Usar o modelo predefinido de reconhecimento de texto no Power Automate
O modelo de reconhecimento de texto predefinido no AI Builder extrai texto impresso e manuscrito de imagens e documentos. Usando esse modelo Power Automate, você pode criar fluxos de trabalho que processam automaticamente o texto de documentos, fotos e PDFs digitalizados, permitindo a manipulação eficiente de dados e a integração com outros aplicativos.
Este documento fornece um guia sobre como usar o modelo predefinido de reconhecimento de texto no Power Automate.
Inicializar o fluxo do Power Automate
Inicializar o Power Automate fluxo é a primeira etapa para configurar seu processo automatizado. Esta etapa permite que você defina o gatilho e os parâmetros de entrada iniciais para seu fluxo. Ao inicializar, você pode garantir que seu fluxo seja iniciado corretamente e tenha as informações necessárias para processar as tarefas de reconhecimento de texto de forma eficiente.
Para inicializar seu fluxo, siga estas etapas:
Entre no Power Automate.
No menu de navegação à esquerda, selecione Meus fluxos e, em seguida, escolha Novo fluxo>Fluxo da nuvem instantâneo.
Nomeie seu fluxo, selecione Disparar um fluxo manualmente em Escolher como disparar este fluxo e selecione Criar.
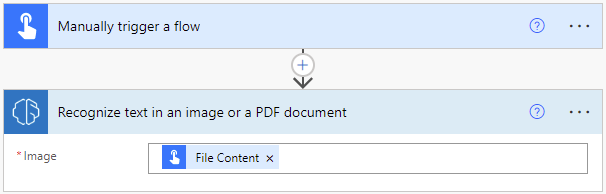
Expanda Disparar um fluxo manualmente e selecione + Adicionar uma entrada>Arquivo como o tipo de entrada.
Selecione +Nova etapa>AI Builder e, depois, Reconhecer texto em uma imagem ou documento PDF na lista de ações.
Selecione a entrada Imagem e depois Conteúdo do Arquivo da lista Conteúdo dinâmico:
Para processar os resultados, você pode usar o texto completo do documento, um texto de página ou o texto do documento linha por linha.
Obter o texto completo do documento ou um texto de página inteira
Se você precisar executar uma ação no texto completo do documento ou no texto da página específico, essa opção será útil. Um exemplo de uso de texto de página é quando você deseja pesquisar uma subcadeia de caracteres ou passá-la para uma ação subsequente.
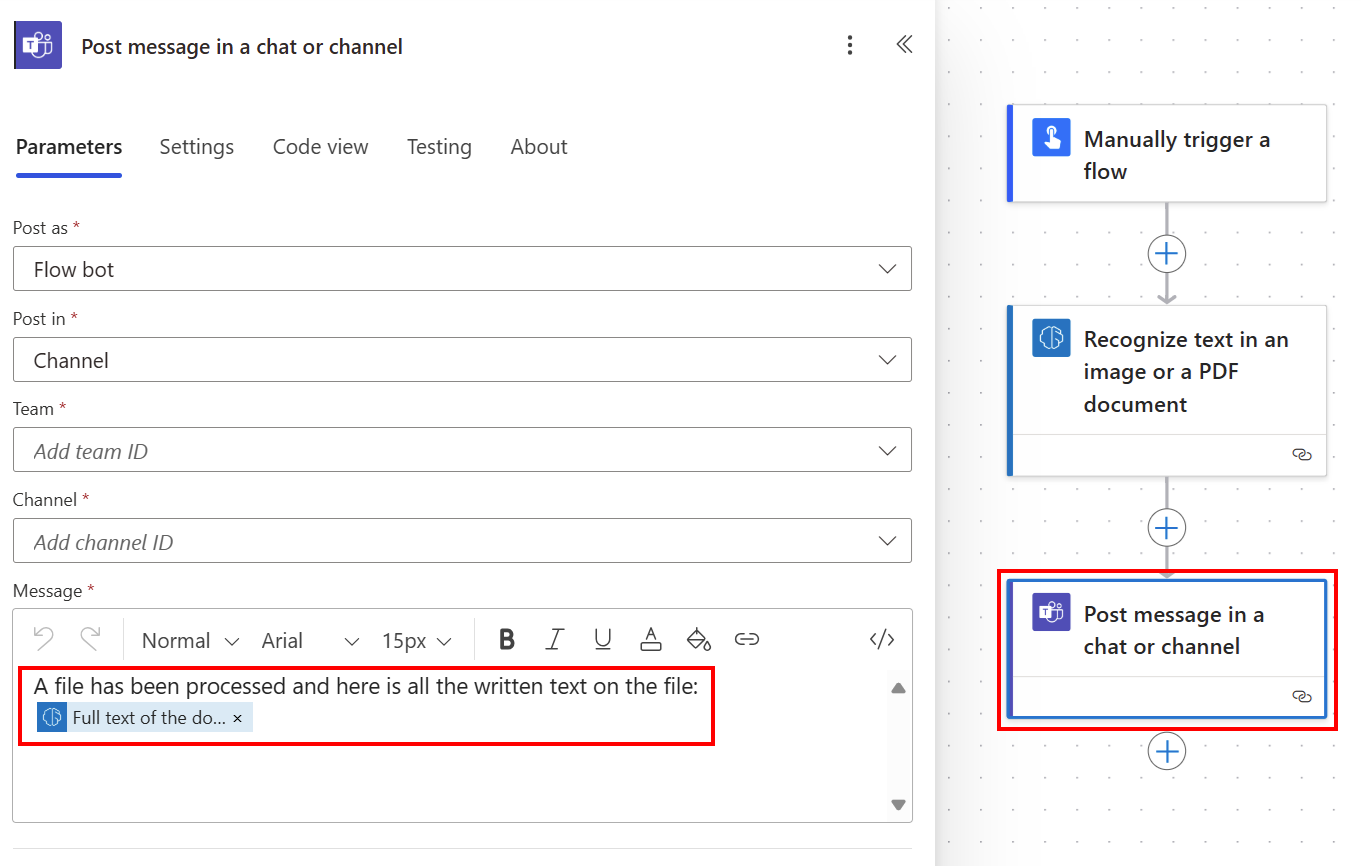
Você pode postar todo o texto extraído em um canal do Teams usando o texto completo do documento da lista Conteúdo dinâmico.
Obter o texto do documento linha por linha
Obter o texto do documento linha por linha pode ser útil se você precisar isolar uma linha específica de texto ou reformatar o texto de acordo com sua conveniência.
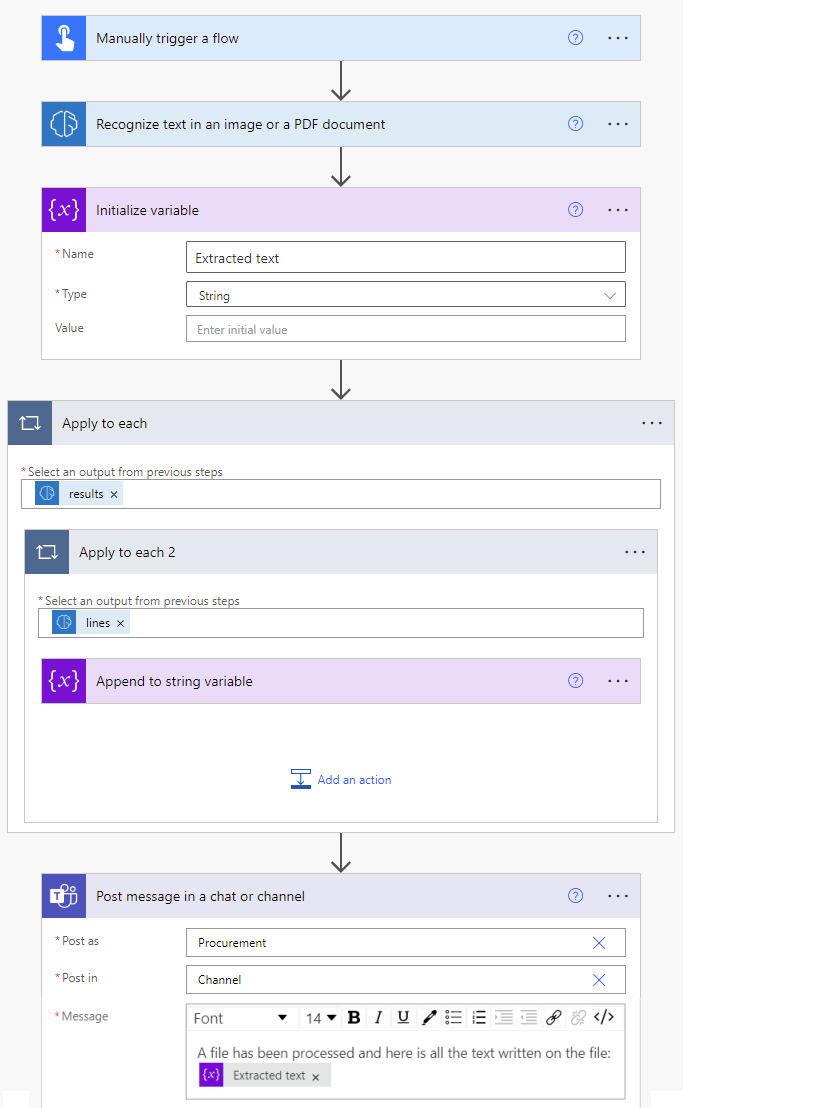
Para criar uma variável de cadeia de caracteres, selecione +Nova etapa>Controlee, em seguida, selecione Inicializar variável.
Nomeie-o Texto extraído, por exemplo.
Selecione +Nova etapa>Controle e selecione Acrescentar à variável de cadeia de caracteres.
No campo valor, selecione Texto na lista de Conteúdo dinâmico.
Ele gera automaticamente duas ações Aplicar a cada enquanto lê uma lista de linhas de texto em uma lista de páginas. Em seguida, você pode postar todo o texto extraído em um canal do Teams.
Parabéns! Você criou um fluxo que utiliza o modelo de reconhecimento de texto. Você pode continuar a se basear nesse fluxo para atender às suas necessidades. Selecione Salvar na parte superior direita, depois Testar para testar seu fluxo.
Parâmetros
O modelo predefinido de reconhecimento de texto no AI Builder contém os seguintes parâmetros de entrada e saída.
Entrada
| Name | Obrigatória | Type | Description |
|---|---|---|---|
| Imagem | Sim | arquivo | Imagem a analisar |
Saída
O texto detectado está incorporado na sublista linhas da lista resultados. Primeiro, você precisa selecionar a coluna linhas em uma ação Aplicar a cada para visualizar todas as colunas a seguir.
| Nome | Digitar | Descrição |
|---|---|---|
| Texto | cadeia de caracteres | Cadeias de caracteres que contêm a linha de texto detectada |
| Número da página | cadeia de caracteres | Número da página do texto detectado |
| Coordenadas | float | Coordenadas do texto detectado |
| Texto completo do documento | cadeia | Texto completo detectado |
| Texto completo da página | cadeia | Texto de página inteira detectado |