Introdução às implantações em lotes do Serviço OpenAI do Azure
A API de Lote do OpenAI do Azure foi projetada para lidar com tarefas de processamento em grande escala e de alto volume com eficiência. Processe grupos assíncronos de solicitações com cota separada, com reviravolta de destino de 24 horas, a custos 50% menor que o padrão global. Com o processamento em lote, em vez de enviar uma solicitação por vez, você deve enviar um grande número de solicitações em um único arquivo. As solicitações em lotes globais têm uma cota de token enfileirada separada, evitando qualquer interrupção das suas cargas de trabalho online.
Os casos de uso incluem:
Processamento de dados em larga escala: analisar rapidamente conjuntos de dados extensos em paralelo.
Geração de Conteúdo: Criar grandes volumes de texto, como descrições de produto ou artigos.
Revisão e Resumo de Documentos: automatizar a revisão e o resumo de documentos longos.
Automação de Suporte ao Cliente: lidar com várias consultas simultaneamente para obter respostas mais rápidas.
Extração e Análise de Dados: extrair e analisar informações de grandes quantidades de dados não estruturados.
Tarefas do Processamento de Linguagem Natural (NLP): execute tarefas como análise de sentimento ou tradução em grandes conjuntos de dados.
Marketing e personalização: gere conteúdo personalizado e recomendações em escala.
Importante
Nosso objetivo é processar solicitações em lotes dentro de 24 horas; não expiramos os trabalhos que levam mais tempo. Você poderá cancelar o trabalho a qualquer momento. Ao cancelar o trabalho, qualquer trabalho restante é cancelado e qualquer trabalho já concluído é retornado. Você será cobrado por qualquer trabalho concluído.
Os dados armazenados inativos permanecem na geografia designada do Azure, enquanto os dados podem ser processados para inferência em qualquer local do Azure OpenAI. Saiba mais sobre residência de dados.
Suporte ao lote
Disponibilidade do modelo de lote global
| Região | o3-mini, 31/01/2025 | gpt-4o, 2024-05-13 | gpt-4o, 2024-08-06 | gpt-4o, 2024-11-20 | gpt-4o-mini, 2024-07-18 | gpt-4, 0613 | gpt-4, turbo-2024-04-09 | gpt-35-turbo, 0613 | gpt-35-turbo, 1106 | gpt-35-turbo, 0125 |
|---|---|---|---|---|---|---|---|---|---|---|
| australiaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| brazilsouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| canadaeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| francecentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| germanywestcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| japaneast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| koreacentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| northcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norwayeast | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| polandcentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southafricanorth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southcentralus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southindia | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| swedencentral | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| switzerlandnorth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| uksouth | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westeurope | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus | - | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
O registro é necessário para acesso a o3-mini. Para obter mais informações, consulte nosso guia de modelo de raciocínio.
Os seguintes modelos dão suporte ao lote global:
| Modelar | Versão | Formato de entrada |
|---|---|---|
o3-mini |
2025-01-31 | text |
gpt-4o |
06/08/2024 | texto + imagem |
gpt-4o-mini |
2024-07-18 | texto + imagem |
gpt-4o |
2024-05-13 | texto + imagem |
gpt-4 |
turbo-2024-04-09 | text |
gpt-4 |
0613 | text |
gpt-35-turbo |
0125 | text |
gpt-35-turbo |
1106 | text |
gpt-35-turbo |
0613 | text |
Consulte a página de modelos para obter as informações mais atualizadas sobre regiões/modelos em que o lote global tem suporte no momento.
Suporte a API
| Versão da API | |
|---|---|
| Lançamento mais recente da API de GA: | 2024-10-21 |
| Lançamento mais recente da API em versão prévia: | 2025-01-01-preview |
Suporte adicionado pela primeira vez em: 2024-07-01-preview
Suporte a recursos
No momento, não há suporte para o seguinte:
- Integração com a API de Assistentes.
- Integração com o recurso do OpenAI do Azure em Seus Dados.
Observação
Agora há suporte para saídas estruturadas no Lote global.
Implantação em lote
Observação
No portal da Fábrica de IA do Azure, os tipos de implantação em lote serão exibidos como Global-Batch e Data Zone Batch. Para saber mais sobre os tipos de implantação do OpenAI do Azure, confira nosso guia de tipos de implantação.

Dica
Recomendamos habilitar cota dinâmica para todas as implantações globais de modelo em lotes para ajudar a evitar falhas de trabalho devido à cota de token enfileirada insuficiente. A cota dinâmica permite que sua implantação aproveite de forma oportunista mais cota quando a capacidade extra estiver disponível. Quando a cota dinâmica for definida como desativada, sua implantação só poderá processar solicitações até o limite de token enfileirado definido quando você criou a implantação.
Pré-requisitos
- Uma assinatura do Azure – Crie uma gratuitamente.
- Um recurso do OpenAI do Azure com um modelo do tipo
Global-Batchde implantação implantado. Consulte a guia de criação de recursos e implantação de modelo para obter ajuda com esse processo.
Preparar seu arquivo em lote
Assim como o ajuste fino, o lote global usa arquivos no formato de linhas JSON (.jsonl). Abaixo estão alguns arquivos de exemplo com diferentes tipos de conteúdo com suporte:
Formato de entrada
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
O custom_id é necessário permitir identificar qual solicitação em lote individual corresponde a uma determinada resposta. As respostas não serão retornadas em ordem idêntica à ordem definida no arquivo em lote .jsonl.
O atributo model deve ser definido para corresponder ao nome da implantação do Lote Global que você deseja direcionar para respostas de inferência.
Importante
O atributo model deve ser configurado para corresponder ao nome da implantação do Lote Global que você deseja direcionar para as respostas de inferência. O mesmo nome de implantação do modelo do Lote Globa deve estar presente em cada linha do arquivo de lote. Se você quiser direcionar uma implantação diferente, deverá fazê-lo em um arquivo de lote/trabalho separado.
Para obter um melhor desempenho, recomendamos enviar arquivos grandes para processamento em lote, em vez de muitos arquivos pequenos com apenas algumas linhas em cada um.
Criar arquivo de entrada
Para este artigo, criaremos um arquivo nomeado test.jsonl e copiaremos o conteúdo do bloco de código de entrada padrão acima para o arquivo. Você precisará modificar e adicionar seu nome de implantação em lote global a cada linha do arquivo.
Carregar arquivo em lote
Depois que o arquivo de entrada estiver preparado, primeiro você precisará carregar o arquivo para poder iniciar um trabalho em lotes. O upload de arquivo pode ser feito programaticamente ou por meio do Studio.
Entre no portal do Azure AI Foundry.
Selecione o recurso do OpenAI do Azure em que você tem uma implantação de modelo de lote global disponível.
Selecione Trabalhos em lote>+Criar trabalhos em lote.
Na lista suspensa, em Dados em lote>Fazer upload de arquivos>, selecione Carregar arquivo e forneça o caminho para o arquivo
test.jsonlcriado na etapa >anterior Avançar.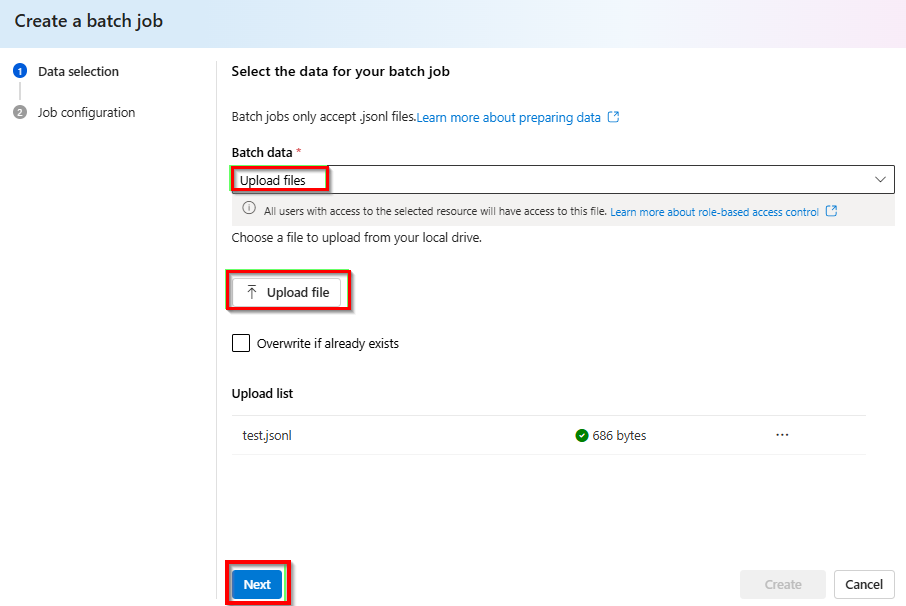


Criar trabalho do lote
Selecione Criar para iniciar o trabalho em lotes.

Acompanhar o progresso do trabalho em lotes
Após criar o trabalho, você poderá monitorar o progresso do trabalho selecionando a ID do trabalho para o trabalho criado mais recentemente. Por padrão, você será direcionado para a página de status do trabalho em lotes criado mais recentemente.

Você poderá acompanhar o status do trabalho para seu trabalho no painel direito:

Recuperar o arquivo de saída do trabalho em lote
Quando o trabalho for concluído ou atingir um estado terminal, ele vai gerar um arquivo de erro e um arquivo de saída que podem ser baixados para revisão selecionando o respectivo botão com o ícone de seta para baixo.

Cancelar lote
Cancela um lote em andamento. O lote ficará em status cancelling por até 10 minutos, antes de ser alterado para cancelled, onde terá resultados parciais (se houver) disponíveis no arquivo de saída.

Pré-requisitos
- Uma assinatura do Azure – Crie uma gratuitamente.
- Python 3.8 ou versão posterior
- A seguinte biblioteca do Python:
openai - Jupyter Notebooks
- Um recurso do OpenAI do Azure com um modelo do tipo
Global-Batchde implantação implantado. Consulte a guia de criação de recursos e implantação de modelo para obter ajuda com esse processo.
As etapas neste artigo devem ser executadas sequencialmente no Jupyter Notebooks. Por esse motivo, só instanciaremos o cliente do OpenAI do Azure uma vez no início dos exemplos. Caso queira executar uma etapa fora de ordem, muitas vezes precisará configurar um cliente do OpenAI do Azure como parte dessa chamada.
Mesmo se você já tiver a biblioteca do Python do OpenAI instalada, talvez seja necessário atualizar sua instalação para a versão mais recente:
!pip install openai --upgrade
Preparar seu arquivo em lote
Assim como o ajuste fino, o lote global usa arquivos no formato de linhas JSON (.jsonl). Abaixo estão alguns arquivos de exemplo com diferentes tipos de conteúdo com suporte:
Formato de entrada
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
O custom_id é necessário permitir identificar qual solicitação em lote individual corresponde a uma determinada resposta. As respostas não serão retornadas em ordem idêntica à ordem definida no arquivo em lote .jsonl.
O atributo model deve ser definido para corresponder ao nome da implantação do Lote Global que você deseja direcionar para respostas de inferência.
Importante
O atributo model deve ser configurado para corresponder ao nome da implantação do Lote Global que você deseja direcionar para as respostas de inferência. O mesmo nome de implantação do modelo do Lote Globa deve estar presente em cada linha do arquivo de lote. Se você quiser direcionar uma implantação diferente, deverá fazê-lo em um arquivo de lote/trabalho separado.
Para obter um melhor desempenho, recomendamos enviar arquivos grandes para processamento em lote, em vez de muitos arquivos pequenos com apenas algumas linhas em cada um.
Criar arquivo de entrada
Para este artigo, criaremos um arquivo nomeado test.jsonl e copiaremos o conteúdo do bloco de código de entrada padrão acima para o arquivo. Você precisará modificar e adicionar seu nome de implantação em lote global a cada linha do arquivo. Salve esse arquivo no mesmo diretório que você está executando seu Jupyter Notebook.
Carregar arquivo em lote
Depois que o arquivo de entrada estiver preparado, primeiro você precisará carregar o arquivo para poder iniciar um trabalho em lotes. O upload de arquivo pode ser feito programaticamente ou por meio do Studio. Este exemplo usa variáveis de ambiente no lugar dos valores de chave e ponto de extremidade. Caso não esteja familiarizado com o uso de variáveis de ambiente com Python, consulte um de nossos guias de início rápido em que o processo de configuração das variáveis de ambiente é explicado passo a passo.
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
# Upload a file with a purpose of "batch"
file = client.files.create(
file=open("test.jsonl", "rb"),
purpose="batch"
)
print(file.model_dump_json(indent=2))
file_id = file.id
Saída:
{
"id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"bytes": 815,
"created_at": 1722476551,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": null,
"status_details": null
}
Criar trabalho do lote
Após carregar o arquivo, você poderá enviar o arquivo para processamento em lote.
# Submit a batch job with the file
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
)
# Save batch ID for later use
batch_id = batch_response.id
print(batch_response.model_dump_json(indent=2))
Observação
Atualmente, a janela de conclusão deve ser definida como 24h. Caso defina qualquer outro valor que não seja 24h, o trabalho falhará. Os trabalhos que levam mais de 24 horas continuarão a ser executados até serem cancelados.
Saída:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": null,
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
Acompanhar o progresso do trabalho em lotes
Após criar um trabalho em lote com êxito, você poderá monitorar seu progresso no Studio ou programaticamente. Ao verificar o progresso do trabalho em lotes, recomendamos aguardar pelo menos 60 segundos entre cada chamada de status.
import time
import datetime
status = "validating"
while status not in ("completed", "failed", "canceled"):
time.sleep(60)
batch_response = client.batches.retrieve(batch_id)
status = batch_response.status
print(f"{datetime.datetime.now()} Batch Id: {batch_id}, Status: {status}")
if batch_response.status == "failed":
for error in batch_response.errors.data:
print(f"Error code {error.code} Message {error.message}")
Saída:
2024-07-31 21:48:32.556488 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: validating
2024-07-31 21:49:39.221560 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:50:53.383138 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:52:07.274570 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:53:21.149501 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:54:34.572508 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:55:35.304713 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:56:36.531816 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:57:37.414105 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: completed
Os seguintes valores de status são possíveis:
| Status | Descrição |
|---|---|
validating |
O arquivo de entrada está sendo validado antes que o processamento em lote possa começar. |
failed |
O arquivo de entrada falhou no processo de validação. |
in_progress |
O arquivo de entrada foi validado com êxito e o lote está em execução no momento. |
finalizing |
O lote foi concluído e os resultados estão sendo preparados. |
completed |
O lote foi concluído e os resultados estão prontos. |
expired |
O lote não pôde ser concluído dentro da janela de tempo de 24 horas. |
cancelling |
O lote está sendo cancelled (isso pode levar até 10 minutos para entrar em vigor.) |
cancelled |
o lote era cancelled. |
Para examinar os detalhes do status do trabalho, você poderá executar:
print(batch_response.model_dump_json(indent=2))
Saída:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1722477429,
"error_file_id": "file-c795ae52-3ba7-417d-86ec-07eebca57d0b",
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": 1722477177,
"in_progress_at": null,
"metadata": null,
"output_file_id": "file-3304e310-3b39-4e34-9f1c-e1c1504b2b2a",
"request_counts": {
"completed": 3,
"failed": 0,
"total": 3
}
}
Observe que há ambos error_file_id e um separado output_file_id. Use o error_file_id para ajudar na depuração de quaisquer problemas que ocorram com seu trabalho em lote.
Recuperar o arquivo de saída do trabalho em lote
import json
output_file_id = batch_response.output_file_id
if not output_file_id:
output_file_id = batch_response.error_file_id
if output_file_id:
file_response = client.files.content(output_file_id)
raw_responses = file_response.text.strip().split('\n')
for raw_response in raw_responses:
json_response = json.loads(raw_response)
formatted_json = json.dumps(json_response, indent=2)
print(formatted_json)
Saída:
Para fins de brevidade, estamos incluindo apenas uma única resposta de conclusão de chat da saída. Caso siga as etapas neste artigo, deverá ter três respostas semelhantes à seguinte:
{
"custom_id": "task-0",
"response": {
"body": {
"choices": [
{
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
},
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Microsoft was founded on April 4, 1975, by Bill Gates and Paul Allen in Albuquerque, New Mexico.",
"role": "assistant"
}
}
],
"created": 1722477079,
"id": "chatcmpl-9rFGJ9dh08Tw9WRKqaEHwrkqRa4DJ",
"model": "gpt-4o-2024-05-13",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": "fp_a9bfe9d51d",
"usage": {
"completion_tokens": 24,
"prompt_tokens": 27,
"total_tokens": 51
}
},
"request_id": "660b7424-b648-4b67-addc-862ba067d442",
"status_code": 200
},
"error": null
}
Comandos de lote adicionais
Cancelar lote
Cancela um lote em andamento. O lote ficará em status cancelling por até 10 minutos, antes de ser alterado para cancelled, onde terá resultados parciais (se houver) disponíveis no arquivo de saída.
client.batches.cancel("batch_abc123") # set to your batch_id for the job you want to cancel
Listar lote
Liste os trabalhos em lote para um recurso específico do OpenAI do Azure.
client.batches.list()
Os métodos de lista na biblioteca do Python são paginados.
Para listar todos os trabalhos:
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.batches.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
Lote de lista (Versão prévia)
Use a API REST para listar todos os trabalhos em lote com opções adicionais de classificação/filtragem.
Nos exemplos abaixo, estamos fornecendo a função generate_time_filter para facilitar a construção do filtro. Se você não quiser usar essa função, o formato da cadeia de caracteres de filtro será semelhante a created_at gt 1728860560 and status eq 'Completed'.
import requests
import json
from datetime import datetime, timedelta
from azure.identity import DefaultAzureCredential
token_credential = DefaultAzureCredential()
token = token_credential.get_token('https://cognitiveservices.azure.com/.default')
endpoint = "https://{YOUR_RESOURCE_NAME}.openai.azure.com/"
api_version = "2024-10-01-preview"
url = f"{endpoint}openai/batches"
order = "created_at asc"
time_filter = lambda: generate_time_filter("past 8 hours")
# Additional filter examples:
#time_filter = lambda: generate_time_filter("past 1 day")
#time_filter = lambda: generate_time_filter("past 3 days", status="Completed")
def generate_time_filter(time_range, status=None):
now = datetime.now()
if 'day' in time_range:
days = int(time_range.split()[1])
start_time = now - timedelta(days=days)
elif 'hour' in time_range:
hours = int(time_range.split()[1])
start_time = now - timedelta(hours=hours)
else:
raise ValueError("Invalid time range format. Use 'past X day(s)' or 'past X hour(s)'")
start_timestamp = int(start_time.timestamp())
filter_string = f"created_at gt {start_timestamp}"
if status:
filter_string += f" and status eq '{status}'"
return filter_string
filter = time_filter()
headers = {'Authorization': 'Bearer ' + token.token}
params = {
"api-version": api_version,
"$filter": filter,
"$orderby": order
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
if response.status_code == 200:
print(json.dumps(json_data, indent=2))
else:
print(f"Request failed with status code: {response.status_code}")
print(response.text)
Saída:
{
"data": [
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729011896,
"completion_window": "24h",
"created_at": 1729011128,
"error_file_id": "file-472c0626-4561-4327-9e4e-f41afbfb30e6",
"expired_at": null,
"expires_at": 1729097528,
"failed_at": null,
"finalizing_at": 1729011805,
"id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"in_progress_at": 1729011493,
"input_file_id": "file-f89384af0082485da43cb26b49dc25ce",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-62bebde8-e767-4cd3-a0a1-28b214dc8974",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
},
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729016366,
"completion_window": "24h",
"created_at": 1729015829,
"error_file_id": "file-85ae1971-9957-4511-9eb4-4cc9f708b904",
"expired_at": null,
"expires_at": 1729102229,
"failed_at": null,
"finalizing_at": 1729016272,
"id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43",
"in_progress_at": 1729016126,
"input_file_id": "file-686746fcb6bc47f495250191ffa8a28e",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-04399828-ae0b-4825-9b49-8976778918cb",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
}
],
"first_id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"has_more": false,
"last_id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43"
}
Pré-requisitos
- Uma assinatura do Azure – Crie uma gratuitamente.
- Um recurso do OpenAI do Azure com um modelo do tipo
Global-Batchde implantação implantado. Consulte a guia de criação de recursos e implantação de modelo para obter ajuda com esse processo.
Preparar seu arquivo em lote
Assim como o ajuste fino, o lote global usa arquivos no formato de linhas JSON (.jsonl). Abaixo estão alguns arquivos de exemplo com diferentes tipos de conteúdo com suporte:
Formato de entrada
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
O custom_id é necessário permitir identificar qual solicitação em lote individual corresponde a uma determinada resposta. As respostas não serão retornadas em ordem idêntica à ordem definida no arquivo em lote .jsonl.
O atributo model deve ser definido para corresponder ao nome da implantação do Lote Global que você deseja direcionar para respostas de inferência.
Importante
O atributo model deve ser configurado para corresponder ao nome da implantação do Lote Global que você deseja direcionar para as respostas de inferência. O mesmo nome de implantação do modelo do Lote Globa deve estar presente em cada linha do arquivo de lote. Se você quiser direcionar uma implantação diferente, deverá fazê-lo em um arquivo de lote/trabalho separado.
Para obter um melhor desempenho, recomendamos enviar arquivos grandes para processamento em lote, em vez de muitos arquivos pequenos com apenas algumas linhas em cada um.
Criar arquivo de entrada
Para este artigo, criaremos um arquivo nomeado test.jsonl e copiaremos o conteúdo do bloco de código de entrada padrão acima para o arquivo. Você precisará modificar e adicionar seu nome de implantação em lote global a cada linha do arquivo.
Carregar arquivo em lote
Depois que o arquivo de entrada estiver preparado, primeiro você precisará carregar o arquivo para poder iniciar um trabalho em lotes. O upload de arquivo pode ser feito programaticamente ou por meio do Studio. Este exemplo usa variáveis de ambiente no lugar dos valores de chave e ponto de extremidade. Caso não esteja familiarizado com o uso de variáveis de ambiente com Python, consulte um de nossos guias de início rápido em que o processo de configuração das variáveis de ambiente é explicado passo a passo.
Importante
Use as chaves de API com cuidado. Não inclua a chave da API diretamente no seu código e nunca a publique publicamente. Se você usar uma chave de API, armazene-a com segurança no Azure Key Vault. Para obter mais informações sobre como usar chaves de API com segurança em seus aplicativos, consulte Chaves de API com o Azure Key Vault.
Para obter mais informações sobre a segurança dos serviços de IA, veja Autenticar solicitações para serviços de IA do Azure.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files?api-version=2024-10-21 \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=batch" \
-F "file=@C:\\batch\\test.jsonl;type=application/json"
O código acima pressupõe um caminho de arquivo específico para o arquivo test.jsonl. Ajuste esse caminho de arquivo conforme necessário para seu sistema local.
Saída:
{
"status": "pending",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
Acompanhar o status de upload de arquivo
Dependendo do tamanho do arquivo de carregamento, pode levar algum tempo até que ele seja totalmente carregado e processado. Para verificar a execução do status de upload de arquivo:
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{file-id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Saída:
{
"status": "processed",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
Criar trabalho do lote
Após carregar o arquivo, você poderá enviar o arquivo para processamento em lote.
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-abc123",
"endpoint": "/chat/completions",
"completion_window": "24h"
}'
Observação
Atualmente, a janela de conclusão deve ser definida como 24h. Caso defina qualquer outro valor que não seja 24h, o trabalho falhará. Os trabalhos que levam mais de 24 horas continuarão a ser executados até serem cancelados.
Saída:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:13:57.2491382+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:13:57.1918498+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_fe3f047a-de39-4068-9008-346795bfc1db",
"in_progress_at": null,
"input_file_id": "file-21006e70789246658b86a1fc205899a4",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
Acompanhar o progresso do trabalho em lotes
Após criar um trabalho em lote com êxito, você poderá monitorar seu progresso no Studio ou programaticamente. Ao verificar o progresso do trabalho em lotes, recomendamos aguardar pelo menos 60 segundos entre cada chamada de status.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Saída:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:33:29.1619286+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:33:29.1578141+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_e0a7ee28-82c4-46a2-a3a0-c13b3c4e390b",
"in_progress_at": null,
"input_file_id": "file-c55ec4e859d54738a313d767718a2ac5",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
Os seguintes valores de status são possíveis:
| Status | Descrição |
|---|---|
validating |
O arquivo de entrada está sendo validado antes que o processamento em lote possa começar. |
failed |
O arquivo de entrada falhou no processo de validação. |
in_progress |
O arquivo de entrada foi validado com êxito e o lote está em execução no momento. |
finalizing |
O lote foi concluído e os resultados estão sendo preparados. |
completed |
O lote foi concluído e os resultados estão prontos. |
expired |
O lote não pôde ser concluído dentro da janela de tempo de 24 horas. |
cancelling |
O lote está sendo cancelled (isso pode levar até 10 minutos para entrar em vigor.) |
cancelled |
o lote era cancelled. |
Recuperar o arquivo de saída do trabalho em lote
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{output_file_id}/content?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" > batch_output.jsonl
Comandos de lote adicionais
Cancelar lote
Cancela um lote em andamento. O lote ficará em status cancelling por até 10 minutos, antes de ser alterado para cancelled, onde terá resultados parciais (se houver) disponíveis no arquivo de saída.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}/cancel?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Listar lote
Liste os trabalhos em lotes existentes para um determinado recurso do OpenAI do Azure.
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
A chamada à API de lista é paginada. A resposta contém um booliano has_more para indicar quando há mais resultados para iterar.
Lote de lista (Versão prévia)
Use a API REST para listar todos os trabalhos em lote com opções adicionais de classificação/filtragem.
curl "YOUR_RESOURCE_NAME.openai.azure.com/batches?api-version=2024-10-01-preview&$filter=created_at%20gt%201728773533%20and%20created_at%20lt%201729032733%20and%20status%20eq%20'Completed'&$orderby=created_at%20asc" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Para evitar o erro URL rejected: Malformed input to a URL function, os espaços são substituídos por %20.
Limites de lote
| Nome do limite | Valor do limite |
|---|---|
| Máximo de arquivos por recurso | 500 |
| Tamanho máximo do arquivo de entrada | 200 MB |
| Máximo de solicitações por arquivo | 100.000 |
Cota do lote
A tabela mostra o limite de cota do lote. Os valores de cota para o lote global são representados em termos de tokens enfileirados. Ao enviar um arquivo para processamento em lote, o número de tokens presentes no arquivo é contado. Até que o trabalho em lote atinja um estado de terminal, esses tokens contarão com o limite total de tokens enfileirados.
Lote global
| Modelar | Contrato Enterprise | Padrão | Assinaturas mensais baseadas em cartão de crédito | Assinaturas MSDN | Azure for Students, avaliações gratuitas |
|---|---|---|---|---|---|
gpt-4o |
5 B | 200 M | 50 M | 90 mil | N/D |
gpt-4o-mini |
15 B | 1 B | 50 M | 90 mil | N/D |
gpt-4-turbo |
300 mi | 80 M | 40 mi | 90 mil | N/D |
gpt-4 |
150 mi | 30 M | 5 mi | 100 mil | N/D |
gpt-35-turbo |
10 bi | 1 B | 100 mi | 2 M | 50 mil |
o3-mini |
15 B | 1 B | 50 M | 90 mil | N/A |
B = bilhões | M = milhões | K = mil
Lote da zona de dados
| Modelar | Contrato Enterprise | Padrão | Assinaturas mensais baseadas em cartão de crédito | Assinaturas MSDN | Azure for Students, avaliações gratuitas |
|---|---|---|---|---|---|
gpt-4o |
500 M | 30 M | 30 M | 90 mil | N/A |
gpt-4o-mini |
1,5 B | 100 mi | 50 M | 90 mil | N/A |
Objeto de lote
| Propriedade | Tipo | Definição |
|---|---|---|
id |
string | |
object |
cadeia de caracteres | batch |
endpoint |
string | O ponto de extremidade de API usado pelo lote |
errors |
objeto | |
input_file_id |
string | A ID do arquivo de entrada para o lote |
completion_window |
string | O período dentro do qual o lote deve ser processado |
status |
string | O status atual do lote. Valores possíveis: validating, failed, in_progress, finalizing, completed, expired, cancelling e cancelled. |
output_file_id |
string | A ID do arquivo que contém as saídas de solicitações executadas com êxito. |
error_file_id |
string | A ID do arquivo que contém as saídas de solicitações com erros. |
created_at |
Número inteiro | Um carimbo de data/hora quando esse lote foi criado (em épocas do Unix). |
in_progress_at |
Número inteiro | Um carimbo de data/hora quando este lote começou a progredir (em épocas do Unix). |
expires_at |
Número inteiro | Um carimbo de data/hora em que esse lote expirará (em épocas do Unix). |
finalizing_at |
Número inteiro | Um carimbo de data/hora quando este lote começou a ser finalizado (em épocas do Unix). |
completed_at |
Número inteiro | Um carimbo de data/hora quando este lote começou a ser finalizado (em épocas do Unix). |
failed_at |
Número inteiro | Um carimbo de data/hora quando esse lote falhou (em épocas do Unix) |
expired_at |
Número inteiro | Um carimbo de data/hora quando esse lote expirou (em épocas do Unix). |
cancelling_at |
Número inteiro | Um carimbo de data/hora quando este lote foi iniciado cancelling (em épocas do Unix). |
cancelled_at |
Número inteiro | Um carimbo de data/hora quando este lote estava cancelled (em épocas do Unix). |
request_counts |
objeto | Estrutura do objeto:total
inteiro O número total de solicitações no lote. completed
inteiro O número de solicitações no lote que foram concluídas com êxito. failed
inteiro O número de solicitações no lote que falharam. |
metadata |
map | Um conjunto de pares chave-valor que podem ser anexados ao lote. Esta propriedade poderá ser útil para armazenar informações adicionais sobre o lote em um formato estruturado. |
Perguntas frequentes
As imagens podem ser usadas com a API do lote?
Essa funcionalidade é limitada a determinados modelos multi modais. Atualmente, apenas GPT-4o dá suporte a imagens como parte de solicitações em lote. As imagens podem ser fornecidas como entrada por meio doURL da imagem ou de uma representação codificada em base64 da imagem. No momento, não há suporte para imagens para lote com GPT-4 Turbo.
Posso usar a API do lote com modelos ajustados?
Não há suporte para esse recurso no momento.
Posso usar a API do lote para modelos de inserção?
Não há suporte para esse recurso no momento.
A filtragem de conteúdo funciona com a implantação do Lote Global?
Sim. Semelhante a outros tipos de implantação, você poderá criar filtros de conteúdo e associá-los ao tipo de implantação do Lote Global.
Posso solicitar cota adicional?
Sim, na página de cotas no portal do Azure AI Foundry. A alocação de cota padrão pode ser encontrada no artigo de cota e limites.
O que acontece se a API não concluir minha solicitação dentro do período de 24 horas?
Nosso objetivo é processar essas solicitações dentro de 24 horas; não expiramos os trabalhos que levam mais tempo. Você poderá cancelar o trabalho a qualquer momento. Ao cancelar o trabalho, qualquer trabalho restante é cancelado e qualquer trabalho já concluído é retornado. Você será cobrado por qualquer trabalho concluído.
Quantas solicitações posso fazer fila usando o lote?
Não há nenhum limite fixo no número de solicitações que você poderá fazer em lote, no entanto, isso dependerá da cota de token enfileirada. Sua cota de token enfileirada inclui o número máximo de tokens de entrada que você poderá enfileirar ao mesmo tempo.
Depois que a solicitação em lote for concluída, o limite de taxa de lote será redefinido, pois os tokens de entrada serão limpos. O limite depende do número de solicitações globais na fila. Se a fila da API do Lote processar seus lotes rapidamente, o limite de taxa de lote será redefinido mais rapidamente.
Solução de problemas
Um trabalho é bem-sucedido quando status é Completed. Trabalhos bem-sucedidos ainda gerarão um error_file_id, mas ele será associado a um arquivo vazio com zero bytes.
Quando ocorrer uma falha no trabalho, você encontrará detalhes sobre a falha na errors propriedade:
"value": [
{
"id": "batch_80f5ad38-e05b-49bf-b2d6-a799db8466da",
"completion_window": "24h",
"created_at": 1725419394,
"endpoint": "/chat/completions",
"input_file_id": "file-c2d9a7881c8a466285e6f76f6321a681",
"object": "batch",
"status": "failed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1725419955,
"error_file_id": "file-3b0f9beb-11ce-4796-bc31-d54e675f28fb",
"errors": {
"object": “list”,
"data": [
{
“code”: “empty_file”,
“message”: “The input file is empty. Please ensure that the batch contains at least one request.”
}
]
},
"expired_at": null,
"expires_at": 1725505794,
"failed_at": null,
"finalizing_at": 1725419710,
"in_progress_at": 1725419572,
"metadata": null,
"output_file_id": "file-ef12af98-dbbc-4d27-8309-2df57feed572",
"request_counts": {
"total": 10,
"completed": null,
"failed": null
},
}
Códigos do Erro
| Código do erro | Definição |
|---|---|
invalid_json_line |
Uma linha (ou várias) no arquivo de entrada não pôde ser analisada como json válida. Verifique se não há erros de digitação, colchetes de abertura e fechamento adequados e aspas de acordo com o padrão do JSON e reenvie a solicitação. |
too_many_tasks |
O número de solicitações no arquivo de entrada excede o valor máximo permitido de 100.000. Verifique se o total de solicitações está abaixo de 100.000 e reenvie o trabalho. |
url_mismatch |
Uma linha no arquivo de entrada tem um URL que não corresponde ao restante das linhas ou o URL especificado no arquivo de entrada não corresponde ao URL do ponto de extremidade esperada. Verifique se todos os URLs de solicitação são iguais e se correspondem ao URL do ponto de extremidade associada à implantação do OpenAI do Azure. |
model_not_found |
O nome de implantação do modelo do OpenAI do Azure especificado na propriedade model do arquivo de entrada não foi encontrado.Verifique se esse nome aponta para uma implantação de modelo válida do OpenAI do Azure. |
duplicate_custom_id |
A ID personalizada dessa solicitação é uma duplicata da ID personalizada em outra solicitação. |
empty_batch |
Verifique o arquivo de entrada para garantir que o parâmetro de ID personalizado seja exclusivo para cada solicitação no lote. |
model_mismatch |
O nome de implantação do modelo do OpenAI do Azure especificado na propriedade model dessa solicitação no arquivo de entrada não corresponde ao restante do arquivo.Verifique se todas as solicitações no lote apontam para a mesma implantação de modelo do Serviço OpenAI do Azure na propriedade model da solicitação. |
invalid_request |
O esquema da linha de entrada é inválido ou o SKU de implantação é inválido. Verifique se as propriedades da solicitação no arquivo de entrada correspondem às propriedades de entrada esperadas e se a SKU de implantação do OpenAI do Azure é globalbatch para solicitações de API em lote. |
Problemas conhecidos
- Os recursos implantados com a CLI do Azure não funcionarão prontamente com o lote global do OpenAI do Azure. Isso ocorre devido a um problema em que os recursos implantados usando esse método têm subdomínios de ponto de extremidade que não seguem o padrão
https://your-resource-name.openai.azure.com. Uma solução alternativa para esse problema é implantar um novo recurso do OpenAI do Azure usando um dos outros métodos de implantação comuns que manipularão corretamente a configuração do subdomínio como parte do processo de implantação.
Confira também
- Saiba mais sobre os tipos de implantação do OpenAI do Azure
- Saiba mais sobre as cotas e limites do OpenAI do Azure