Deduplicação de dados – Windows Server 2012 R2
Deduplicação de dados foi inserido no Windows Server 2012 com o princípio de otimizar e economia de espaço em disco. Não é uma técnica nova, mas que agora pode também ser aplicada diretamente pelo Sistema Operacional, sem necessitar de software específico de Storage como da Dell, IBM ou muitos outros.
Não irei aprofundar sobre os recursos e o que a Role de deduplicação não fornece. Mas como principais opções de economia de espaço podemos descrever:
Compartilhamento de arquivos gerais - implantação de software, bibliotecas VHD - Documentos de usuários e ambiente VDI.
Podemos citar um cenário que poderá vir em versões futuras para 2015 ou até antes quem sabe. Você utilizar a deduplicação para diminuir backup de VMs com SCDPM. Imaginando ter 100 VMs para suportar Sites IIS e aplicações online. Todos esses servidores virtuais com objetivo de manter o site no ar, gera um espaço gigantesco em storage, sendo que as VMs podem ser idênticas, e com a deduplicação imaginado 20gb por VM = 2TB podendo se tornar apenas 100gb 200gb num total de 85 a 95% de otimização e economia de disco.
Irei mostrar na prática o recurso que é muito fácil de utilizar, mas precisa planejar o que será otimizado, pois pode ocorrer problemas em alguns casos. Tenha sempre backup antes de qualquer teste.
Primeiro iremos em Server Manager para adicionar a Role, abrimos a opção File And Storage Services -> File and iSCSI Services e ticamos a opção Data Deduplication, apenas avançamos e não será necessário reiniciar o servidor.
http://andrenovello.files.wordpress.com/2013/10/11.jpg
{kind=link}
Iremos agora no Dashboard do File Server e em Volumes verificamos que tem duas abas chamadas Deduplication Rate que é a taxa de otimização que foi feita e Deduplication Savings que é a quantidade em MB, GB, TB ou quem sabe PB de dados com esse crescimento desenfreado de dados na rede.
http://andrenovello.files.wordpress.com/2013/10/24.jpg
{kind=link}
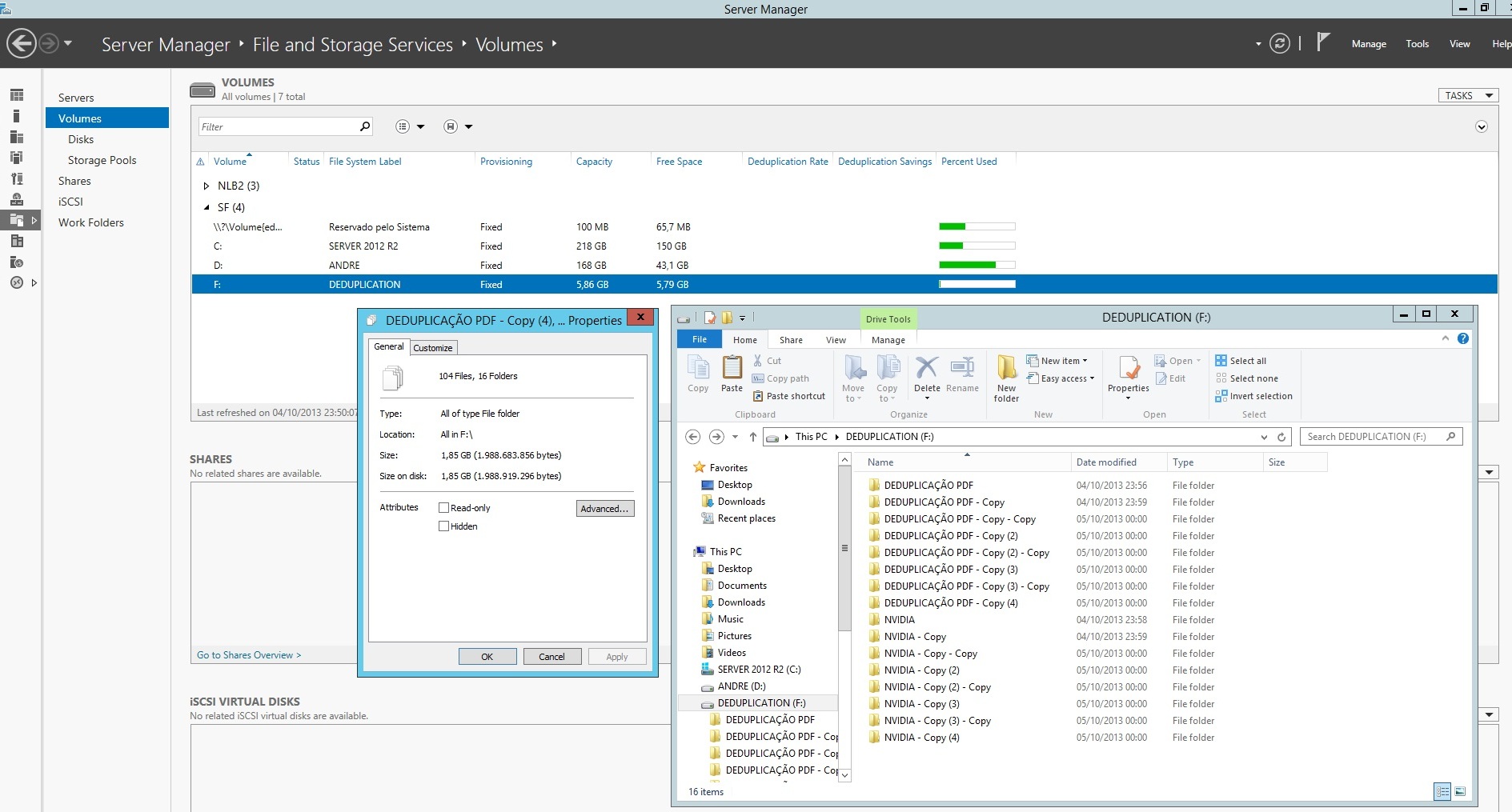
Criei algumas pastas na unidade F: Deduplication com 6gb de espaço do meu servidor para fazer os testes referente a deduplicação. Coloquei a pasta com Nome Deduplicação PDF e NVIDIA. O espaço ocupado pelas duas pastas com os mesmos tipos de dados é de 237 MB, e fiz algumas cópias com total de 1,85GB lembrando que não é possível fazer deduplicação com partição em formato ReFS e nem em partição C que tem imagem de sistema. Como podemos ver na imagem nada foi aplicado ainda.
http://andrenovello.files.wordpress.com/2013/10/32.jpg
{kind=link}
Agora vamos adicionar a deduplicação de dados clicando com botão direito em cima da partição e selecionando Configure Data Deduplication.
http://andrenovello.files.wordpress.com/2013/10/42.jpg
{kind=link}
Na próxima imagem selecionamos General Purposes file Server para deduplicação de arquivos gerais. Também podemos selecionar um horário para a função, e podemos excluir arquivos que não serão incluídos por extensão como .wmv, .mp3, .jpg, ou também exclusão de pastas inteiras. Irei apenas deixar selecionado Enable background Optimization. Isso significa que ele já irá durante o dia fazer a deduplicação ao invés de agendar para horários fora do expediente. Podemos selecionar se a função será feita para arquivos gerais ou para ambiente VDI, nesse caso coloquei para arquivos do dia a dia. E também para funcionar corretamente nosso teste, em Deduplicate Files Older Than (in days), eu coloquei zero pois padrão vem 3, e mesmo que forçasse a deduplicação, ele não irá completar pois ele não encontra arquivos com mais de 3 dias, caso você criou ele no momento para os testes.
http://andrenovello.files.wordpress.com/2013/10/52.jpg
{kind=link}
Conseguimos fazer também a deduplicação por Powershell com apenas um comando fácil e também verificar o status da otimização. Sendo eles:
Start-DedupJob -Volume f: -Type Optimization -Verbose
Get-DedupStatus
http://andrenovello.files.wordpress.com/2013/10/6.jpg
{kind=link}
Podemos ver que a ferramenta é simples de configurar e eficiente. Economizamos 79% do espaço e um total de 1,62gb, e 104 arquivos otimizados. Ambientes com Terabytes ou PT de informações em datacenter com hospedagem de arquivos pode se beneficiar dessa função. Para o youtube que tem muitos vídeos parecidos isso será de grande valia, pois irá economizar Petabytes de dados caso um dia seja possível relacionar os bits de um vídeo com outros.
Caso queiram mais informações sobre deduplicação, deixo o link para o technet: http://technet.microsoft.com/pt-br/library/hh831700.aspx