Gerenciamento de custo para o pool de SQL sem servidor no Azure Synapse Analytics
Este artigo explica como você pode estimar e gerenciar os custos para o pool de SQL sem servidor no Azure Synapse Analytics:
- Estimar a quantidade de dados processados antes de emitir uma consulta
- Usar o recurso controle de custo para definir o orçamento
Entenda que os custos para o pool de SQL sem servidor no Azure Synapse Analytics são apenas uma parte dos custos mensais em sua fatura do Azure. Se estiver usando outros serviços do Azure, você será cobrado por todos os serviços e recursos do Azure usados na sua assinatura do Azure, incluindo os serviços de terceiros. Este artigo explica como você pode planejar e gerenciar os custos para o pool de SQL sem servidor no Azure Synapse Analytics.
Dados processados
Os dados processados são a quantidade de dados que o sistema armazena temporariamente enquanto uma consulta é executada. Os dados processados consistem nas seguintes quantidades:
- Quantidade de dados lidos do armazenamento. Essa quantidade inclui:
- Dados lidos durante a leitura de dados.
- Dados lidos durante a leitura de metadados (para formatos de arquivo que contêm metadados, como Parquet).
- Quantidade de dados em resultados intermediários. Esses dados são transferidos entre nós enquanto a consulta é executada. Inclui a transferência de dados para seu ponto de extremidade, em um formato descompactado.
- Quantidade de dados gravados no armazenamento. Se você usar CETAS para exportar o conjunto de resultados para armazenamento, a quantidade de dados gravados será adicionada à quantidade de dados processados para a parte SELECT de CETAS.
A leitura de arquivos do armazenamento é altamente otimizada. O processo usa:
- Pré-busca, que pode adicionar alguma sobrecarga à quantidade de dados lidos. Se uma consulta ler um arquivo inteiro, não haverá sobrecarga. Se um arquivo for lido parcialmente, como nas consultas TOP N, um pouco mais de dados será lido usando a pré-busca.
- Um analisador de valor separado por vírgula (CSV) otimizado. Se você usar PARSER_VERSION='2.0' para ler arquivos CSV, as quantidades de dados lidos do armazenamento aumentarão um pouco. Um analisador CSV otimizado lê arquivos em paralelo, em partes de tamanho igual. As partes não contêm necessariamente linhas inteiras. Para garantir que todas as linhas sejam analisadas, o analisador CSV otimizado também lê pequenos fragmentos de partes adjacentes. Esse processo adiciona uma pequena quantidade de sobrecarga.
Estatísticas
O otimizador de consulta do pool de SQL sem servidor se baseia em estatísticas para gerar planos de execução de consulta ideais. Você pode criar estatísticas manualmente. Caso contrário, o pool de SQL sem servidor as criará automaticamente. De qualquer forma, as estatísticas são criadas com a execução de uma consulta separada que retorna uma coluna específica em uma taxa de amostra fornecida. Esta consulta tem uma quantidade associada de dados processados.
Se você executar a mesma ou qualquer outra consulta que possa se beneficiar das estatísticas criadas, as estatísticas serão reutilizadas, se possível. Não há dados adicionais processados para a criação de estatísticas.
Quando as estatísticas são criadas para uma coluna Parquet, somente a coluna relevante é lida a partir dos arquivos. Quando as estatísticas são criadas para uma coluna CSV, arquivos inteiros são lidos e analisados.
Arredondamento
A quantidade de dados processados é arredondada para o MB mais próximo por consulta. Cada consulta tem um mínimo de 10 MB de dados processados.
Quais dados processados não incluem
- Metadados de nível de servidor (como logons, funções e credenciais de nível de servidor).
- Bancos de dados que você cria em seu ponto de extremidade. Esses bancos de dados contêm apenas metadados (como usuários, funções, esquemas, modos de exibição, funções com valor de tabela embutida [TVFs], procedimentos armazenados, credenciais no escopo do banco de dados, fontes externas de dados, formatos de arquivos externos e tabelas externas).
- Se você usar a inferência de esquema, os fragmentos de arquivo serão lidos para inferir nomes de coluna e tipos de dados, e a quantidade de dados lidos será adicionada à quantidade de dados processados.
- Instruções DDL (linguagem de definição de dados), exceto para a instrução CREATE STATISTICS porque ela processa dados do armazenamento com base na porcentagem de amostra especificada.
- Consultas somente de metadados.
Reduzir a quantidade de dados processados
Você pode otimizar a quantidade de dados processados por consulta e melhorar o desempenho ao particionar e converter seus dados em um formato baseado em coluna compactado, como Parquet.
Exemplos
Imagine três tabelas.
- A tabela population_csv é apoiada por 5 TB de arquivos CSV. Os arquivos são organizados em cinco colunas igualmente dimensionadas.
- A tabela population_parquet tem os mesmos dados que a tabela population_csv. Tem o suporte de 1 TB de arquivos Parquet. Esta tabela é menor do que a anterior porque os dados são compactados no formato Parquet.
- A tabela very_small_csv tem o suporte de 100 KB de arquivos CSV.
Consulta 1: SELECIONE SUM (população) DE population_csv
Esta consulta lê e analisa arquivos inteiros para obter valores para a coluna de população. Nós processam fragmentos dessa tabela e a soma da população para cada fragmento é transferida entre nós. A soma final é transferida para o ponto de extremidade.
Essa consulta processa 5 TB de dados mais uma pequena sobrecarga de valores para transferir somas de fragmentos.
Consulta 2: SELECIONE SUM (população) DE population_parquet
Quando você consulta formatos compactados e baseados em colunas como Parquet, são lidos menos dados do que na consulta 1. Você verá esse resultado porque o pool de SQL sem servidor lê uma única coluna compactada em vez de todo o arquivo. Nesse caso, 0.2 TB é lido. (Cinco colunas igualmente dimensionadas têm 0.2 TB cada.) Nós processam fragmentos dessa tabela e a soma da população para cada fragmento é transferida entre nós. A soma final é transferida para o ponto de extremidade.
Essa consulta processa 0.2 TB de dados mais uma pequena sobrecarga de valores para transferir somas de fragmentos.
Consulta 3: SELECIONE * DE population_parquet
Essa consulta lê todas as colunas e transfere todos os dados em um formato descompactado. Se o formato de compactação for 5:1, a consulta processará 6 TB porque ela lê 1 TB e transfere 5 TB de dados descompactados.
Consulta 4: SELECIONE COUNT(*) DE very_small_csv
Essa consulta lê arquivos inteiros. O tamanho total dos arquivos no armazenamento para esta tabela é de 100 KB. Nós processam fragmentos dessa tabela e a soma para cada fragmento é transferida entre nós. A soma final é transferida para o ponto de extremidade.
Essa consulta processa um pouco mais de 100 KB de dados. A quantidade de dados processados para essa consulta é arredondada para 10 MB, conforme especificado na seção Arredondamento deste artigo.
Controle de custo
O recurso controle de custo no pool de SQL sem servidor permite que você defina o orçamento para a quantidade de dados processados. Você pode definir o orçamento em TB de dados processados para um dia, uma semana e um mês. Ao mesmo tempo, você pode ter um ou mais orçamentos definidos. Para configurar o controle de custo para o pool de SQL sem servidor, você pode usar o Synapse Studio ou o T-SQL.
Configurar o controle de custo para o pool de SQL sem servidor no Synapse Studio
Para configurar o controle de custo para o pool de SQL sem servidor no Synapse Studio, navegue até o item Gerenciar no menu à esquerda, em vez de selecionar o item pool de SQL em pools de análise. Ao focalizar o pool de SQL sem servidor, você observará um ícone de controle de custo - clique nesse ícone.
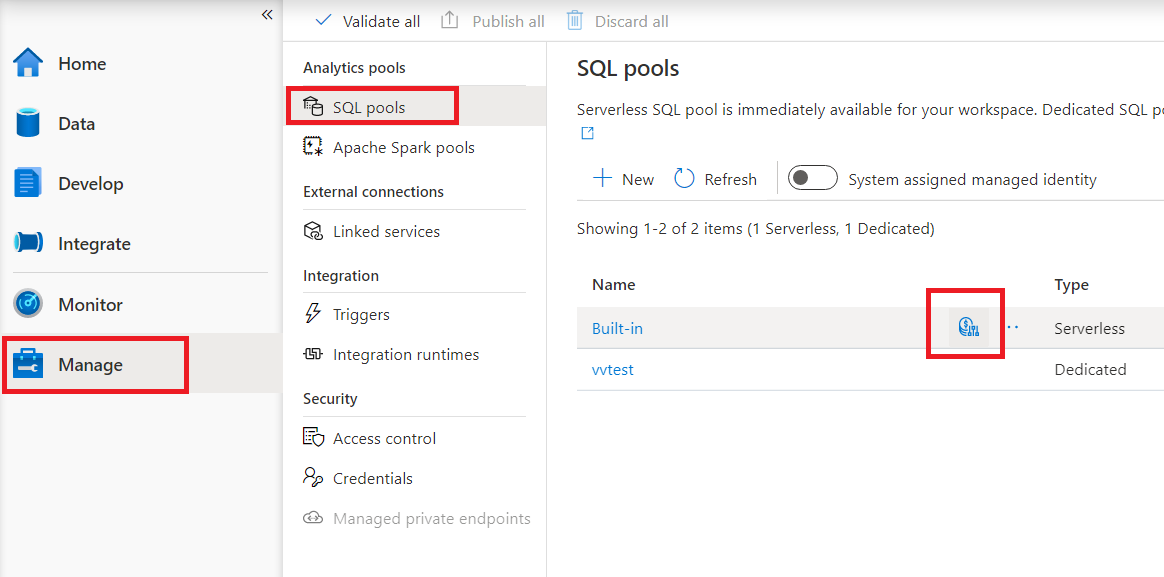
Depois de clicar no ícone controle de custo, uma barra lateral será exibida:
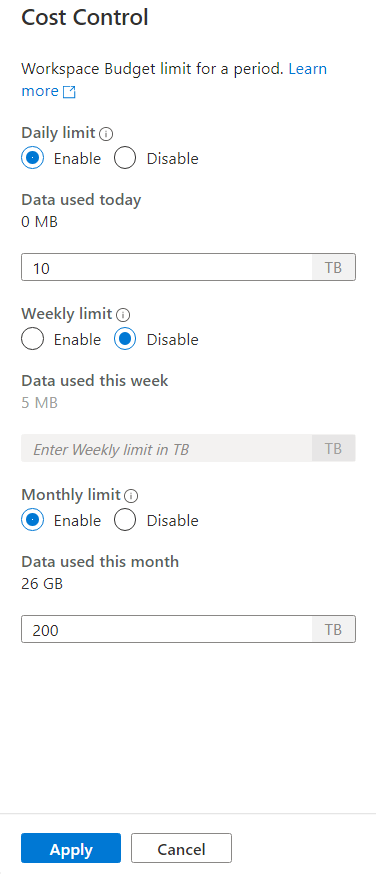
Para definir um ou mais orçamentos, primeiro clique no botão de opção Habilitar para um orçamento que você deseja definir, em vez de inserir o valor inteiro na caixa de texto. A unidade para o valor é TBs. Depois de configurar os orçamentos desejados, clique no botão Aplicar na parte inferior da barra lateral. Pronto. Agora seu orçamento está definido.
Configurar o controle de custo para o pool de SQL sem servidor no T-SQL
Para configurar o controle de custo para o pool de SQL sem servidor no T-SQL, você precisa executar um ou mais dos procedimentos armazenados a seguir.
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
Para visualizar a configuração atual, execute a seguinte instrução T-SQL:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
Para ver quantos dados foram processados durante o dia, a semana ou o mês atual, execute a seguinte instrução T-SQL:
SELECT * FROM sys.dm_external_data_processed
Excedendo os limites definidos no controle de custo
Quando algum limite é excedido durante a execução da consulta, ela não é encerrada.
Quando isso acontece, uma nova consulta é rejeitada com uma mensagem de erro que contém detalhes sobre o período, o limite definido para esse período e os dados processados durante ele. Por exemplo, quando uma nova consulta é executada, sendo que o limite semanal definido como 1 TB foi excedido, a mensagem de erro é:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
Próximas etapas
Para saber como otimizar suas consultas de desempenho, consulte Práticas recomendadas para o pool de SQL sem servidor.