Projeto REAL: Business Intelligence ETL Design práticas (pt-BR)
**  **
**
Projeto REAL: Business Intelligence ETL Design práticas
SQL Artigo técnico do servidor
Autor: Erik Veerman
Revisores técnicos: Donald Farmer, Grant Dickinson
Parceiro: Intellinet
Publicado: Maio de 2005
Aplica-se a: SQL Server 2005
**Este artigo é uma tradução da (http://www.microsoft.com/download/en/details.aspx?id=14582) feito por uma máquina de tradução. Nós encorajamos você a contribuir com o conteúdo visando a melhoria da qualidade do artigo
Resumo:** ler sobre SQL Server 2005 Integration Services (SSIS) em ação. Usado na implementação de referência de inteligência de negócios chamada Project REAL, o SSIS demonstra um alto volume e reais com base de extração, transformaçãoe carregamento de processo (ETL). Esta solução ETL oferece suporte a um de vários terabytes data warehousee contém representativo de processamento de dados, configuraçãoe administração mecanismos de uma iniciativa de grande armazém.
Direitos autorais
Este é um documento preliminar e pode ser alterado substancialmente antes para lançamento comercial final do software aqui descrito.
As informações contidas neste documento representam a visão atual da Microsoft Corporation sobre as questões discutidas na data da publicação. Como a Microsoft deve responder às mudanças do mercado, não deve ser interpretado como um compromisso por parte da Microsoft e a Microsoft não pode garantir a exactidão de qualquer informação apresentada após a data da publicação.
Este White Paper é apenas para fins informativos. A MICROSOFT DISPONIBILIZA NÃO OFERECE GARANTIAS, EXPRESSAS, IMPLÍCITAS OU ESTATUTÁRIAS, COMO PARA AS INFORMAÇÕES CONTIDAS NESTE DOCUMENTO.
Obedecer a todas as leis de direitos autorais aplicáveis é responsabilidade do usuário. Sem limitar os direitos autorais, nenhuma parte deste documento pode ser reproduzida, armazenada ou introduzida em um sistema de recuperação, ou transmitida de qualquer forma ou por qualquer meio (seja eletrônico, mecânico, fotocópia, gravação ou outro), ou para qualquer finalidade, sem a permissão expressa e por escrito da Microsoft Corporation.
A Microsoft pode ter patentes ou requisições para obtenção de patente, marcas comerciais, direitos autorais ou outros direitos de propriedade intelectual que abrangem o conteúdo deste documento. A posse deste documento não lhe confere nenhum direito sobre as citadas patentes, marcas comerciais, direitos autorais ou outros direitos de propriedade intelectual, salvo aqueles expressamente mencionados em um contrato de licença, por escrito, da Microsoft.
A menos que especificado de outra forma, os exemplos de empresas, organizações, produtos, nomes de domínio , endereços de email, logotipos, pessoas, lugares e eventos aqui descritos são fictícios e nenhuma associação com qualquer empresa real, organização, produto, nome de domínio , endereço de email, logotipo, pessoa, lugar ou evento é intencional ou deve ser inferida.
Ó 2005 Microsoft Corporation. Todos os direitos reservados.
Microsoft, Visual Basic, Visual Source Safe e Visual Studio **** são marcas registradas ou marcas comerciais da Microsoft Corporation na Estados Unidos e/ou outros países.
Os nomes reais das empresas e produtos mencionados aqui podem ser marcas comerciais de seus respectivos proprietários.
Sumário
Projeto REAL: Business Intelligence ETL Design práticas. 1
Introdução
Aplicativos de sucesso de business intelligence (BI) precisam de ferramentas sólidas para ser executado no. O processo de criação desses aplicativos também é facilitado quando os desenvolvedores e os administradores possuem uma base de associados do conhecimento sobre como realizar uma implementação bem sucedida — em suma, melhores práticas de informações. Através do Project REAL, Microsoft e vários de seus parceiros estão descobrindo práticas recomendadas para aplicativos de BI baseados no Microsoft ® SQL Server ™ 2005. No Project REAL estamos fazendo isso criando implementações de referência com base em cenários de clientes reais. Isso significa que os dados do cliente são trazidos internamente e são usados para trabalhar com os mesmos problemas que esses clientes enfrentam durante a implantação. Esses problemas incluem:
- Design de esquemas — esquemas relacionais e aqueles usados no Analysis Services.
- Implementação de extração de dados, transformaçãoe carregamento (ETL) processos.
- Projeto e implantação de sistemas front-end do cliente , para emissão de relatórios e análise interativa.
- Dimensionamento de sistemas de produção.
- Gerenciamento e manutenção dos sistemas em uma base contínua, incluindo atualizações incrementais dos dados.
Trabalhando com cenários de implantação real, adquirimos uma compreensão completa de como trabalhar com as ferramentas. Nosso objetivo é atender a gama completa de preocupações que uma grande empresa enfrentaria durante sua própria implantação real.
Este livro centra-se sobre o SQL Server Integration Services (SSIS) extração de transformação e carregamento (ETL) design para projeto REAL. Este projeto baseia-se na Barnes & Nobre da arquitetura ETL — construído a partir do zero para usar SSIS e a primeira implementação de ETL de produção do SSIS. Uma vez que a solução não é um projeto atualizado com base na Data Transformation Services (DTS) ou outra ferramentade ETL, você verá que muitas das abordagens tomadas são ao contrário a arquitetura típica de ETL vista no DTS. O objetivo dessa solução foi pensar fora da caixa e criar um processo ETL que podia modelar uma prática recomendada para o design geral de ETL, aproveitando a nova arquitetura de aplicativo do SSIS. Durante todo este white paper, explicaremos as decisões de design que foram feitas para cada detalhe cenário e implementação do esforço de projeto REAL SSIS.
Para obter uma visão geral do Project REAL, consulte o white paper chamado Project REAL: visão geral técnica. O Project REAL irá resultar em um número de documentos, ferramentas e exemplos ao longo de sua vida. Para encontrar as informações mais recentes, verifique novamente para o seguinte site:
http://www.microsoft.com/sql/bi/ProjectREAL
O Project REAL é um esforço cooperativo entre Microsoft e vários de seus parceiros na área de BI. Estes parceiros incluem: Apollo Data Technologies, EMC, Intellinet, Panorama, Proclarity, especialistas em escalabilidade e Unisys. O cenário de negócios para o Project REAL e a fonte de dados conjunto, graciosamente foram fornecidos pela Barnes & Nobre.
Nota: Este white paper é um projecto. Ele contém as práticas recomendadas com base em nossas experiências de trabalho com primeiras compilações Community Technology Preview (CTP) do SQL Server 2005. Este white paper é precisa na data de publicação. A funcionalidade do produto descrita neste documento pode ser alteradas e melhor de práticas de informação pode ser desenvolvida mais tarde.
Objetivos do projeto REAL ETL
Em qualquer sistema de business intelligence (BI), processamento de ETL existe para dar suporte aos requisitos de emissão de relatórios e análises. O ETL deve ser aplicado com este papel coadjuvante na mente. Isso não deve diminuir o importante papel que ele desempenha, desde que os dados a serem relatados serão tratados directamente através do ETL processamento. Alguns aspectos de ETL incluem calendário, o desempenho e a precisão do tratamento; igualmente importantes são o suporte, gerenciamento, escalabilidade e extensibilidade do design ETL. Sistemas reais têm sempre incógnitas e anomalias que afetam o ETL. Estes exigem que o processamento de ETL ser capaz de lidar com mudanças facilmente e apoiar o objetivo final de um sistema estável.
Para o Project REAL, essas áreas chave levaram a vários objetivos primários para o design ETL da seguinte forma:
- **Administração de ETL. ** Para fornecer suporte administrativo, um projeto foi implementado que permite o controle e emissão de relatórios de ETL metadados. Esse elemento permite que uma imagem clara do Estado do processamento para fins informativos e solução de problemas, ajudando a isolar problemas e resolvê-los.
- **Configuração dinâmica. ** Este objectivo foi desenvolvido para oferecer suporte a um sistema corporativo na publicação e distribuição dos componentes principais. Ele também envolveu design adaptabilidade para negócios e mudanças de exigência técnica e um ambiente adequado para uma grande equipe de suporte e desenvolvimento.
- **Integração de plataforma. ** Isso envolveu projetar uma solução que poderia interagir com vários níveis de uma solução de BI. Estes incluem segurança, infra-estrutura, relacional e estruturas OLAP e as ferramentas de relatórios e análises que colhem os dados.
- **Desempenho. ** Atenção para problemas de desempenho foi fundamental para a solução Project REAL, dada o volume de dados processados e gerenciados no armazém. No total, os dados elevou-se a vários terabytes.
Resumo
Este livro destaca vários princípios de design específicos, algumas das lições aprenderam com o processo de design e um panorama da arquitetura da solução. O livro fornece uma visão geral referência e inclui alguns destaques de design da solução. Novas soluções maturos e são desenvolvidas na plataforma do SQL Server 2005, mais detalhada e abrangente material será publicado. Futuros artigos irão desenvolver conceitos, ajustar desempenho design e provavelmente demonstram alguns exemplos dos melhores desenhos. Este livro fornece que uma referência sólida para BI (ETL) com base no SSIS. Ele pode ser uma ferramenta usada por arquitetos BI durante o planejamento e desenvolvimento de ETL redesenha, upgrades e novas implementações.
Funcionalidade do SSIS vai além de apenas manipulação ETL — fornece muitos mais recursos para integração de sistemas, gerenciamento de informações e transformaçãode dados. Este livro aborda somente alguns aspectos do produto, cobrindo partes principais do SSIS que se refiram ao processamento de ETL.
Contorno
Os exemplos neste documento referem-se diretamente para a implementação do Project REAL. Cada exemplo foi escolhido porque ele destaca aspectos particulares do SSIS como ele se aplica ao processamento de ETL. Esses exemplos demonstram algumas das metas descritas acima e cenários comuns de ETL incluindo:
- Ambiente de desenvolvimento do SSIS
- ETL auditoria e log
- Design dinâmico configuração para administração de fonte de dados e propriedade
- Dimensão de processamento para cenários de padrão e exclusivos
- Processamento de tabela de fato das associações de dimensão e atualizações de tabela de fatos
- Projeto de arquitetura de processamento de dados
- Técnicas de otimização de processamento de dados
Todos esses exemplos são implementados na solução de projeto REAL SSIS que tenha sido executada com êxito com 90 dias de diário e semanal de dados de volume de produção. Os dados processados incluem uma porção da corrida de varejo do feriado e se estende por dois anos para provar a estabilidade e a confiabilidade do presente como um exemplo do mundo real. Como já foi referido, a solução SSIS "real" que se baseia o projeto REAL ETL tem sido em produção desde novembro de 2004 na Barnes & Nobre. Muitos desses exemplos e pacotes estão ou estarão disponíveis para análise detalhada dos detalhes de implementação. Esta informação será publicada no Project REAL site da Web em uma data futura. Além disso, os pacotes serão apresentados em congressos do setor para demonstrar a concepção do projeto REAL SSIS.
Perfil de dados
O ETL para Project REAL tipifica os requisitos de extração para muitos cenários de negócios, mesmo que este projecto de referência concentra-se em um sistema de varejo. Como é comum para o processamento de ETL, há um conjunto de necessidades diárias de processamento, onde as alterações e adições à fonte dados é extraído e processados através do sistema todos os dias. Além disso, um conjunto de processos de downloads são executados para gerenciar os downloads grãos de instantâneo de inventário para o modelo dimensional. O perfil de dados inclui extrações diárias de transações, atualizações de dimensão e gerenciamento de downloads de tabelas de fatos de inventário.
Tabelas de fatos
O modelo relacional é um design padrão esquema em estrela com dois tipos principais de tabelas de fatos; vendas e inventário. As transações de vendas são coletadas diariamente e representam compras detalhadas de produtos em lojas de varejo incluindo ordens da Web. Vários milhões de transações são manipulados que deve ser adicionado à estrutura de fatos de vendas, com a maioria dos registros de vendas provenientes de vendas do dia anterior. Além disso, há um pequeno punhado de vendas que são novos para o sistema, mas estão chegando atrasado vendas históricas. Todas as vendas são controladas em um diário de grãos e o processo ETL é projetado para permitir o processamento de múltiplos de dados durante todo o dia. As métricas primárias controladas giram em torno da quantidade de quantidade e de venda de cada item-nível transação.
A estrutura de inventário é concebida como um padrão instantâneo tabela de fatos em grãos downloads, onde posições de estoque são atualizadas diariamente mas historicamente gerenciadas em incrementos semanais. Inventário é controlado no grãos de centro o armazenamento e a distribuição para o item nível, que produz semanalmente dezenas de milhões de linhas e requer milhões de alterações em uma base diária. Dos objectivos principais relatórios é ver o inventário e tendências de vendas e evitar situações de indisponibilidade de estoque. Portanto, para além das quantidades de 'disponível' padrão, um fato 'dias em estoque' é controlado que identifica o número de dias que um item foi em estoque para o Grão downloads nos locais de centro de armazenamento ou distribuição. Quando uma semana chega ao fim, os níveis de inventário são duplicados e inicializados para o início de uma nova semana, um processo intensivo exigido ao ETL.
Tabelas de dimensões
As dimensões que suportam as tabelas de fatos têm alguns aspectos ��nicos que fez o design interessante e destacam vários aspectos do SSIS. A dimensão do produto tem vários milhões de membros e contém alterando padrão e atributos históricos, mas também requer que alterações de atributo e hierarquia historicamente controladas apenas iniciar após a ocorrência de uma venda. Como isso impacta o ETL é discutida neste documento. Para complementar a dimensão produto, várias outras dimensões típicas de varejo estão envolvidos. Por causa da forma como os dados de fonte são gerenciados, todas as dimensões exigem que se um membro da dimensão está ausente durante o processamento de fato, um registro de espaço reservado com os negócios relevantes chave ser adicionado à dimensão até a dimensão completa fonte está disponível para uma atualização completa. Isso é chamado um Membro inferido e tem impacto do processamento sobre o ETL. Algumas das dimensões são também originadas diretamente a transação primária ou tabelas de fonte de inventário e requerem um tratamento especial para seus aditamentos para as tabelas de fatos.
Dada a dimensionalidade complexa, o processo global de SSIS demonstra a flexibilidade e a escalabilidade da ferramentae destinam-se a fornecer um ponto de referência forte para muitos projetos ETL, baseados na plataforma SQL 2005.
Ambiente de desenvolvimento do SSIS
O Business Intelligence (BI) Development Studio é construído sobre a plataforma Microsoft Visual Studio ® 2005 (VS). Embora esta seja uma mudança por atacado de UI baseados no Enterprise Manager no SQL Server 2000, BI Development Studio são implementados de forma que permitirá uma transição fácil para os administradores de banco de dados (DBAs), dados arquitetos e desenvolvedores. O fator de intimidação que vem com VS foi atenuado por um perfil de interface do usuário simplificado com foco nas necessidades do desenvolvedor BI.
Para o Project REAL, uma única solução de BI abriga o projeto ETL recorrentes. Este projeto tem todos os pacotes do SSIS executados de forma incremental. A Figura 1 mostra o Solution Explorer com fontes de dados compartilhadas e pacotes do SSIS. Os pacotes são nomeados para indicar sua função. Existem vários tipos de pacotes; a primeira e mais simples conjunto é a dimensão pacote. Cada dimensão é originário de sua própria fonte entidade tem seu próprio pacote. Os pacotes de tabela de fato são semelhantes em design, exceto que eles são nomeados com sua programação de recorrência respectivos (diariamente ou semanalmente) — existe um diferentes pacote para diário e semanal, uma vez que a lógica de negócio é distinta entre esses grupos. Por exemplo, o Fact_Daily_Store_Inventory pacote executa tarefas de processamento diferentes do que suas contrapartes downloads, o Fact_Weekly_Store_Inventory pacote, mesmo que ambos afetam a mesma tabela de fatos.
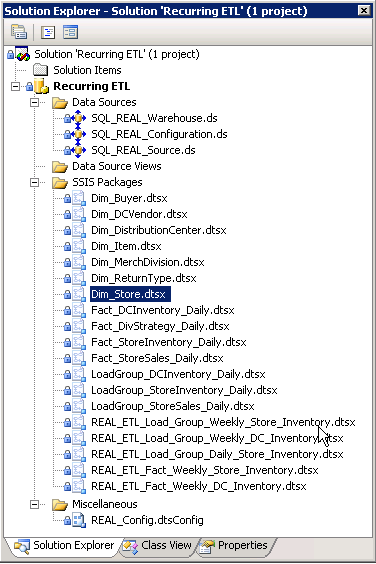
Figura1
Para a coordenação de processamento, um terceiro conjunto de pacotes, chamado carregar o grupo pacotes, é exibido. Esses pacotes não contêm nenhuma lógica de processamento de negócios e são usados para lidar com a coordenação do fluxo de trabalho do pacote de dimensão e fatos anteriormente descritos, bem como alguns aplicativos de auditoria e capacidade de reinicialização. A Figura 2 mostra um exemplo de um grupo de carga pacote. A tarefa de executar pacote é utilizada para executar pacotes de dimensão e de fatos do filho e o fluxo de controle é usado para manipular o fluxo de trabalho e a paralelização de algumas tarefas de processamento. Outras tarefas são incluídas que auxiliam no processo de auditoria e capacidade de reinicialização — estas são descritas em mais detalhes posteriormente neste documento.
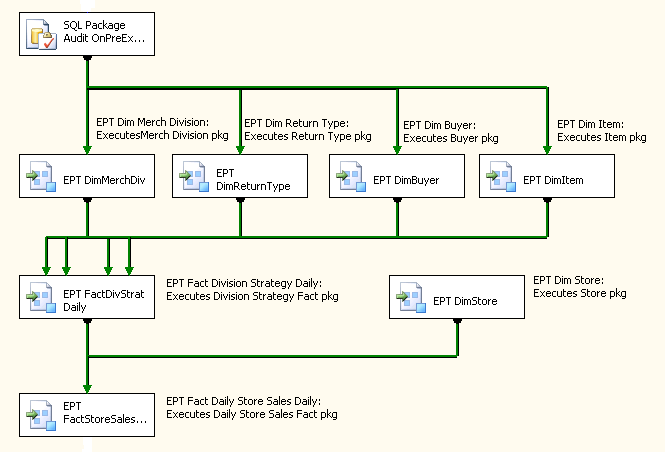
Figura2
Integração do controle de fonte
Uma vantagem que baseados em VS BI Development Studio traz é a integração com controle de fonte . Embora não se limitando a Microsoft Visual Source Safe ® (VSS), o ambiente de desenvolvimento compartilhado para o REAL tem aproveitado VSS para ajudar a impedir o desenvolvimento "bloqueios" onde dois ou mais desenvolvedores tentam trabalhar sobre os mesmos processos ao mesmo tempo. Funcionalidade padrão do VSS inclui histórico e backup; bloqueio de funcionalidade para check-in e check-out pacotes, fontes de dados ou arquivos; e comparação de versão para realçar as diferenças. A maioria dos recursos de controle de fonte é encontrada no arquivo | Menu controle de origem, conforme mostrado na Figura 3.
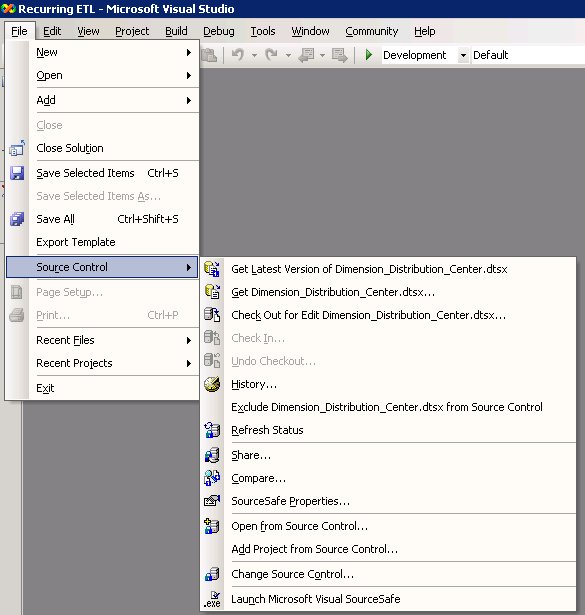
Figura3
Depois de Controlarar de fonte é implementado com o Visual Source Safe ou algum outro aplicativo de controle de fonte , muitos dos recursos relacionados ao objeto no BI Development Studio podem ser acessados clicando simplesmente com o pacote ou dados de fonte conforme mostrado na Figura 4.
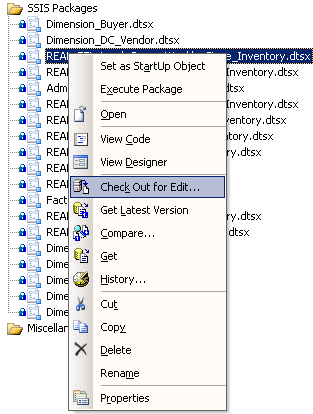
Figura4
Nomenclatura e práticas de Layout
A Convenção que é usada para o layout do pacote , nomeação de tarefas e anotações é digna de nota. Para manter a consistência, todas as tarefas e as transformações são nomeadas começando com um 3 - ou 4‑letra abreviatura do tipo de tarefa ou transformação , seguido de uma descrição de palavra de 3-4 do objeto de função. Isso ajudou muito na auditoria e log, uma vez que os detalhes de registro são controlados pelo nome do objeto. Layout do pacote geralmente flui para baixo primeiro e, em seguida, para a direita como tarefas ou transforma sair de fluxos de controle primário e fluxos de dados. Anotações ajudam para pacotes de documento descrevendo cada tarefa com mais detalhes.
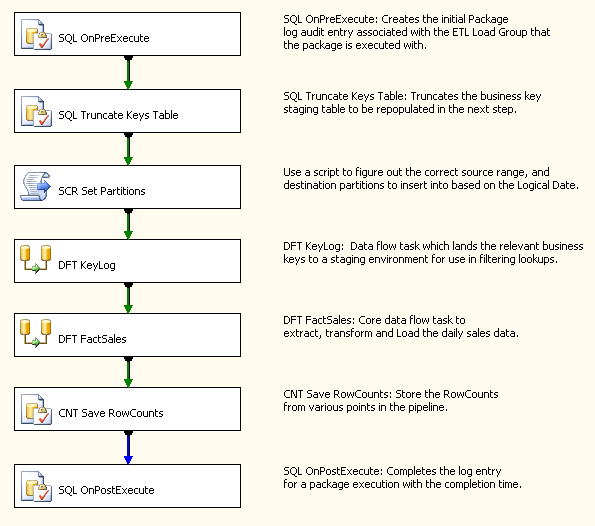
Figura5
ETL auditoria e log
Integrado na concepção de estrutura do pacote através do pai pacotes de fluxo de trabalho e os pacotes filho são etapas de auditoria personalizadas que controlar detalhes de execução de alto -nível , isso inclui a partir do pacote , terminando, e tempos de falhas, bem como linha conta que ajude a validação de volumes de dados e processamento. SSIS nativamente oferece registro de execução detalhada pacote para uma variedade de tipos de provedor de log. Essas entradas de log de detalhes são evento-driven e desnormalizado em selecionado provedordo destino. Por exemplo, se um banco de dados é escolhido como o provedorde log, todas as entradas de log são inseridas em uma única tabela. Um evento é ponto de referência do motor durante toda a execução — em aviso, na validação, em executar, no pré executar, no Post Execute, etc. Figura 6 destaca o seletor de detalhes de evento de log.
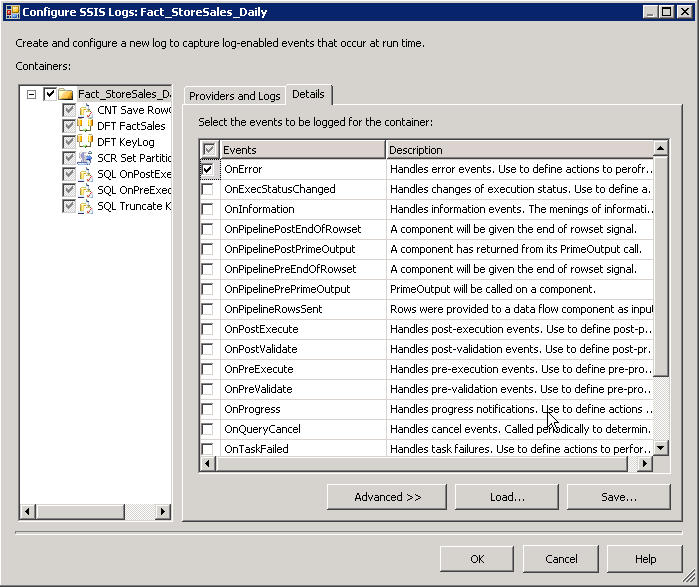
Figura6
Cada registro em um log de evento é associado com o ID de execução do associado pacote que correu para a tarefa ou transformação debaixo. Essa ID de execução é um GUID que é gerado com exclusividade cada vez que um pacote é executado. Como você pode imaginar, quando o log SSIS está ligado, o grão mais baixo, ele pode produzir centenas, senão milhares de entradas para cada pacote. O log SSIS fornece grande detalhe para fins de solução de problemas. No entanto, por si só esta informação é difícil colher e siga sem profundo conhecimento do SSIS eventos e uma maneira limpa para mapear o pacote ID de execução para um específico pacote executado pelo mecanismo.
Para o Project REAL, o objetivo era aumentar de log interna do provedor com alguns específica relacionados com o BI execução auditoria, mas também para aproveitar os recursos de log para emissão de relatórios detalhados de drill-down. A estrutura de auditoria voltado as seguintes características:
- Associação de grupo de pacote e carga e identificação.
- Adições de coluna de linhagem para as estruturas de armazém.
- Auditoria de validação de número de linhas.
- Processamento de ETL relatórios com a capacidade de fazer uma busca detalhada.
Pacote e rastreamento de grupo de carga
Noções básicas sobre a coordenação dos pacotes usados para um processo ETL é fundamental para o apoio e a administração de uma solução de BI. Portanto, um maior nível tabela de controle foi criada para permitir que as associações de pacotes relacionados executados juntos. Em segundo lugar, uma tabela também foi criado em grãos de execução de um único pacote . Enquanto isto pode soar um pouco redundante com os recursos de log do SSIS, permite um mapeamento simples entre o ID de execução de internos de log do provedor com o nome do pacote e o grupo ID do processo do fluxo de trabalho da execução de nível superior. Desde que o pacote auditoria tabela contém apenas um registro único para cada execução de um pacote, ele também simplifica a emissão de relatórios e permite recursos de relatório de detalhamento.
Auditoria do projeto aplicativo REAL é implementado principalmente com a executar SQL tarefa. Para os pacotes de fluxo de trabalho, as primeiras e últimos etapas no fluxo de controle de gerenciam a auditoria de grupo de carga. Neste exemplo a carga grupo pacote, você vai notar que os primeiros e últimos passos são destacados no fluxo de controle de que trata este processo.

Figura7
Um nível mais baixo do que a auditoria de fluxo de trabalho de pacote é o pacote nível de controle, que também contém um design semelhante usando os primeiros e últimos passos de fluxo de controle. Desde que o grupo carga pacote é também um pacote em si, você pode ver na Figura 7 que a segunda etapa e a segunda para última etapa são também auditoria executar SQL tarefas. Em uma dimensão ou tabela de fatos pacote, estas são as etapas de primeiras e últimos.
Outro aspecto central de auditoria é identificar rapidamente os erros. Um recurso interessante do SSIS é o conceito do evento manipulador de controle de fluxos. Estes estão disponíveis na guia terceira do pacote interface do usuário. O manipulador de evento OnError é empregado para esta finalidade e definido no pacotedonível, que vai interceptar quaisquer erros de pacote que emergir.
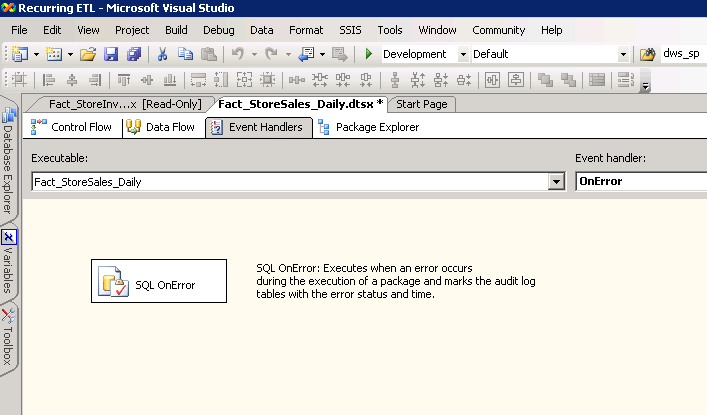
Figura8
Além disso, um conjunto de variáveis do pacote é usado para controlar metadados entre o banco de dados e pacotes através destes executar SQL tarefas. As principais variáveis usadas são as variáveis de sistema system::PackageExecutionID e system::PackageName e a variável de usuário user::ETL_Load_ID, que é o identificador criado no banco de dados e passados de volta para os pacotes. Essas variáveis são também passadas de pai pacote para os pacotes filho usando o recurso de configuração de variável pai do SSIS.
Adições de linhagem ao armazém
O identificador do lote , ETL_Load_ID, reúne não só a auditoria metadados para emissão de relatórios e isolar, mas ele também é usado no armazém para identificar o registro fonte. Cada registro de dimensão e de fatos se originou de uma carga de dados específicos, e esta coluna identifica essa carga. Isso é útil para fins de validação e linhagem de dados, além de correções manuais necessárias em caso de corrupção de dados.
O identificador do lote é adicionado para o fluxo de dados imediatamente após os dados de fonte são extraídos, usando a coluna derivada transformação. Portanto, quaisquer transformações downstream podem utilizar esta coluna para atualizações, inserções e controle, e há pouca sobrecarga deve incluir esses metadados com os registros.
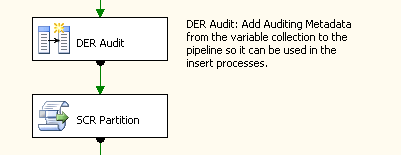
Figura9
Contagem de linhas de controle
Validação de dados é uma sono ajuda para DBAs — integral para a solução de BI para administração e solução de problemas, mas também um construtor de confiança para a Comunidade de usuários. Se os usuários não confiar nos dados, então a solução está em risco de falha. O Project REAL emprega linha contando como uma demonstração de um aspecto de validação de dados. Embora este nível de validação representa apenas um subconjunto do que deve ser feito, é um sólido primeiro nível de validação.
Auditoria de contagem de linha é implementado dentro do fluxo de dados usando a contagem de linhas transformação, que simplesmente conta o número de linhas que passam por ele e armazena o valor em uma variável de utilizador predefinidos. Um bom recurso de contagem de linhas transformação é o mínimo de sobrecarga e recursos que ele requer. Assim, dentro do fluxo de dados de núcleo de todos os pacotes de dimensão e de fato, uma contagem de linhas transformação foi inserido após cada fonte, antes de cada destino ou OLE BD comando e em qualquer ponto de alto valor no meio do fluxo de dados. As contagens são colocadas em variáveis separadas e, em seguida, mantidas no banco de dados com um executar SQL tarefa imediatamente após a transformaçãode fluxo de dados. A Figura 10 mostra a implementação destas transformações de contagem de linha no fluxo de dados.
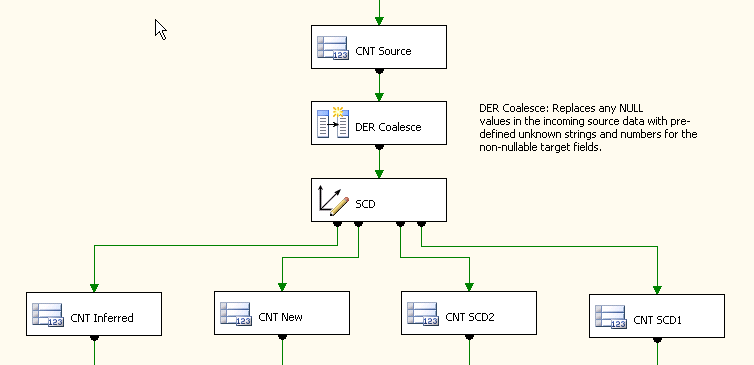
Figura10
Emissão de relatórios de ETL
Para unir tudo e apresentar bem organizado informações para o administrador e uma ferramenta de solução de problemas para o desenvolvedor, uma série de vinculado Reporting Services relatórios foram projetados, que correlacionam a auditoria, validação e log. Pisando voltar, se você seguiu a discussão de auditoria, você provavelmente tem uma idéia da esquema de suporte que permite que os metadados ser associado. Existem quatro tabelas primárias usadas no esquema — três tabelas definidas pelo usuário integrada com o built-in SSIS log de tabela.
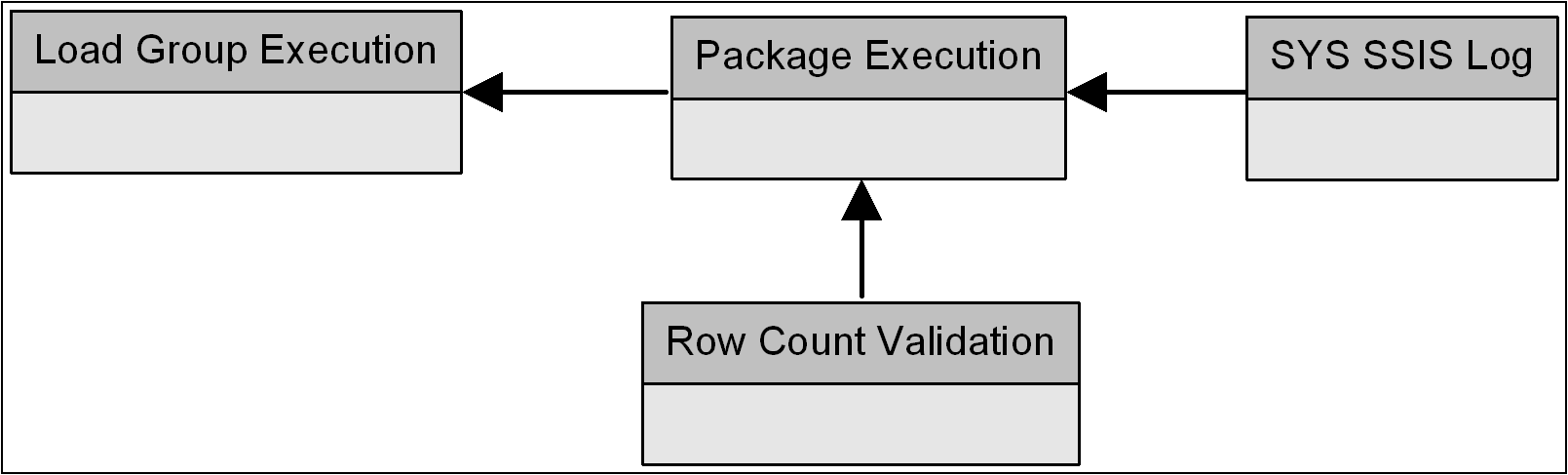
Figura11
Projeto REAL ETL relatório baseia-se nessas estruturas e fornece a execução de grupo de carga de alto nível resumo com a capacidade para detalhar os detalhes, usando o Reporting Services tabela agrupamento e sub-relatórios vinculados. Os seguintes níveis de emissão de relatórios estão incluídos:
- Grupo de execução sumária de carga – horários de início e conclusão, resumo de duração e status de execução.
- Resumo de execução do pacote – associação de grupo, horários de início e conclusão, resumo de duração e status de execução de carga.
- Detalhes de contagem de linhas – etapa descrição e tipo, contagem de linhas.
- Controle de fluxo tarefa resumo do pacote – tarefa resumo agregação derivado da tabela de log base com duração de tarefas e status.
- Detalhadas linhagem de Log de eventos – entradas de log de detalhes ordenada e filtrada para o selecionado pacote ou tarefa.
Uma noção geral de um relatório ETL demonstra sua utilidade no gerenciamento de soluções do SSIS e solução de problemas.
Figura12
Design dinâmico de configuração
A chave para a capacidade de gerenciamento, distribuição e implantação de pacotes do SSIS situa-se na configuração. SSIS contém várias maneiras de configurar as propriedades do pacote em tempo de execução, que permitem a atualização das propriedades de informações, variáveis e quaisquer outras tarefas ou transformação de conexão que requerem um dinâmico configuração em execução. Vários métodos internos de configuração estão disponíveis que cobrem um amplo espectro de requisitos de ambiente que soluções diferentes podem aproveitar, incluindo:
- Arquivos de configuração
- Variáveis de ambiente
- SQLtabelas deconfiguração
- Variáveis do pacote pai
Uma área onde esta funcionalidade é muito útil é quando migrar um ETL pacote de desenvolvimento para preparo para produção. Na maioria dos casos, isso pode ser feito alterando simplesmente algumas entradas no sistema de configuração .
Configurações deSQL
O objetivo do projeto REAL foi Centralizar configurações e permitir que o design ETL ser destacáveis para dois ambientes exclusivos, a escala de modelo e modelo distribuído. Da mesma forma, também existem várias versões da solução REAL (um volume completo versão, uma amostra versãoe demo versão) para fins de referência e demonstração. Por conseguinte, configurações estavam centralizadas para as versões de banco de dados diferente da solução usando as configurações de SQL incorporadas, permitir que as propriedades de configuração e mapeamentos para ser colocado em uma tabela de relacional e compartilhados entre pacotes. Para abrir a ferramentade gerenciamento centralizado, você seleciona SSIS, em seguida, configurações. A Figura 13 mostra as opções de configuração do SQL .
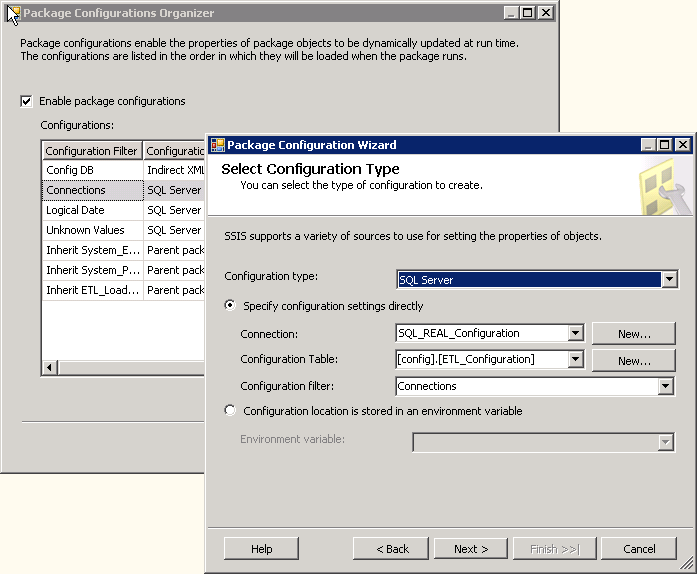
Figura13
Existem várias entradas para diferentes propriedades de configuração tabela. O primeiro conjunto de entradas é para conexões. É importante destacar como aplicam as entradas de configuração para conexões e como fontes de dados da solução de trabalho para um pacote. Quando uma conexão é criada a partir de um objeto de fonte de dados, a conexão é uma cópia de tempo de execução da fonte de dados e não é actualizada da fonte de dados pai quando um pacote é executado. Fontes de dados são construções de tempo de design, para que quando um pacote é aberto na interface do usuário, as conexões são atualizadas se eles foram construídos de uma fonte dentro da solução do SSIS. Por causa disto, as conexões são um grande candidato para configurações — eles normalmente precisam ser dinâmicos baseados no ambiente (desenvolvimento, teste e produção). Outras entradas na configuraçãoProject REALtabela são mapeamentos variáveis, que permitem a atualização dos valores de variáveis usadas no ETL para processamento de lógica e gerenciamento.
Configurações de arquivo XML
Na Figura 13, o local da SQL apropriado configurações tabela baseia-se em uma conexão de pacote . No entanto, se todas as informações de conexão são localizadas na configuração tabela, então isto representaria uma referência circular que resultaria na utilização do valor de conexão codificado do pacote , que não é desejado. Para evitar isso, foi usado um segundo tipo de configuração — configurações do arquivo XML. Mais uma vez, com o objetivo de centralizar as configurações para uma tabelade banco de dados, é necessário apenas uma entrada de configuração no arquivo XML — a cadeia de conexão que aponta para o banco de dados que contém as configurações do SQL tabela. Como você pode ver, é realmente apenas uma propriedade para um arquivo XML configuração— o local e o nome do arquivo XML.
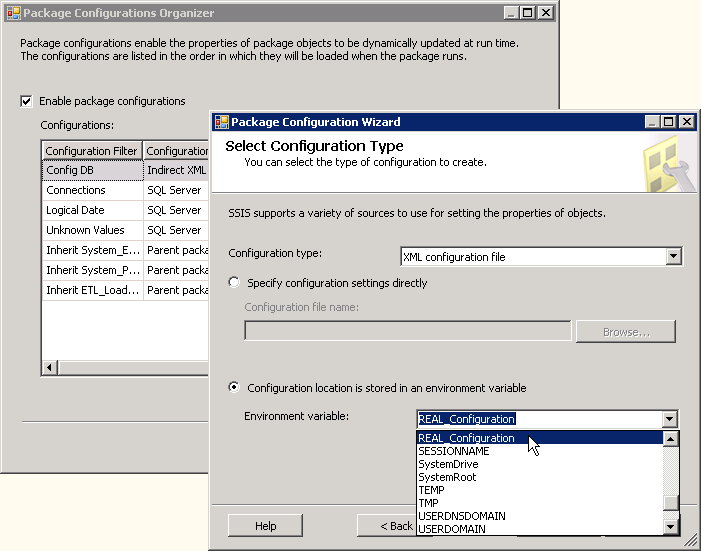
Figura14
Um recurso valioso da arquivo de configuração é a capacidade de usar uma variável de ambiente do servidor que define o local do arquivo de configuração . Uma vez que todos os pacotes de referência neste arquivo, usar uma variável de ambiente permite que um único local para uma alteração no arquivo. Isso também é valioso para implantação, onde outros servidores executando esses pacotes podem usar arquivo diferentes localizações e nomes de arquivo. O uso de variáveis de ambiente é diferente do que a configuração de variável SSIS ambiente onde um servidor pode conter várias variáveis de ambiente que substituir qualquer pacote propriedade.
Configurações de variáveis pai
Todo o uso de configuração Project REAL descrito até agora tem sido de propriedades globais em escopo— isto é, conexões e variáveis que são usadas para cada execução de um pacote ou um grupo de pacotes em um determinado ambiente. Algumas configurações precisam ser limitado para a execução específica do grupo de pacote e fluxo de trabalho em que participa o pacote . Por exemplo, o identificador de lote do grupo de fluxo de trabalho, ETL_Load_ID, é criado na etapa inicial do grupo carga pacote e usado em todos os pacotes de filho . Cada execução dos pacotes é executado sob o contexto de um novo lote e, portanto, a configuração para esta variável precisa ser dinâmico de acordo com o pacotede execução.
O recurso de configuração de variável pai do SSIS permite variáveis de um pai pacote a ser herdada por um filho pacote. Isso é diferente do que o antecessor do SSIS, DTS, onde variáveis foram empurrados para baixo do pai pacote para opacotede filho. No SSIS filho pacote solicita a variável por nome do pai de pacote, permitindo que a variável a ser herdado de qualquer chamada pai pacote que usa a tarefa de executar pacote para chamar o filho pacote.
O Project REAL para ter uma configuração que é local para a instância de execução do pacote ou conjunto de pacotes bem requisito pelo recurso de configuração de variável pai. Como já foi referido, o ETL_Load_ID é herdada por todos os pacotes de dimensão e de fatos, bem como a identificação de execução do pacote do pai para permitir a correlação entre os pacotes de dados. A Figura 15 mostra a variável de configuração para o vnETL_Load_ID identificador.
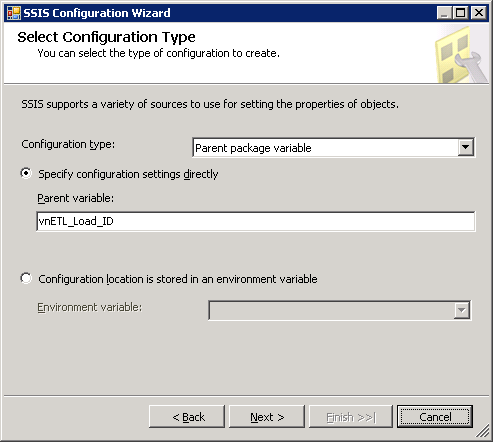
Figura15
Arquitetura de processamento de dados
Até agora temos discutido a estrutura de suporte do SSIS design sem mergulhar em qualquer um dos principais lógica de processamento de ETL. Esta visão geral ajudou a conjunto o cenário para uma reflexão mais pensativo sobre a lógica de processamento, tendo em conta os conceitos abordados nas seções anteriores deste documento. No entanto, antes de descrever os detalhes da implementação de processamento de dados do Project REAL, é importante voltar atrás e considerar alguns dos novos recursos do SSIS no contexto de princípios importantes de ETL.
Fluxo de controle e fluxo de dados
Os principais recursos do SSIS usado para implementar a lógica de negócio do núcleo estão contidos nos componentes de fluxo de controle e fluxo de dados. Esses componentes já foram mencionados algumas vezes neste artigo ao referenciar o ambiente e auditoria de estruturas de Project REAL.
A nívelsuperficial, o Fluxo de controle é o mecanismo de fluxo de trabalho de tarefa que coordena a lógica de fluxo de processo de negócios para um pacote. Cada pacote tem exatamente um fluxo de controle primário (manipuladores de eventos são um tipo de fluxo de controle também) se ele contém uma única etapa ou dezenas de tarefas interconectadas. As tarefas dentro do fluxo de controle são ligadas por restrições — sucesso, falha, conclusão e expressões de restrição personalizada e lógica booleana.
O De fluxo de dados é o mecanismo de processamento de dados que controla a movimentação de dados, lógica de transformação , organização de dados e a extração e compromisso dos dados para e partir de origens e destinos. Ao contrário do fluxo de controle, pode haver vários dados flui definidos em pacotes que são coordenadas pelo fluxo de controle. Embora o fluxo de dados possui conectores verdes e vermelhos que são muito semelhantes aos conectores de fluxo de trabalho de fluxo de controle, sua função é completamente diferente. Considere o conector de fluxo de dados como um pipeline de dados que está fluindo de uma transformação para outro em pequenos lotes de dados, chamados buffers de. Enquanto isso é a maneira mais fácil de visualizar como funciona o fluxo de dados, na realidade as transformações definidas são realmente as coisas fazendo a maior parte do que se deslocam — sobre os buffers de dados para o melhor desempenho ideal.
Vantagens de arquitetura do SSIS
Além das vantagens de produto que SSIS tem sobre DTS nas áreas de interoperabilidade, configuração, capacidade de reinicialização e registro em log, ele traz um mecanismo de transformação que permite economias de escala e abre a arquitetura ETL para mais estável, flexível e projetos baseados em desempenho. Para o Project REAL, essas vantagens foram consideradas no núcleo desenvolvimento de ETL e, por conseguinte, determinadas decisões de design afastou o status quo arquitetura baseada em DTS.
Edição limitada
Para começar, o SSIS permite a redução de um ambiente de preparo, permitindo transformações de dados complexas, limpeza e pesquisas para ser executada diretamente no fluxo de dados, com pouca dependência do mecanismo de RDBMS e armazenamento. As comparações de dados entre as tabelas de fonte e armazém podem ser manipuladas através de pesquisas e mesclagem transformações com divisões condicionais para direcionar os resultados para a lógica de carregamento apropriado. Com esta consideração, é o único requisito para o mecanismo de banco de dados exportar os dados para o fluxo de dados do SSIS e não para o banco de dados que está realizando a pesquisas ou associações ou comparações de linha.
Vantagens de pipeline
A maioria dos componentes de fluxo de dados permitem verdadeiro paralelismo pipeline (com algumas exceções notáveis, como as transformações de classificar e agregado), que significa que o espectro de processamento para armazém s está acontecendo simultaneamente nos buffers de dados pequenos sem a necessidade de esperar por todo o processo de upstream terminar antes de passar para a próxima. Isso ajuda a aliviar o impacto da extração no sistema de fonte e na maioria dos casos vistos durante o desenvolvimento do Project REAL, quando um pacote do SSIS é otimizado, o tempo necessário para extrair dados brutos de fonte e terra imediatamente para um banco de dados é aproximadamente equivalente ao tempo necessário para extrair os dados e passá-lo para uma série de transformações na memória projetada no componente de fluxo de dados.
Limpeza de dados e transformação
Fora das transformações de fluxo de dados do SSIS de caixa incluem uma série de ferramentas tais como pesquisas difusas e junções, mapas de caracteres, conversões de tipo de dados, colunas derivadas e um conjunto de funções baseadas em Boolean para comparações de dados e substituição de limpeza de dados.
Destinos e fontes de muitos-para-muitos.
Uma vez que um único fluxo de dados pode conter várias fontes heterogêneas e destinos, isso libera dados originados a partir de uma única fonte para ser dividida para vários destinos. O mesmo se aplica para o cenário inverso; podem combinar vários objetos de fonte para um único destino. Muitas vezes em um sistema de BI, uma dimensão pode ser originada de tabelas diferentes dentro do mesmo sistema ou de diferentes sistemas. Da mesma forma, fatos podem se originar de uma ou várias tabelas ou transacional fonte pode ser quebradas para vários destinos de tabela de fatos .
Alterações de grãos e tipo de dimensão e de fatos
Na maioria das vezes, armazém objetos são carregados no mesmo Grão como seu objeto de fonte de OLTP. No entanto, pode haver situações em que uma dimensão é agregada para um grão mais elevado ou um pai filho self-joined fonte é desnormalizado para uma hierarquia padrão. Registros de origem podem exigir dinamização, por exemplo, quando linhas de fonte são consolidadas de um quarto normal design para baixo para um conjunto de registros consolidado de atributos relacionados. Tabelas de fatos também podem passar por transformações semelhantes quando eles são agregados ou agrupados para atender às exigências de informação. Estas menos cenários comuns muitas vezes podem ser manipuladas dentro do fluxo de dados usando outras transformações de out-of-box —agregação, pivô, un-dinâmica, classificação, junção de mesclagem, etc.
Processamento de dimensões
A história de uma dimensão de manipulação é um dos aspectos mais complexos de uma solução ETL. Para o Project REAL, os cenários de carregamento dimensional envolvem mais do que apenas processamento atributos históricos e de alteração, mas também a dimensão alterar tipos e fato fora de sincronização para associações de dimensão. Além de considerar a funcionalidade interna do assistente SCD (lentamente a dimensão variável), também nós vai aflorar algumas exigências mais distintas incluídas no projeto:
- Inferido Membros da dimensão, onde um fato é recebido sem um membro correspondente da dimensão porque o registro de dimensão total não foi ainda disponível para carregar. Algumas vezes referido como fatos órfãos.
- Alteração de tipos de SCD, onde os membros dentro de uma única dimensão têm requisitos diferentes mudança histórica que individualmente podem sofrer alterações através do tempo.
SSIS forneceu os recursos para lidar com os casos padrão e exclusivos da solução Project REAL, como será mostrado.
Assistente de dimensão de alteração lenta
Na lista de desejos de cada ETL designer é uma ferramenta que pode lidar com dimensões de alteração lenta magicamente. SSIS chega perto — no SSIS é um assistente que orienta o desenvolvedor através de uma série de etapas com base em esquemas de dimensão de fonte e de destino , para determinar as características de mudanças. O assistente cria as transformações necessárias para processar essa dimensão. Mesmo quando as necessidades mudam, chamar o assistente é com monitoração de Estado, permitindo que as seleções originais ser modificado para lidar com o novo processo.
Para o Project REAL, o lentamente mudando dimensão (SCD) ferramenta foi muito vantajosa. Todas as tabelas de dimensão do esquema em estrela usa o SCD transformação. Ele drasticamente reduzido tempo de desenvolvimento para o processamento da dimensão. Para mostrar como funciona o Assistente do SCD, a dimensão Store fornece o uso mais abrangente do assistente. Os requisitos da dimensão loja envolvem:
- Novos membros da dimensão – a adição de um novo membro da dimensão que é adicionado à fonte
- Alterar os atributos de dimensão – as alterações tradicionais tipo-1 coluna onde história é sobrescrita sempre que altera o valor dacoluna fonte.
- Atributo de dimensão histórica – o tipo-2 tradicional coluna onde a história é mantida pela adição de um novo registro de dimensão que está associado com todos os novos registros de fato até a próxima alteração.
- Inferido Membros – a situação em que um membro da dimensão não foi carregado no tabela de dimensões antes do processo de fato é executado e assim que um registro de espaço reservado é adicionado, que é então posteriormente atualizada (tipo 1 e tipo 2 colunas) quando a dimensão completa fonte torna-se disponível
Executando o Assistente para a dimensão Store, a primeira tela mostra uma lista de colunas com uma seleção disponível para seus negócios chave(s) como mostrado na Figura 16.
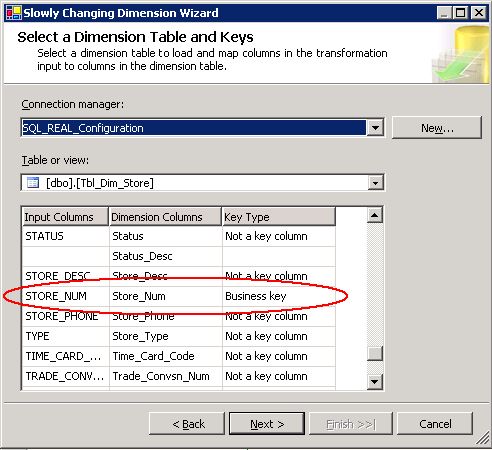
Figura16
Em seguida, o assistente requer uma distinção das colunas que participam os tipos de alteração. As opções estão mudando atributo, atributo histórico e atributo fixo, que identifica colunas que não devem ser alteradas. A Figura 17 mostra esses atributos.
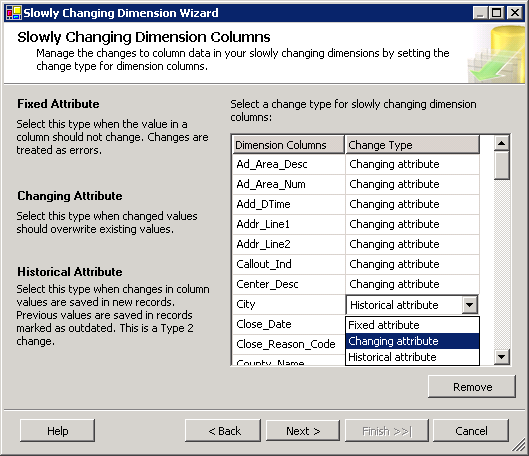
Figura17
Dimensões que contêm colunas históricas ou tipo-2 requerem alguns metadados para gerenciar a natureza atual e histórica de cada alteração. A próxima tela (Figura 18) ajuda o processo sabe como a dimensão store trilhas história. Nessa situação, um Current_Row coluna controla o registro de dimensão é o atual para a linha de dimensão que muda.
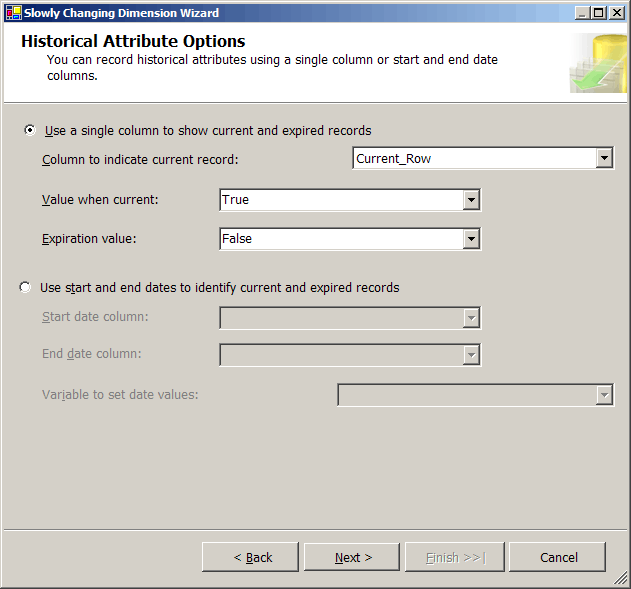
Figura18
Em seguida, se inferido Membros são usados, a tela mostrada na Figura 19 identifica como o Assistente do SCD sabe quando um registro de dimensão é um membro deduzido, para que todas as colunas, além do negócio chave são atualizadas durante o processamento. Existem duas opções. A primeira opção indica que todos os não-chave colunas são valores NULL para identificar um membro deduzido. A segunda opção é impulsionada por uma coluna do sinalizador que indica se o membro é inferido. Dado que colunas NULL não exibir bem no Analysis Services, nós escolhemos usar uma coluna chamada Inferred_Member. Em seguida, fomos capazes de substituir os atributos usados em hierarquias de Analysis Services com nomeado valores desconhecido.
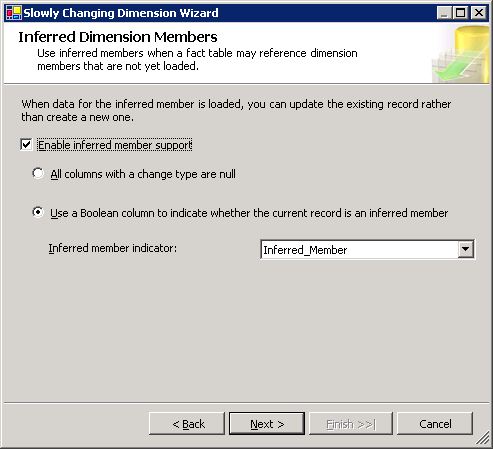
Figura19
Após a última tela, o assistente gera uma série de transformações personalizadas para os detalhes que foram inseridos durante o processo do assistente. A principal transformação é chamado a dimensão de alteração lenta transformação. Toma como entrada os registros de fonte para a dimensão, se eles são uma cópia completa da dimensão de fonte ou apenas um subconjunto dos registros de fonte — aqueles adicionados ou alterados na fonte. Considere a tarefa SCD para ser como uma combinação de uma pesquisa sem cache transformação e uma divisão condicional transformação, onde os registros de dimensão de fonte são avaliados em relação a dimensão de armazém e depois distribuídos para as diferentes saídas do SCD. A Figura 20 mostra a imagem de interface do usuário final da loja SCD transformação com suas saídas associadas.
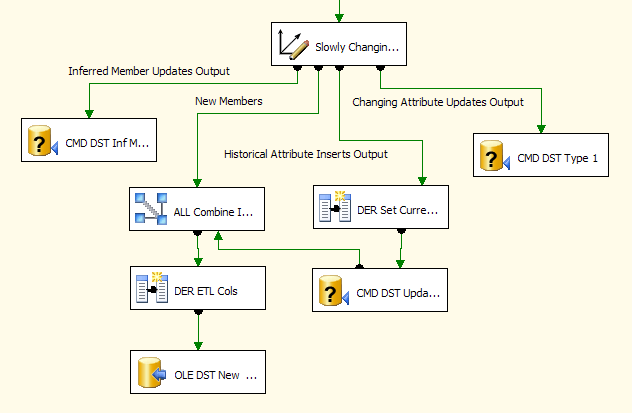
Figura20
Cenário de dimensão exclusiva
A dimensão REAL projeto única pacote que não usam o SCD transformação de processamento é a dimensão de Item. Suas necessidades são únicas e seu tamanho (cerca de 6 milhões de Membros) requer um tratamento especial para escalabilidade.
Uma característica que diferencia a dimensão do Item do resto das dimensões é o tipo de tipos de alteração SCD que ocorrem. Além de exigir que o membro deduzido, alterar atributos e atributos históricos, os requisitos de especificar que, para um determinado membro, seus tipos de alteração de atributo podem modular alterem a histórica; Digite 1 para tipo 2. Esta situação ocorre quando a primeira venda acontece para um item. Antes da primeira venda, todos os atributos de agir como alterar os atributos de tipo-1, mas uma vez que uma venda ocorre, um subconjunto dos atributos tornam-se mudanças históricas do tipo-2. Este cenário tem sido cunhado uma alteração de tipo 1.5 e é impulsionado pelo desejo de negócios para limitar o número de tipo-2 adições à dimensão; Isto é porque quando um item é inserido no sistema transacional pela primeira vez, o processo para estabelecer suas características faz com que várias alterações acontecer nos primeiros dias. Enquanto esses detalhes de atributo iniciais são trabalhados, o membro da dimensão está em um Estado onde uma mudança para qualquer atributo faz com que uma atualização desse atributo na dimensão ao invés de um novo registro de histórico de tipo-2. É o valor que essa abordagem fornece para limitar o crescimento tabela de dimensões para mudanças históricas importantes, que quando um item é estável e venda. Embora impulsionado por requisitos de negócios diferentes, este cenário é semelhante à forma como funciona um membro deduzido. No entanto, neste caso o registro de dimensão de fonte está disponível e a necessidade de atualizar todos os atributos permanece até que o requisito de venda.
Um fator decisivo de usar o Assistente do SCD ou não foi o volume de registros processados para a dimensão. A dimensão do Item 6 - milhões de membro pode submeter-se dezenas de milhares de alterações por dia através de seus 100 atributos. O processo de pesquisa de componentes interno do SCD foi gerar um número equivalente de chamadas para o banco de dados, consultando um grande grande tabelae retornando dezenas de colunas na linha de resultado. Esse processo não foi suficiente para a janela de tempo desejado; por conseguinte, uma abordagem alternativa foi tomada.
Foi uma opção para usar uma pesquisa de transformação e trazer toda a dimensão no cache para que todas as colunas seria disponíveis para as comparações do tipo de alteração. No entanto, todas as colunas de uma grande tabela de cache necessário vários GB de memória e teria levado uma quantidade significativa de tempo para ser carregado na memória. Assim, em vez disso, uma esquerda Merge Join transformação foi usada, onde os registros de fonte à esquerda foram combinados com os membros da dimensão atual à direita através de de negócios chave, como mostra a Figura 21. O efeito desta associação foi fluir em somente aqueles Item registros que foram realmente utilizados em factos relevantes. Colunas necessárias da dimensão para análise do tipo de alterações foram incluídas no fluxo de dados de registros correspondentes. Uma mesclagem esquerda foi usada para que novos registros da fonte (à esquerda) iria continuar para baixo a tubulação onde iria ser adicionados à dimensão, como novos membros.
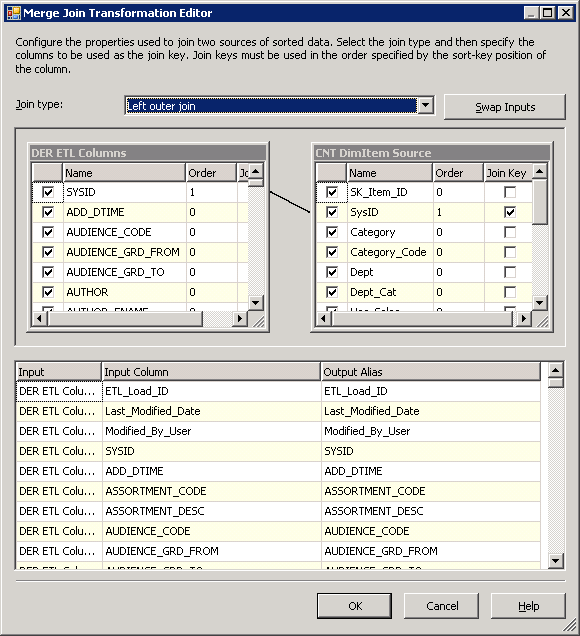
Figura21
A mesclagem neste cenário executa muito bem porque as colunas de entrada já estão classificadas — como correspondências ocorrem, os registros são liberados para as transformações downstream para processamento.
transformação de divisão condicional (localizada imediatamente abaixo o Merge Join transformação) avalia determinadas condições e, em seguida, dirige as linhas para múltiplas saídas da transformação . As condições são avaliadas em ordem. A primeira condição reuniram-se para uma linha designa sua saída, para que uma linha não é enviada a várias saídas.
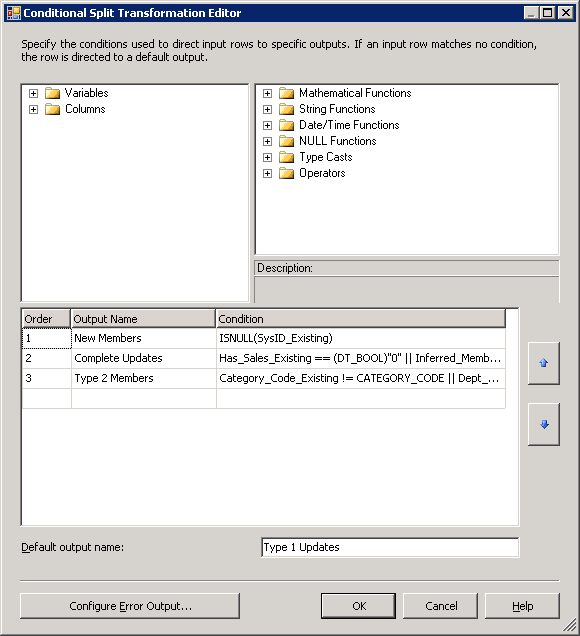
Figura22
A divisão condicional transformação na Figura 22 primeiro avalia se o lado direito do join tinha uma correspondência usando um ISNULL função. Linhas de origem que correspondeu a seleção nula estão de saída para uma transformação que adiciona a linha como um novo membro de dimensão. Desde os membros restantes todos tem correspondência para o armazém tabela de dimensões, o tipo de mudança critérios são avaliados. Para registros correspondentes, os primeiros critérios avaliados são as condições de membro inferido e bandeira de vendas. Uma vez que ambos exigem uma atualização completa para os atributos de dimensão, eles são combinados e manipulados ao mesmo tempo. Mudança histórica, próxima atributos são avaliados. Se não houver uma alteração em um ou mais dos atributos historicamente controlados, é gerado um registro de mudança de tipo-2. Finalmente, todas as alterações para as colunas de tipo de mutação restantes causam uma instrução de atualização de dimensão substituir o anterior valor para esse atributo (em forma de tipo-1).
Observe que a condição final não for especificada, mas o padrão para a divisão de condição de saída descreve este cenário. Uma vez que os registros de fonte são apenas novos e alterados linhas, sabemos que se todos os outros requisitos, os últimos critérios devem aplicar para os registros restantes. Isso enfatiza o fato de que a ordem dos critérios é crucial para o tratamento correto da dimensão do Item desta forma.
As transformações a jusante da divisão condicional são muito semelhantes à saída da SCD transformação no exemplo de loja. Isso é porque a saída é modelada após o SCD processamento de novas adições, alterações e inferido Membros (chamado atualizações completas por causa das mudanças de tipo 1,5).
Figura23
Processamento de tabelas de fato
Manipulação da transformação de tabela de fatos é, na sua maior parte, muito diferente do processamento da dimensão.Além disso, um processo de tabela de fatos pode ser muito diferente do próximo. No entanto, a maioria dos processos de tabela de fatos contêm fato linha comparações e pesquisas de chave de dimensão. Para fins de ilustração, um par de diferentes pacotes de tabela de fatos Project REAL é destacado nesta seção. Estes pacotes modelar cenários comuns.
Extrações incrementais e completa fonte
O projeto REAL ETL tem dois tipos de extracções tabela de fatos ; completa fonte extrações, onde novos ou alterados registros não são identificáveis e Extrações incrementais, onde novos e alterados registros somente são extraídos.
Extrações completa fonte
As posições de estoque do distrito central (DC) são controladas semanalmente para diferentes combinações de DC e item cerca de 8 milhões. No sistema de fonte , esses registros estão contidos em uma tabela que não identifica um registro novo ou modificado, por conseguinte, o processo ETL deve comparar registros entre o inventário fonte e o tabela de fatos para identificar quando ocorreu uma mudança. Ele pode então corretamente lidar com a inserção ou atualização.
A abordagem adoptada foi usar uma junção de mesclagem completa com o conjunto de dados completo para tabelas de fonte e destino . Um full join ajuda a identificar quando um registro de inventário foi adicionado na fonte ou completamente removido. Para esta solução, os requisitos especificados que registros excluídos fonte necessários a serem controladas como uma posição de estoque zero tabela de fatos— usando um Merge Join transformação configurado como um full join satisfaz este requisito. A mesclagem é mostrada na Figura 24.
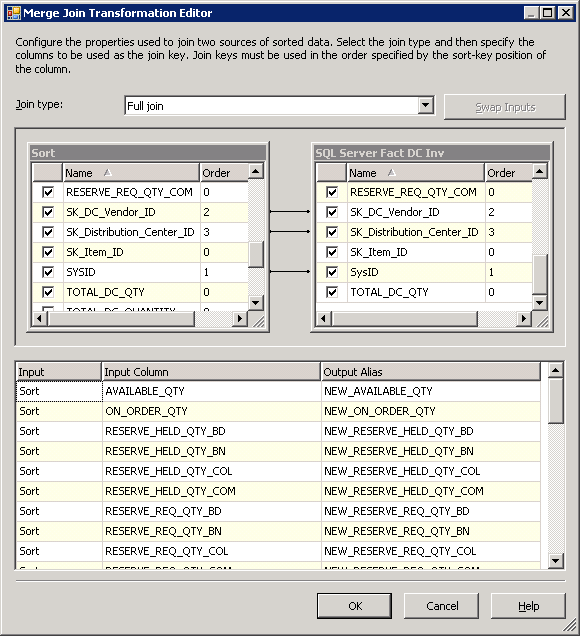
Figura24
O próximo a jusante transformação, uma divisão condicional transformação, lida com a identificação de alterações do registro, avaliando a junção de resultados e a comparação de valores de coluna .
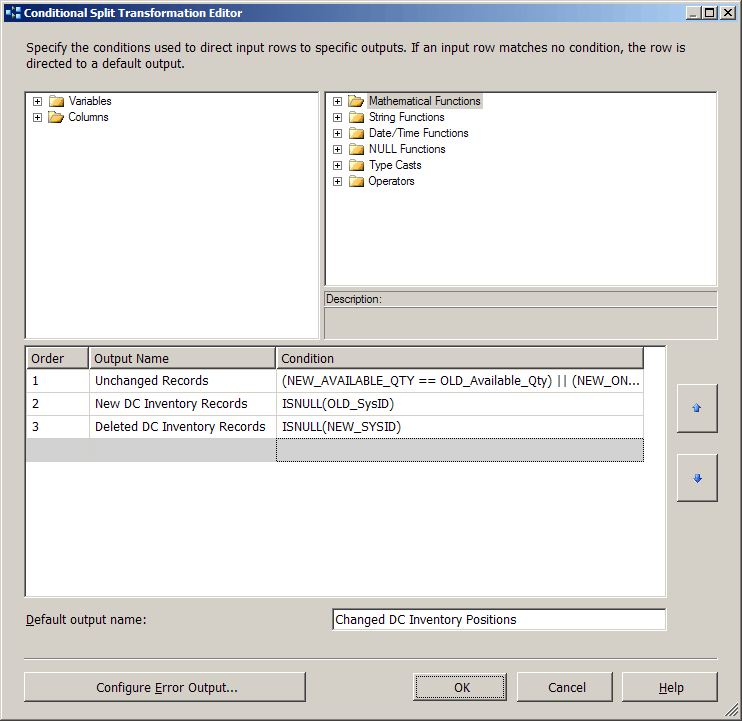
Figura25
As condições aplicadas na transformação de divisão condicional são ordenadas para desempenho, começando com o caso onde a associação produziu uma correspondência e os atributos e medidas não foram alteradas. Esta saída é listada primeiro no designer, uma vez que a maioria dos registros de cumprir este critério, mas o fluxo de saída não é usado. Desde registros inalterados não exigem processamento, isso tem o efeito de filtrar as linhas. O segundo critério é identificar novos registros de inventário — aqueles onde a linha de fonte não tinha uma correspondência com um registro de tabela de fatos existente. Em contraste, a próxima avaliação é o cenário de full join onde a posição de inventário de fato precisa ser conjunto como zero porque a linha de fonte foi removida. Finalmente, todas as outras linhas estão presos com a saída padrão; estes tiveram mudanças de posição de inventário e precisam ser atualizados no banco de dados.
Extrações incrementais fonte
Quando um processo de extração pode isolar o conjunto de atualizações e inserções em um sistema de fonte , isso pode aumentam o desempenho do processo ETL relacionado. Felizmente, muitas das fontes de dados grandes no Project REAL são capazes de aproveitar estes puxa direcionadas. Um exemplo disto é a extração de inventário da loja. Se toda a armazenar inventário fonte— perto de 200 milhões de registros — foi necessária para processar as alterações diárias, não haveria suficiente horas em um dia para lidar com a carga. Mas uma vez que o inventário diário pode ser extraído incrementalmente, o processamento de janela é reduzido a um muito gerenciável janela.
Para o inventário da loja, o processo de extração incremental usa uma pesquisa em cache para ajudar a determinar se um registro incremental é uma inserção ou atualização. Uma coisa que ajuda nesse processo é um processo encenado provisório, que é usado para filtrar os registros na pesquisa, otimizar o processamento e ajudar a implementação global. Para obter mais informações, consulte técnicas de otimização de processamento de dados, posteriormente neste documento.
Figura 26 mostra o fluxo de dados de processamento de fatos de inventário da loja. A pesquisa que compara alterados registros de fonte com registros de fato atual é realçada.
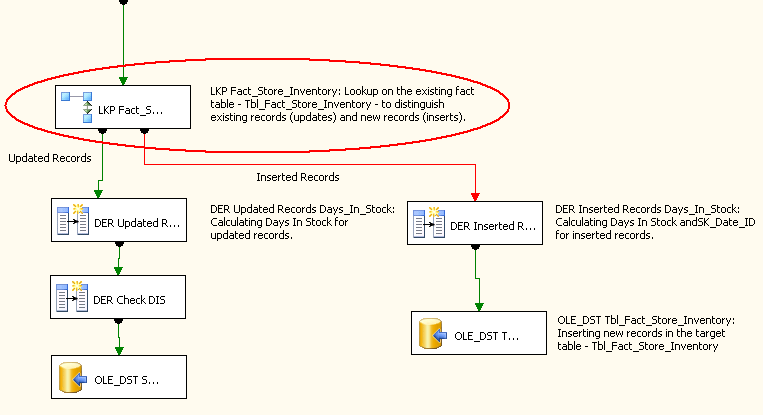
Figura26
Pesquisas de dimensão
Cada processo de tabela de fatos requer uma maneira de associar os fatos com o tabela de dimensões. Isto tem sido tratado através da placa usando a pesquisa de transformação que pode armazenar em cache a dimensão. Como as linhas de fonte fluem, ele rapidamente retorna as chaves substitutas necessárias para o tabela de fatos com base em associação de chave de negócios. Este processo é simples e particularmente eficaz para dimensões com um menor número de linha. Qualquer hora que uma dimensão tem alterações históricas de tipo-2 e, portanto, um identificador de linha atual, em seguida, o cache é filtrada para usar somente as linhas atuais, para que a mais recente versão do membro de dimensão é associado com o fato. Figura 27 mostra a guia de tabela de referência da pesquisa de transformação. Neste exemplo para a dimensão store, uma consulta é usado para filtrar o Current_Row.
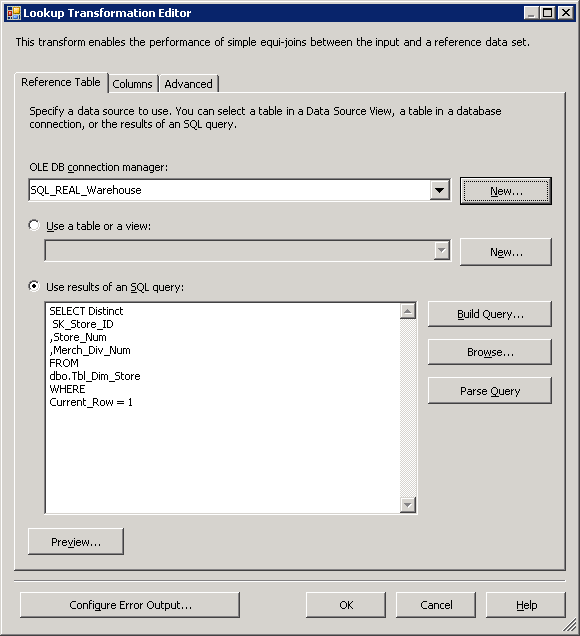
Figura27
A guia de colunas de pesquisa transformação é onde as fluxo de dados as colunas são mapeadas para as colunas tabela de referência . Uma vez que o objetivo da pesquisa de dimensão é obter o substituto chave da dimensão, o negócio chave é usado como um mapa (Store_Num), e o substituto chave é retornado (SK_Store_ID) junto com um secundário coluna que é usada a jusante no fluxo de dados.
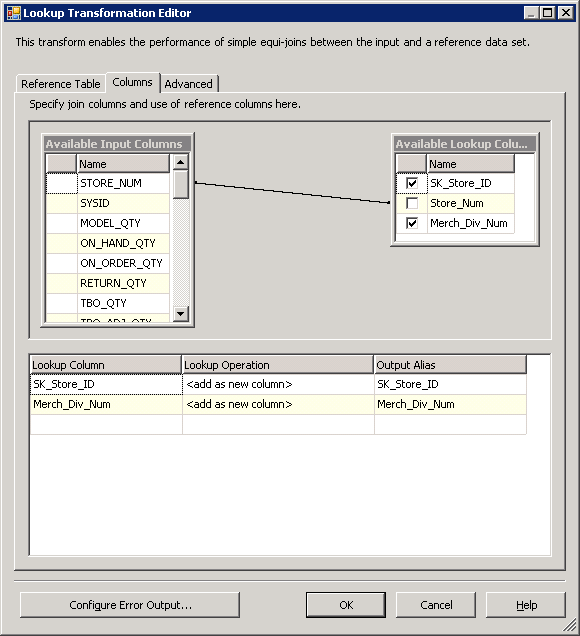
Figura28
De um ponto de vista de fluxo de dados de fonte linhas simplesmente ir de pesquisa para pesquisa, associando as linhas com os mais recentes chaves substitutas dimensão. O fluxo de dados na Figura 29 mostra as transformações de pesquisa descritas acima. Várias outras transformações são exibidas, incluindo um Script transformação e transformações Union All usadas para os membros inferidos, que são descritos em detalhes na próxima seção.

Figura29
Para a dimensão do item , que contém milhões de linhas, uma técnica de otimização tem sido empregada para limitar a pesquisa apenas para as linhas necessárias para a execução de qualquer que seja o processo de tabela de fatos . Para obter mais informações, consulte técnicas de otimização de processamento de dados, posteriormente neste documento.
Manipulação inferida membro adições
Uma vez que as dimensões reais do projeto exigirem que membros deduzidos ser criado quando um registro de dimensão não existe, temos mais trabalho a fazer. Como um lembrete, um inferido membro é um registro de dimensão que atua como um espaço reservado com apenas o valor de chave de negócios, de modo que quando o registro de dimensão completa está disponível, todas as colunas de dimensão são atualizadas com os novos valores que estão disponíveis. O processo de atualização ocorre durante o processamento da dimensão, mas a adição do membro inferido acontece durante o processo de fato quando a pesquisa de transformação não gera uma correspondência. Quando a pesquisa de transformação que manipula a pesquisa dim em cache para a chave não é possível localizar uma correspondência, a linha realmente falha. Para configurar a saída para a linha pode ser redirecionada através do tubo com falha, clique no botão Configurar saída de erro na interface do usuário de pesquisa e configurar a linha "redirecionamento". Ver Figura 30.
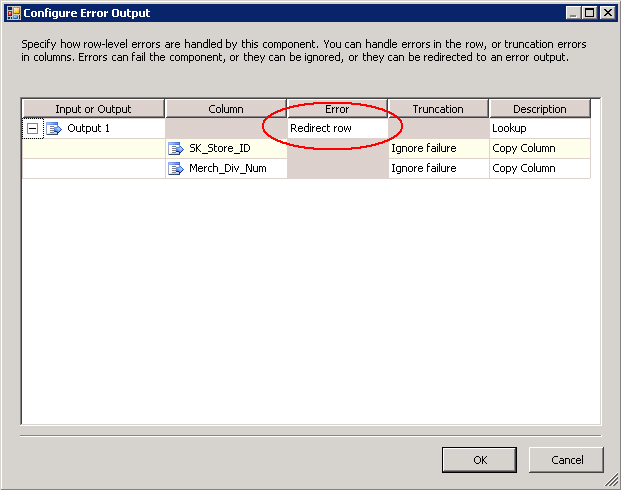
Figura30
Configurando a pesquisa primária transformação desta forma, as linhas não correspondentes são redirecionadas e membros deduzidos podem ser adicionados à dimensão por meios alternativos. Todas as chaves de dimensão de substituto no Project REAL são colunas de identidade, que torna esse processo mais difícil do que se as chaves foram identificadores exclusivos que podem ser gerados pelo SSIS. Várias abordagens foram consideradas para lidar com as adições de membro deduzido. Dado o volume de dados, os requisitos necessitava de uma maneira de manter o processo em execução ideal, mantendo o membro inferido adições no fluxo de dados primário. Para manter o processo simplificado e evitar vários fluxos de dados, o recém-gerado inferido chaves de membro necessárias para ser trazido de volta para o fluxo de dados antes da próxima pesquisa de dimensão. Outra consideração foi que desde que o cache de transformação de pesquisa primário é carregado antes da execução de fluxo de dados, quando um membro deduzido é adicionado ao banco de dados na primeira vez, ele não é adicionado ao cache com o resto dos registros de dimensão. Assim se há milhares de registros de fato entrar em toda para o mesmo negócio inigualável chave, todos os registros não será encontrado no cache e, portanto, serão enviados para a saída de erro para o processo de adição de membro deduzido.
Tendo em conta os requisitos acima, um Script transformação foi selecionado para identificador inferido Membros adições. Um Script transformação, diferente de uma tarefa de Script, é usada no fluxo de dados. Ele pode realizar manipulações baseada em script em linhas e colunas vem através do gasoduto. Em situações onde um único cenário exige tratamento especial, o Script transformação fornece valor na sua flexibilidade e personalização. O objetivo específico aqui foi tomar a saída de pesquisa inigualável, adicionar o membro inferido para o tabela de dimensões no banco de dados e receber de volta o substituto recém-gerado chave, tudo isso sem fazer várias chamadas para o banco de dados para o mesmo negócio inigualável chave. Antes de desenvolver o Visual Basic ®.Script de líquido, uma estrutura de tópicos do código foi juntos que fornece uma visão geral do processo de transformação de Script:
- São passos iniciais, executados antes que o primeiro registro é processado:
- Declare variáveis.
- Crie um hash tabela a ser usada para o negócio chave(s) e pesquisa de chave saída substituto para otimização.
- Para cada linha que vem através do pipeline de transformação de Script, verifique a tabela de hash para a existência de negócios atual chave. Então:
- Se o negócio chave existe, retorne o substituto chave para a saída da pipeline.
- Se o negócio chave não existir:
- Conecte ao banco de dados.
- Execute o procedimento armazenado que cria o membro deduzido e retorna o substituto chave.
- Adicione o negócio chave e novo substituto chave para a tabelade hash.
- Retorne o substituto chave para a saída da pipeline.
- Etapas de limpeza e desalocação seguem a última linha da tubulação de entrada.
O seguinte Script transformação é um processo de membro exemplo inferido para a pesquisa de loja, usado quando o Store_Num não tem um registro correspondente na pesquisa.
' Componente de script de usuário do Microsoft Data Transformation Services ' Este é o novo componente de script no Microsoft Visual Basic.NET ' ScriptMain é a classe de entrypoint para componentes de Script do DTS
As importações sistema As importações System. Data As importações System. Collections As importações Microsoft.SqlServer.Dts.Pipeline.Wrapper ___________________________________
Público classe ScriptMain Herda UserComponent Privado htBusinessID como nova Hashtable Privado objConnection como nova SqlClient.SqlConnection Privado objCommand como nova SqlClient.SqlCommand Privado boolInit como Boolean = False Privado strProcedureName como Cadeia de caracteres = "config.up_ETL_DimStore_CreateInferredMember" Privado strBusinessID como Cadeia de caracteres = "@ pnStore_Num" Privado strSurrogateID como Cadeia de caracteres = "@ pnSK_Store_ID" Privado strETLLoadID como Cadeia de caracteres = "@ pnETL_Load_ID" Privado strReturnValue como Cadeia de caracteres = "@ RETURN_VALUE" ___________________________________
Público substitui Sub Input0_ProcessInputRow (ByVal linha como Input0Buffer) Se (boolInit = False) , em seguida, Me.Connect) Se não (htBusinessID.Contains(Row.InBusinessID)) , em seguida, Dim strSurrogateKey como Cadeia de caracteres = Me.Executar (Row.INBusinessID, Row.ETLLoadID) htBusinessID.Add (Row.InBusinessID, strSurrogateKey) Final se Me.ProcessRow(Row) Final Sub Público Sub ProcessRow (ByVal linha como Input0Buffer) Row.OutSurrogateID = System.Convert.ToInt16(htBusinessID.Item(row.INBusinessID).System Final Sub Privado função executar (ByVal BusinessId como Decimal, ByVal ETLLoadID como inteiro, ByVal) Como String Me.objCommand.Parameters(strBusinessID).Valor = System.Convert.ToString(BusinessId) Me.objCommand.Parameters(strETLLoadID).Valor = System.Convert.ToString(ETLLoadID) Me.objCommand.ExecuteNonQuery()
Executar = System.Convert.ToDecimal (Me.objCommand.Parameters(strSurrogateID).Valor).ToString) Final função ___________________________________
Privado Sub Connect) Se boolInit = False , em seguida, Dim strConnection como Cadeia de caracteres = Connections.SQLRealWarehouse.ConnectionString Dim x como inteiro = strConnection.ToUpper().IndexOf("PROVIDER") Se x > = 0 , em seguida, Dim y como inteiro = strConnection.IndexOf (";", x + 1) Se (y > = 1) , em seguida, strConnection = strConnection.Remove (x, y - x + 1) Final se
Me. objConnection.ConnectionString = strConnection Me.objConnection.Open() Me. objCommand.Connection = Me.objConnection Me. objCommand.CommandType = CommandType. StoredProcedure Me. objCommand.CommandText = Me.strProcedureName
Dim Parm como nova SqlClient.SqlParameter (strBusinessID, SqlDbType.Decimal) Parm.Direction = ParameterDirection.Input objCommand.Parameters.Add(Parm)
Parm = nova SqlClient.SqlParameter (strETLLoadID, SqlDbType) Parm.Direction = ParameterDirection.Input objCommand.Parameters.Add(Parm)
Parm = nova SqlClient.SqlParameter (strSurrogateID, SqlDbType) Parm.Direction = ParameterDirection.InputOutput Parm.Value = 0 objCommand.Parameters.Add(Parm)
Parm = nova SqlClient.SqlParameter (strReturnValue, SqlDbType) Parm.Direction = ParameterDirection.ReturnValue objCommand.Parameters.Add(Parm)
Me.boolInit = verdadeiro Final se Final Sub ___________________________________
Privado Sub Close) Se boolInit = True , em seguida, saída Sub Me.objCommand.Dispose() Me.objConnection.Close() Me.objConnection.Dispose() Me.htBusinessID = nada MyBase.Finalize() Final Sub Final classe
|
O procedimento é executado pela transformação Script verifica a dimensão para a existência de negócios chave e insere um novo registro (o membro deduzido) se o registro não existe. Em seguida, retorna a identidade recém-adicionado coluna para o script para que ele pode ser usado a jusante no fluxo de dados.
Depois de deduzidos os scripts transformação, os registros são mesclados voltar para o pipeline primário usando a transformaçãoUnion All. Em seguida, estão disponíveis para a próxima pesquisa de dimensão. A Figura 31 mostra uma série de pesquisas, de que seus associados inferido pesquisas de membro e os sindicatos necessários para reunir os resultados .
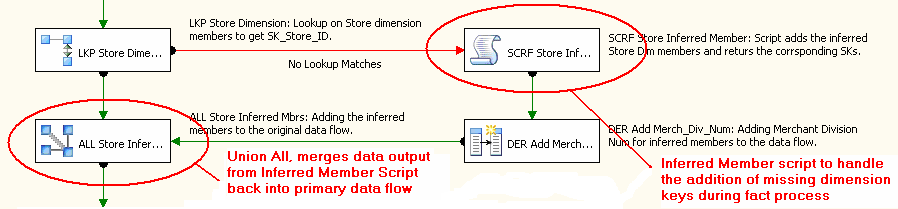
Figura31
Otimização do processamento de dados técnicas
Por meio de fora o processo de desenvolvimento de projeto REAL, otimização algumas técnicas têm sido identificados que ajuda a agilizar a ETL. Estas envolvem princípios baseados sobre as vantagens da arquitetura do produto, as configurações no SSIS e ajuste para lidar com grandes volumes de fluxo de dados. Algumas das otimizações incluem:
- Usar o alto valor alvo de preparo para pesquisas de filtro e dados de fontes de mesclagem de dados.
- Limitar o uso de transformação de fluxo de dados completo conjunto de linhas (bloquear) como agregações e classificação.
- Manipulação de cenários comuns de processamento de dados antes a exceção.
- Considerando atualizações lote para a dimensão de grande volume ou tabela de fatos atualização.
Alto valor alvo preparo
A pesquisa totalmente em cache transformação correlaciona dados entre fontes, como associar chaves de dimensão tabela de fatos registros. De grandes dimensões, no entanto, carregar toda a dimensão para o cache de memória de pesquisa vai levar um longo tempo e usar memória RAM que poderia estar disponível para outros processos. Para o Project REAL, nós criamos um alvo de preparação tabela para as chaves de negócios da dimensão do grande item , que contém 6-7 milhões de membros. Este preparo estreitas tabela é preenchida em pacotes tabela de fatos usando um fluxo de dados que contém uma única fonte e destino e só extrai o produto negócios chave de transacional fonte e terras para uma tabelade preparação. Figura 32 mostra a conclusão bem-sucedida das chaves de negócios de 4,4 milhões de preparo em 55 segundos. Desde então destina-se a extração e estreitas, este fluxo de dados é capaz de terminar em questão de segundos para várias linhas milhões.
Figura32
As etapas chaves, em seguida, são usadas para filtrar a consulta que a pesquisa usa para carregar seu cache. Uma vez que as chaves de negócio em uma dimensão já estão cadastradas, a associação para limitar os registros da dimensão executa muito bem. Para este exemplo, esta técnica filtra o cache de pesquisa de dimensão para baixo para quase 1/10 do tamanho da dimensão completa, mas ainda que contém todos os membros da dimensão necessários para a pesquisa durante o fato de processamento desde o mesmo conjunto de chaves de negócio são usados para a pesquisa. O seguinte código SQL é usado para preencher o cache de pesquisa e envolve a filtragem a dimensão (Tbl_Dim_Item) com as chaves de negócios contidas do preparo tabela (tbl_DWS_ETL_Store_Inventory_Log).
Selecione distintas ITEM de.SK_Item_ID , ITEM.SysID , ITEM.SK_Parent_Item_ID , ITEM.Retail_Amt DE dbo.Tbl_Dim_Item como ITEM INTERIOR se juntar config.tbl_DWS_ETL_Store_Inventory_Log_Keys como INV_LOG ON ITEM.SysID = INV_LOG.SysID E ITEM.Current_Row = 1 |
Esta abordagem também pode ser empregada para limitar os registros de fonte usados em um Merge Join transformação. Junções de mesclagem são usadas em vários cenários de maneira semelhante como a pesquisa, para associar dados de fonte e destino juntos. Quando a chamada de requisitos para comparar várias dezenas colunas entre a fonte e o armazém, uma pesquisa de transformação pode não ser capaz de lidar com o tamanho do cache de pesquisa como cada coluna de cada linha precisará ser armazenado na memória. Uma abordagem alternativa é usar um Merge Join transformação para reunir os dados de fonte e armazém. O Merge Join não tem a sobrecarga de memória, mas pode também aproveitar um armazém filtrado de fonte quando as chaves de negócio são encenadas, conforme descrito anteriormente.
Limitar as transformações de classificação e agregação de fluxo de dados
Embora limitar as transformações de classificação e agregação beneficiará desempenho (uma vez que realizar-se todas as linhas no pipeline e consomem tempo e recursos), há momentos quando eles são necessários ou necessário. Por exemplo, o Merge Join, que é usado em vários pacotes Project REAL, exige que as fontes de ser classificado por coluna(s) que definem a junção. Usar uma classificação transformação para ambas as fontes exige que todas as linhas em ambos os lados da mesclagem ser realizada na classificação de transformação antes de serem lançados para o Merge Join. Pequenos conjuntos de dados não pode ser afetados por isso, mas mais volumes consideráveis causam alguns efeitos. Em primeiro lugar, os registros sendo carregados em tipos (ou agregação em outros exemplos) são armazenados na memória. Como limites são atingidos, porções do cache podem ser temporariamente carregadas fora no disco pela classificação transformação ou através do Gerenciador de memória virtual, assim criando ineficiências em I/O e usando os recursos de memória que podem precisar de outras transformações downstream para processamento. Quando transformações usadas no fluxo de dados faz com que dados a ser realizada, o efeito volta coloca pressão sobre os dados upstream no pipeline, que se isso filtra volta para as conexões de fonte , vai abrandar a extração e, por conseguinte, a global tempo de processamento.
Isto não implica que nós completamente evitadas usando as transformações de classificação ou agregação. Em geral, eles operam incrivelmente rápido e são úteis para muitas situações. Sim, este é um cuidado para cenários de alto volume ou disponibilidade de recurso de memória limitada.
Para este exemplo Merge Join, a transformação de classificação pode ser eliminados se o fonte dados podem ser pré-classificada. Em todos os cenários do Project REAL, isso tem funcionado bastante bem. Uma vez que um processo ETL normalmente usaria um Merge Join para associação de dados através de chaves de negócio para dimensões ou chaves substitutas para fatos, a classificação pode adiada para a conexão com a fonte consulta. Classificação em um mecanismo relacional pode exigir muita sobrecarga, a menos que exista o índice certo ou combinação de índices. Desde que negócios e chaves substitutas são fortes candidatas a índices, adicionando um ORDER BY cláusula àconsulta SQLpode ser valiosa e eficiente. Para fazer isso, as necessidades de fluxo de dados para tomar conhecimento de que a fonte é classificado e as colunas e direção a que se aplica a classificação. Isso é feito no Editor Avançado da ligação de origem. Na guia Propriedades de entrada e saída, examinar as propriedades do mais alto nível da OLE BD origem saída— há uma propriedade chamada IsSorted, que deve ser conjunto como True. Em segundo lugar, as colunas que são classificadas devem ser especificadas através da SortKeyPosition propriedade do contêiner de colunas de saída como mostrado na Figura 33. Em seguida, o fluxo de dados irá reconhecer a classificação.
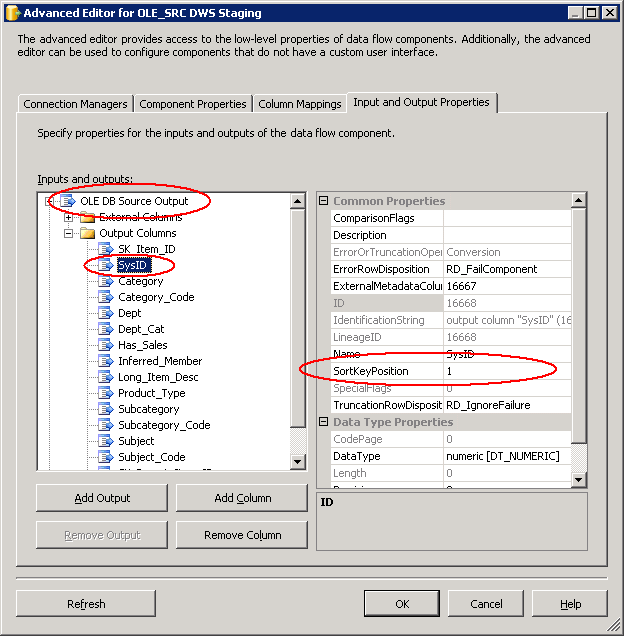
Figura33
Em outras situações onde os requisitos de classificação ou agregação envolvem apenas um subconjunto dos dados de fluxo de dados, outra sugestão de otimização é ramificar os dados (usando uma transformaçãode Multicast), em seguida, filtro as linhas se necessário (usando uma transformaçãode divisão condicional) e, em seguida, especificar o subconjunto de colunas necessárias para o processamento de dados (dentro da classificação ou agregação) de saída.
Manipulação de cenários comuns antes a exceção
Com a ramificação, mesclagem, filtragem e União recursos no pipeline, existem maneiras de otimizar o processamento por lidar com cenários exclusivos separadamente. Isso pode ser realizado quando uma operação pode ser realizada noventa mais por cento do tempo usando um processo simplificado de como a pesquisa em cache ou em massa de destino, mas a exceção de dez por cento restantes requer limitar o processo por um menos eficiente método.
O OLE BD comando transformação vs. atualizaçõeslote
Grande volume de atualizações podem ser o calcanhar de Aquiles de um processo ETL. Alguns sistemas de evitar tabela de fatos atualiza completamente para evitar o custo geral do processo. Criar tabela de fatos alterar registros para compensar diferenças de medida traz seu próprio conjunto de desafios em comunicação e processamento. O inventário diário de processamento para o Project REAL modelos nesta situação. O inventário instantâneo tabela de fatos tem um grão downloads com quase 200 milhões de registros armazenados por semana. Além disso, pode haver alterações de 10 milhões para os dados de inventário atual em uma base diária. Adicione isso juntos e magias gargalo.
Os dois métodos principais para lidar com um processo de atualização deste tamanho são:
- Use o OLE BD comando transformação com um com parâmetros de consulta.
- Por terra os registros de mudança para uma tabela de preparo e executar um conjunto-com base em atualização RDBMS.
Para o primeiro método, o SSIS contém uma transformação que pode interagir com o banco de dados diretamente para lidar com várias operações, a mais comum sendo uma instrução update. O OLE BD comando transformação usa uma instrução SQL que é parametrizada com mapeamentos para colunas de fluxo de dados. Como linhas são passadas para a transformação, a operação é executada com os dados fornecidos nas linhas. Uma vez que a operação é executada uma linha por vez, ele tem uma série de limitações quando usado para processar uma grande série de atualizações. Quando milhões de linhas são direcionados por essa transformação para executar atualizações este resultados em graves inconvenientes, tais como o impacto sobre o banco de dados relacional, o pressão de retorno que ele coloca sobre o fluxo de dados e o tempo necessário para concluir o processamento.
A segunda abordagem envolve os dados de teste e usando o mecanismo relacional para lidar com a atualização associando a encenado tabela com atabela de destinoem uma instrução update. Isso envolverá a fortemente aproveitando de um ambiente de preparo, mas devido ao custo, pode haver ganhos globais em prosseguir esta abordagem como uma alternativa para o primeiro método. Desvantagens nessa abordagem são os custos de recurso de usar um ambiente de preparo e o impacto sobre o banco de dados do armazém durante o processo de atualização, que pode envolver tanto salientando de recursos do sistema e tabela, página ou bloqueio de linha.
As vantagens da abordagem este último só são evidentes quando comparado com a alternativa. Pelos dados necessários para a atualização de preparo, o gasoduto irá realizar muito melhor, desde que o destino transformação pode ser otimizado. Além disso, a duração total de impacto para atabela de destinodeve ser reduzida, porque um conjunto-operação com base pode ser tratado com mais eficiência por SQL do que as alternativas atualizações de linha por linha. A atualização também se beneficiarão de indexação otimizado e potencialmente manipulação as atualizações em uma série de processos lote menores.
Conclusão
A lógica de negócios encapsulada no núcleo SSIS controle e componentes de fluxo de dados, representa as operações de ETL fundamentais que apoiam os objectivos de visão geral do Project REAL — informações disponíveis, organizadas e precisas para análise. Além de processos de negócios de dados, uma solução ETL requer mecanismos que oferecem suporte os métodos de administração e desenvolvimento, que também foram incorporados no Project REAL solução. Em geral, SSIS forneceu os recursos para atender estes pré-requisitos — dados e operacionais — com o desempenho, a facilidade de desenvolvimento, e precisa de flexibilidade que são essenciais para o complexo de hoje.
Reconhecimento e agradecimentos são devido à Barnes & Nobre, Intellinet e Microsoft Consulting equipes para dirigir a solução "real" para o sucesso, e também para o Microsoft SSIS equipe de desenvolvimento para sua inestimável ajuda no fornecimento de consulta de design e suporte durante o ciclo de vida do beta do SQL Server 2005. As lições contidas neste documento foram adquiridas não só por causa do tempo e esforço durante o Project REAL, mas também por causa das horas passadas no teste de desempenho, avaliações de design, ensaios e erros, e coleta e planejamento do projeto requisitos que passou na Barnes & Nobre. Esta base tem permitido o Project REAL esforço concentrar-se tendo o núcleo ETL e otimização, adaptação e reforço a ser um forte modelo ETL para o SQL Server 2005 plataforma.
Para obter mais informações:
http://www.Microsoft.com/SQL/! href (http://www.microsoft.com/sql/)
Este livro ajudá-lo? Por favor, dê-nos seus comentários. Em uma escala de 1 (pobres) a 5 (excelente), como você classificaria este documento?! href (mailto: sqlfback@microsoft.com?subject=Feedback:papel título)
Inserir o título do livro depois de "Feedback:"