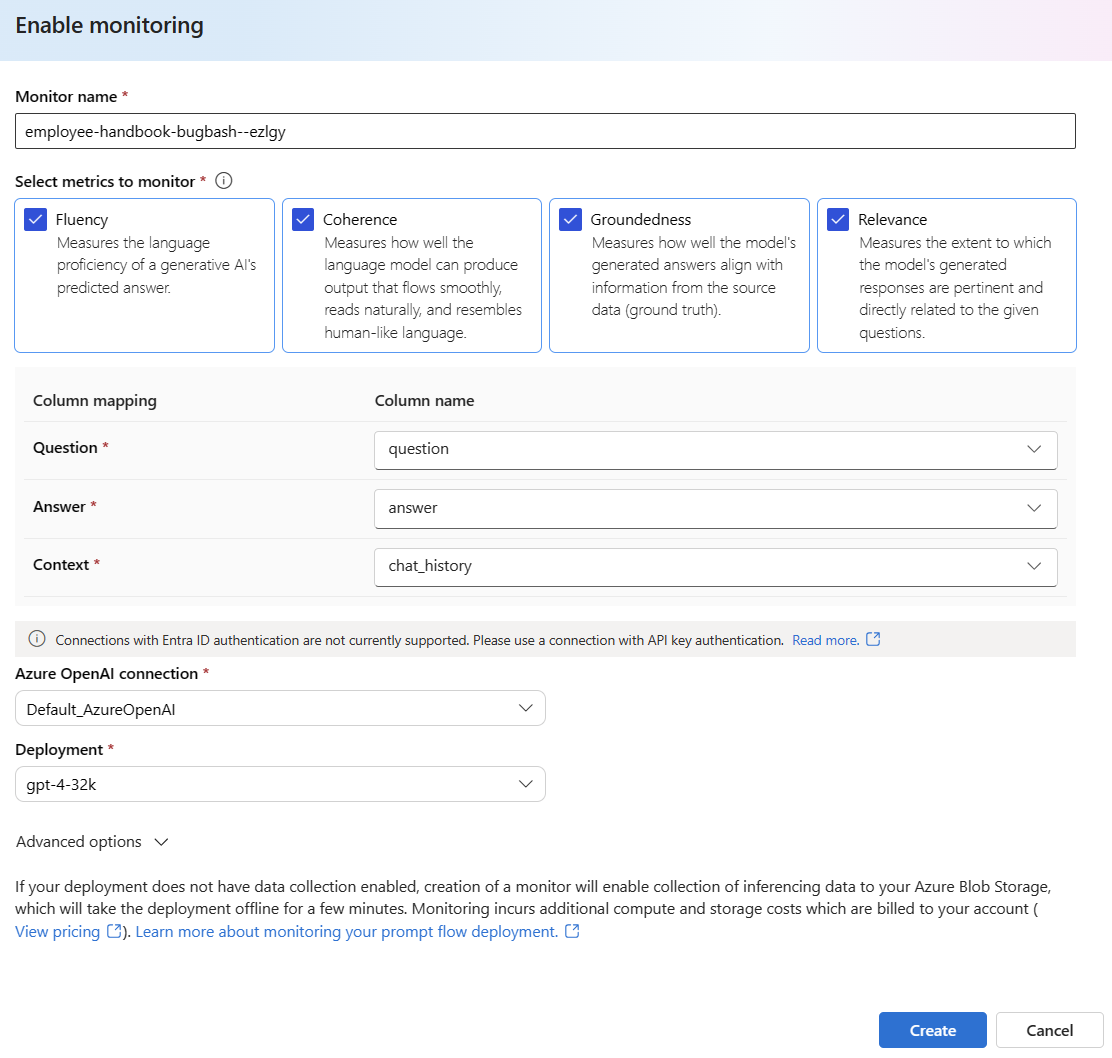
Ajuste a taxa de amostragem, os limites das métricas configuradas e especifique os endereços de email que devem receber alertas quando a pontuação média de uma determinada métrica ficar abaixo do limite.
Observação
Se a implantação não tiver a coleta de dados habilitada, a criação de um monitor habilitará a coleta de dados de inferência para o Armazenamento de Blobs do Azure, o que deixará a implantação offline por alguns minutos.
Selecione Criar para criar seu monitoramento.



Consumir resultados de monitoramento
Depois de criar o monitoramento, ele será executado diariamente para calcular as métricas de qualidade de geração e uso de token.
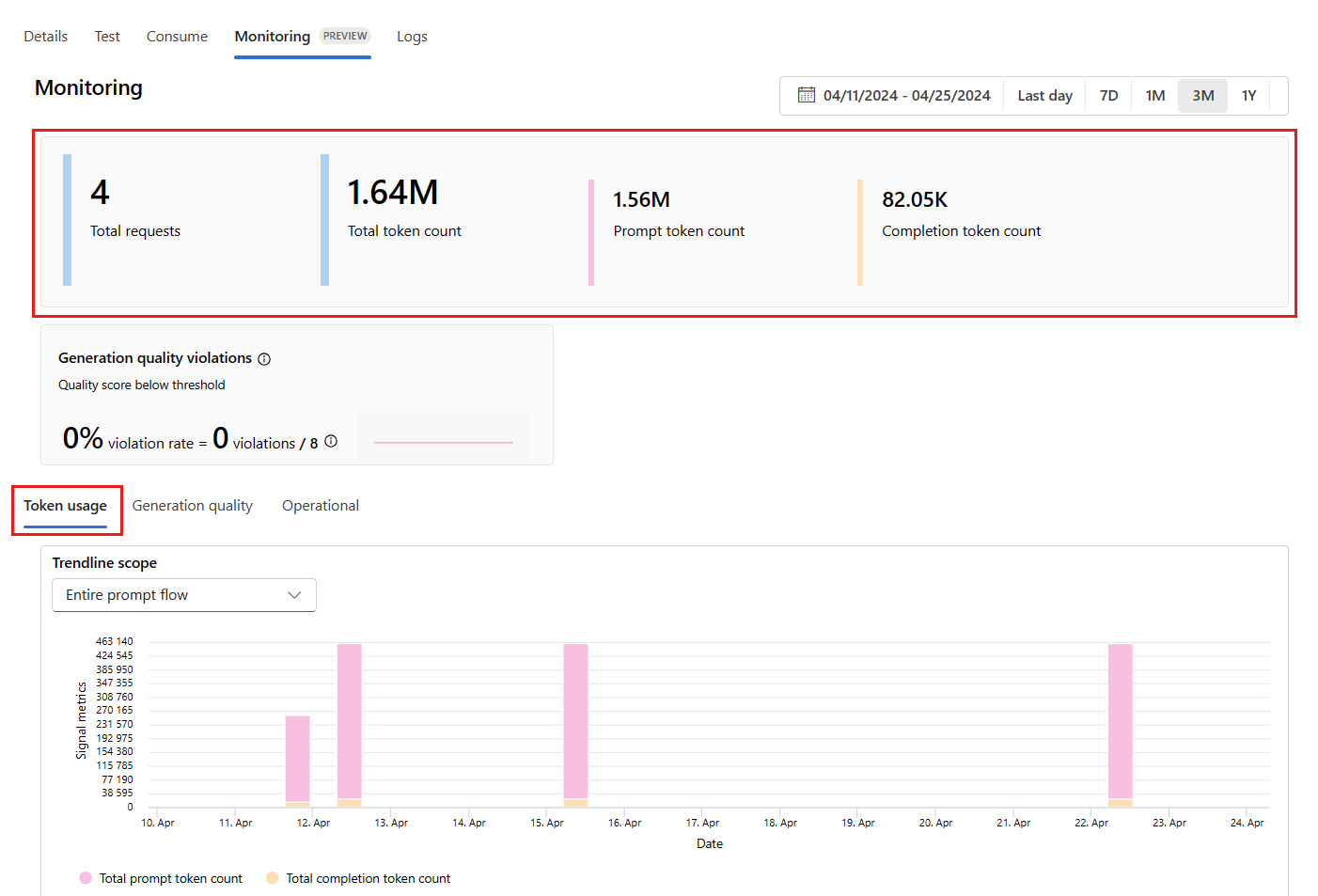
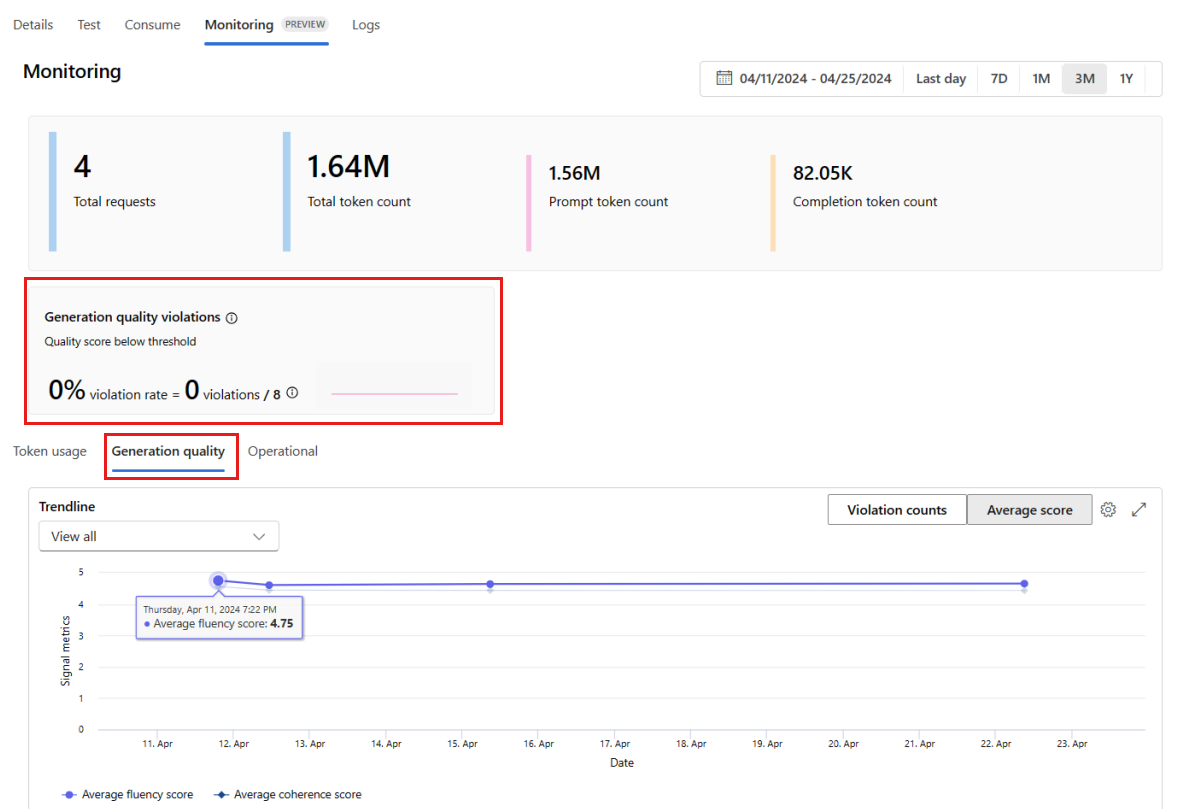
Vá para a guia Monitoramento (versão prévia) de dentro da implantação para exibir os resultados do monitoramento. Aqui, você verá uma visão geral dos resultados de monitoramento durante a janela de tempo selecionada. Você pode usar o seletor de data para alterar a janela de tempo dos dados que você está monitorando. As seguintes métricas estão disponíveis nesta visão geral:
- Contagem total de solicitações: o número total de solicitações enviadas para a implantação durante a janela de tempo selecionada.
- Contagem total de tokens: o número total de tokens enviados pela implantação durante a janela de tempo selecionada.
- Contagem de tokens de prompt: o número de tokens de prompt enviados pela implantação durante a janela de tempo selecionada.
- Contagem de tokens de conclusão: o número de tokens de conclusão enviados pela implantação durante a janela de tempo selecionada.
Veja as métricas na guia Uso do token (essa guia é selecionada por padrão). Aqui, você pode ver o uso do token do aplicativo ao longo do tempo. Você também pode ver a distribuição de tokens de prompt e de conclusão ao longo do tempo. Você pode alterar o Escopo da linha de tendência para monitorar todos os tokens em todo o aplicativo ou uso de token para uma implantação específica (por exemplo, gpt-4) usada em seu aplicativo.
Vá para a guia Qualidade de geração para monitorar a qualidade do aplicativo ao longo do tempo. As seguintes métricas são mostradas no gráfico de tempo:
- Contagem de violações: a contagem de violações de uma determinada métrica (por exemplo, Fluência) é a soma de violações na janela de tempo selecionada. Uma violação ocorre para uma métrica quando as métricas são calculadas (o padrão é diário) se o valor calculado da métrica estiver abaixo do valor limite definido.
- Pontuação média: a pontuação média de uma determinada métrica (por exemplo, Fluência) é a soma das pontuações de todas as instâncias (ou solicitações) divididas pelo número de instâncias (ou solicitações) na janela de tempo selecionada.
O cartão Violações de qualidade de geração mostra a taxa de violação na janela de tempo selecionada. A taxa de violação é o número de violações dividido pelo número total de possíveis violações. Você pode ajustar os limites de métricas nas configurações. Por padrão, as métricas são calculadas diariamente. Essa frequência também pode ser ajustada nas configurações.
Na guia Monitoramento (versão prévia), você também pode ver uma tabela abrangente de todas as solicitações de exemplo enviadas para a implantação durante a janela de tempo selecionada.
Observação
O monitoramento define a taxa de amostragem padrão em 10%. Isso significa que, se 100 solicitações forem enviadas para sua implantação, 10 serão amostradas e usadas para calcular as métricas de qualidade de geração. Você pode ajustar essa taxa de amostragem nas configurações.
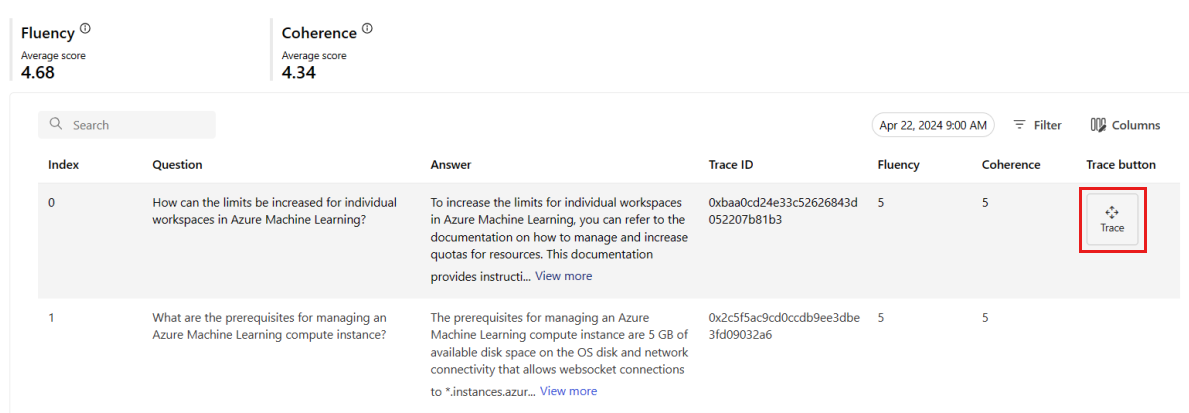
Selecione o botão Rastrear no lado direito de uma linha na tabela para ver os detalhes de rastreamento de uma determinada solicitação. Essa exibição fornece detalhes de rastreamento abrangentes para a solicitação ao seu aplicativo.
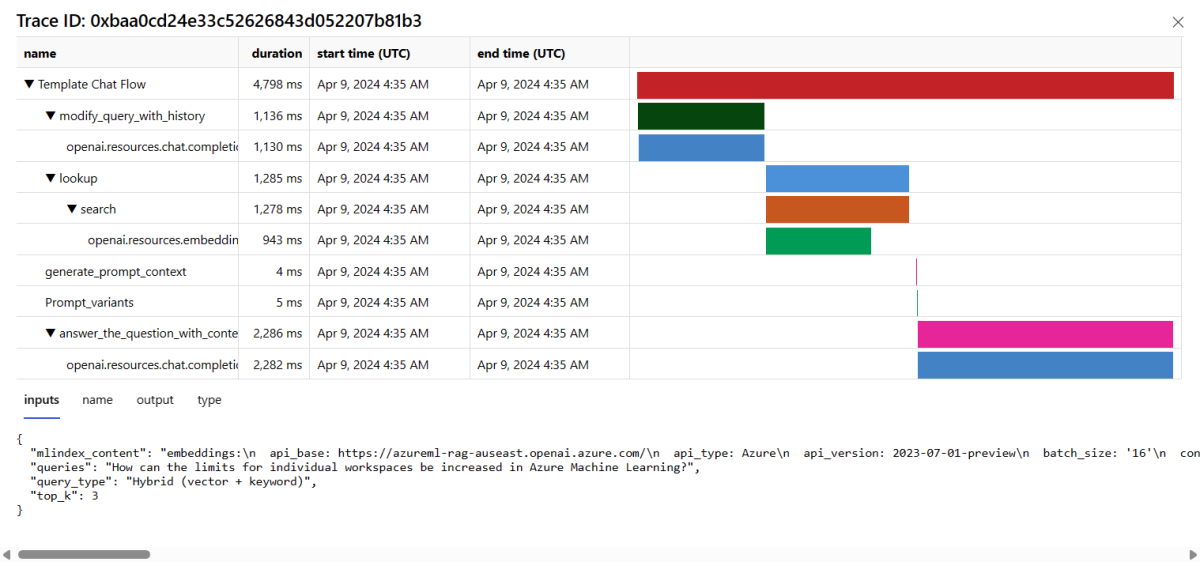
Feche o modo de exibição Rastreamento.
Vá para a guia Operacional para ver as métricas operacionais da implantação quase em tempo real. Damos suporte às seguintes métricas operacionais:
- Contagem de solicitações
- Latency
- Taxa de erros
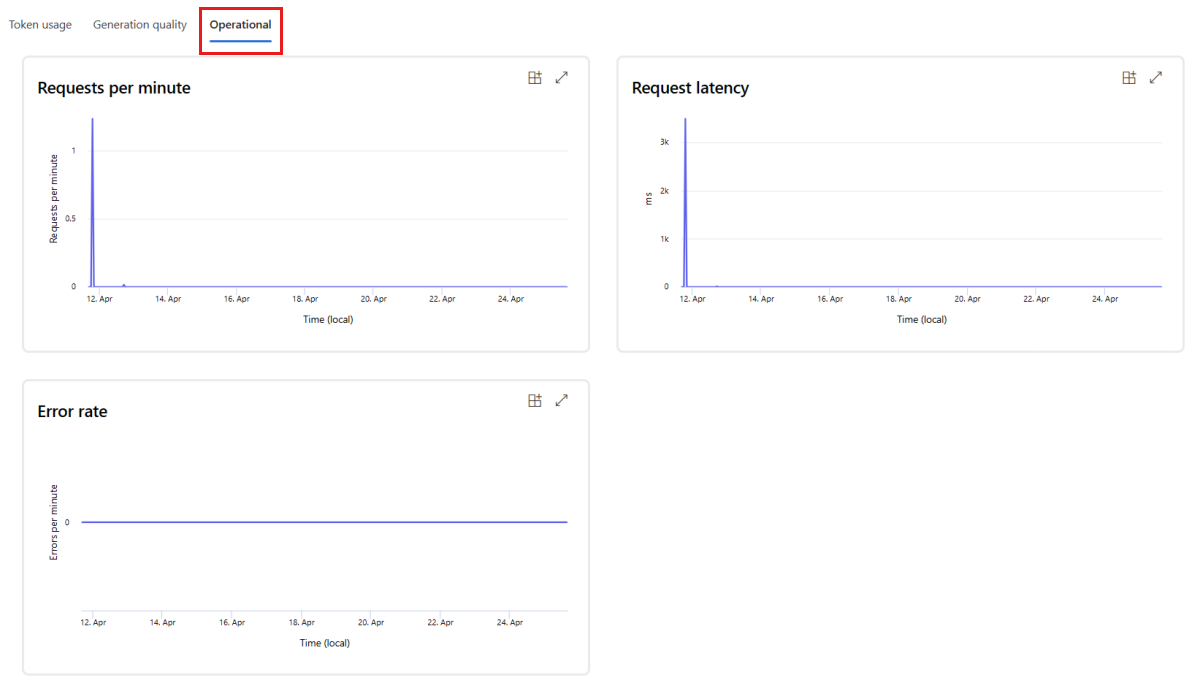





Os resultados na guia Monitoramento (versão prévia) da implantação fornecem insights para ajudar você a melhorar proativamente o desempenho do aplicativo de prompt flow.
Configuração avançada de monitoramento com o SDK v2
O monitoramento também dá suporte a opções de configuração avançadas com o SDK v2. Há suporte para os seguintes cenários:
Habilitar o monitoramento de uso de token
Se você tiver interesse apenas em habilitar o monitoramento de uso de token do seu aplicativo de prompt flow implantado, poderá adaptar o seguinte script ao seu cenário:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Habilitar o monitoramento da qualidade de geração
Se você tiver interesse apenas em habilitar o monitoramento de qualidade de geração do seu aplicativo de prompt flow implantado, poderá adaptar o seguinte script ao seu cenário:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your AI Studio project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Depois de criar o monitoramento do SDK, você pode consumir os resultados de monitoramento no Estúdio de IA.
Conteúdo relacionado
- Saiba mais sobre o que você pode fazer no Estúdio de IA do Azure.
- Obtenha respostas às perguntas frequentes no artigo Perguntas Frequentes sobre IA do Azure.