Modelo de leitura da Informação de Documentos
Esse conteúdo se aplica a:![]() v4.0 (GA) | Versões anteriores:
v4.0 (GA) | Versões anteriores:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Observação
Para extrair texto de imagens externas, como rótulos, placas de rua e cartazes, use o recurso de leitura da Análise de Imagem v4.0 da IA do Azure otimizado para imagens gerais (e não documentos) com uma API síncrona aprimorada pelo desempenho. Essa funcionalidade facilita a inserção do OCR em cenários de experiência do usuário em tempo real.
O modelo OCR (Reconhecimento óptico de caracteres) de leitura da Informação de Documentos é executado em uma resolução mais alta do que a Pesquisa Visual da IA do Azure ; lê e extrai texto impresso e manuscrito de documentos PDF e imagens digitalizadas. Ele também inclui suporte para extrair texto de documentos do Microsoft Word, do Excel, do PowerPoint e de HTML. Ele detecta parágrafos, linhas de texto, palavras, locais e idiomas. O Modelo de Leitura é o mecanismo de OCR subjacente para outros modelos predefinidos da Informação de Documentos, como Layout, Documento Geral, Fatura, Recibo, Identidade (ID), cartão de seguro saúde, W2 além de modelos personalizados.
O que é o reconhecimento óptico de caracteres?
O OCR (Reconhecimento Óptico de Caracteres) para documentos é otimizado para documentos grandes com uso intenso de texto em vários formatos de arquivo e idiomas globais. Ele inclui recursos como verificação de maior resolução de imagens de documento para melhor manipulação de texto menor e denso; detecção de parágrafo e gerenciamento de formulário preenchível. Os recursos de OCR também incluem cenários avançados, como caixas de caracteres únicos e extração precisa de campos-chave comumente encontrados em faturas, recibos e outros cenários predefinidos.
Opções de desenvolvimento (v4)
O Document Intelligence v4.0: 2024-11-30 (GA) oferece suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Ler o modelo OCR | • Estúdio de Informação de Documentos • API REST • SDK do C# • SDK do Python • SDK do Java • SDK do JavaScript |
prebuilt-read |
Requisitos de entrada (v4)
Formatos de arquivo com suporte:
| Modelar | Image,: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Ler | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Documento geral | ✔ | ✔ | |
| Predefinida | ✔ | ✔ | |
| Extração personalizada | ✔ | ✔ | |
| Classificação personalizada | ✔ | ✔ | ✔ |
Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de camada gratuita, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para análise de documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 x 10.000 pixels.
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1.024 x 768 pixels. Essa dimensão corresponde a aproximadamente
8pontos de texto a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para o treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é de
1GB, com um máximo de 10.000 páginas. Para a versão 2024-11-30 (GA), o tamanho total dos dados de treinamento é de2GB com um máximo de 10.000 páginas.
Introdução ao modelo de leitura (v4)
Tente extrair dados de formulários e documentos pelo Estúdio da Informação de Documentos. Você precisará dos seguintes ativos:
Uma assinatura do Azure: você pode criar uma gratuitamente.
Uma instância da Informação de Documentos no portal do Azure. Você pode usar o tipo de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter a chave e o ponto de extremidade.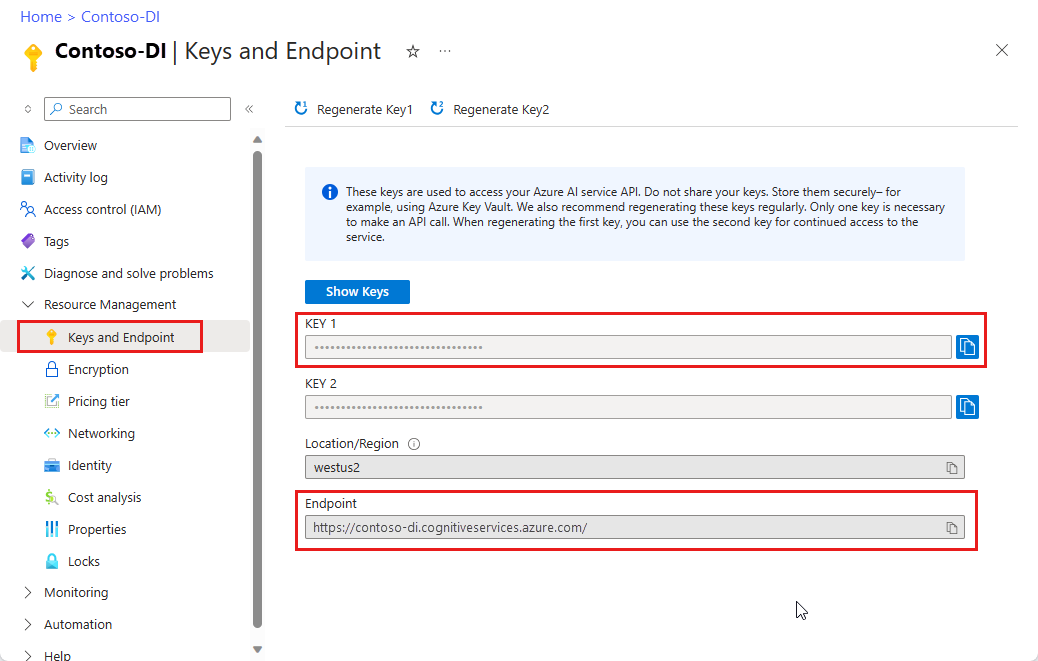
Observação
Atualmente, o Estúdio da Informação de Documentos não dá suporte aos formatos de arquivo Microsoft Word, Excel, PowerPoint e HTML.
Documento de exemplo processado com o Estúdio da Informação de Documentos
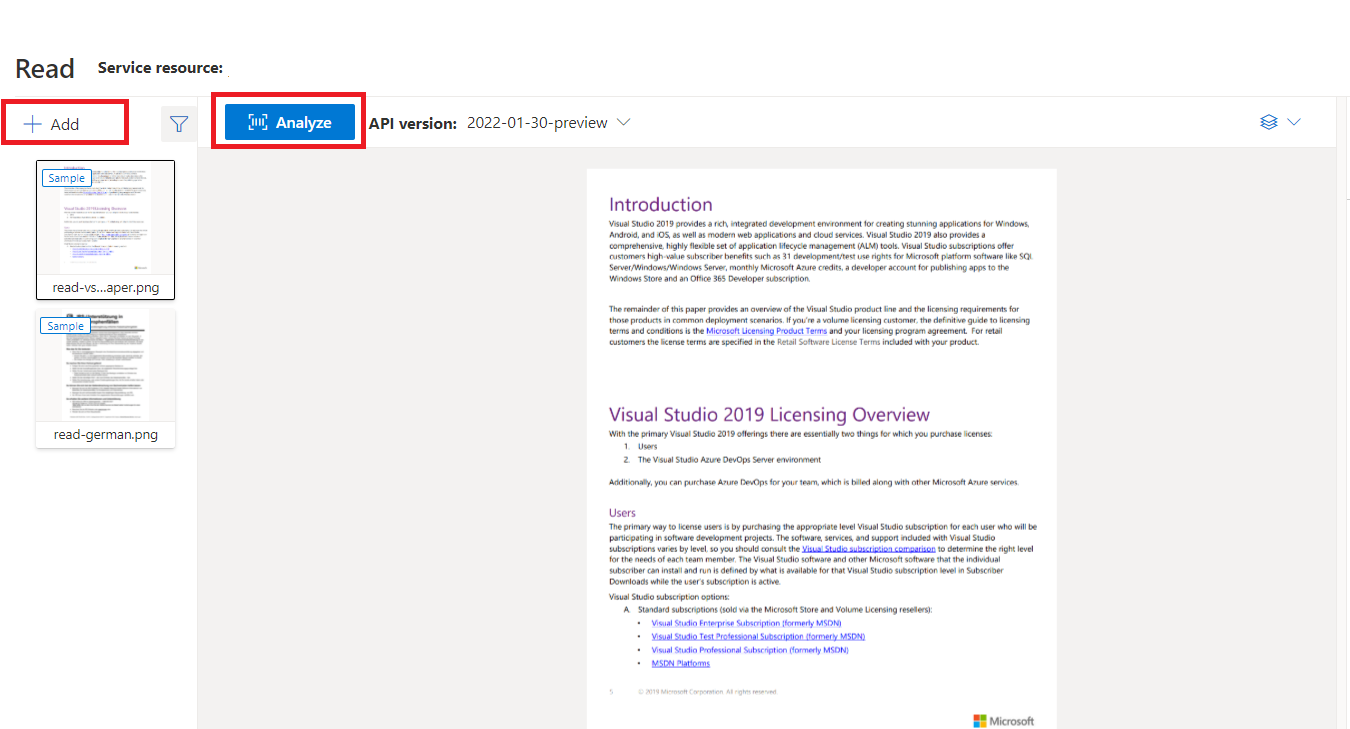
Na página inicial do Estúdio da Informação de Documentos, selecione Ler.
Você pode analisar o documento de amostra ou carregar seus próprios arquivos.
Selecione o botão Executar análise e, se necessário, configure as opções Analisar :

Idiomas e localidades com suporte (v4)
Confira a página Suporte a Idiomas: modelos de análise de documentos, para obter uma lista completa dos idiomas com suporte.
Extração de dados (v4)
Observação
O Microsoft Word e o arquivo HTML são compatíveis com a v4.0. No momento, não há suporte para os seguintes recursos:
- Não há ângulo, largura/altura e unidade em cada objeto de página.
- Para cada objeto detectado, não há polígono ou região delimitadora.
- Nenhum intervalo de páginas (
pages) como um parâmetro retornado. - Nenhum objeto
lines.
PDFs pesquisáveis
A funcionalidade do PDF pesquisável permite que você converta um PDF analógico, como arquivos PDF de imagem digitalizada, em um PDF com texto inserido. O texto inserido habilita a pesquisa de texto profundo no conteúdo extraído do PDF sobrepondo as entidades de texto detectadas sobre os arquivos de imagem.
Importante
- Atualmente, apenas o modelo LER OCR
prebuilt-readdá suporte à funcionalidade de PDF pesquisável. Ao usar esse recurso, especifique omodelIdcomoprebuilt-read. Outros tipos de modelo retornam um erro para esta versão de visualização. - O PDF pesquisável está incluído no modelo
2024-11-30GAprebuilt-readsem custos adicionais para gerar uma saída em PDF pesquisável.
Usar PDFs pesquisáveis
Para usar o PDF pesquisável, faça uma solicitação POST usando a operação Analyze e especifique o formato de saída como pdf:
POST {endpoint}/documentintelligence/documentModels/prebuilt-read:analyze?_overload=analyzeDocument&api-version=2024-11-30&output=pdf
{...}
202
Verifique a conclusão da operação Analyze. Depois que a operação terminar, emita uma solicitação GET para recuperar o formato PDF dos resultados da operação Analyze.
Após a conclusão bem-sucedida, o PDF pode ser recuperado e baixado como application/pdf. Essa operação permite o download direto do formulário de texto inserido do PDF em vez de do JSON codificado em Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET {endpoint}/documentintelligence/documentModels/prebuilt-read/analyzeResults/{resultId}/pdf?api-version=2024-11-30
URI Parameters
Name In Required Type Description
endpoint path True
string
uri
The Document Intelligence service endpoint.
modelId path True
string
Unique document model name.
Regex pattern: ^[a-zA-Z0-9][a-zA-Z0-9._~-]{1,63}$
resultId path True
string
uuid
Analyze operation result ID.
api-version query True
string
The API version to use for this operation.
Responses
Name Type Description
200 OK
file
The request has succeeded.
Media Types: "application/pdf", "application/json"
Other Status Codes
DocumentIntelligenceErrorResponse
An unexpected error response.
Media Types: "application/pdf", "application/json"
Security
Ocp-Apim-Subscription-Key
Type: apiKey
In: header
OAuth2Auth
Type: oauth2
Flow: accessCode
Authorization URL: https://login.microsoftonline.com/common/oauth2/authorize
Token URL: https://login.microsoftonline.com/common/oauth2/token
Scopes
Name Description
https://cognitiveservices.azure.com/.default
Examples
Get Analyze Document Result PDF
Sample request
HTTP
HTTP
Copy
GET https://myendpoint.cognitiveservices.azure.com/documentintelligence/documentModels/prebuilt-invoice/analyzeResults/3b31320d-8bab-4f88-b19c-2322a7f11034/pdf?api-version=2024-11-30
Sample response
Status code:
200
JSON
Copy
"{pdfBinary}"
Definitions
Name Description
DocumentIntelligenceError
The error object.
DocumentIntelligenceErrorResponse
Error response object.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
DocumentIntelligenceError
The error object.
Name Type Description
code
string
One of a server-defined set of error codes.
details
DocumentIntelligenceError[]
An array of details about specific errors that led to this reported error.
innererror
DocumentIntelligenceInnerError
An object containing more specific information than the current object about the error.
message
string
A human-readable representation of the error.
target
string
The target of the error.
DocumentIntelligenceErrorResponse
Error response object.
Name Type Description
error
DocumentIntelligenceError
Error info.
DocumentIntelligenceInnerError
An object containing more specific information about the error.
Name Type Description
code
string
One of a server-defined set of error codes.
innererror
DocumentIntelligenceInnerError
Inner error.
message
string
A human-readable representation of the error.
In this article
URI Parameters
Responses
Security
Examples
200 OK
Content-Type: application/pdf
Parâmetro Pages
A coleção de páginas é uma lista de páginas dentro do documento. Cada página é representada sequencialmente dentro do documento e inclui o ângulo de orientação que indica se a página foi girada, além de largura e altura (dimensões em pixels). As unidades de página na saída do modelo são computadas conforme mostrado:
| Formato de arquivo | Unidade de página computada | Total de páginas |
|---|---|---|
| Imagens (JPEG/JPG, PNG, BMP, HEIF) | Cada imagem = 1 unidade de página | Total de imagens |
| Cada página no PDF = 1 unidade de página | Total de páginas no PDF | |
| TIFF | Cada imagem no TIFF = 1 unidade de página | Total de imagens no TIFF |
| Word (DOCX) | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
| Excel (XLSX) | Cada planilha = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de planilhas |
| PowerPoint (PPTX) | Cada slide = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de slides |
| HTML | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Usar páginas para extração de texto
Para grandes documentos PDF com várias páginas, use o parâmetro de consulta pages para indicar números de página ou intervalos de página específicos para a extração de texto.
Extração de parágrafo
O modelo do OCR de Leitura na Informação de Documentos extrai todos os blocos de texto identificados na coleção paragraphs como um objeto de nível superior sob analyzeResults. Cada entrada dessa coleção representa um bloco de texto e inclui o texto extraído como content e as coordenadas polygon de limitação. As informações de span apontam para o fragmento de texto dentro da propriedade content de nível superior que contém o texto completo do documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Extração de texto, linhas e palavras
O modelo do OCR de Leitura extrai textos de estilo impresso e manuscritos como lines e words. O modelo gera coordenadas delimitadoras polygon e confidence para as palavras extraídas. A coleção styles inclui qualquer estilo manuscrito para linhas (se detectado), juntamente com os intervalos apontando para o texto associado. Esse recurso se aplica a linguagens manuscritas com suporte.
Para o Microsoft Word, Excel, PowerPoint e HTML, o modelo de Leitura de informação de documentos v3.1 e versões posteriores extrai todo o texto inserido como está. Textos são extraídos como palavras e parágrafos. Não há suporte para imagens incorporadas.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Extração de estilo manuscrito
A resposta inclui classificar se cada linha de texto tem um estilo manuscrito ou não, junto com uma pontuação de confiança. Para obter mais informações, confira o suporte ao idioma escrito à mão. O exemplo a seguir mostra um snippet JSON de exemplo.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Se você habilitou a funcionalidade de complemento de fonte/estilo, também obterá o resultado de fonte/estilo como parte do objeto styles.
Próximas etapas v4.0
Conclua um início rápido da Informação de Documentos:
Explore nossa API REST:
Confira mais exemplos no GitHub:
Observação
Para extrair texto de imagens externas, como rótulos, placas de rua e cartazes, use o recurso de leitura da Análise de Imagem v4.0 da IA do Azure otimizado para imagens gerais (e não documentos) com uma API síncrona aprimorada pelo desempenho. Essa funcionalidade facilita a inserção do OCR em cenários de experiência do usuário em tempo real.
O modelo OCR (Reconhecimento óptico de caracteres) de leitura da Informação de Documentos é executado em uma resolução mais alta do que a Pesquisa Visual da IA do Azure ; lê e extrai texto impresso e manuscrito de documentos PDF e imagens digitalizadas. Ele também inclui suporte para extrair texto de documentos do Microsoft Word, do Excel, do PowerPoint e de HTML. Ele detecta parágrafos, linhas de texto, palavras, locais e idiomas. O Modelo de Leitura é o mecanismo de OCR subjacente para outros modelos predefinidos da Informação de Documentos, como Layout, Documento Geral, Fatura, Recibo, Identidade (ID), cartão de seguro saúde, W2 além de modelos personalizados.
O que é o OCR para documentos?
O OCR (Reconhecimento Óptico de Caracteres) para documentos é otimizado para documentos grandes com uso intenso de texto em vários formatos de arquivo e idiomas globais. Ele inclui recursos como verificação de maior resolução de imagens de documento para melhor manipulação de texto menor e denso; detecção de parágrafo e gerenciamento de formulário preenchível. Os recursos de OCR também incluem cenários avançados, como caixas de caracteres únicos e extração precisa de campos-chave comumente encontrados em faturas, recibos e outros cenários predefinidos.
Opções de desenvolvimento
A Informação de Documentos v3.1 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Ler o modelo OCR | • Estúdio de Informação de Documentos • API REST • SDK do C# • SDK do Python • SDK do Java • SDK do JavaScript |
prebuilt-read |
A Informação de Documentos v3.0 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Ler o modelo OCR | • Estúdio de Informação de Documentos • API REST • SDK do C# • SDK do Python • SDK do Java • SDK do JavaScript |
prebuilt-read |
Requisitos de entrada
Formatos de arquivo com suporte:
| Modelar | Image,: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Ler | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Documento geral | ✔ | ✔ | |
| Predefinida | ✔ | ✔ | |
| Extração personalizada | ✔ | ✔ | |
| Classificação personalizada | ✔ | ✔ | ✔ |
Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de camada gratuita, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para análise de documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 x 10.000 pixels.
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1.024 x 768 pixels. Essa dimensão corresponde a aproximadamente
8pontos de texto a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para o treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é de
1GB, com um máximo de 10.000 páginas. Para a versão 2024-11-30 (GA), o tamanho total dos dados de treinamento é de2GB com um máximo de 10.000 páginas.
Introdução ao modelo de leitura
Tente extrair dados de formulários e documentos pelo Estúdio da Informação de Documentos. Você precisará dos seguintes ativos:
Uma assinatura do Azure: você pode criar uma gratuitamente.
Uma instância da Informação de Documentos no portal do Azure. Você pode usar o tipo de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter a chave e o ponto de extremidade.
Observação
Atualmente, o Estúdio da Informação de Documentos não dá suporte aos formatos de arquivo Microsoft Word, Excel, PowerPoint e HTML.
Documento de exemplo processado com o Estúdio da Informação de Documentos
Na página inicial do Estúdio da Informação de Documentos, selecione Ler.
Você pode analisar o documento de amostra ou carregar seus próprios arquivos.
Selecione o botão Executar análise e, se necessário, configure as opções Analisar :
Idiomas e localidades com suporte
Confira a página Suporte a Idiomas: modelos de análise de documentos, para obter uma lista completa dos idiomas com suporte.
Extração de dados
Observação
O Microsoft Word e o arquivo HTML são compatíveis com a v4.0. No momento, não há suporte para os seguintes recursos:
- Não há ângulo, largura/altura e unidade em cada objeto de página.
- Para cada objeto detectado, não há polígono ou região delimitadora.
- Nenhum intervalo de páginas (
pages) como um parâmetro retornado. - Nenhum objeto
lines.
PDF Pesquisável
A funcionalidade do PDF pesquisável permite que você converta um PDF analógico, como arquivos PDF de imagem digitalizada, em um PDF com texto inserido. O texto inserido habilita a pesquisa de texto profundo no conteúdo extraído do PDF sobrepondo as entidades de texto detectadas sobre os arquivos de imagem.
Importante
- Atualmente, apenas o modelo Ler OCR
prebuilt-readdá suporte à funcionalidade de PDF pesquisável. Ao usar esse recurso, especifique omodelIdcomoprebuilt-read. Outros tipos de modelo retornam um erro. - O PDF pesquisável está incluído no modelo
2024-11-30prebuilt-readsem custos adicionais para gerar uma saída em PDF pesquisável.- Atualmente, o PDF pesquisável só oferece suporte a arquivos PDF como entrada.
Usar o PDF pesquisável
Para usar o PDF pesquisável, faça uma solicitação POST usando a operação Analyze e especifique o formato de saída como pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Verifique a conclusão da operação Analyze. Depois que a operação terminar, emita uma solicitação GET para recuperar o formato PDF dos resultados da operação Analyze.
Após a conclusão bem-sucedida, o PDF pode ser recuperado e baixado como application/pdf. Essa operação permite o download direto do formulário de texto inserido do PDF em vez de do JSON codificado em Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Pages (Páginas)
A coleção de páginas é uma lista de páginas dentro do documento. Cada página é representada sequencialmente dentro do documento e inclui o ângulo de orientação que indica se a página foi girada, além de largura e altura (dimensões em pixels). As unidades de página na saída do modelo são computadas conforme mostrado:
| Formato de arquivo | Unidade de página computada | Total de páginas |
|---|---|---|
| Imagens (JPEG/JPG, PNG, BMP, HEIF) | Cada imagem = 1 unidade de página | Total de imagens |
| Cada página no PDF = 1 unidade de página | Total de páginas no PDF | |
| TIFF | Cada imagem no TIFF = 1 unidade de página | Total de imagens no TIFF |
| Word (DOCX) | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
| Excel (XLSX) | Cada planilha = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de planilhas |
| PowerPoint (PPTX) | Cada slide = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de slides |
| HTML | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Selecionar páginas para extração de texto
Para grandes documentos PDF com várias páginas, use o parâmetro de consulta pages para indicar números de página ou intervalos de página específicos para a extração de texto.
Parágrafos
O modelo do OCR de Leitura na Informação de Documentos extrai todos os blocos de texto identificados na coleção paragraphs como um objeto de nível superior sob analyzeResults. Cada entrada dessa coleção representa um bloco de texto e inclui o texto extraído como content e as coordenadas polygon de limitação. As informações de span apontam para o fragmento de texto dentro da propriedade content de nível superior que contém o texto completo do documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Linhas, texto e palavras
O modelo do OCR de Leitura extrai textos de estilo impresso e manuscritos como lines e words. O modelo gera coordenadas delimitadoras polygon e confidence para as palavras extraídas. A coleção styles inclui qualquer estilo manuscrito para linhas (se detectado), juntamente com os intervalos apontando para o texto associado. Esse recurso se aplica a linguagens manuscritas com suporte.
Para o Microsoft Word, Excel, PowerPoint e HTML, o modelo de Leitura de informação de documentos v3.1 e versões posteriores extrai todo o texto inserido como está. Textos são extraídos como palavras e parágrafos. Não há suporte para imagens incorporadas.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Estilo manuscrito para linhas de texto
A resposta inclui classificar se cada linha de texto tem um estilo manuscrito ou não, junto com uma pontuação de confiança. Para obter mais informações, confira o suporte ao idioma escrito à mão. O exemplo a seguir mostra um snippet JSON de exemplo.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Se você habilitou a funcionalidade de complemento de fonte/estilo, também obterá o resultado de fonte/estilo como parte do objeto styles.
Próximas etapas
Conclua um início rápido da Informação de Documentos:
Explore nossa API REST:
Confira mais exemplos no GitHub: