Equation of a Fuzzing Curve -- Part 2/2
Follow-up notes and discussion
See Part 1 here.
Can you predict how many bugs will be found at infinity?
No.
There seems to be a fundamental limit on fuzzing curve extrapolation.
To see that, consider bug distribution function of the following form:
.png)
where p0 >> p1 but a0 ≈ a1 and δ(x) is a Dirac delta-function.
For such a distribution U(N) is:

At early fuzzing stages, the 2nd term is so much smaller than the first one that it remains undetectable. Under that condition, only the first term would be considered, with the expected U(N) value at infinity of a0. However, the true bug yield for that curve is a0 + a1! But we will not notice that until we've done enough fuzzing to "see" the 2nd term. It is possible to show that it will become detectable only after more than the following number of iterations is performed:

Prior to that, the extrapolation of the above fuzzing curve will produce grossly incorrect results.
Since (in general) any fuzzing curve can potentially carry terms similar to the last one in (150) it means that no matter how long we've fuzzed, predicting what the curve would look like beyond a certain horizon is impossible. If that reasoning is correct, only short or mid-term fuzzing extrapolation is possible.
What defines G(p)?
What if we obtain G(p) not from the observations but use some theory to construct it in the most generic form?
Unfortunately, it seems that G(p) is more a function of a fuzzer rather than of a product.
Often, you run a sophisticated fuzzer for countless millions of iterations and beat seemingly all the dust out of your product. Next day, someone appears with a new fuzzer made out of 5 lines of Python code and finds new good bugs. Many. That's hard to explain if bug discovery probability was mostly a property of a product, not of a fuzzer.
[Also, fuzzing stack traces often tend to be very deep, with many dozens of frames, suggesting that the volume of functionality space being fuzzed is so large that most fuzzers probably only scratch the surface of it rather than completely exhaust it]
If that is correct, fuzzer diversity should work better than fuzzing duration. Twelve different fuzzers running for a month should be able to produce more good bugs than one fuzzer running for a year.
That said, constructing G(p) from a pure theory and therefore finding a fuzzing curve approximation that works better than generic form (140) might be possible – but for a specific fuzzer only, using the knowledge of that fuzzer intrinsic properties and modes of operation.
How long should you fuzz?
The only right answer from the security standpoint is "indefinitely"!
However, from the business prospective the following return-on-investment (ROI) analysis may make sense and lead to a different answer.
Fuzzing has its dollar cost. That’s because infrastructure, machines, electric power, triaging, filing and fixing bugs cost money, not to mention paying the people who do all that.
Not fuzzing has its cost as well. The most prominent part of it is the cost of patching vulnerabilities that could’ve been prevented by fuzzing.
Let’s introduce the cost of fuzzing per one iteration X(N) . In addition to that, there is a cost of bugs management Y per bug, and a one-time cost of enabling fuzzing infrastructure C. Thus, the cost of running N fuzzing iterations per a parser is:

Not running fuzzing introduces security bugs. Let’s denote the average cost of responding to a security vulnerability via T, and the probability that the response will be required via q (assuming, for simplicity, that q is constant). If there are B total bugs in the product, and the fuzzer in question has ran for N iterations, it would’ve found U(N) bugs. Then B - U(N) bugs would remain in the product, and some of them would be found and exploited. Therefore, the cost of not running fuzzer after the initial N iterations is q*T*(B-U(N)) .
Combined together, these two figures give the cost of a decision to run fuzzing for N iterations and then stopping, as a function of N:

From purely the ROI standpoint, fuzzing needs to continue while the increase of iterations decreases the total cost:

which translates to:

Let’s introduce Δ N(N) – the number of fuzzing iterations required to find one bug. By the definition,

Multiplying (220) by Δ N and slightly rearranging, we arrive to:
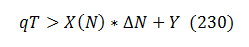
This is a generic stopping condition for static fuzzing.
It says: “fuzz until the cost of finding the next bug plus managing it exceeds the cost of addressing a vulnerability multiplied by the chance such vulnerability would be found or exploited”.
Since fuzzing with no bugs found (yet) costs no less than fuzzing until the first bug is hit, the condition above could be generalized to include situations with or with no bugs found yet:
- Estimate the cost of addressing one externally known vulnerability in your product
- Multiply it by the chance that internally known bug becomes externally known or exploited
- As a security person, I should strongly push to use 100% here…
- …but we know that in reality it may be different
- My previous post provides some thoughts on assessing that figure
- Subtract the cost of managing and fixing one bug internally
- Call the result V
- Fuzz until the costs of fuzzing exceeds V or until potentially exploitable bugs are found
- If such bugs are found, reset the cost to 0 and go back to step 5
Similar logic could be applied to the attacker’s side and similar conclusion would be derived, but with "vulnerability cost" replaced by "the benefits of exploiting one vulnerability". Comparing the attacker's and the defenders' ROIs then leads to some conclusions:
- If defenders lose less than attackers benefit from finding a vulnerability, attackers will statistically prevail in fuzzing (actually, you don't really need the math above to see that).
- ROI-driven fuzzing dictates a "stopping point" that will be surpassed by attackers who:
- Are not driven by direct profits (e.g., groups with geopolitical or military interests), and
- Have large cache reserves (e.g., are state-sponsored)
- …meaning, such groups will (provided other things being equal) prevail over the defenders in finding fuzzing bugs and exploiting them.
- Software manufacturers still should fuzz, but mainly to increase the entry barrier ( Δ N) for new attackers seeking to join the arms race.
What if my fuzzer is not random?
Some fuzzers learn from what they find to better aim their efforts. Their bug search is not completely random. However, a slight modification to the same theory permits describing their output with the same equation (140) where individual bugs are replaced by small (3-15 in size) bug clusters.
Summary
1. In many practical cases, fuzzing curve could be modeled as

where ai and pi are some positive fixed parameters and D is small, on the order of 0 to 3.
2. Two fuzzers working for a month are better than one fuzzer working for 2 months.
3. There is a limit on how far into the future a static fuzzing curve could be extrapolated, and it seems to be fundamental (not depending on the method of extrapolation).
4. State-sponsored, non-profit driven attackers are likely to fuzz more than ROI-driven software manufacturers. That said the defenders have no other choice as to continue fuzzing and invest in fuzzing diversity and sophistication (rather than pure duration).
Acknowledgements
To Tim Burrell, Graham Calladine, Patrice Godefroid, Matt Miller, Lars Opstad, Andy Renk, Tony Rice, Gavin Thomas for valuable feedback, support, and discussions. To Charlie Miller for his permission to reference data in his work.