Introdução à desduplicação de dados no Windows Server 2012
Este artigo foi traduzido do Blog do Technet americana focado na novidade de deduplicação do Windows Server 2012, é o resultado de uma extensa colaboração com a Microsoft Research e depois de dois anos de desenvolvimento e testes agora temos estado-da-arte da deduplicação que usa variável chunking e compressão e pode ser aplicado a seus dados primários. O recurso é projetado para hardware padrão da indústria e pode ser executado em um servidor muito pequena com apenas uma única CPU, uma unidade SATA e 4GB de memória. Desduplicação de dados irá escalar bem como adicionar múltiplos núcleos e memória adicional. Esta equipa tem algumas das pessoas mais inteligentes com quem trabalhei na Microsoft e estamos todos muito animado sobre este lançamento.
Não importa desduplicação?
Unidades de disco rígido estão ficando maiores e mais barato a cada ano, por que eu precisaria de deduplicação? Bem, o problema é o crescimento. Crescimento em dados está explodindo tanto que os departamentos de TI em toda parte terá alguns desafios sérios atender a demanda. Confira a tabela abaixo, onde IDC previu que estamos começando a experimentar um crescimento de armazenamento em massa. Você consegue imaginar um mundo que consome 90 milhões de terabytes em um ano? Estamos a cerca de 18 meses de distância!
https://lh5.googleusercontent.com/-ETkpDBCTCFU/ULJhJ6EzCtI/AAAAAAAAAF4/_eNG4Qe-B9A/s416/1.png
{kind=link}
Fonte: IDC armazenamento baseado em arquivo Mundial 2011-2015 Previsão:
Soluções da Fundação para a entrega de conteúdo, arquivamento e Big Data, Doc # 231910, December 2011
Bem-vindo ao Windows Server 2012!
Esta funcionalidade de desduplicação de dados é nova uma nova abordagem. Nós apenas apresentou um estudo de larga escala e Projeto de Sistemas de papel em desduplicação de dados primário para USENIX a ser discutido na Conferência Anual próxima Técnico em junho.
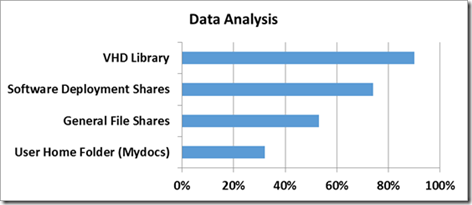
Tamanhos Típicos:
Analisamos muitos terabytes de dados reais dentro da Microsoft para obter estimativas das economias que você deve esperar se você ligado desduplicação para diferentes tipos de dados. Estamos focados em cenários de implantação do núcleo que nós apoiamos, incluindo bibliotecas, ações de implantação, compartilhamentos de arquivos e usuário / grupo partes. A tabela de Análise de Dados abaixo mostra as economias típicas fomos capazes de obter a partir de cada tipo:
https://lh4.googleusercontent.com/-984hzL_8las/ULJhJ7ESM9I/AAAAAAAAAF0/89KhTRvoD0A/s472/2.png
{kind=link}
Microsoft IT foi a implantação do Windows Server com desduplicação para o ano passado e eles relataram alguns números de espaços reais. Estes números validar que nossa análise de dados típicos é bastante precisa. Na tabela implantações vivem abaixo temos três cargas de trabalho de servidores muito populares na Microsoft, incluindo:
- Uma compilação servidor de laboratório: Esses são servidores que constroem uma nova versão do Windows a cada dia para que possamos testá-lo. Os símbolos de depuração que coleta permite que os desenvolvedores para investigar a linha exata do código que corresponde ao código de máquina que um sistema está em execução. Há um monte de duplicatas criado, uma vez que apenas mudar uma pequena quantidade de código em um determinado dia. Quando as equipes de liberar o mesmo grupo de arquivos em uma pasta nova a cada dia, há uma série de semelhanças a cada dia.
- Partes de lançamento de produtos: Existem servidores internos da Microsoft que detêm todos os produtos que já expedidos, em todas as línguas. Como você poderia esperar, quando você cortá-lo, 70% dos dados é redundante e pode ser destilado para baixo bem.
- Ações do grupo: Grupo incluem partes de compartilhamentos de arquivos regulares que uma equipe pode usar para armazenar dados e inclui ambientes que utilizam o redirecionamento de pasta , de forma transparente redirecionar o caminho de uma pasta (como uma pasta de documentos) para uma localização central.
https://lh6.googleusercontent.com/-GaPIpFTnJVY/ULJhKiilyZI/AAAAAAAAAGA/jhCSao4DLvg/s477/3.png
{kind=link}
Abaixo está uma imagem de interface ‘Volumes “o Server Manager nova de um dos servidores de construção de laboratório, observe a quantidade de dados que estamos economizando esses volumes 2TB. O laboratório estáeconomizando mais de 6 TB em cada um desses volumes 2TB e eles ainda tem cerca de 400GB livre em cada unidade.Estes são alguns números muito divertido.
https://lh3.googleusercontent.com/-1myIuT_F_IY/ULJhKgqePlI/AAAAAAAAAGE/olTdDL38eeg/s733/4.jpg
{kind=link}
Há um claro retorno sobre o investimento que pode ser medido em dólares pelo uso da desduplicação. A economia de espaço são dramáticas e os dólares-salvo pode ser calculada muito facilmente quando você paga pelo gigabyte. Eu tive muitas pessoas dizem que querem Windows Server 2012 apenas para esta função. Que poderia permitir-lhes adiar a compra de novas matrizes de armazenamento.
Características de desduplicação de dados:
1) Transparente e fácil de usar: desduplicação pode ser facilmente instalado e ativado em volumes de dados selecionados em poucos segundos. Aplicativos e usuários finais não sabem que os dados foram transformados no disco e quando um usuário solicita um arquivo, ele será transparente servido imediatamente. O sistema de arquivos como um todo apóia todas as semântica NTFS que você esperaria. Alguns arquivos não são processados pela deduplicação, como arquivos criptografados usando o sistema de arquivos criptografados (EFS), os arquivos que são menores de 32 KB ou aqueles que estenderam Atributos (EAS). Nestes casos, a interação com os arquivos é inteiramente através de NTFS e do driver de filtro de desduplicação não se envolver. Se um ficheiro tem um fluxo de dados alternativo, apenas o fluxo de dados primário serão desduplicados eo fluxo alternativo será deixado no disco.
2) Projetado para Dados Primários: O recurso pode ser instalado em seus volumes de dados primários, sem interferir com o principal objectivo do servidor. Dados quentes (arquivos que estão sendo gravados em) será percorrido por desduplicação até que o arquivo chega a uma certa idade. Desta forma, você pode obter um desempenho ideal para arquivos ativos e uma grande economia no resto dos arquivos. Arquivos que atendem aos critérios de desduplicação são referidos como “em matéria de política de” arquivos.
um. Pós-Processamento : Desduplicação não está no caminho de gravação quando novos arquivos vir.Novos arquivos escrever diretamente para o volume NTFS e os arquivos são avaliados por um Pesquisador de arquivos em uma programação regular. O modo de processamento em segundo plano verifica a existência de arquivos que são elegíveis para deduplicação horas cada e você pode adicionar as listas adicionais, se você precisar deles.
b. Idade arquivo: desduplicação tem uma configuração chamada MinimumFileAgeDays que controla quantos anos um arquivo deve ser antes de processar o arquivo. A configuração padrão é de 5 dias. Esta definição é configurável pelo usuário e pode ser definido como “0″ para processar arquivos independentemente de como eles são velhos.
c. Tipo de Arquivo e exclusões Localização de arquivo: Você pode dizer que o sistema não processar arquivos de um tipo específico, como arquivos PNG que já têm grande compressão de arquivos CAB ou comprimidos que não podem beneficiar de desduplicação. Você também pode dizer que o sistema não processar uma determinada pasta.
3) Portabilidade: Um volume que está sob controle de desduplicação é uma unidade atômica. Você pode fazer backup do volume e restaurá-lo para outro servidor. Você pode rasgá-lo fora de um servidor Windows 2012 e movê-lo para outro. Tudo o que é necessário para acessar seus dados está localizado na unidade. Todas as configurações de desduplicação são mantidas no volume e será apanhado pelo filtro desduplicação quando o volume está montado. A única coisa que não é mantida no volume são as configurações de programação que fazem parte do mecanismo de tarefas-scheduler. Se você mover o volume para um servidor que não está executando o recurso de deduplicação de dados, você só será capaz de acessar os arquivos que não foram desduplicados.
4) Com foco no uso de recursos baixos: O recurso foi construída para produzir automaticamente os recursos do sistema de carga de trabalho do servidor primário e de back-off até que os recursos estão disponíveis novamente. A maioria das pessoas concorda que seus servidores têm um trabalho a fazer e do armazenamento é apenas facilitar as suas necessidades de dados.
um. Índice hash o pedaço é projetado para usar recursos de baixa e reduzir a leitura / gravação do disco IOPS para que ele possa escalar para grandes conjuntos de dados e entregar inserção alta / pesquisa desempenho. A pegada índice é extremamente baixo, de cerca de 6 bytes de RAM por pedaço e ele usa particionamento temporária para apoiar escala muito alta
c. Desduplicação vai verificar que não há memória suficiente para fazer o trabalho e, se não ele vai parar e tentar novamente no próximo intervalo programado.
d. Os administradores podem programar e executar qualquer um dos trabalhos de desduplicação durante horários fora de pico ou durante o tempo ocioso.
5) chunking Sub-arquivo : arquivos de desduplicação de segmentos em variável-tamanhos (32-128 pedaços kilobyte) usando um novo algoritmo desenvolvido em conjunto com a pesquisa da Microsoft. O módulo de segmentação divide um arquivo em uma seqüência de pedaços de uma forma dependente do conteúdo. O sistema utiliza uma Rabin impressão digital baseada em hash de janela deslizante sobre o fluxo de dados para identificar os limites do pedaço. Os pedaços têm um tamanho médio de 64 KB e eles são compactados e colocados em uma loja pedaço localizado em uma pasta oculta na raiz do volume chamado System Volume Information, ou “pasta SVI”. O arquivo normal é substituído por um pequeno ponto de nova análise , que tem um ponteiro para um mapa de todos os fluxos de dados e pedaços necessários para “hidratar” o arquivo e servi-lo quando for solicitado.
Imagine que você tem um arquivo que se parece com isto em NTFS:
https://lh4.googleusercontent.com/-CxoTIYbh1lw/ULJhLqqzhaI/AAAAAAAAAGQ/5zYTuGqyHVQ/s299/5.jpg
{kind=link}
E você também tem outro arquivo que tem alguns dos mesmos pedaços:
https://lh6.googleusercontent.com/-ZulYE6v-jIo/ULJhLtuB5bI/AAAAAAAAAGM/WzTQvXfIIm8/s298/6.jpg
{kind=link}
Após ser processado, os arquivos são agora pontos de nova análise com metadados e links que apontam para onde o arquivo de dados está localizado no bloco da loja.
https://lh5.googleusercontent.com/-Lf1UXo_DTMc/ULJhLx03cUI/AAAAAAAAAGU/3VDH3BB58-k/s391/7.png
{kind=link}
6) O BranchCache ™ : Outro benefício para o Windows é que o arquivo de sub-chunking e mecanismo de indexação é compartilhada com o recurso BranchCache . Quando um servidor Windows no escritório de casa está funcionando desduplicação os blocos de dados já estão indexados e está pronto para ser rapidamente enviados pela WAN, se necessário. Isso economiza uma tonelada de tráfego WAN para uma filial.
Qual o impacto acesso a dados?
Desduplicação cria fragmentação para os arquivos que estão no seu disco como pedaços pode acabar sendo afastados e isso faz com aumentos de tempo de busca como as cabeças do disco deve se mover mais para reunir todos os dados necessários. Como cada arquivo é processado, o driver de filtro trabalha para manter a seqüência de pedaços únicos juntos, preservando em disco local, por isso não é uma distribuição completamente aleatória. A desduplicação também tem um cache para evitar ir para o disco para pedaços de repetição. O sistema de arquivos tem uma outra camada de cache que é aproveitado para acesso a arquivos. Se vários usuários estão acessando arquivos semelhantes, ao mesmo tempo, o padrão de acesso permitirá desduplicação para acelerar as coisas para todos os usuários.
- Não há diferenças notáveis para abrir um documento do Office. Os usuários nunca vai saber que o volume subjacente esteja em execução desduplicação.
- Ao copiar um único arquivo grande, vemos momentos de ponta a ponta-cópia que pode ser 1,5 vezes o que é preciso em um volume não desduplicados.
- Ao copiar vários arquivos grandes ao mesmo tempo temos visto ganhos devido ao cache que pode fazer com que o tempo de cópia a ser mais rápido em até 30%.
- Sob o nosso simulador de carga de servidor de arquivos (o arquivo Ferramenta capacidade de servidor ) definido para simular 5.000 usuários acessando simultaneamente o sistema só vemos uma redução de 10% no número de usuários que podem ser suportados sobre SMB 3,0 .
- Os dados podem ser otimizados a 20-35 MB / s em um único trabalho, que sai para cerca de 100GB/hour para um único volume 2TB usando um núcleo único CPU e 1GB de RAM livre. Vários volumes podem ser processados em paralelo, se os recursos da CPU adicional de memória, e estão disponíveis no disco.
Atenuações de confiabilidade e risco
Mesmo com RAID e redundância implementado em seu sistema, existem riscos de corrupção de dados devido a anomalias de disco vários erros do controlador, bugs de firmware ou mesmo fatores ambientais, como a radiação ou vibrações do disco. Desduplicação aumenta o impacto de um único pedaço de corrupção desde que um pedaço popular pode ser referenciado por um grande número de arquivos. Imagine um pedaço que é referenciada por 1.000 arquivos são perdidos devido a um erro de setor; você instantaneamente sofrer uma perda de arquivos 1000.
- Suporte Backup: Temos suporte para totalmente otimizado de backup usando a caixa de entrada ferramenta Windows Server Backup e temos vários grandes fornecedores que trabalham com a adição de suporte para backup otimizado e não-otimizado de backup. Temos um arquivo de restauração seletiva API para permitir que aplicativos de backup para puxar os arquivos de um backup otimizado.
- Relatórios e Detecção : Toda vez que o filtro de desduplicação percebe uma corrupção que registra no log de eventos, para que possa ser limpo. Validação de checksum é feito em todos os dados e metadados, quando ele é lido e escrito. Desduplicação reconhecer quando os dados que está sendo acessado foi corrompido, reduzindo corrupções silenciosas.
- Redundância : cópias extras de metadados crítica são criados automaticamente. Pedaços muito populares receber dados inteiros cópias duplicadas sempre que é referenciado 100 vezes. Nós chamamos essa área “hotspot”, que é uma coleção dos pedaços mais populares.
- Reparação : Um trabalho de lavagem semanal inspeciona o log de eventos para corrupções registrados e corrige os blocos de dados a partir de cópias alternativas, se existirem. Há também um trabalho profundo matagal opcional disponível que irá percorrer o conjunto de dados inteiro, à procura de corrupções e tenta corrigi-los. Ao utilizar um conjunto de armazenamento de disco Espaços que é espelhado, deduplicação chegará a mais para o outro lado do espelho e agarrar a boa versão. Caso contrário, os dados terão que ser recuperados a partir de uma cópia de segurança. Desduplicação continuamente escanear pedaços de entrada que encontra olhando para os que podem ser usados para corrigir uma corrupção.
Ele corta, ele corta e limpa o seu chão!
Bem, o recurso de desduplicação de dados não faz tudo nesta versão. Ele só está disponível em certas edições do Windows Server 2012 e tem algumas limitações. Desduplicação foi construído para volumes de dados NTFS e ele não suporta boot ou unidades do sistema e não pode ser usado com Cluster Shared Volumes (CSV). Não apoiamos desduplicação VMs ao vivo ou executar bancos de dados SQL. Veja como determinar quais volumes são candidatos a desduplicação no Technet.
Experimente o desduplicação Ferramenta de Avaliação de Dados
Para auxiliar na avaliação de conjuntos de dados foi criada uma ferramenta de avaliação portátil. Quando o recurso é instalado, DDPEval.exe é instalado para a pasta \ Windows \ System32 \ diretório. Esta ferramenta pode ser copiado e executado no Windows 7 ou sistemas posteriores para determinar as economias esperadas que você obteria se desduplicação foi ativado em um determinado volume. DDPEval.exe suporta discos locais e também mapeadas ou não mapeada partes remotas. Você pode executá-lo contra uma participação em seu NAS do Windows , ou um NAS EMC / NetApp e comparar as economias.
Resumo:
Eu acho que esse recurso de deduplicação de novo no Windows Server 2012 será muito popular. É o tipo de tecnologia que as pessoas precisam e não posso esperar para vê-lo em implantações de produção. Eu gostaria de ver os seus relatórios na parte inferior deste blog de quanto espaço em disco e dinheiro que você economizou. Basta copiar o resultado deste comando PowerShell: PS > **Get-DedupVolume
**
- Espaço + 30-90% pode ser alcançado com desduplicação na maioria dos tipos de dados. Eu tenho um disco de 200GB que eu continuo jogando dados em e agora tem 1.7TB de dados sobre ele. É fácil esquecer que é uma unidade de 200GB.
- A desduplicação é fácil de instalar e as configurações padrão não vai deixar você um tiro no próprio pé.
- Desduplicação trabalha duro para detectar, notificar e reparar corrupções de disco.
- Você pode experimentar vezes mais rápido download de arquivos e consumo de largura de banda reduzida através de uma WAN através da integração com o BranchCache.
- Experimente a ferramenta de avaliação para ver quanto espaço você vai economizar se você atualizar para o Windows Server 2012!
Fontes:
Fonte Original: https://blogs.technet.com/b/filecab/archive/2012/05/21/introduction-to-data-deduplication-in-windows-server-2012.aspx?Redirected=true
Ajuda Online: http://technet.microsoft.com/en-us/library/hh831602.aspx
Cmdlets PowerShell: http://technet.microsoft.com/en-us/library/hh848450.aspx