Início Rápido: comece a usar a geração de áudio do OpenAI do Azure
O modelo gpt-4o-audio-preview apresenta a modalidade de áudio na API /chat/completions existente. O modelo de áudio expande o potencial para aplicativos de IA em interações baseadas em texto e voz e análise de áudio. As modalidades com suporte no modelo gpt-4o-audio-preview incluem: texto, áudio e texto + áudio.
Confira aqui uma tabela das modalidades com suporte com casos de uso de exemplo:
| Entrada de modalidade | Saída de modalidade | Caso de uso de exemplo |
|---|---|---|
| Texto | Texto + áudio | Conversão de texto em fala, geração de audiolivro |
| Áudio | Texto + áudio | Transcrição de áudio, geração de audiolivro |
| Áudio | Texto | Transcrição de áudio |
| Texto + áudio | Texto + áudio | Geração de audiolivro |
| Texto + áudio | Texto | Transcrição de áudio |
Usando recursos de geração de áudio, você pode obter aplicativos de IA mais dinâmicos e interativos. Modelos que dão suporte a entradas e saídas de áudio permitem que você gere respostas de áudio faladas para solicitações e use entradas de áudio para solicitar ao modelo.
Modelos com suporte
Atualmente, apenas a versão gpt-4o-audio-preview: 2024-12-17 dá suporte a geração áudio.
O modelo gpt-4o-audio-preview está disponível para implantações globais nas regiões Leste dos EUA 2 e Suécia Central.
Atualmente, há suporte para as seguintes vozes para saída de áudio: Alloy, Echo e Shimmer.
O arquivo de áudio pode ter no máximo 20 MB.
Observação
A API Realtime usa o mesmo modelo subjacente de áudio do GPT-4o para a API de conclusões, mas é otimizada para interações de áudio em tempo real com baixa latência.
Suporte a API
O suporte para conclusões de áudio foi adicionado pela primeira vez na versão 2025-01-01-preview da API.
Implantar um modelo para geração de áudio
Para implantar o modelo gpt-4o-audio-preview no portal do Azure AI Foundry:
- Acesse a página do Serviço OpenAI do Azure no portal do Azure AI Foundry. Verifique se você está conectado com a assinatura do Azure que tem o recurso do Serviço OpenAI do Azure e o modelo
gpt-4o-audio-previewimplantado. - Selecione o playground de Chat em Playgrounds no painel esquerdo.
- Selecione + Criar implantação>De modelos de base para abrir a janela de implantação.
- Pesquise e selecione o modelo
gpt-4o-audio-previewe selecione Implantar no recurso selecionado. - No assistente de implantação, selecione a versão do modelo
2024-12-17. - Siga o assistente para concluir a implantação do modelo.
Agora que você tem uma implantação do modelo gpt-4o-audio-preview, pode interagir com ele no portal da Fábrica de IA do Azure, no playground de Chat ou na API de conclusões de chat.
Usar a geração de áudio do GPT-4o
Para conversar com o modelo gpt-4o-audio-preview implantado no playground de Chat do portal da Fábrica de IA do Azure, siga essas etapas:
Acesse a página do Serviço OpenAI do Azure no portal do Azure AI Foundry. Verifique se você está conectado com a assinatura do Azure que tem o recurso do Serviço OpenAI do Azure e o modelo
gpt-4o-audio-previewimplantado.Selecione o playground de Chat no Playground de recursos no painel esquerdo.
Selecione o modelo
gpt-4o-audio-previewimplantado na lista de seleção Implantação.Comece a conversar com o modelo e ouça as respostas de áudio.
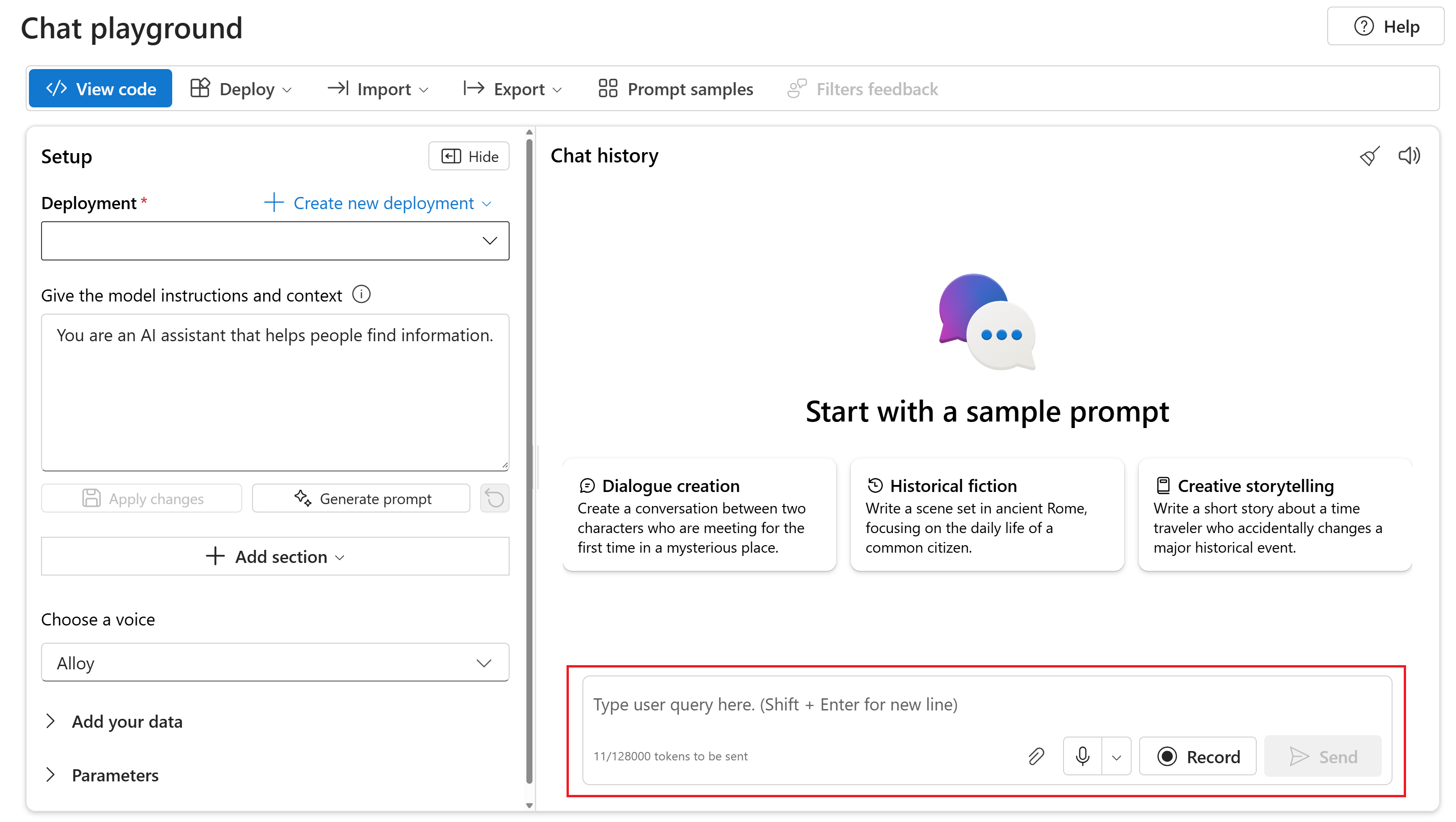
Você poderá:
- Grave solicitações de áudio.
- Anexe arquivos de áudio ao chat.
- Insira solicitações de texto.

Documentação de referência | Código-fonte da biblioteca | Pacote (npm) | Exemplos
O modelo gpt-4o-audio-preview apresenta a modalidade de áudio na API /chat/completions existente. O modelo de áudio expande o potencial para aplicativos de IA em interações baseadas em texto e voz e análise de áudio. As modalidades com suporte no modelo gpt-4o-audio-preview incluem: texto, áudio e texto + áudio.
Confira aqui uma tabela das modalidades com suporte com casos de uso de exemplo:
| Entrada de modalidade | Saída de modalidade | Caso de uso de exemplo |
|---|---|---|
| Texto | Texto + áudio | Conversão de texto em fala, geração de audiolivro |
| Áudio | Texto + áudio | Transcrição de áudio, geração de audiolivro |
| Áudio | Texto | Transcrição de áudio |
| Texto + áudio | Texto + áudio | Geração de audiolivro |
| Texto + áudio | Texto | Transcrição de áudio |
Usando recursos de geração de áudio, você pode obter aplicativos de IA mais dinâmicos e interativos. Modelos que dão suporte a entradas e saídas de áudio permitem que você gere respostas de áudio faladas para solicitações e use entradas de áudio para solicitar ao modelo.
Modelos com suporte
Atualmente, apenas a versão gpt-4o-audio-preview: 2024-12-17 dá suporte a geração áudio.
O modelo gpt-4o-audio-preview está disponível para implantações globais nas regiões Leste dos EUA 2 e Suécia Central.
Atualmente, há suporte para as seguintes vozes para saída de áudio: Alloy, Echo e Shimmer.
O arquivo de áudio pode ter no máximo 20 MB.
Observação
A API Realtime usa o mesmo modelo subjacente de áudio do GPT-4o para a API de conclusões, mas é otimizada para interações de áudio em tempo real com baixa latência.
Suporte a API
O suporte para conclusões de áudio foi adicionado pela primeira vez na versão 2025-01-01-preview da API.
Pré-requisitos
- Uma assinatura do Azure – crie uma gratuitamente
- Suporte a Node.js LTS ou ESM.
- Um recurso do OpenAI do Azure criado nas regiões Leste dos EUA 2 ou Suécia Central. Confira a Disponibilidade de região.
- Em seguida, você precisa implantar um modelo
gpt-4o-audio-previewcom o recurso do OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
Pré-requisitos do Microsoft Entra ID
Para a autenticação sem chave recomendada com o Microsoft Entra ID, você precisa:
- Instale a CLI do Azure usada para autenticação sem chave com o Microsoft Entra ID.
- Atribua a função de
Cognitive Services Userà sua conta de usuário. Você pode atribuir funções no portal do Azure em Controle de acesso (IAM)>Adicionar atribuição de função.
Configuração
Crie uma nova pasta
audio-completions-quickstartpara conter o aplicativo e abra o Visual Studio Code nessa pasta com o seguinte comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCrie o
package.jsoncom o seguinte comando:npm init -yAtualize o
package.jsonpara ECMAScript com o seguinte comando:npm pkg set type=moduleInstale a biblioteca de clientes do OpenAI para JavaScript com:
npm install openaiPara a autenticação sem chave recomendada com o Microsoft Entra ID, instale o pacote
@azure/identitycom:npm install @azure/identity
Recuperar as informações do recurso
Você precisa recuperar as seguintes informações para autenticar seu aplicativo com seu recurso do OpenAI do Azure:
| Nome da variável | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Esse valor pode ser encontrado na seção Chaves e Ponto de Extremidade ao examinar seu recurso no portal do Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Esse valor corresponderá ao nome personalizado escolhido para sua implantação ao implantar um modelo. Esse valor pode ser encontrado em Gerenciamento de Recursos>Implantações de Modelos no portal do Azure. |
OPENAI_API_VERSION |
Saiba mais sobre as Versões de API. |
Saiba mais sobre autenticação sem chave e configuração de variáveis de ambiente.
Cuidado
Para usar a autenticação sem chave recomendada com o SDK, verifique se a variável de ambiente AZURE_OPENAI_API_KEY não está definida.
Gerar áudio com base na entrada de texto
Crie o arquivo
to-audio.jscom o seguinte código:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Entre no Azure com o seguinte comando:
az loginExecute o arquivo JavaScript.
node to-audio.js
Leva alguns minutos para obter a resposta.
Saída de geração de áudio com base na entrada de texto
O script gera um arquivo de áudio chamado dog.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada à solicitação: "Um golden retriever é um bom cão de família?"
Gerar áudio e texto com base na entrada de áudio
Crie o arquivo
from-audio.jscom o seguinte código:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; const { writeFileSync } = require("node:fs"); // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file writeFileSync( "analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Entre no Azure com o seguinte comando:
az loginExecute o arquivo JavaScript.
node from-audio.js
Leva alguns minutos para obter a resposta.
Saída de geração de áudio e texto com base na entrada de áudio
O script gera uma transcrição do resumo da entrada de áudio falada. Ele também gera um arquivo de áudio chamado analysis.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada para a solicitação.
Gerar áudio e usar conclusões de chat com várias rodadas
Crie o arquivo
multi-turn.jscom o seguinte código:require("dotenv").config(); const { AzureOpenAI } = require("openai"); const { DefaultAzureCredential, getBearerTokenProvider } = require("@azure/identity"); const fs = require('fs').promises; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); // Set environment variables or edit the corresponding values here. const endpoint = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion = "2025-01-01-preview"; const deployment = "gpt-4o-audio-preview"; const client = new AzureOpenAI({ endpoint, azureADTokenProvider, apiVersion, deployment }); async function main() { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: { id: response.choices[0].message.audio.id } }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err) => { console.error("Error occurred:", err); }); module.exports = { main };Entre no Azure com o seguinte comando:
az loginExecute o arquivo JavaScript.
node multi-turn.js
Leva alguns minutos para obter a resposta.
Saída de conclusões de chat com várias rodadas
O script gera uma transcrição do resumo da entrada de áudio falada. Em seguida, ele faz uma conclusão de chat com várias rodadas para resumir brevemente a entrada de áudio falada.
Código-fonte da biblioteca | Pacote | Amostras
O modelo gpt-4o-audio-preview apresenta a modalidade de áudio na API /chat/completions existente. O modelo de áudio expande o potencial para aplicativos de IA em interações baseadas em texto e voz e análise de áudio. As modalidades com suporte no modelo gpt-4o-audio-preview incluem: texto, áudio e texto + áudio.
Confira aqui uma tabela das modalidades com suporte com casos de uso de exemplo:
| Entrada de modalidade | Saída de modalidade | Caso de uso de exemplo |
|---|---|---|
| Texto | Texto + áudio | Conversão de texto em fala, geração de audiolivro |
| Áudio | Texto + áudio | Transcrição de áudio, geração de audiolivro |
| Áudio | Texto | Transcrição de áudio |
| Texto + áudio | Texto + áudio | Geração de audiolivro |
| Texto + áudio | Texto | Transcrição de áudio |
Usando recursos de geração de áudio, você pode obter aplicativos de IA mais dinâmicos e interativos. Modelos que dão suporte a entradas e saídas de áudio permitem que você gere respostas de áudio faladas para solicitações e use entradas de áudio para solicitar ao modelo.
Modelos com suporte
Atualmente, apenas a versão gpt-4o-audio-preview: 2024-12-17 dá suporte a geração áudio.
O modelo gpt-4o-audio-preview está disponível para implantações globais nas regiões Leste dos EUA 2 e Suécia Central.
Atualmente, há suporte para as seguintes vozes para saída de áudio: Alloy, Echo e Shimmer.
O arquivo de áudio pode ter no máximo 20 MB.
Observação
A API Realtime usa o mesmo modelo subjacente de áudio do GPT-4o para a API de conclusões, mas é otimizada para interações de áudio em tempo real com baixa latência.
Suporte a API
O suporte para conclusões de áudio foi adicionado pela primeira vez na versão 2025-01-01-preview da API.
Use este guia para começar a gerar áudio com o SDK do OpenAI do Azure para Python.
Pré-requisitos
- Uma assinatura do Azure. Crie um gratuitamente.
- Python 3.8 ou versão posterior. É recomendável usar o Python 3.10 ou posterior, mas ter pelo menos Python 3.8 é necessário. Se você não tiver uma versão adequada do Python instalada, poderá seguir as instruções no Tutorial do Python do VS Code para obter a maneira mais fácil de instalar o Python em seu sistema operacional.
- Um recurso do OpenAI do Azure criado nas regiões Leste dos EUA 2 ou Suécia Central. Confira a Disponibilidade de região.
- Em seguida, você precisa implantar um modelo
gpt-4o-audio-previewcom o recurso do OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
Pré-requisitos do Microsoft Entra ID
Para a autenticação sem chave recomendada com o Microsoft Entra ID, você precisa:
- Instale a CLI do Azure usada para autenticação sem chave com o Microsoft Entra ID.
- Atribua a função de
Cognitive Services Userà sua conta de usuário. Você pode atribuir funções no portal do Azure em Controle de acesso (IAM)>Adicionar atribuição de função.
Configuração
Crie uma nova pasta
audio-completions-quickstartpara conter o aplicativo e abra o Visual Studio Code nessa pasta com o seguinte comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCrie um ambiente virtual. Se você já tiver o Python 3.10 ou superior instalado, crie um ambiente virtual usando os seguintes comandos:
Ativar o ambiente Python significa que, ao executar
pythonoupipna linha de comando, você usará o interpretador Python contido na pasta.venvdo seu aplicativo. Você pode usar o comandodeactivatepara sair do ambiente virtual do Python e depois reativar quando necessário.Dica
Recomendamos que você crie e ative um novo ambiente Python para usar para instalar os pacotes necessários para este tutorial. Não instale pacotes na instalação global do Python. Você sempre deve usar um ambiente virtual ou do Conda ao instalar pacotes do Python, caso contrário, poderá interromper a instalação global do Python.
Instale a biblioteca de clientes do OpenAI para Python com:
pip install openaiPara a autenticação sem chave recomendada com o Microsoft Entra ID, instale o pacote
azure-identitycom:pip install azure-identity
Recuperar as informações do recurso
Você precisa recuperar as seguintes informações para autenticar seu aplicativo com seu recurso do OpenAI do Azure:
| Nome da variável | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Esse valor pode ser encontrado na seção Chaves e Ponto de Extremidade ao examinar seu recurso no portal do Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Esse valor corresponderá ao nome personalizado escolhido para sua implantação ao implantar um modelo. Esse valor pode ser encontrado em Gerenciamento de Recursos>Implantações de Modelos no portal do Azure. |
OPENAI_API_VERSION |
Saiba mais sobre as Versões de API. |
Saiba mais sobre autenticação sem chave e configuração de variáveis de ambiente.
Gerar áudio com base na entrada de texto
Crie o arquivo
to-audio.pycom o seguinte código:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Make the audio chat completions request completion=client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": "Is a golden retriever a good family dog?" } ] ) print(completion.choices[0]) # Write the output audio data to a file wav_bytes=base64.b64decode(completion.choices[0].message.audio.data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Execute o arquivo Python.
python to-audio.py
Leva alguns minutos para obter a resposta.
Saída de geração de áudio com base na entrada de texto
O script gera um arquivo de áudio chamado dog.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada à solicitação: "Um golden retriever é um bom cão de família?"
Gerar áudio e texto com base na entrada de áudio
Crie o arquivo
from-audio.pycom o seguinte código:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Make the audio chat completions request completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=[ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] ) print(completion.choices[0].message.audio.transcript) # Write the output audio data to a file wav_bytes = base64.b64decode(completion.choices[0].message.audio.data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Execute o arquivo Python.
python from-audio.py
Leva alguns minutos para obter a resposta.
Saída de geração de áudio e texto com base na entrada de áudio
O script gera uma transcrição do resumo da entrada de áudio falada. Ele também gera um arquivo de áudio chamado analysis.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada para a solicitação.
Gerar áudio e usar conclusões de chat com várias rodadas
Crie o arquivo
multi-turn.pycom o seguinte código:import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential, get_bearer_token_provider token_provider=get_bearer_token_provider(DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default") # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication client=AzureOpenAI( azure_ad_token_provider=token_provider, azure_endpoint=endpoint, api_version="2025-01-01-preview" ) # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] # Get the first turn's response completion = client.chat.completions.create( model="gpt-4o-audio-preview", modalities=["text", "audio"], audio={"voice": "alloy", "format": "wav"}, messages=messages ) print("Get the first turn's response:") print(completion.choices[0].message.audio.transcript) print("Add a history message referencing the first turn's audio by ID:") print(completion.choices[0].message.audio.id) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.choices[0].message.audio.id } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) # Send the follow-up request with the accumulated messages completion = client.chat.completions.create( model="gpt-4o-audio-preview", messages=messages ) print("Very briefly, summarize the favorability.") print(completion.choices[0].message.content)Execute o arquivo Python.
python multi-turn.py
Leva alguns minutos para obter a resposta.
Saída de conclusões de chat com várias rodadas
O script gera uma transcrição do resumo da entrada de áudio falada. Em seguida, ele faz uma conclusão de chat com várias rodadas para resumir brevemente a entrada de áudio falada.
O modelo gpt-4o-audio-preview apresenta a modalidade de áudio na API /chat/completions existente. O modelo de áudio expande o potencial para aplicativos de IA em interações baseadas em texto e voz e análise de áudio. As modalidades com suporte no modelo gpt-4o-audio-preview incluem: texto, áudio e texto + áudio.
Confira aqui uma tabela das modalidades com suporte com casos de uso de exemplo:
| Entrada de modalidade | Saída de modalidade | Caso de uso de exemplo |
|---|---|---|
| Texto | Texto + áudio | Conversão de texto em fala, geração de audiolivro |
| Áudio | Texto + áudio | Transcrição de áudio, geração de audiolivro |
| Áudio | Texto | Transcrição de áudio |
| Texto + áudio | Texto + áudio | Geração de audiolivro |
| Texto + áudio | Texto | Transcrição de áudio |
Usando recursos de geração de áudio, você pode obter aplicativos de IA mais dinâmicos e interativos. Modelos que dão suporte a entradas e saídas de áudio permitem que você gere respostas de áudio faladas para solicitações e use entradas de áudio para solicitar ao modelo.
Modelos com suporte
Atualmente, apenas a versão gpt-4o-audio-preview: 2024-12-17 dá suporte a geração áudio.
O modelo gpt-4o-audio-preview está disponível para implantações globais nas regiões Leste dos EUA 2 e Suécia Central.
Atualmente, há suporte para as seguintes vozes para saída de áudio: Alloy, Echo e Shimmer.
O arquivo de áudio pode ter no máximo 20 MB.
Observação
A API Realtime usa o mesmo modelo subjacente de áudio do GPT-4o para a API de conclusões, mas é otimizada para interações de áudio em tempo real com baixa latência.
Suporte a API
O suporte para conclusões de áudio foi adicionado pela primeira vez na versão 2025-01-01-preview da API.
Pré-requisitos
- Uma assinatura do Azure. Crie um gratuitamente.
- Python 3.8 ou versão posterior. É recomendável usar o Python 3.10 ou posterior, mas ter pelo menos Python 3.8 é necessário. Se você não tiver uma versão adequada do Python instalada, poderá seguir as instruções no Tutorial do Python do VS Code para obter a maneira mais fácil de instalar o Python em seu sistema operacional.
- Um recurso do OpenAI do Azure criado nas regiões Leste dos EUA 2 ou Suécia Central. Confira a Disponibilidade de região.
- Em seguida, você precisa implantar um modelo
gpt-4o-audio-previewcom o recurso do OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
Pré-requisitos do Microsoft Entra ID
Para a autenticação sem chave recomendada com o Microsoft Entra ID, você precisa:
- Instale a CLI do Azure usada para autenticação sem chave com o Microsoft Entra ID.
- Atribua a função de
Cognitive Services Userà sua conta de usuário. Você pode atribuir funções no portal do Azure em Controle de acesso (IAM)>Adicionar atribuição de função.
Configuração
Crie uma nova pasta
audio-completions-quickstartpara conter o aplicativo e abra o Visual Studio Code nessa pasta com o seguinte comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCrie um ambiente virtual. Se você já tiver o Python 3.10 ou superior instalado, crie um ambiente virtual usando os seguintes comandos:
Ativar o ambiente Python significa que, ao executar
pythonoupipna linha de comando, você usará o interpretador Python contido na pasta.venvdo seu aplicativo. Você pode usar o comandodeactivatepara sair do ambiente virtual do Python e depois reativar quando necessário.Dica
Recomendamos que você crie e ative um novo ambiente Python para usar para instalar os pacotes necessários para este tutorial. Não instale pacotes na instalação global do Python. Você sempre deve usar um ambiente virtual ou do Conda ao instalar pacotes do Python, caso contrário, poderá interromper a instalação global do Python.
Instale a biblioteca de clientes do OpenAI para Python com:
pip install openaiPara a autenticação sem chave recomendada com o Microsoft Entra ID, instale o pacote
azure-identitycom:pip install azure-identity
Recuperar as informações do recurso
Você precisa recuperar as seguintes informações para autenticar seu aplicativo com seu recurso do OpenAI do Azure:
| Nome da variável | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Esse valor pode ser encontrado na seção Chaves e Ponto de Extremidade ao examinar seu recurso no portal do Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Esse valor corresponderá ao nome personalizado escolhido para sua implantação ao implantar um modelo. Esse valor pode ser encontrado em Gerenciamento de Recursos>Implantações de Modelos no portal do Azure. |
OPENAI_API_VERSION |
Saiba mais sobre as Versões de API. |
Saiba mais sobre autenticação sem chave e configuração de variáveis de ambiente.
Gerar áudio com base na entrada de texto
Crie o arquivo
to-audio.pycom o seguinte código:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Is a golden retriever a good family dog?" } ] } ] } # Make the audio chat completions request completion = requests.post(url, headers=headers, json=body) audio_data = completion.json()['choices'][0]['message']['audio']['data'] # Write the output audio data to a file wav_bytes = base64.b64decode(audio_data) with open("dog.wav", "wb") as f: f.write(wav_bytes)Execute o arquivo Python.
python to-audio.py
Leva alguns minutos para obter a resposta.
Saída de geração de áudio com base na entrada de texto
O script gera um arquivo de áudio chamado dog.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada à solicitação: "Um golden retriever é um bom cão de família?"
Gerar áudio e texto com base na entrada de áudio
Crie o arquivo
from-audio.pycom o seguinte código:import requests import base64 import os from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }, ] } completion = requests.post(url, headers=headers, json=body) print(completion.json()['choices'][0]['message']['audio']['transcript']) # Write the output audio data to a file audio_data = completion.json()['choices'][0]['message']['audio']['data'] wav_bytes = base64.b64decode(audio_data) with open("analysis.wav", "wb") as f: f.write(wav_bytes)Execute o arquivo Python.
python from-audio.py
Leva alguns minutos para obter a resposta.
Saída de geração de áudio e texto com base na entrada de áudio
O script gera uma transcrição do resumo da entrada de áudio falada. Ele também gera um arquivo de áudio chamado analysis.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada para a solicitação.
Gerar áudio e usar conclusões de chat com várias rodadas
Crie o arquivo
multi-turn.pycom o seguinte código:import requests import base64 import os from openai import AzureOpenAI from azure.identity import DefaultAzureCredential # Set environment variables or edit the corresponding values here. endpoint = os.environ['AZURE_OPENAI_ENDPOINT'] # Keyless authentication credential = DefaultAzureCredential() token = credential.get_token("https://cognitiveservices.azure.com/.default") api_version = '2025-01-01-preview' url = f"{endpoint}/openai/deployments/gpt-4o-audio-preview/chat/completions?api-version={api_version}" headers= { "Authorization": f"Bearer {token.token}", "Content-Type": "application/json" } # Read and encode audio file with open('dog.wav', 'rb') as wav_reader: encoded_string = base64.b64encode(wav_reader.read()).decode('utf-8') # Initialize messages with the first turn's user input messages = [ { "role": "user", "content": [ { "type": "text", "text": "Describe in detail the spoken audio input." }, { "type": "input_audio", "input_audio": { "data": encoded_string, "format": "wav" } } ] }] body = { "modalities": ["audio", "text"], "model": "gpt-4o-audio-preview", "audio": { "format": "wav", "voice": "alloy" }, "messages": messages } # Get the first turn's response, including generated audio completion = requests.post(url, headers=headers, json=body) print("Get the first turn's response:") print(completion.json()['choices'][0]['message']['audio']['transcript']) print("Add a history message referencing the first turn's audio by ID:") print(completion.json()['choices'][0]['message']['audio']['id']) # Add a history message referencing the first turn's audio by ID messages.append({ "role": "assistant", "audio": { "id": completion.json()['choices'][0]['message']['audio']['id'] } }) # Add the next turn's user message messages.append({ "role": "user", "content": "Very briefly, summarize the favorability." }) body = { "model": "gpt-4o-audio-preview", "messages": messages } # Send the follow-up request with the accumulated messages completion = requests.post(url, headers=headers, json=body) print("Very briefly, summarize the favorability.") print(completion.json()['choices'][0]['message']['content'])Execute o arquivo Python.
python multi-turn.py
Leva alguns minutos para obter a resposta.
Saída de conclusões de chat com várias rodadas
O script gera uma transcrição do resumo da entrada de áudio falada. Em seguida, ele faz uma conclusão de chat com várias rodadas para resumir brevemente a entrada de áudio falada.
Documentação de referência | Código-fonte da biblioteca | Pacote (npm) | Exemplos
O modelo gpt-4o-audio-preview apresenta a modalidade de áudio na API /chat/completions existente. O modelo de áudio expande o potencial para aplicativos de IA em interações baseadas em texto e voz e análise de áudio. As modalidades com suporte no modelo gpt-4o-audio-preview incluem: texto, áudio e texto + áudio.
Confira aqui uma tabela das modalidades com suporte com casos de uso de exemplo:
| Entrada de modalidade | Saída de modalidade | Caso de uso de exemplo |
|---|---|---|
| Texto | Texto + áudio | Conversão de texto em fala, geração de audiolivro |
| Áudio | Texto + áudio | Transcrição de áudio, geração de audiolivro |
| Áudio | Texto | Transcrição de áudio |
| Texto + áudio | Texto + áudio | Geração de audiolivro |
| Texto + áudio | Texto | Transcrição de áudio |
Usando recursos de geração de áudio, você pode obter aplicativos de IA mais dinâmicos e interativos. Modelos que dão suporte a entradas e saídas de áudio permitem que você gere respostas de áudio faladas para solicitações e use entradas de áudio para solicitar ao modelo.
Modelos com suporte
Atualmente, apenas a versão gpt-4o-audio-preview: 2024-12-17 dá suporte a geração áudio.
O modelo gpt-4o-audio-preview está disponível para implantações globais nas regiões Leste dos EUA 2 e Suécia Central.
Atualmente, há suporte para as seguintes vozes para saída de áudio: Alloy, Echo e Shimmer.
O arquivo de áudio pode ter no máximo 20 MB.
Observação
A API Realtime usa o mesmo modelo subjacente de áudio do GPT-4o para a API de conclusões, mas é otimizada para interações de áudio em tempo real com baixa latência.
Suporte a API
O suporte para conclusões de áudio foi adicionado pela primeira vez na versão 2025-01-01-preview da API.
Pré-requisitos
- Uma assinatura do Azure – crie uma gratuitamente
- Suporte a Node.js LTS ou ESM.
- TypeScript instalado globalmente.
- Um recurso do OpenAI do Azure criado nas regiões Leste dos EUA 2 ou Suécia Central. Confira a Disponibilidade de região.
- Em seguida, você precisa implantar um modelo
gpt-4o-audio-previewcom o recurso do OpenAI do Azure. Para obter mais informações, consulte Criar um recurso e implantar um modelo com o Azure OpenAI.
Pré-requisitos do Microsoft Entra ID
Para a autenticação sem chave recomendada com o Microsoft Entra ID, você precisa:
- Instale a CLI do Azure usada para autenticação sem chave com o Microsoft Entra ID.
- Atribua a função de
Cognitive Services Userà sua conta de usuário. Você pode atribuir funções no portal do Azure em Controle de acesso (IAM)>Adicionar atribuição de função.
Configuração
Crie uma nova pasta
audio-completions-quickstartpara conter o aplicativo e abra o Visual Studio Code nessa pasta com o seguinte comando:mkdir audio-completions-quickstart && code audio-completions-quickstartCrie o
package.jsoncom o seguinte comando:npm init -yAtualize o
package.jsonpara ECMAScript com o seguinte comando:npm pkg set type=moduleInstale a biblioteca de clientes do OpenAI para JavaScript com:
npm install openaiPara a autenticação sem chave recomendada com o Microsoft Entra ID, instale o pacote
@azure/identitycom:npm install @azure/identity
Recuperar as informações do recurso
Você precisa recuperar as seguintes informações para autenticar seu aplicativo com seu recurso do OpenAI do Azure:
| Nome da variável | Valor |
|---|---|
AZURE_OPENAI_ENDPOINT |
Esse valor pode ser encontrado na seção Chaves e Ponto de Extremidade ao examinar seu recurso no portal do Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Esse valor corresponderá ao nome personalizado escolhido para sua implantação ao implantar um modelo. Esse valor pode ser encontrado em Gerenciamento de Recursos>Implantações de Modelos no portal do Azure. |
OPENAI_API_VERSION |
Saiba mais sobre as Versões de API. |
Saiba mais sobre autenticação sem chave e configuração de variáveis de ambiente.
Cuidado
Para usar a autenticação sem chave recomendada com o SDK, verifique se a variável de ambiente AZURE_OPENAI_API_KEY não está definida.
Gerar áudio com base na entrada de texto
Crie o arquivo
to-audio.tscom o seguinte código:import { writeFileSync } from "node:fs"; import { AzureOpenAI } from "openai/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: "Is a golden retriever a good family dog?" } ] }); // Inspect returned data console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync( "dog.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" } ); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Crie o arquivo
tsconfig.jsonpara transpilar o código TypeScript e copiar o código a seguir para ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile de TypeScript para JavaScript.
tscEntre no Azure com o seguinte comando:
az loginExecute o código com o seguinte comando:
node to-audio.js
Leva alguns minutos para obter a resposta.
Saída de geração de áudio com base na entrada de texto
O script gera um arquivo de áudio chamado dog.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada à solicitação: "Um golden retriever é um bom cão de família?"
Gerar áudio e texto com base na entrada de áudio
Crie o arquivo
from-audio.tscom o seguinte código:import { AzureOpenAI } from "openai"; import { writeFileSync } from "node:fs"; import { promises as fs } from 'fs'; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Make the audio chat completions request const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ] }); console.log(response.choices[0]); // Write the output audio data to a file if (response.choices[0].message.audio) { writeFileSync("analysis.wav", Buffer.from(response.choices[0].message.audio.data, 'base64'), { encoding: "utf-8" }); } else { console.error("Audio data is null or undefined."); } } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Crie o arquivo
tsconfig.jsonpara transpilar o código TypeScript e copiar o código a seguir para ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile de TypeScript para JavaScript.
tscEntre no Azure com o seguinte comando:
az loginExecute o código com o seguinte comando:
node from-audio.js
Leva alguns minutos para obter a resposta.
Saída de geração de áudio e texto com base na entrada de áudio
O script gera uma transcrição do resumo da entrada de áudio falada. Ele também gera um arquivo de áudio chamado analysis.wav no mesmo diretório que o script. O arquivo de áudio contém a resposta falada para a solicitação.
Gerar áudio e usar conclusões de chat com várias rodadas
Crie o arquivo
multi-turn.tscom o seguinte código:import { AzureOpenAI } from "openai/index.mjs"; import { promises as fs } from 'fs'; import { ChatCompletionMessageParam } from "openai/resources/index.mjs"; import { DefaultAzureCredential, getBearerTokenProvider, } from "@azure/identity"; // Set environment variables or edit the corresponding values here. const endpoint: string = process.env["AZURE_OPENAI_ENDPOINT"] || "AZURE_OPENAI_ENDPOINT"; const apiVersion: string = "2025-01-01-preview"; const deployment: string = "gpt-4o-audio-preview"; // Keyless authentication const getClient = (): AzureOpenAI => { const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const client = new AzureOpenAI({ endpoint: endpoint, apiVersion: apiVersion, azureADTokenProvider, }); return client; }; const client = getClient(); async function main(): Promise<void> { // Buffer the audio for input to the chat completion const wavBuffer = await fs.readFile("dog.wav"); const base64str = Buffer.from(wavBuffer).toString("base64"); // Initialize messages with the first turn's user input const messages: ChatCompletionMessageParam[] = [ { role: "user", content: [ { type: "text", text: "Describe in detail the spoken audio input." }, { type: "input_audio", input_audio: { data: base64str, format: "wav" } } ] } ]; // Get the first turn's response const response = await client.chat.completions.create({ model: "gpt-4o-audio-preview", modalities: ["text", "audio"], audio: { voice: "alloy", format: "wav" }, messages: messages }); console.log(response.choices[0]); // Add a history message referencing the previous turn's audio by ID messages.push({ role: "assistant", audio: response.choices[0].message.audio ? { id: response.choices[0].message.audio.id } : undefined }); // Add a new user message for the second turn messages.push({ role: "user", content: [ { type: "text", text: "Very concisely summarize the favorability." } ] }); // Send the follow-up request with the accumulated messages const followResponse = await client.chat.completions.create({ model: "gpt-4o-audio-preview", messages: messages }); console.log(followResponse.choices[0].message.content); } main().catch((err: Error) => { console.error("Error occurred:", err); }); export { main };Crie o arquivo
tsconfig.jsonpara transpilar o código TypeScript e copiar o código a seguir para ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile de TypeScript para JavaScript.
tscEntre no Azure com o seguinte comando:
az loginExecute o código com o seguinte comando:
node multi-turn.js
Leva alguns minutos para obter a resposta.
Saída de conclusões de chat com várias rodadas
O script gera uma transcrição do resumo da entrada de áudio falada. Em seguida, ele faz uma conclusão de chat com várias rodadas para resumir brevemente a entrada de áudio falada.
Recursos de limpeza
Caso queria limpar e remover um recurso OpenAI do Azure, é possível excluir o recurso. Antes de excluir o recurso, você deve primeiro excluir todos os modelos implantados.
Conteúdo relacionado
- Saiba mais sobre os tipos de implantação do OpenAI do Azure
- Saiba mais sobre as cotas e limites do OpenAI do Azure