Análise em lote da Informação de Documentos
A API de análise em lote permite processar em massa vários documentos usando uma solicitação assíncrona. Em vez de precisar enviar documentos individualmente e acompanhar várias IDs de solicitação, você pode analisar uma coleção de documentos como faturas, uma série de documentos de empréstimo ou um grupo de documentos personalizados simultaneamente. A API do lote dá suporte à leitura dos documentos do armazenamento de blobs do Azure e à gravação dos resultados no armazenamento de blobs.
- Para utilizar a análise em lote, você precisa de uma conta de armazenamento de Blobs do Azure com contêineres específicos para seus documentos de origem e para as saídas processadas.
- Após a conclusão, o resultado da operação em lote lista todos os documentos individuais processados com seu status, como
succeeded,skippedoufailed. - A versão prévia da API do Lote está disponível por meio de preços de pagamento conforme o uso.
Diretrizes de análise em lote
O número máximo de documentos processados por solicitação de análise em lote único (incluindo documentos ignorados) é de 10.000.
Os resultados da operação são mantidos por 24 horas após a conclusão. Os documentos e os resultados ficam na conta de armazenamento fornecida, mas o status da operação não estará mais disponível 24 horas após a conclusão.
Pronto para começar?
Pré-requisitos
Você precisa de uma assinatura ativa do Azure. Se você não tem uma assinatura do Azure, pode criar uma gratuita.
Uma vez que você tenha uma assinatura do Azure, você precisará de uma instância da Informação de Documentos no portal do Azure. Você pode usar o tipo de preço gratuito (
F0) para experimentar o serviço.Após a implantação do recurso, selecione Ir para o recurso para recuperar a chave e o ponto de extremidade.
- Você precisará da chave e do ponto de extremidade do recurso para conectar seu aplicativo ao serviço de Informação de Documentos. Você vai colar a chave e o ponto de extremidade no código mais adiante no guia de início rápido. Você pode encontrar esses valores na página Chaves e ponto de extremidade do portal do Azure.
Uma conta de Armazenamento de Blobs do Azure. Você vai criar contêineres na sua conta do Armazenamento de Blobs do Azure para seus arquivos de origem e de resultado:
- Contêiner de origem. Esse contêiner é onde você carrega seus arquivos nativos para análise (obrigatório).
- Contêiner de resultados. Esse contêiner é onde os arquivos processados são armazenados (opcional).
Você pode designar o mesmo contêiner do Armazenamento de Blobs do Azure para documentos processados e de origem. No entanto, para minimizar as possíveis chances de substituir dados acidentalmente, recomendamos escolher contêineres separados.
Autorização de contêiner de armazenamento
Você pode escolher uma das opções a seguir para autorizar o acesso ao seu recurso de Informação de Documentos.
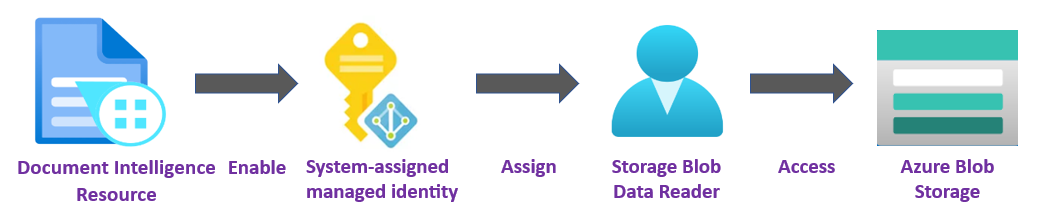
✔️Identidade Gerenciada. Uma identidade gerenciada é uma entidade de serviço que cria uma identidade do Microsoft Entra e permissões específicas para um recurso gerenciado do Azure. As identidades gerenciadas permitem que você execute seu aplicativo de Informação de Documentos sem precisar inserir credenciais em seu código. As identidades gerenciadas são uma maneira mais segura de conceder acesso aos dados de armazenamento e substituem o requisito de incluir tokens de assinatura de acesso compartilhado (SAS) pelas suas URLs de origem e de resultado.
Para saber mais, confiraIdentidades gerenciadas para a Informação de Documentos.
Importante
- Ao usar identidades gerenciadas, não inclua uma URL de token SAS com suas solicitações HTTP. Elas falharão. O uso de identidades gerenciadas substitui o requisito de incluir tokens de assinatura de acesso compartilhado (SAS).
✔️Uma SAS (Assinatura de Acesso Compartilhado). Uma assinatura de acesso compartilhado é uma URL que concede acesso restrito por um período de tempo especificado ao seu serviço de Informação de Documentos. Para usar esse método, você precisa criar tokens de SAS (Assinatura de Acesso Compartilhado) para seus contêineres de origem e de resultado. Os contêineres de origem e de resultado devem incluir um token de Assinatura de Acesso Compartilhado (SAS), acrescentado como uma cadeia de caracteres de consulta. O token pode ser atribuído ao contêiner ou a blobs específicos.

- Seu contêiner ou blob de origem deve designar os acessos de leitura, gravação, lista e exclusão.
- Seu contêiner ou blob de resultados deve designar os acessos de gravação, lista e exclusão.
Para saber mais, consulte Criar os tokens SAS.
Chamando a API de análise em lote
- Especifique a URL do contêiner do Armazenamento de Blobs do Azure para o conjunto de documentos de origem dentro dos objetos
azureBlobSourceouazureBlobFileListSource.
Especificar os arquivos de entrada
A API do lote dá suporte a duas opções para especificar os arquivos a serem processados. Se você precisar de todos os arquivos em um contêiner ou pasta processado, e o número de arquivos for menor que o limite de 10000 para apenas uma única solicitação em lote, use o contêiner azureBlobSource.
Se você tiver arquivos específicos no contêiner ou pasta a ser processado ou o número de arquivos a serem processados estiver acima do limite máximo de um lote, use o azureBlobFileListSource. Divida o conjunto de dados em vários lotes e adicione um arquivo com a lista de arquivos a serem processados em um formato JSONL na pasta raiz do contêiner. Um exemplo de qual é o formato de lista de arquivos.
{"file": "Adatum Corporation.pdf"}
{"file": "Best For You Organics Company.pdf"}
Especificar o local dos resultados
Especifique a URL do contêiner do Armazenamento de Blobs do Azure para os resultados da análise em lote usando resultContainerUrl. Para evitar substituição acidental, recomendamos o uso de contêineres separados para documentos de origem e processados.
Defina a propriedade booliana overwriteExisting como false se você não quiser que os resultados existentes com os mesmos nomes de arquivo sejam substituídos. Essa configuração não afeta a cobrança e só impede que os resultados sejam substituídos depois que o arquivo de entrada é processado.
Defina o namespace resultPrefix para os resultados dessa execução da API do lote.
- Se você planeja usar o mesmo contêiner para entrada e saída, defina
resultContainerUrleresultPrefixpara corresponderem à sua entradaazureBlobSource. - Ao usar o mesmo contêiner, você pode incluir o campo
overwriteExistingpara decidir se deseja substituir os arquivos pelos arquivos de resultado da análise.
Compilar e executar a solicitação POST
Antes de executar a solicitação POST, substitua {your-source-container-SAS-URL} e {your-result-container-SAS-URL} pelos valores de suas instâncias de contêiner de Armazenamento de Blobs do Azure.
O seguinte exemplo mostra como adicionar a propriedade azureBlobSource à solicitação:
Permitia apenas um, azureBlobSource ou azureBlobFileListSource.
POST /documentModels/{modelId}:analyzeBatch
{
"azureBlobSource": {
"containerUrl": "https://myStorageAccount.blob.core.windows.net/myContainer?mySasToken",
"prefix": "trainingDocs/"
},
"resultContainerUrl": "https://myStorageAccount.blob.core.windows.net/myOutputContainer?mySasToken",
"resultPrefix": "layoutresult/",
"overwriteExisting": true
}
O seguinte exemplo mostra como adicionar a propriedade azureBlobFileListSource à solicitação:
POST /documentModels/{modelId}:analyzeBatch
{
"azureBlobFileListSource": {
"containerUrl": "https://myStorageAccount.blob.core.windows.net/myContainer?mySasToken",
"fileList": "myFileList.jsonl"
},
"resultContainerUrl": "https://myStorageAccount.blob.core.windows.net/myOutputContainer?mySasToken",
"resultPrefix": "customresult/",
"overwriteExisting": true
}
Resposta bem-sucedida
202 Accepted
Operation-Location: /documentModels/{modelId}/analyzeBatchResults/{resultId}
Recuperar resultados da API de análise em lote
Depois que a operação da API do Lote for executada, você poderá recuperar os resultados da análise em lote usando a operação GET. Essa operação busca informações do status da operação, porcentagem de conclusão da operação e data/hora da operação e da atualização.
GET /documentModels/{modelId}/analyzeBatchResults/{resultId}
200 OK
{
"status": "running", // notStarted, running, completed, failed
"percentCompleted": 67, // Estimated based on the number of processed documents
"createdDateTime": "2021-09-24T13:00:46Z",
"lastUpdatedDateTime": "2021-09-24T13:00:49Z"
...
}
Interpretando mensagens de status
Para cada documento de um conjunto, há um status atribuído, seja succeeded, failed ou skipped. Para cada documento, há duas URLs fornecidas para validar os resultados: sourceUrl, que é o contêiner de armazenamento de blobs de origem para o documento de entrada bem-sucedido e resultUrl, que é construído combinando resultContainerUrl eresultPrefix criando o caminho relativo para o arquivo de origem e .ocr.json.
Status
notStartedourunning. A operação de análise em lote não foi iniciada ou não foi concluída. Aguarde até que a operação seja concluída para todos os documentos.Status
completed. A operação de análise em lote foi concluída.Status
failed. Falha na operação em lote. Essa resposta geralmente ocorre se houver problemas gerais com a solicitação. Falhas em arquivos individuais são retornadas na resposta do relatório do lote, mesmo que todos os arquivos falhem. Por exemplo, os erros de armazenamento não interrompem a operação em lote como um todo, para que você possa acessar resultados parciais por meio da resposta do relatório do lote.
Somente os arquivos que têm um status succeeded têm a propriedade resultUrl gerada na resposta. Isso permite que o treinamento do modelo detecte nomes de arquivo que terminam com .ocr.json e identifique-os como os únicos arquivos que podem ser usados para treinamento.
Exemplo de uma resposta do status succeeded:
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
{
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
}
]
}
]
...
Exemplo de uma resposta do status failed:
- Esse erro só será retornado se houver erros na solicitação geral do lote.
- Depois que a operação de análise em lote for iniciada, o status da operação de documento individual não afetará o status do trabalho em lote geral, mesmo que todos os arquivos tenham o status
failed.
[
"result": {
"succeededCount": 0,
"failedCount": 2,
"skippedCount": 2,
"details": [
"sourceUrl": "https://{your-source-container}/myContainer/trainingDocs/file2.jpg",
"status": "failed",
"error": {
"code": "InvalidArgument",
"message": "Invalid argument.",
"innererror": {
"code": "InvalidSasToken",
"message": "The shared access signature (SAS) is invalid: {details}"
}
}
]
}
]
...
Exemplo de resposta do status skipped:
[
"result": {
"succeededCount": 3,
"failedCount": 0,
"skippedCount": 2,
"details": [
...
"sourceUrl": "https://myStorageAccount.blob.core.windows.net/myContainer/trainingDocs/file4.jpg",
"status": "skipped",
"error": {
"code": "OutputExists",
"message": "Analysis skipped because result file {path} already exists."
}
]
}
]
...
Os resultados da análise em lote ajudam você a identificar quais arquivos foram analisados com sucesso e validar os resultados da análise comparando o arquivo no resultUrl com o arquivo de saída no resultContainerUrl.
Observação
Os resultados da análise não são retornados para arquivos individuais até que toda a análise em lote do conjunto de documentos seja concluída. Para acompanhar o progresso detalhado além de percentCompleted, você pode monitorar arquivos *.ocr.json conforme eles são gravados no resultContainerUrl.