API Realtime do GPT-4o para fala e áudio (versão prévia)
Observação
Esse recurso está atualmente em visualização pública. Essa versão prévia é fornecida sem um contrato de nível de serviço e não recomendamos isso para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
A API Realtime do GPT-4o do OpenAI do Azure para fala e áudio faz parte da família de modelos GPT-4o que oferece suporte a interações conversacionais de baixa latência, do tipo "fala de entrada, fala de saída". A API de áudio GPT-4o realtime foi projetada para lidar com interações conversacionais de baixa latência e em tempo real, o que a torna ideal para casos de uso que envolvem interações ao vivo entre um usuário e um modelo, como agentes de suporte ao cliente, assistentes de voz e tradutores em tempo real.
A maioria dos usuários da API Realtime precisa enviar e receber áudio de um usuário final em tempo real, incluindo aplicativos que utilizam WebRTC ou um sistema de telefonia. A API Realtime não foi projetada para se conectar diretamente a dispositivos de usuários finais e depende de integrações de cliente para finalizar os fluxos de áudio dos usuários finais.
Modelos com suporte
Atualmente, apenas a versão gpt-4o-realtime-preview: 2024-10-01-preview dá suporte a áudio em tempo real.
O modelo gpt-4o-realtime-preview está disponível para implantações globais nas regiões Leste dos EUA 2 e Suécia Central.
Importante
O sistema armazena seus prompts e respostas conforme descrito na seção "Uso e acesso de dados para monitoramento de abusos" dos Termos de Produto específicos do Serviço OpenAI do Azure, exceto que a Exceção Limitada não se aplica. O monitoramento de abusos será ativado para uso da API gpt-4o-realtime-preview, mesmo para clientes que, de outra forma, estão aprovados para monitoramento de abusos modificado.
Suporte a API
O suporte para a API Realtime foi adicionado pela primeira vez na versão 2024-10-01-preview da API.
Observação
Para obter mais informações sobre a API e a arquitetura, consulte o repositório de áudio em tempo real do GPT-4o do OpenAI do Azure no GitHub.
Implantar um modelo para áudio em tempo real
Para implantar o modelo gpt-4o-realtime-preview no portal do Azure AI Foundry:
- Acesse o portal do Azure AI Foundry e verifique se você está conectado com a assinatura do Azure que tem o recurso do Serviço OpenAI do Azure (com ou sem implantações de modelo).
- Selecione o playground de áudio em tempo real em Playgrounds no painel esquerdo.
- Selecione Criar nova implantação para abrir a janela de implantação.
- Pesquise e selecione o modelo
gpt-4o-realtime-previewe selecione Confirmar. - No assistente de implantação, selecione a versão do modelo
2024-10-01. - Siga o assistente para concluir a implantação do modelo.
Agora que você tem uma implantação do modelo gpt-4o-realtime-preview, pode interagir com ele em tempo real no portal do IA do Azure Foundry Playground de áudio em tempo real ou API em tempo real.
Use o áudio em tempo real do GPT-4o
Para conversar com o modelo gpt-4o-realtime-preview implantado no playground de Áudio em tempo real do Azure AI Foundry, siga estas etapas:
Acesse a página do Serviço OpenAI do Azure no portal do Azure AI Foundry. Verifique se você está conectado com a assinatura do Azure que tem o recurso do Serviço OpenAI do Azure e o modelo
gpt-4o-realtime-previewimplantado.Selecione o playground de áudio em tempo real em Playgrounds no painel esquerdo.
Selecione o modelo
gpt-4o-realtime-previewimplantado na lista de seleção Implantação.Selecione Habilitar microfone para permitir que o navegador acesse seu microfone. Se você já concedeu permissão, pode pular esta etapa.
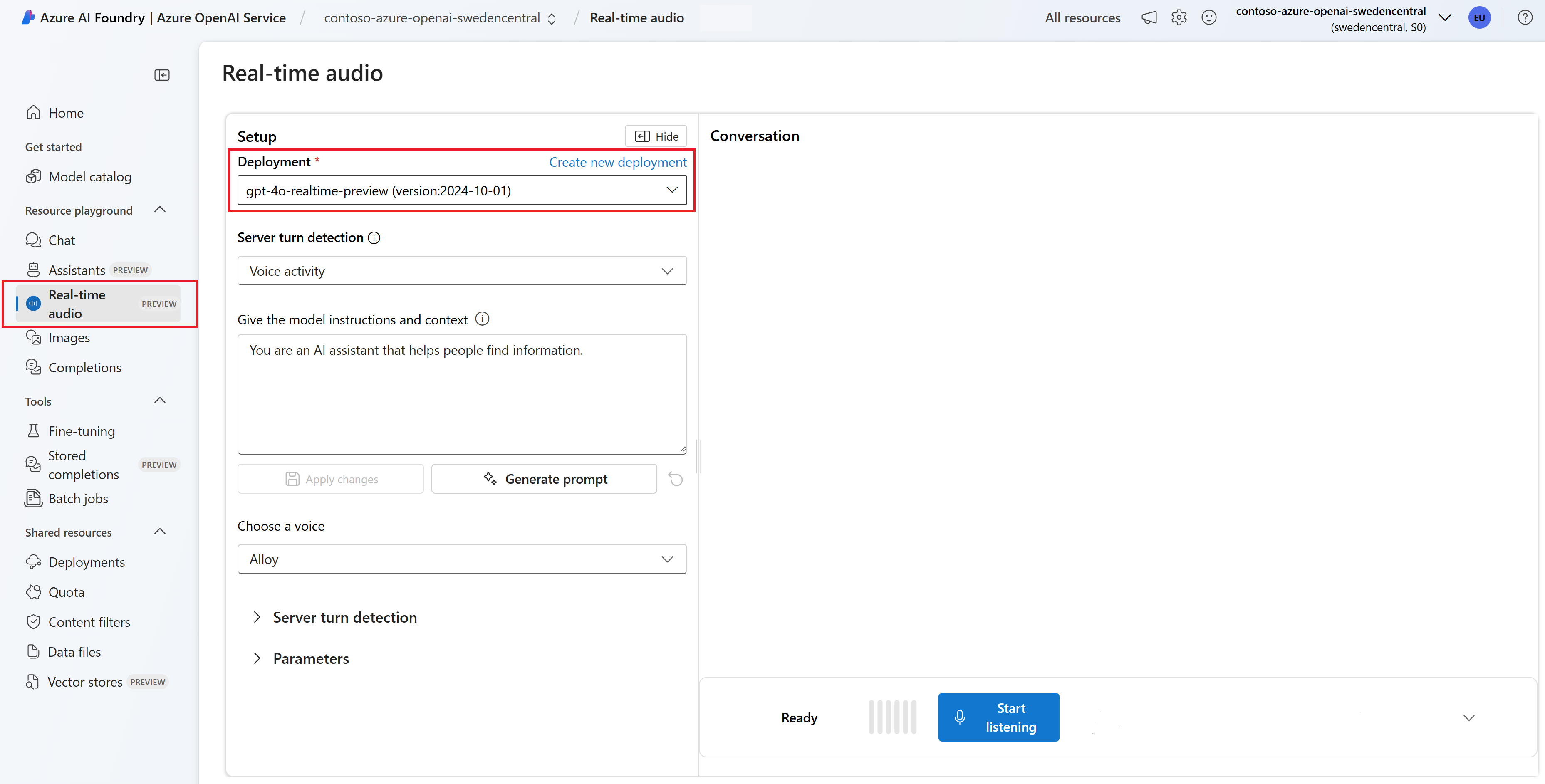
Opcionalmente, você pode editar o conteúdo na caixa de texto Fornecer instruções e contexto ao modelo. Forneça ao modelo instruções sobre como ele deve se comportar e qualquer contexto que ele deve referenciar ao gerar uma resposta. Você pode descrever a personalidade do assistente, dizer a ele o que ele deve ou não responder e como formatar as respostas.
Se quiser, altere as configurações, como limite, preenchimento de prefixo e duração do silêncio.
Selecione Começar a ouvir para iniciar a sessão. Você pode falar no microfone para iniciar um chat.
Você pode interromper o chat a qualquer momento, falando. Você pode encerrar o chat selecionando o botão Parar de ouvir.


Pré-requisitos
- Uma assinatura do Azure – crie uma gratuitamente
- Suporte a Node.js LTS ou ESM.
- Um recurso do OpenAI do Azure criado nas regiões Leste dos EUA 2 ou Suécia Central. Confira a Disponibilidade de região.
- Em seguida, você precisa implantar um modelo
gpt-4o-realtime-previewcom o recurso do OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
Pré-requisitos do Microsoft Entra ID
Para a autenticação sem chave recomendada com o Microsoft Entra ID, você precisa:
- Instale a CLI do Azure usada para autenticação sem chave com o Microsoft Entra ID.
- Atribua a função de
Cognitive Services Userà sua conta de usuário. Você pode atribuir funções no portal do Azure em Controle de acesso (IAM)>Adicionar atribuição de função.
Implantar um modelo para áudio em tempo real
Para implantar o modelo gpt-4o-realtime-preview no portal do Azure AI Foundry:
- Acesse o portal do Azure AI Foundry e verifique se você está conectado com a assinatura do Azure que tem o recurso do Serviço OpenAI do Azure (com ou sem implantações de modelo).
- Selecione o playground de áudio em tempo real em Playgrounds no painel esquerdo.
- Selecione Criar nova implantação para abrir a janela de implantação.
- Pesquise e selecione o modelo
gpt-4o-realtime-previewe selecione Confirmar. - No assistente de implantação, selecione a versão do modelo
2024-10-01. - Siga o assistente para concluir a implantação do modelo.
Agora que você tem uma implantação do modelo gpt-4o-realtime-preview, pode interagir com ele em tempo real no portal do IA do Azure Foundry Playground de áudio em tempo real ou API em tempo real.
Configuração
Crie uma nova pasta
realtime-audio-quickstartpara conter o aplicativo e abra o Visual Studio Code nessa pasta com o seguinte comando:mkdir realtime-audio-quickstart && code realtime-audio-quickstartCrie o
package.jsoncom o seguinte comando:npm init -yAtualize o
package.jsonpara ECMAScript com o seguinte comando:npm pkg set type=moduleInstale a biblioteca de clientes de áudio em tempo real para JavaScript com:
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzPara a autenticação sem chave recomendada com o Microsoft Entra ID, instale o pacote
@azure/identitycom:npm install @azure/identity
Recuperar as informações do recurso
| Nome da variável | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Esse valor pode ser encontrado na seção Chaves e Ponto de Extremidade ao examinar seu recurso no portal do Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Esse valor corresponderá ao nome personalizado escolhido para sua implantação ao implantar um modelo. Esse valor pode ser encontrado em Gerenciamento de Recursos>Implantações de Modelos no portal do Azure. |
OPENAI_API_VERSION |
Saiba mais sobre as Versões de API. |
Saiba mais sobre autenticação sem chave e configuração de variáveis de ambiente.
Cuidado
Para usar a autenticação sem chave recomendada com o SDK, verifique se a variável de ambiente AZURE_OPENAI_API_KEY não está definida.
Entrada de texto e saída de áudio
Crie o arquivo
text-in-audio-out.jscom o seguinte código:import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient(new URL(endpoint), new DefaultAzureCredential(), { deployment: deployment }); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Entre no Azure com o seguinte comando:
az loginExecute o arquivo JavaScript.
node text-in-audio-out.js
Leva alguns minutos para obter a resposta.
Saída
O script obtém uma resposta do modelo e imprime os dados de transcrição e áudio recebidos.
A saída terá esta aparência:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Exemplo de aplicativo Web
Nosso exemplo da Web JavaScript no GitHub demonstra como usar a API GPT-4o em tempo real para interagir com o modelo em tempo real. O código de exemplo inclui uma interface da Web simples que captura áudio do microfone do usuário e o envia para o modelo para processamento. O modelo responde com texto e áudio, que o código de exemplo renderiza na interface da Web.
Você pode executar o código de exemplo localmente em seu computador seguindo estas etapas. Consulte o repositório no GitHub para obter as instruções mais atualizadas.
Se você não tiver o Node.js instalado, baixe e instale a versão LTS do Node.js.
Clone o repositório em seu computador local:
git clone https://github.com/Azure-Samples/aoai-realtime-audio-sdk.gitVá para a pasta
javascript/samples/webno editor de código de sua preferência.cd ./javascript/samplesExecute
download-pkg.ps1oudownload-pkg.shpara baixar os pacotes necessários.Vá para a pasta
webda pasta./javascript/samples.cd ./webExecute
npm installpara instalar as dependências do pacote.Execute
npm run devpara iniciar o servidor Web, navegando por quaisquer solicitações de permissão de firewall, conforme necessário.Vá para qualquer uma das URIs fornecidas da saída do console (como
http://localhost:5173/) em um navegador.Insira as seguintes informações na interface da Web:
- Ponto de extremidade: o ponto de extremidade do recurso de um recurso do OpenAI do Azure. Você não precisa acrescentar o caminho
/realtime. Uma estrutura de exemplo pode serhttps://my-azure-openai-resource-from-portal.openai.azure.com. - Chave de API: uma chave de API correspondente para o recurso do OpenAI do Azure.
- Implantação: o nome do modelo
gpt-4o-realtime-previewque você implantou na seção anterior. - Mensagem do sistema: opcionalmente, você pode fornecer uma mensagem do sistema como "Você sempre fala como um pirata amigável".
- Temperatura: opcionalmente, você pode fornecer uma temperatura personalizada.
- Voz: opcionalmente, você pode selecionar uma voz.
- Ponto de extremidade: o ponto de extremidade do recurso de um recurso do OpenAI do Azure. Você não precisa acrescentar o caminho
Selecione o botão Gravar para iniciar a sessão. Aceite as permissões para usar o microfone, caso seja solicitado.
Você deve ver uma mensagem
<< Session Started >>na saída principal. Em seguida, você pode falar no microfone para iniciar um chat.Você pode interromper o chat a qualquer momento, falando. Você pode encerrar o chat selecionando o botão Parar.
Pré-requisitos
- Uma assinatura do Azure. Crie um gratuitamente.
- Python 3.8 ou versão posterior. É recomendável usar o Python 3.10 ou posterior, mas ter pelo menos Python 3.8 é necessário. Se você não tiver uma versão adequada do Python instalada, poderá seguir as instruções no Tutorial do Python do VS Code para obter a maneira mais fácil de instalar o Python em seu sistema operacional.
- Um recurso do OpenAI do Azure criado nas regiões Leste dos EUA 2 ou Suécia Central. Confira a Disponibilidade de região.
- Em seguida, você precisa implantar um modelo
gpt-4o-realtime-previewcom o recurso do OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
Pré-requisitos do Microsoft Entra ID
Para a autenticação sem chave recomendada com o Microsoft Entra ID, você precisa:
- Instale a CLI do Azure usada para autenticação sem chave com o Microsoft Entra ID.
- Atribua a função de
Cognitive Services Userà sua conta de usuário. Você pode atribuir funções no portal do Azure em Controle de acesso (IAM)>Adicionar atribuição de função.
Implantar um modelo para áudio em tempo real
Para implantar o modelo gpt-4o-realtime-preview no portal do Azure AI Foundry:
- Acesse o portal do Azure AI Foundry e verifique se você está conectado com a assinatura do Azure que tem o recurso do Serviço OpenAI do Azure (com ou sem implantações de modelo).
- Selecione o playground de áudio em tempo real em Playgrounds no painel esquerdo.
- Selecione Criar nova implantação para abrir a janela de implantação.
- Pesquise e selecione o modelo
gpt-4o-realtime-previewe selecione Confirmar. - No assistente de implantação, selecione a versão do modelo
2024-10-01. - Siga o assistente para concluir a implantação do modelo.
Agora que você tem uma implantação do modelo gpt-4o-realtime-preview, pode interagir com ele em tempo real no portal do IA do Azure Foundry Playground de áudio em tempo real ou API em tempo real.
Configuração
Crie uma nova pasta
realtime-audio-quickstartpara conter o aplicativo e abra o Visual Studio Code nessa pasta com o seguinte comando:mkdir realtime-audio-quickstart && code realtime-audio-quickstartCrie um ambiente virtual. Se você já tiver o Python 3.10 ou superior instalado, crie um ambiente virtual usando os seguintes comandos:
Ativar o ambiente Python significa que, ao executar
pythonoupipna linha de comando, você usará o interpretador Python contido na pasta.venvdo seu aplicativo. Você pode usar o comandodeactivatepara sair do ambiente virtual do Python e depois reativar quando necessário.Dica
Recomendamos que você crie e ative um novo ambiente Python para usar para instalar os pacotes necessários para este tutorial. Não instale pacotes na instalação global do Python. Você sempre deve usar um ambiente virtual ou do Conda ao instalar pacotes do Python, caso contrário, poderá interromper a instalação global do Python.
Instale a biblioteca de clientes de áudio em tempo real para Python com:
pip install "https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/py%2Fv0.5.3/rtclient-0.5.3.tar.gz"Para a autenticação sem chave recomendada com o Microsoft Entra ID, instale o pacote
azure-identitycom:pip install azure-identity
Recuperar as informações do recurso
| Nome da variável | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Esse valor pode ser encontrado na seção Chaves e Ponto de Extremidade ao examinar seu recurso no portal do Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Esse valor corresponderá ao nome personalizado escolhido para sua implantação ao implantar um modelo. Esse valor pode ser encontrado em Gerenciamento de Recursos>Implantações de Modelos no portal do Azure. |
OPENAI_API_VERSION |
Saiba mais sobre as Versões de API. |
Saiba mais sobre autenticação sem chave e configuração de variáveis de ambiente.
Entrada de texto e saída de áudio
Crie o arquivo
text-in-audio-out.pycom o seguinte código:import base64 import asyncio from azure.identity.aio import DefaultAzureCredential from rtclient import ( ResponseCreateMessage, RTLowLevelClient, ResponseCreateParams ) # Set environment variables or edit the corresponding values here. endpoint = os.environ["AZURE_OPENAI_ENDPOINT"] deployment = "gpt-4o-realtime-preview" async def text_in_audio_out(): async with RTLowLevelClient( url=endpoint, azure_deployment=deployment, token_credential=DefaultAzureCredential(), ) as client: await client.send( ResponseCreateMessage( response=ResponseCreateParams( modalities={"audio", "text"}, instructions="Please assist the user." ) ) ) done = False while not done: message = await client.recv() match message.type: case "response.done": done = True case "error": done = True print(message.error) case "response.audio_transcript.delta": print(f"Received text delta: {message.delta}") case "response.audio.delta": buffer = base64.b64decode(message.delta) print(f"Received {len(buffer)} bytes of audio data.") case _: pass async def main(): await text_in_audio_out() asyncio.run(main())Execute o arquivo Python.
python text-in-audio-out.py
Leva alguns minutos para obter a resposta.
Saída
O script obtém uma resposta do modelo e imprime os dados de transcrição e áudio recebidos.
A saída terá esta aparência:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: can
Received 12000 bytes of audio data.
Received text delta: I
Received text delta: assist
Received text delta: you
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 28800 bytes of audio data.
Pré-requisitos
- Uma assinatura do Azure – crie uma gratuitamente
- Suporte a Node.js LTS ou ESM.
- TypeScript instalado globalmente.
- Um recurso do OpenAI do Azure criado nas regiões Leste dos EUA 2 ou Suécia Central. Confira a Disponibilidade de região.
- Em seguida, você precisa implantar um modelo
gpt-4o-realtime-previewcom o recurso do OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
Pré-requisitos do Microsoft Entra ID
Para a autenticação sem chave recomendada com o Microsoft Entra ID, você precisa:
- Instale a CLI do Azure usada para autenticação sem chave com o Microsoft Entra ID.
- Atribua a função de
Cognitive Services Userà sua conta de usuário. Você pode atribuir funções no portal do Azure em Controle de acesso (IAM)>Adicionar atribuição de função.
Implantar um modelo para áudio em tempo real
Para implantar o modelo gpt-4o-realtime-preview no portal do Azure AI Foundry:
- Acesse o portal do Azure AI Foundry e verifique se você está conectado com a assinatura do Azure que tem o recurso do Serviço OpenAI do Azure (com ou sem implantações de modelo).
- Selecione o playground de áudio em tempo real em Playgrounds no painel esquerdo.
- Selecione Criar nova implantação para abrir a janela de implantação.
- Pesquise e selecione o modelo
gpt-4o-realtime-previewe selecione Confirmar. - No assistente de implantação, selecione a versão do modelo
2024-10-01. - Siga o assistente para concluir a implantação do modelo.
Agora que você tem uma implantação do modelo gpt-4o-realtime-preview, pode interagir com ele em tempo real no portal do IA do Azure Foundry Playground de áudio em tempo real ou API em tempo real.
Configuração
Crie uma nova pasta
realtime-audio-quickstartpara conter o aplicativo e abra o Visual Studio Code nessa pasta com o seguinte comando:mkdir realtime-audio-quickstart && code realtime-audio-quickstartCrie o
package.jsoncom o seguinte comando:npm init -yAtualize o
package.jsonpara ECMAScript com o seguinte comando:npm pkg set type=moduleInstale a biblioteca de clientes de áudio em tempo real para JavaScript com:
npm install https://github.com/Azure-Samples/aoai-realtime-audio-sdk/releases/download/js/v0.5.2/rt-client-0.5.2.tgzPara a autenticação sem chave recomendada com o Microsoft Entra ID, instale o pacote
@azure/identitycom:npm install @azure/identity
Recuperar as informações do recurso
| Nome da variável | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Esse valor pode ser encontrado na seção Chaves e Ponto de Extremidade ao examinar seu recurso no portal do Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Esse valor corresponderá ao nome personalizado escolhido para sua implantação ao implantar um modelo. Esse valor pode ser encontrado em Gerenciamento de Recursos>Implantações de Modelos no portal do Azure. |
OPENAI_API_VERSION |
Saiba mais sobre as Versões de API. |
Saiba mais sobre autenticação sem chave e configuração de variáveis de ambiente.
Cuidado
Para usar a autenticação sem chave recomendada com o SDK, verifique se a variável de ambiente AZURE_OPENAI_API_KEY não está definida.
Entrada de texto e saída de áudio
Crie o arquivo
text-in-audio-out.tscom o seguinte código:import { DefaultAzureCredential } from "@azure/identity"; import { LowLevelRTClient } from "rt-client"; import dotenv from "dotenv"; dotenv.config(); async function text_in_audio_out() { // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "yourEndpoint"; const deployment = "gpt-4o-realtime-preview"; if (!endpoint || !deployment) { throw new Error("You didn't set the environment variables."); } const client = new LowLevelRTClient( new URL(endpoint), new DefaultAzureCredential(), {deployment: deployment} ); try { await client.send({ type: "response.create", response: { modalities: ["audio", "text"], instructions: "Please assist the user." } }); for await (const message of client.messages()) { switch (message.type) { case "response.done": { break; } case "error": { console.error(message.error); break; } case "response.audio_transcript.delta": { console.log(`Received text delta: ${message.delta}`); break; } case "response.audio.delta": { const buffer = Buffer.from(message.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); break; } } if (message.type === "response.done" || message.type === "error") { break; } } } finally { client.close(); } } await text_in_audio_out();Crie o arquivo
tsconfig.jsonpara transpilar o código TypeScript e copiar o código a seguir para ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile de TypeScript para JavaScript.
tscEntre no Azure com o seguinte comando:
az loginExecute o código com o seguinte comando:
node text-in-audio-out.js
Leva alguns minutos para obter a resposta.
Saída
O script obtém uma resposta do modelo e imprime os dados de transcrição e áudio recebidos.
A saída terá esta aparência:
Received text delta: Hello
Received text delta: !
Received text delta: How
Received text delta: can
Received text delta: I
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: help
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Conteúdo relacionado
- Saiba mais sobre Como usar a API em tempo real
- Consulte a referência de API em tempo real
- Saiba mais sobre as cotas e limites do OpenAI do Azure