Procedural versus Set-Based SQL
During my day job I come across customers that are struggling to make a system perform to the expectations of their users, and they often see this as a SQL Server problem. This post is designed to demonstrate how much of a difference your approach to SQL tasks can make to the performance and scalability of your system. Of course, the real trick is to make sure you performance test thoroughly; a system can behave totally differently in a live environment to how it was seen to behave during development and system testing.
The Scenario
For this post I’ve tried to illustrate a common scenario with the attached SQL script. Very simply, we have Customers, Orders, OrderItems, and Products tables following a very familiar relationship pattern.
I’ve then invented a set of Stored Procedures to retrieve a list of “Big Orders”. The idea is that a “Big Order” is defined according to some rules, based on the date, size of the order, a substring in the order description, and so on.
There are three types of Stored Procedure, and they are all based on approachesthat I’ve regularly seen in real implementations, and therefore hopefully illustrate my points well;
1. GetBigOrdersReselecting. This procedure also uses a function named IsBigOrder. Basically it retrieves a list of Order Ids to work with, and then loops through them calling IsBigOrder with each. IsBigOrder then selects the row it needs to work with using that ID, and determines if the order is “big”. If it is, GetBigOrdersReselecting adds this ID to the result set. This means the row is “reselected” multiple times – a very common approach.
2. GetBigOrdersCursor. This procedure opens a cursor and steps through all the orders determining if the order is “big”. If it is, it adds the ID to the result set using a temporary table. This approach is used in many, many systems.
3. GetBigOrdersSetBased. This procedure uses a single SELECT statement to fetch all the orders that are considered “big”... and is my preferred approach and the reason for this post.
The Tests
What I wanted to show was how each of these approaches behaves differently as the volume of data increases. Therefore I have used a Visual Studio 2008 Data Generation Plan to fill my tables with test data (with ratios Customer:Order:OrderItem of 1:5:15). I have then run each of the Stored Procedures and captured some statistics to look at.
I did this for two test data sets – those that included less than 15% of “big” orders (“Low Hit Ratio”), and those that included about 45% of “big” orders (“High Hit Ratio”). This is intended to reflect two different types of SQL – those that retrieve and process a large percentage of the data as a batch job might, and those that need a smaller percentage of the rows, like an OLTP system might.
It is at this point you must realise that this post is indicative only. It is actually pretty unscientific due to my time constraints. I’m running SQL 2008 on my laptop, with various programs open (e.g. Outlook), using randomly generated data that is different each time, without any sensible indexing strategy, without recompiling stored procs between runs, and so on. In other words, I believe the figures show a valid pattern, but don’t go on the individual millisecond results. Just take the core message on board.
The Results
Let’s get to the point then, and look at how long each of the three approaches took to run (in seconds) for increasing volumes of records in the Order table.
50 |
250 |
500 |
1,000 |
2,500 |
5,000 |
10,000 |
25,000 |
50,000 |
100,000 |
|
Set based High Hit % |
0.000 |
0.000 |
0.017 |
0.017 |
0.046 |
0.047 |
0.126 |
0.237 |
0.453 |
0.686 |
Cursor High Hit % |
0.000 |
0.013 |
0.030 |
0.046 |
0.140 |
0.313 |
0.437 |
1.007 |
2.074 |
3.687 |
Reselect High Hit % |
0.017 |
0.127 |
0.406 |
1.507 |
8.727 |
5.193 |
20.073 |
|||
Set based Low Hit % |
0.000 |
0.000 |
0.013 |
0.017 |
0.033 |
0.064 |
0.046 |
0.186 |
0.343 |
0.513 |
Cursor Low Hit % |
0.000 |
0.013 |
0.017 |
0.030 |
0.077 |
0.173 |
0.280 |
0.734 |
1.413 |
2.530 |
Reselect Low Hit % |
0.017 |
0.127 |
0.406 |
1.490 |
8.917 |
5.157 |
19.747 |
Note I didn’t bother running the 25,000+ runs for the “reselect” approach. There is also an interesting anomaly in there (I wish I had time to investigate!), in that “reselect” seems to temporarily improve around the 5,000 record mark. That could be for all sorts of reasons but at least you know I’m not faking my results J
Anyway, I think two graphs illustrate the results best; the first includes the “reselect” procedure results, the second excludes it so that we can see more detail of the other two.
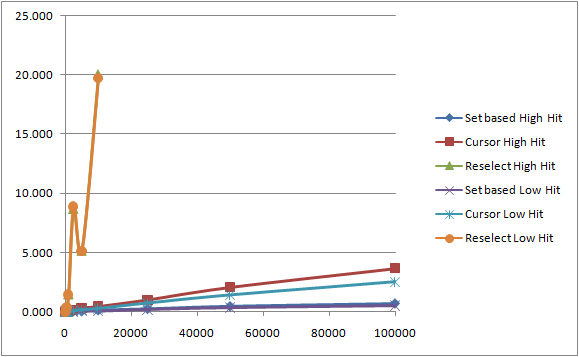
Including Reselect
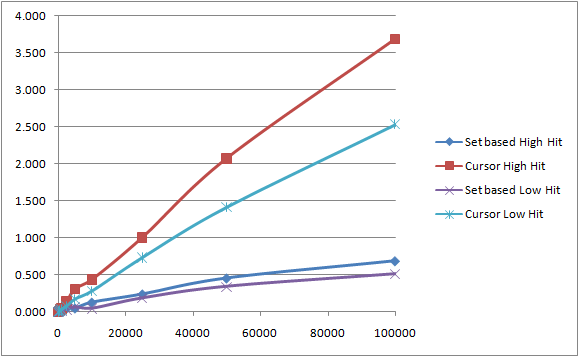
Excluding Reselect
You can clearly see a few things from this;
1. The Set-based approach is faster than any other approach for anything but the smallest amounts of data.
2. The Cursor approach gets a lot slower quickly (fairly proportionally, at least).
3. The Reselect approach is unpredictable, and much, much slower than either of the other two approaches. It almost spirals out of control quickly - with very few records it is probably in the unacceptable performance category for an OLTP system.
It is important to understand that as these queries run slower and slower so they will also have a disproportionately bad effect on any multi-user system. There is more chance that multiple connections will be executing queries against the same data at the same time, more memory will probably be in use, the processor will be busier, and your disks might well be more active. This increases the chances of deadlocks and more. Therefore the wrong approach to SQL statements not only compromises the performance of your queries, but also the scalability of your concurrent queries, and ultimately the stability of your system.
Remember that my example just uses SELECTs, but we could easily be looking at UPDATE statements too.
Implementation
So how is this set-based approach implemented for complex logic you have traditionally used procedural code for? Quite easily actually, after a bit of practice - complex rules can often be expressed using a combination of AND/OR, CASE, and more. Have a look at the HAVING clause of my set-based query;
SELECT
... SQL removed...
HAVING
(
o.OrderDate < GETDATE() AND
(
(
SUM(oi.NumberOfItems * p.Price) > 100 AND
CASE SUBSTRING(o.OrderDescription, 0, 4)
WHEN '011' THEN 1
WHEN '012' THEN 1
ELSE 0
END = 1
) OR
(
SUM(oi.NumberOfItems * p.Price) <= 100 AND
SUM(oi.NumberOfItems) > 3
)
)
) OR
(
o.OrderDate >= GETDATE() AND
SUM(oi.NumberOfItems * p.Price) > 150
)
This is by no means perfect. I could replace SUBSTRING with LIKE, I haven’t tuned it by looking at the query plan at all, and I should consider adding some indices; I might even choose to cache some data using an indexed view, and more. But without any of this work it still runs much faster than the other options, and I think you can see from my HAVING clause how easy it is to express the logic.
I’m trying to keep this post as brief as possible, so I won’t go into approaches to writing this set-based logic – but one key point is to ensure you use mutually exclusive OR clauses (so you might duplicate some lines – such as my use of o.OrderDate), and don’t forget to test, test, test. In fact, if you’re replacing procedural code you might consider automating running both queries against the same data and comparing the results.
Summary
This is one of the easiest summaries I’ve ever written...
Whenever you’re writing SQL always start out with writing set-based statements. It may look harder at first, but it gets easier once you’ve done it a few times, and I firmly believe the effort up front pays dividends when you come to scaling your application. Set-based SQL is also far easier to tune than procedural logic using the usual SQL tricks of changing indexes, partitioning, and so on.
There are always exceptions to rules of thumb, and I’m sure you’ll have a scenario where something can’t or shouldn’t be done in a set-based way... but just be absolutely sure that’s the case. Usually it comes down to data that must be dealt with in an ordered manner, perhaps with a running cumulative total or similar.
If you try reworking some SQL into a set-based approach I’d love to hear what you find; whether it is huge performance improvements, or otherwise – feel free to comment here.
Comments
Anonymous
March 29, 2009
PingBack from http://blog.a-foton.ru/index.php/2009/03/30/procedural-versus-set-based-sql/Anonymous
March 30, 2009
Thank you for submitting this cool story - Trackback from DotNetShoutoutAnonymous
March 30, 2009
Given that gnarly having clause in your SQL you might just be better off with no SQL at all and use MDX instead.Anonymous
March 30, 2009
@ James; Good point - there is a risk that the SQL will become difficult to maintain, but I think laying it out clearly, following a common pattern (e.g. using mutually exclusive clauses as I mentioned) and splitting some into views where needed means it isn't a big problem. SimonAnonymous
April 16, 2009
I completely agree. A set base query is always preferred. If I can give one bit of advice, avoid scalar functions and cursors like the plague, write set based queries whenever possible, only use the CLR if you really need to, and index your tables.Anonymous
April 19, 2009
@ Sam, Thanks! I agree with your rules of thumb... they're very similar to my default approach as well. Although having said that, I guess what makes SQL difficult is that the scenario can impact the advice - so there are some very infrequent cases when I would concede that set-based SQL isn't the most efficient (hence my comment "always start out with writing set-based statements"), or when indexing a table should be avoided (perhaps during bulk loading) and so on... they're good starting points though. SimonAnonymous
May 19, 2009
During my day job I come across customers that are struggling to make a system perform to the expectationsAnonymous
September 17, 2009
I need help converting my procedural based HR SQLs into Set Based form. Can you help?Anonymous
September 17, 2009
The comment has been removed