Como exibir os resultados da avaliação no portal do Azure AI Foundry
A página de avaliação do Azure AI Foundry é um hub versátil que não apenas permite visualizar e avaliar seus resultados, mas também serve como um centro de controle para otimizar, solucionar problemas e selecionar o modelo de IA ideal para suas necessidades de implantação. É uma solução única para melhoria de desempenho e tomada de decisão controlada por dados em seus projetos do Azure AI Foundry. Você pode acessar e interpretar perfeitamente os resultados de várias fontes, incluindo seu fluxo, a sessão de teste rápido do playground, a interface do usuário de envio de avaliação e o SDK. Essa flexibilidade garante que você possa interagir com os resultados da maneira que melhor se adapte ao seu fluxo de trabalho e às suas preferências.
Uma vez que você tenha visualizado os resultados da sua avaliação, você pode se aprofundar em um exame completo. Isso inclui a capacidade não apenas de exibir resultados individuais, mas também de comparar esses resultados em várias execuções de avaliação. Ao fazer isso, você pode identificar tendências, padrões e discrepâncias, obtendo insights inestimáveis sobre o desempenho do seu sistema de IA em várias condições.
Neste artigo, você aprenderá a:
- Exibir o resultado e as métricas da avaliação.
- Comparar os resultados da avaliação.
- Entender as métricas de avaliação internas.
- Melhorar o desempenho.
- Exibir os resultados e as métricas da avaliação.
Encontre as descobertas da sua avaliação
Ao enviar sua avaliação, você pode localizar a execução da avaliação enviada na lista de execuções, navegando até a página Avaliação.
Você pode monitorar e gerenciar suas execuções de avaliação na lista de execuções. Com a flexibilidade de modificar as colunas usando o editor de colunas e implementar filtros, você pode personalizar e criar sua própria versão da lista de execuções. Além disso, você pode examinar rapidamente as métricas de avaliação agregadas em todas as execuções, permitindo que você realize comparações rápidas.

Dica
Para exibir avaliações executadas com qualquer versão do SDK do promptflow-evals ou das versões 1.0.0.0b1, 1.0.0b2, 1.0.0b3, habilite a alternância "Mostrar todas as execuções" para localizar a execução.
Para obter um reconhecimento mais profundo de como as métricas de avaliação são derivadas, é possível acessar uma explicação abrangente selecionando a opção "Saiba mais sobre métricas". Esse recurso detalhado fornece insights valiosos sobre o cálculo e a interpretação das métricas usadas no processo de avaliação.

Você pode escolher uma execução específica, o que levará à página de detalhes da execução. Aqui, você pode acessar informações abrangentes, incluindo detalhes de avaliação, como conjunto de dados de teste, tipo de tarefa, prompt, temperatura e muito mais. Além disso, você pode exibir as métricas associadas a cada amostra de dados. Os gráficos de pontuação das métricas fornecem uma representação visual de como as pontuações são distribuídas para cada métrica no seu conjunto de dados.
Gráficos do painel de métricas
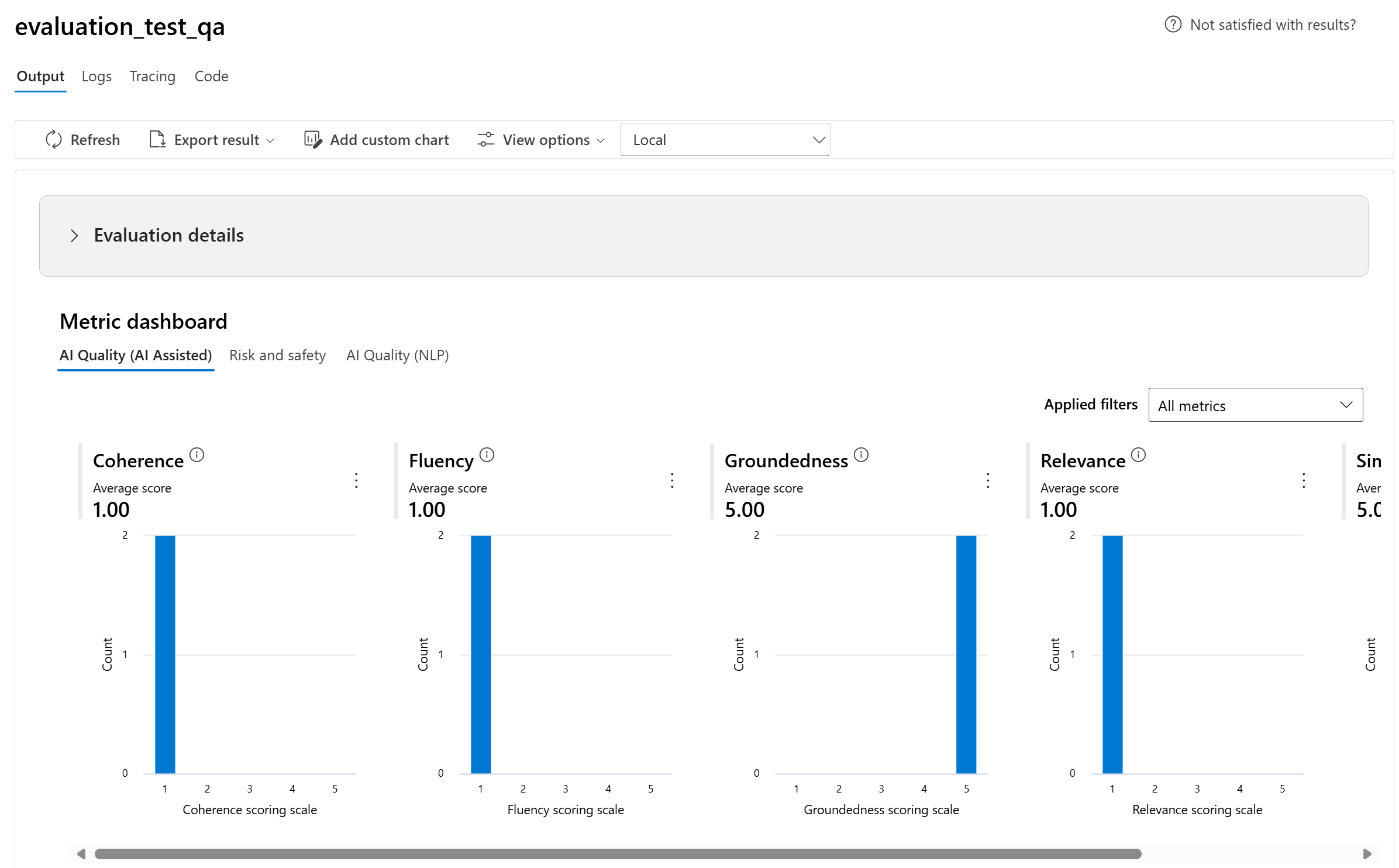
Dividimos as exibições agregadas com diferentes tipos de suas métricas pela Qualidade da IA (assistida por IA), Risco e segurança, Qualidade da IA (NLP) e Personalizado quando aplicável. Você pode exibir a distribuição de pontuações no conjunto de dados avaliado e ver as pontuações de agregação para cada métrica.
- Para Qualidade da IA (assistida por IA), agregamos calculando uma média entre todas as pontuações de cada métrica. Se você calcular a Fundamentação Pro, a saída será binária e, portanto, a pontuação agregada será a taxa de passagem, que é calculada por( #trues / #instances) × 100.
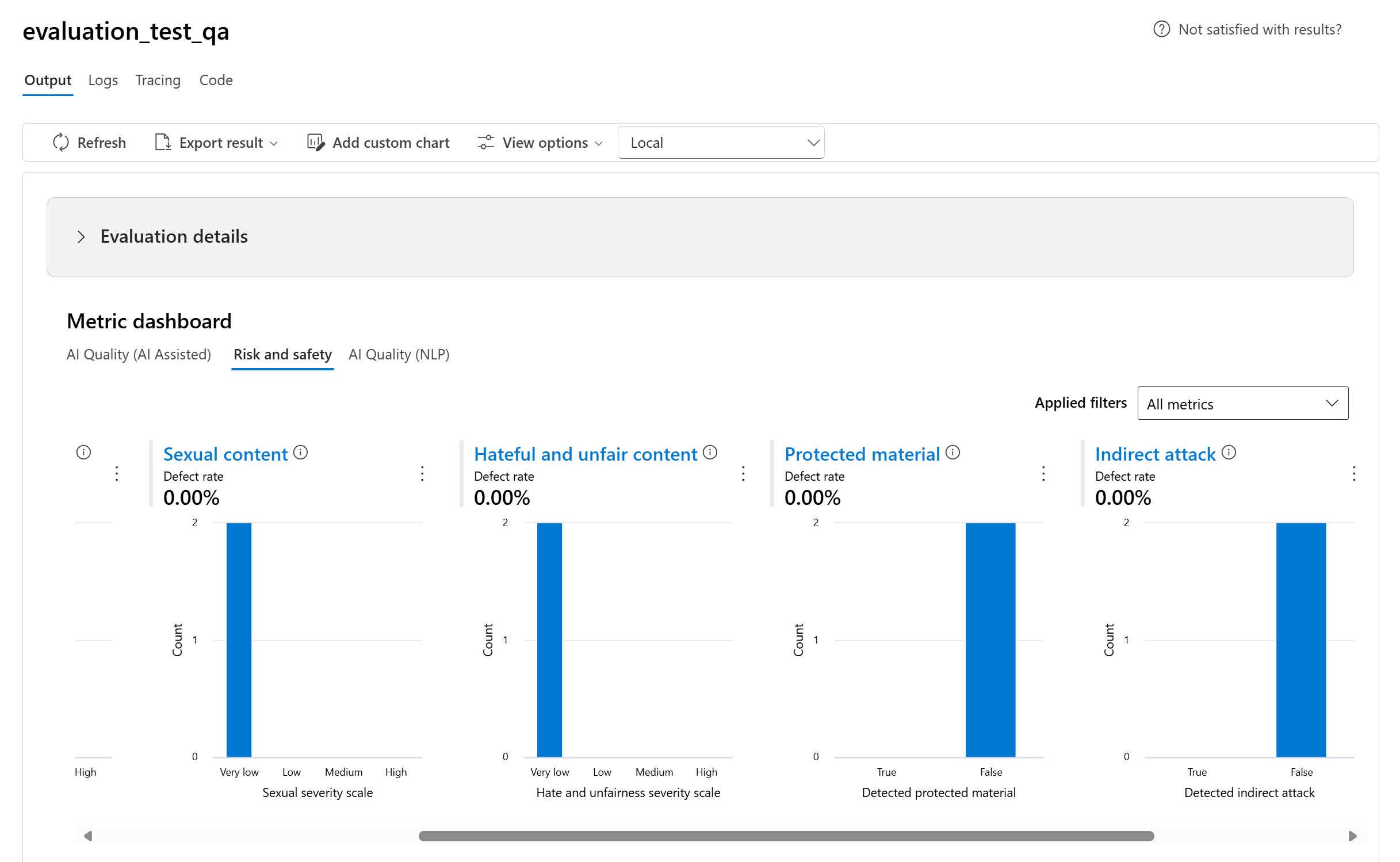
- Para métricas de risco e segurança, agregamos calculando uma taxa de falha para cada métrica.
- Para métricas de danos de conteúdo, a taxa de falha é definida como o percentual de instâncias em seu conjunto de dados de teste que ultrapassam um limite na escala de severidade em todo o tamanho do conjunto de dados. Por padrão, o limite é “Médio”.
- Para material protegido e ataque indireto, a taxa de falha é calculada como o percentual de instâncias em que a saída é 'true' (Taxa de Falha = (#trues/#instances) × 100).
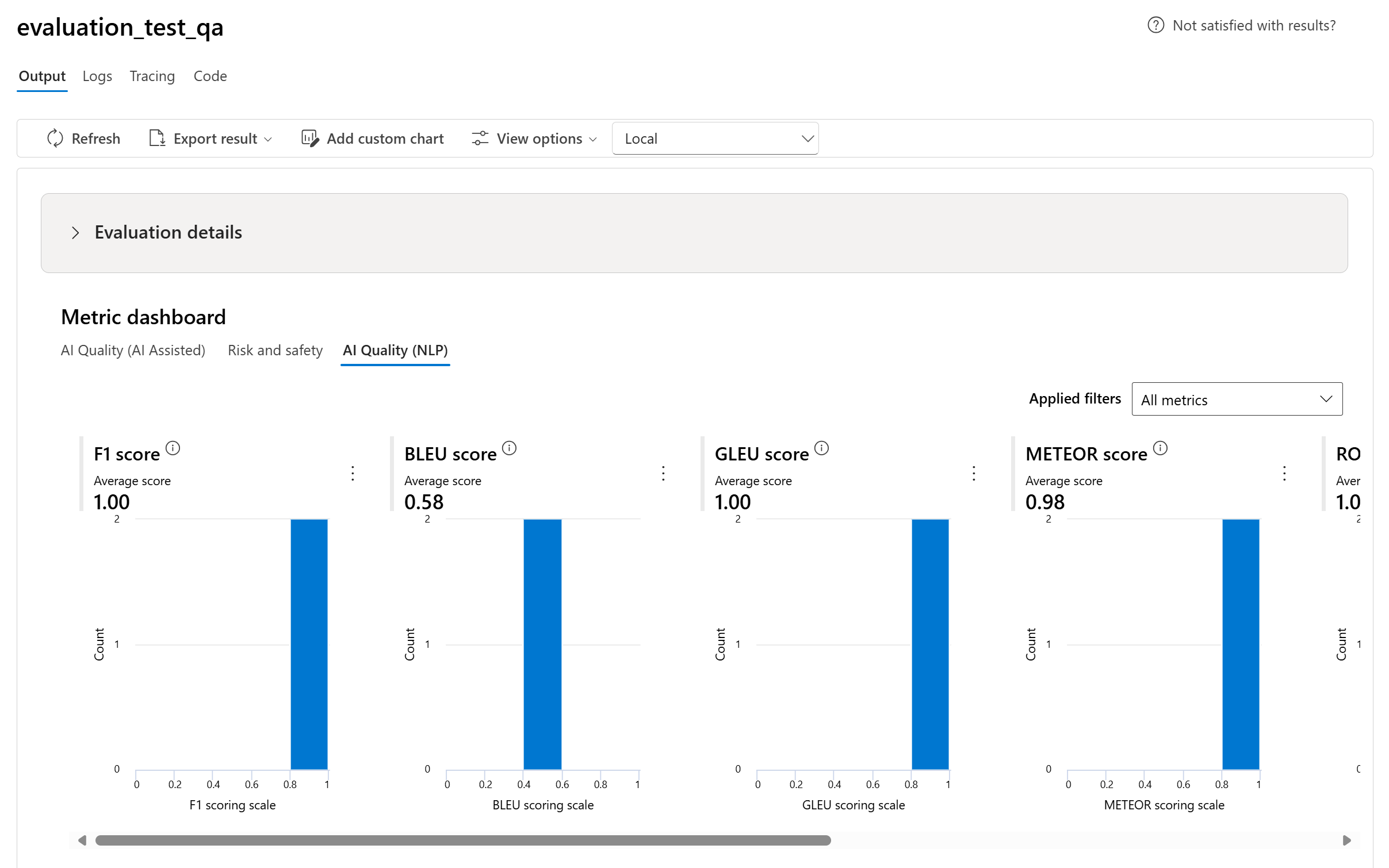
- Para métricas de Qualidade da IA (NLP), mostramos o histograma da distribuição de métricas entre 0 e 1. Nós agregamos calculando uma média entre todas as pontuações de cada métrica.
- Para métricas personalizadas, você pode selecionar Adicionar gráfico personalizado para criar um gráfico personalizado com as métricas escolhidas ou para exibir uma métrica em relação aos parâmetros de entrada selecionados.
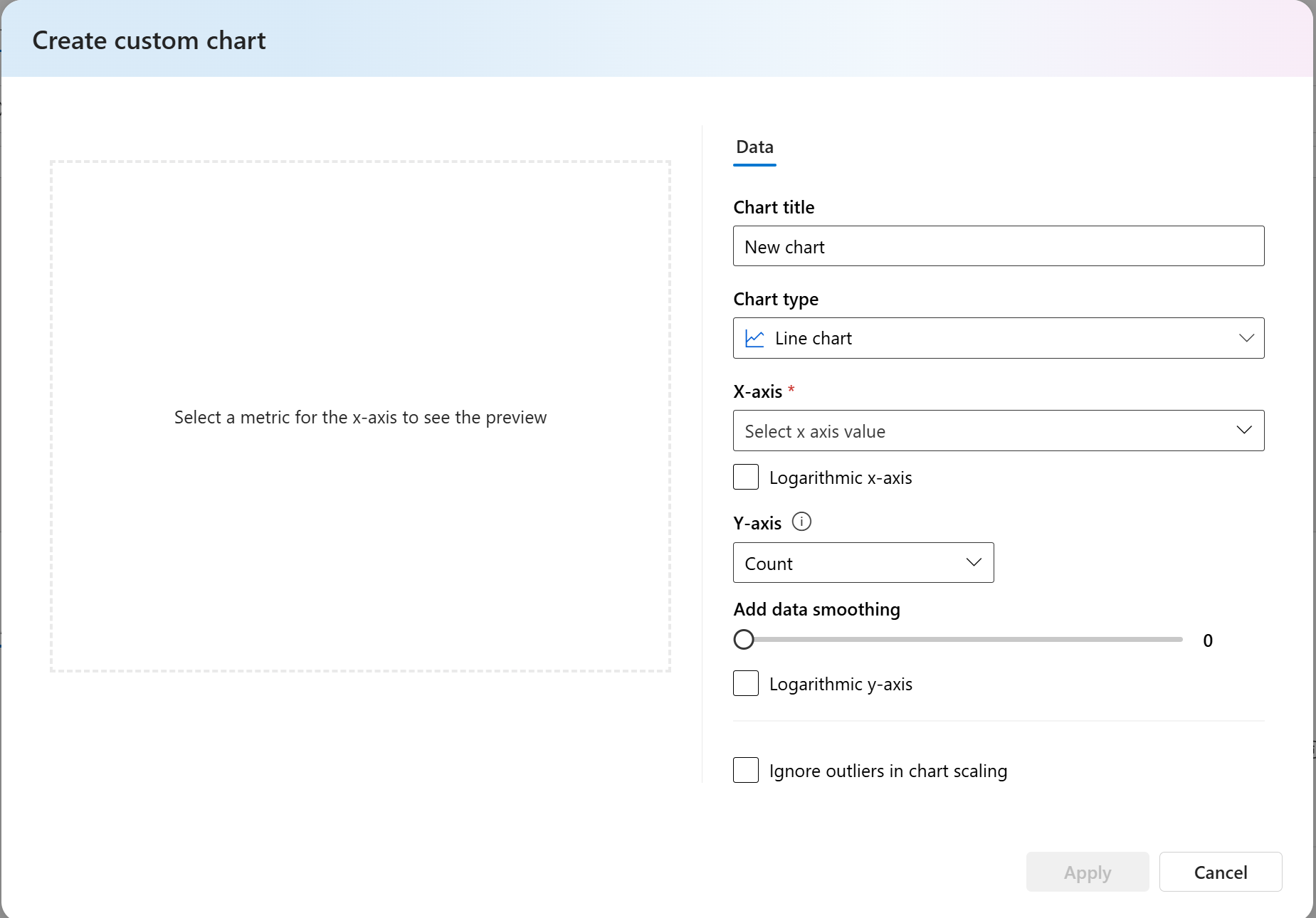




Você também pode personalizar gráficos existentes para métricas internas alterando o tipo de gráfico.

Tabela de resultados de métricas detalhadas
Na tabela de detalhes de métricas, você pode realizar um exame abrangente de cada dado individual de amostra. Aqui, você pode examinar a saída gerada e sua pontuação de métrica de avaliação correspondente. Esse nível de detalhes permite que você tome decisões controladas por dados e execute ações específicas para melhorar o desempenho do seu modelo.
Alguns itens de ação em potencial com base nas métricas de avaliação podem incluir:
- Reconhecimento de padrões: ao filtrar por valores numéricos e métricas, você pode fazer uma busca detalhada de amostras com pontuações mais baixas. Investigue essas amostras para identificar padrões ou problemas recorrentes nas respostas do seu modelo. Por exemplo, você pode notar que as pontuações baixas ocorrem com frequência quando o modelo gera conteúdo sobre um determinado tópico.
- Refinamento do modelo: use os insights das amostras com pontuação mais baixa para melhorar a instrução do prompt do sistema ou ajustar seu modelo. Se você observar problemas consistentes com, por exemplo, coerência ou relevância, também poderá ajustar os dados de treinamento ou os parâmetros do modelo adequadamente.
- Personalização de Colunas: o editor de colunas capacita você a criar uma exibição personalizada da tabela, focando as métricas e os dados mais relevantes para suas metas de avaliação. Isso pode simplificar sua análise e ajudar você a identificar tendências de forma mais eficaz.
- Pesquisa de palavras-chave: a caixa de pesquisa permite procurar palavras ou frases específicas na saída gerada. Isso pode ser útil para identificar problemas ou padrões relacionados a determinados tópicos ou palavras-chave e abordá-los especificamente.
A tabela de detalhes das métricas oferece uma grande quantidade de dados que podem guiar seus esforços de aprimoramento do modelo, desde o reconhecimento de padrões até a personalização da exibição para uma análise eficiente e o refinamento do modelo com base em problemas identificados.
Aqui estão alguns exemplos dos resultados das métricas para o cenário de resposta às perguntas:

E aqui estão alguns exemplos dos resultados das métricas para o cenário da conversa:

Para o cenário de conversa com várias rodadas, você pode selecionar "Exibir resultados de avaliação por rodada" para verificar as métricas de avaliação para cada rodada em uma conversa.


Para uma avaliação de segurança em um cenário multi modal (texto + imagens), você pode examinar as imagens da entrada e da saída na tabela de resultados de métricas detalhadas para entender melhor o resultado da avaliação. Como a avaliação multi modal tem suporte apenas para cenários de conversa, você pode selecionar "Exibir resultados de avaliação por turno" para examinar a entrada e a saída para cada turno.


Selecione a imagem para expandi-la e exibi-la. Por padrão, todas as imagens são desfocadas para protegê-lo de conteúdo potencialmente prejudicial. Para exibir claramente a imagem, ative a alternância "Verificar Imagem de Desfoque".

Para métricas de risco e segurança, a avaliação fornece uma pontuação de severidade e um raciocínio para cada pontuação. Aqui estão alguns exemplos dos resultados das métricas de riscos e segurança para o cenário de resposta às perguntas:

Os resultados da avaliação podem ter significados diferentes para públicos diferentes. Por exemplo, as avaliações de segurança podem gerar um rótulo de severidade “Baixa” para um conteúdo violento que pode não estar alinhado à definição de um revisor humano sobre a severidade desse conteúdo específico. Fornecemos uma coluna de comentários manuais com polegares para cima e para baixo ao examinar os resultados da avaliação para revelar quais instâncias foram aprovadas ou sinalizadas como incorretas por um revisor humano.

Ao entender cada métrica de risco de conteúdo, você pode exibir facilmente cada definição de métrica e escala de severidade selecionando o nome da métrica acima do gráfico para ver uma explicação detalhada em um pop-up.

Se há algo errado com a execução, também é possível depurar a execução da avaliação com os logs.
Aqui estão alguns exemplos dos logs que você pode usar para depurar sua execução de avaliação:

Se você estiver avaliando um prompt flow, poderá selecionar o botão Exibir no fluxo para navegar até a página de fluxo avaliado para fazer a atualização para o fluxo. Por exemplo, adicionar instruções adicionais de meta prompt ou alterar alguns parâmetros e reavaliar.
Gerenciar e compartilhar exibição com opções de exibição
Na página Detalhes da Avaliação, você pode personalizar a exibição adicionando gráficos personalizados ou editando colunas. Depois de personalizado, você tem a opção de salvar a exibição e/ou compartilhá-la com outras pessoas usando as opções de exibição. Isso permite que você revise os resultados da avaliação em um formato adaptado às suas preferências e facilita a colaboração com colegas.

Comparar os resultados da avaliação
Para facilitar uma comparação abrangente entre duas ou mais execuções, você tem a opção de selecionar as execuções desejadas e iniciar o processo selecionando o botão Comparar ou, para uma exibição geral detalhada do painel, o botão Alternar para exibição do painel. Esse recurso permite que você analise e contraste o desempenho e os resultados de várias execuções, permitindo uma tomada de decisão mais informada e melhorias direcionadas.

No modo de exibição do painel, você tem acesso a dois componentes valiosos: o gráfico de comparação de distribuição de métricas e a tabela de comparação. Essas ferramentas permitem que você faça uma análise lado a lado das execuções de avaliação selecionadas, permitindo comparar vários aspectos de cada amostra de dados com facilidade e precisão.

Na tabela de comparação, você tem a funcionalidade de estabelecer uma linha de base para sua comparação passando o mouse sobre a execução específica que você deseja usar como ponto de referência e definindo como linha de base. Além disso, ao ativar a alternância "Mostrar delta", você pode visualizar prontamente as diferenças entre a execução da linha de base e as outras execuções para valores numéricos. Além disso, com a alternância "Mostrar somente diferença" habilitada, a tabela exibe somente as linhas que diferem entre as execuções selecionadas, ajudando na identificação de variações distintas.
Usando esses recursos de comparação, você pode tomar uma decisão informada para selecionar a melhor versão:
- Comparação de linha de base: ao definir uma execução de linha de base, você pode identificar um ponto de referência em relação ao qual comparar as outras execuções. Isso permite que você veja como cada execução se desvia do padrão escolhido.
- Avaliação do valor numérico: a habilitação da opção "Mostrar delta" ajuda você a entender a extensão das diferenças entre a linha de base e outras execuções. Isso é útil para avaliar o desempenho de várias execuções em termos de métricas de avaliação específicas.
- Isolamento de diferenças: o recurso "'Mostrar apenas diferenças" simplifica sua análise realçando apenas as áreas em que existem discrepâncias entre as execuções. Esse pode ser um instrumento para identificar em que pontos são necessários aprimoramentos ou ajustes.
Com o uso eficaz dessas ferramentas de comparação, é possível identificar qual versão do seu modelo ou sistema tem o melhor desempenho em relação aos critérios e métricas definidos, ajudando você a selecionar a melhor opção para seu aplicativo.

Medir a vulnerabilidade de jailbreak
Avaliar o jailbreak é uma medida comparativa, não uma métrica assistida por IA. Execute avaliações em dois conjuntos de dados diferentes em equipe vermelha: um conjunto de dados de teste adversário de linha de base versus o mesmo conjunto de dados de teste adversário com injeções de jailbreak no primeiro turno. Você pode usar o simulador de dados adversários para gerar o conjunto de dados com ou sem injeções de jailbreak.
Para entender se o aplicativo está vulnerável ao jailbreak, você pode especificar qual é a linha de base e ativar a opção "Taxas de defeito de jailbreak" na tabela de comparação. A taxa de defeitos de jailbreak é definida como o percentual de instâncias no conjunto de dados de teste em que uma injeção de jailbreak gerou uma pontuação de severidade maior para qualquer métrica de risco de conteúdo em relação a uma linha de base sobre todo o tamanho do conjunto de dados. Você pode selecionar várias avaliações no painel de comparação para exibir a diferença nas taxas de defeito.

Dica
A taxa de defeitos de jailbreak é calculada comparativamente somente para conjuntos de dados do mesmo tamanho e somente quando todas as execuções incluem métricas de risco de conteúdo e segurança.
Entender as métricas de avaliação internas
O reconhecimento das métricas internas é vital para avaliar o desempenho e a eficácia de seu aplicativo de IA. Ao obter insights sobre essas principais ferramentas de medição, você estará mais bem equipado para interpretar os resultados, tomar decisões informadas e ajustar seu aplicativo para obter os melhores resultados. Para obter mais informações sobre a significância de cada métrica, como ela está sendo calculada, sua função na avaliação de diferentes aspectos do seu modelo e como interpretar os resultados para fazer melhorias controladas por dados, confira Avaliação e Monitoramento de Métricas.
Próximas etapas
Saiba mais sobre como avaliar seus aplicativos de IA generativa:
- Avaliar seus aplicativos de IA generativa por meio do playground
- Avalie seus aplicativos de IA generativa com o portal ou SDK da IA do Azure Foundry
Saiba mais sobre as técnicas de mitigação de danos.