Configurar o loop de aprendizado do Personalizador
Importante
A partir de 20 de setembro de 2023, não será mais possível criar novos recursos do Personalizador. O serviço Personalizador está sendo desativado no dia 1º de outubro de 2026.
A configuração do serviço inclui como o serviço trata as recompensas, com que frequência o serviço faz explorações, com que frequência o modelo é treinado novamente e quantos dados são armazenados.
Configure o loop de aprendizado na página Configuração, no portal do Azure para esse recurso Personalizador.
Planejando mudanças de configuração
Como algumas mudanças de configuração redefinem o seu modelo, você deve planejar as suas mudanças.
Se você planeja usar o modo Aprendiz, não se esqueça de analisar a configuração do Personalizador antes de alternar para o modo Aprendiz.
Configurações que incluem a redefinição do modelo
As ações a seguir acionam um novo treinamento do modelo usando os dados disponíveis até os últimos dois dias.
- Recompensa
- Exploração
Para remover todos os seus dados, use a página Configurações de modelo e aprendizado.
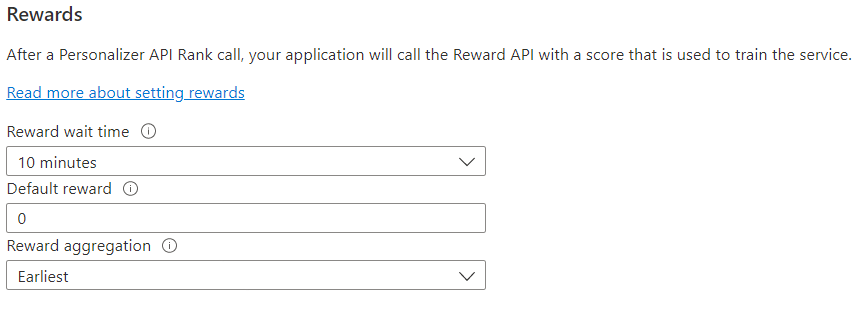
Configurar recompensas para o loop de comentários
Configure o serviço para o uso de recompensas do seu loop de aprendizado. As mudanças nos valores a seguir redefinem o modelo atual do Personalizador e o treinam novamente com os dois últimos dias de dados.
| Valor | Finalidade |
|---|---|
| Tempo de espera de recompensa | Define o período de tempo durante o qual o Personalizador coletará valores de recompensa para uma chamada de Classificação, a partir do momento em que ela ocorre. Esse valor é definido perguntando: "Por quanto tempo o Personalizador deve aguardar chamadas de recompensas?" Qualquer recompensa que chegar após essa janela será registrada, mas não será usada para aprendizado. |
| Recompensa padrão | Se nenhuma chamada de recompensa for recebida pelo Personalizador durante a janela de Tempo de Espera de Recompensa associada a uma Chamada de classificação, o Personalizador atribuirá a Recompensa Padrão. Por padrão e na maioria dos cenários, a recompensa padrão é 0 (zero). |
| Agregação de recompensas | Se várias recompensas forem recebidas para a mesma chamada à API de Classificação, este método de agregação será usado: soma ou mais anterior. A opção "mais anterior" escolhe a pontuação mais anterior recebida e descarta o restante. Isso é útil se você deseja uma recompensa exclusiva entre chamadas possivelmente duplicadas. |
Depois de mudar esses valores, escolha Salvar.
Configurar a exploração para permitir que o loop de aprendizado se adapte
A Personalização pode descobrir novos padrões e se adaptar às mudanças do comportamento do usuário ao longo do tempo, explorando alternativas em vez de usar a previsão do modelo treinado. O valor de Exploração determina qual percentual de chamadas de Classificação são respondidas com a exploração.
As mudanças nesse valor redefinem o modelo atual do Personalizador e o treinam novamente com os dois últimos dias de dados.
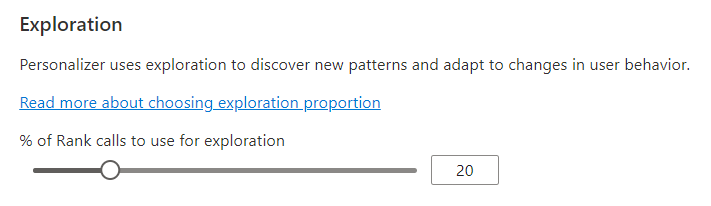
Depois de mudar esse valor, escolha Salvar.
Configurar a frequência de atualização do modelo para o treinamento de modelos
A Frequência de atualização do modelo define a frequência em que o modelo é treinado.
| Configuração de frequência | Finalidade |
|---|---|
| 1 minuto | Frequências de atualização de um minuto são úteis ao depurar o código de um aplicativo usando o Personalizador, executar demonstrações ou testar interativamente os aspectos de machine learning. |
| 15 minutos | As altas frequências de atualização do modelo são úteis em situações em que você deseja acompanhar de perto as mudanças no comportamento do usuário. Os exemplos incluem sites executados em notícias em tempo real, conteúdo viral ou licitação de produtos ao vivo. Você pode usar uma frequência de 15 minutos nesses cenários. |
| 1 hora | Na maioria dos casos de uso, uma frequência de atualização mais baixa é eficaz. |
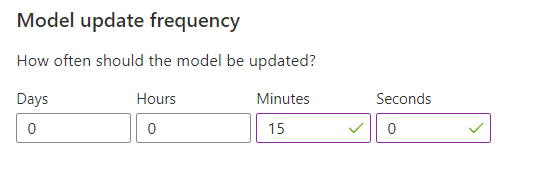
Depois de mudar esse valor, escolha Salvar.
Retenção de dados
O Período de retenção de dados define por quantos dias o Personalizador mantém os logs de dados. Os logs de dados passados são necessários para realizar avaliações offline, que são usados para medir a eficácia do Personalizador e otimizar a Política de Aprendizado.
Depois de mudar esse valor, escolha Salvar.