Otimizar consulta usando a simulação de trabalho
Uma maneira de melhorar o desempenho de um trabalho do (ASA) Azure Stream Analytics é aplicando o paralelismo na consulta. Este artigo demonstra como usar a Simulação de Trabalho no portal do Azure e no VS Code (Visual Studio Code) para avaliar o paralelismo de consulta de um trabalho do Stream Analytics. Você aprenderá a visualizar a execução de uma consulta com um número diferente de unidades de streaming e melhorar o paralelismo de consulta com base nas sugestões de edição.
O que é consulta paralela?
O paralelismo de consulta divide a carga de trabalho de uma consulta, criando vários processos (ou nós de streaming), e a executa paralelamente. Isso reduz consideravelmente o tempo de execução geral da consulta e, portanto, diminui as horas de streaming necessárias.
Para que um trabalho seja paralelo, todas as entradas, saídas e etapas da consulta devem ser alinhadas e usar as mesmas chaves de partição. O particionamento lógico de consulta é determinado pelas chaves usadas para agregações (GROUP BY).
Se você quiser saber mais sobre a paralelização de consulta, confira Utilizar a paralelização de consulta no Azure Stream Analytics.
Usar simulação de trabalho no VS Code
O recurso Simulação de Trabalho simula como o trabalho executaria a topologia no Azure. Neste tutorial, você aprenderá a melhorar o desempenho da consulta de acordo com as sugestões de edição e a executá-la paralelamente. Por exemplo, estamos usando um trabalho não paralelo que recebe os dados de entrada de um hub de eventos e envia os resultados para outro hub de eventos.
Pré-requisitos:
- Extensão de Ferramentas do ASA para VS Code. Se você ainda não instalou, siga este guia para fazê-lo.
- Configure a entrada dinâmica e a saída dinâmica para o trabalho do Stream Analytics.
- É necessário incluir a entrada e a saída dinâmicas na consulta.
Observação
A Simulação de Trabalho não pode simular a topologia de execução do trabalho para entradas e saídas locais. Nenhum dado seria enviado para o destino de saída durante a simulação.
Abra o projeto ASA no VS Code. Acesse o arquivo de consulta *.asaql e selecione Simular trabalho para iniciar a Simulação de Trabalho.
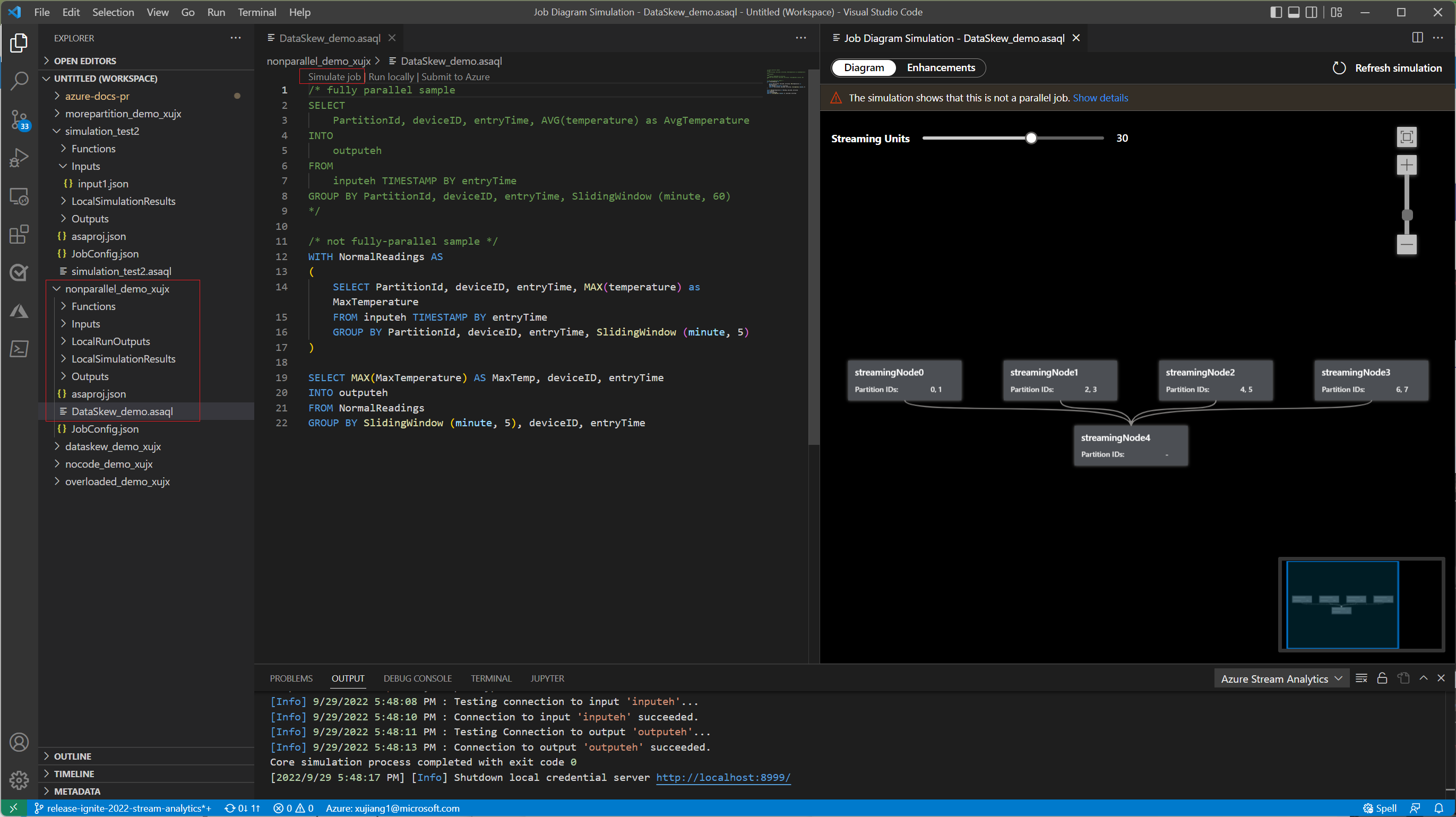
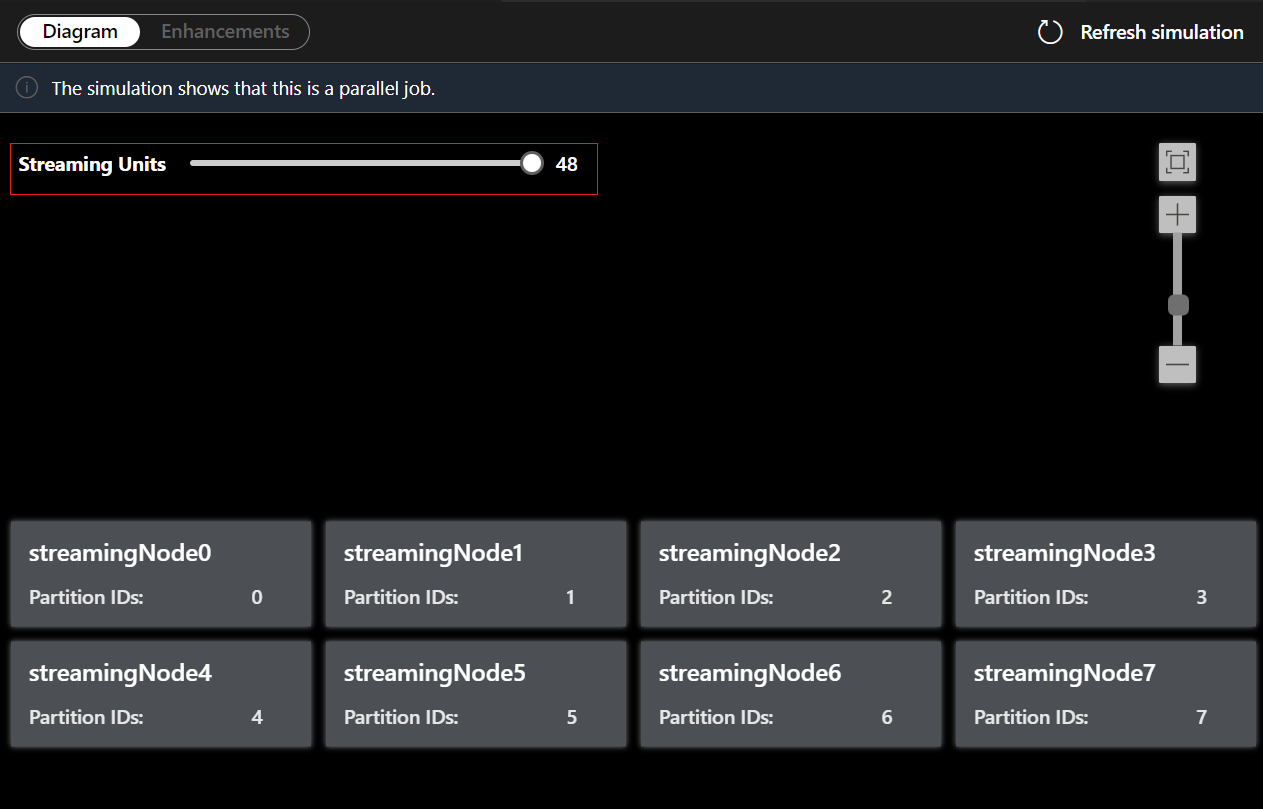
Sob a guia Diagrama, aparece o número de nós de streaming alocados para o trabalho e o número de partições em cada nó de streaming. A captura de tela a seguir é um exemplo de um trabalho não paralelo em que os dados estão fluindo entre nós.
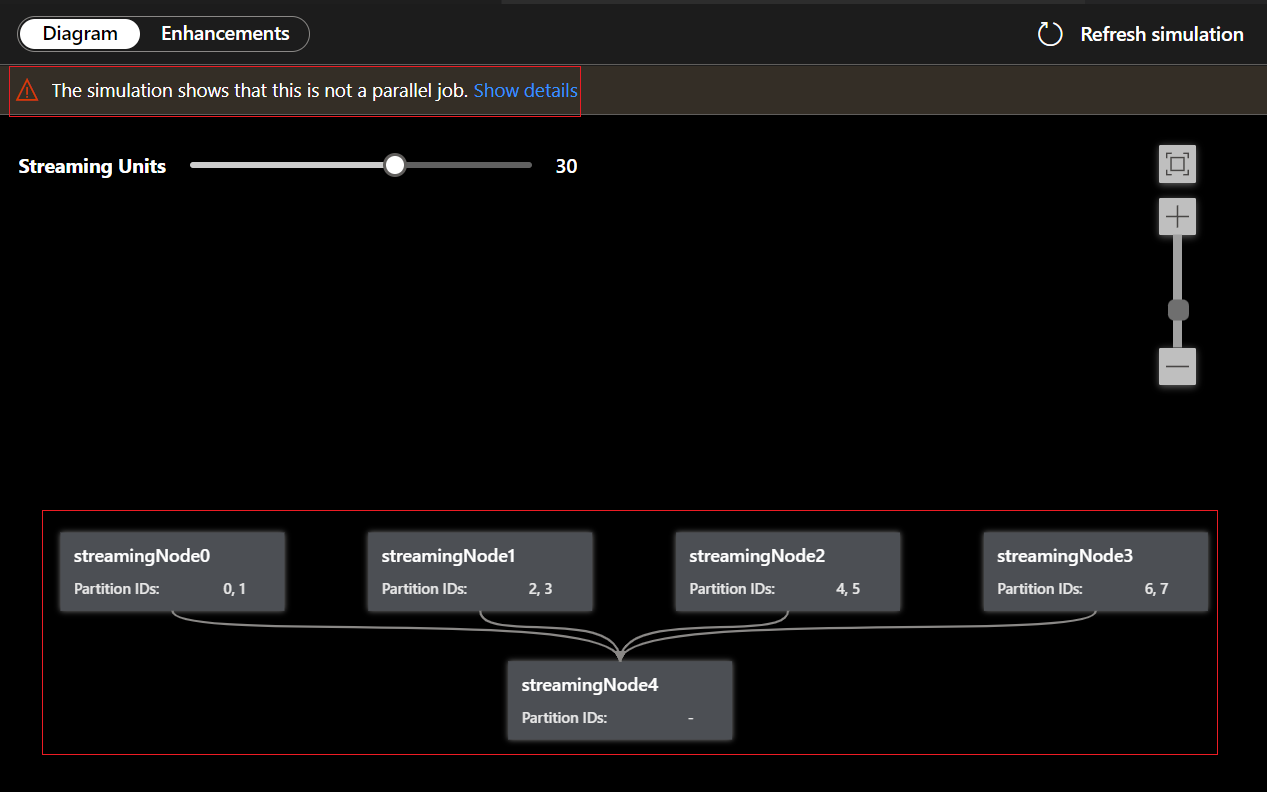
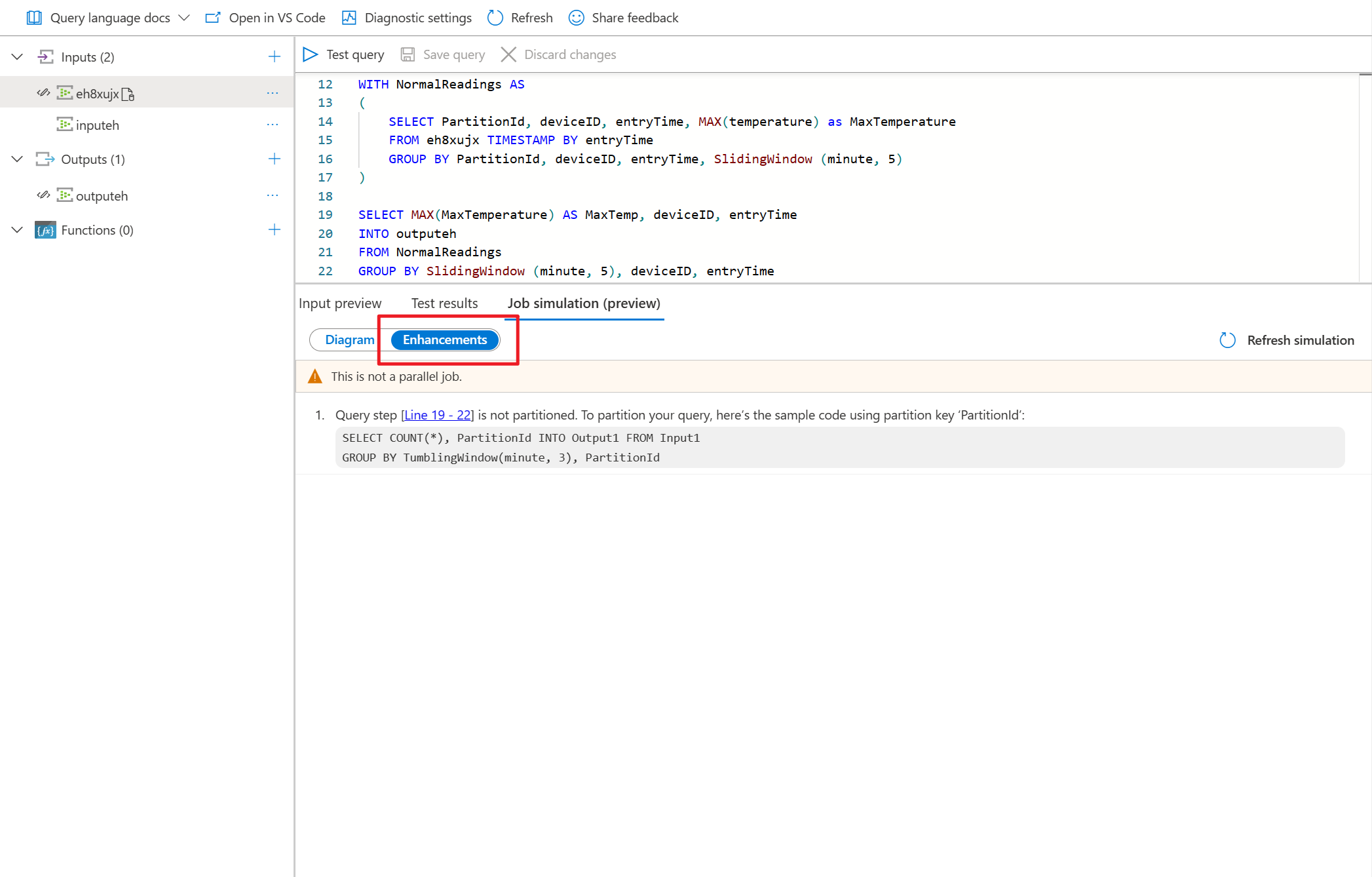
Como essa consulta NÃO está em paralelo, você pode selecionar a guia Aprimoramentos e exibir sugestões sobre como aprimorar a consulta.
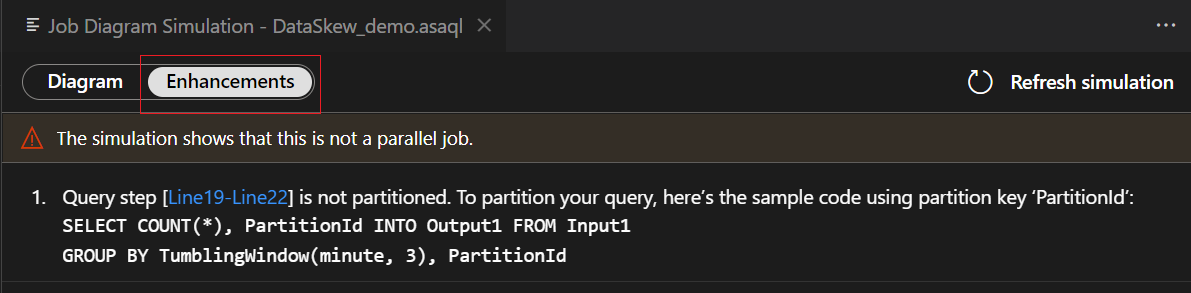
Selecione a etapa de consulta na lista de aprimoramentos. Você verá que as linhas correspondentes estão realçadas e você pode editar a consulta de acordo com as sugestões.

Observação
Estas são sugestões de edição para melhorar o paralelismo de consulta. No entanto, se você estiver usando a função de agregação entre todas as partições, ter uma consulta paralela pode não ser aplicável aos seus cenários.
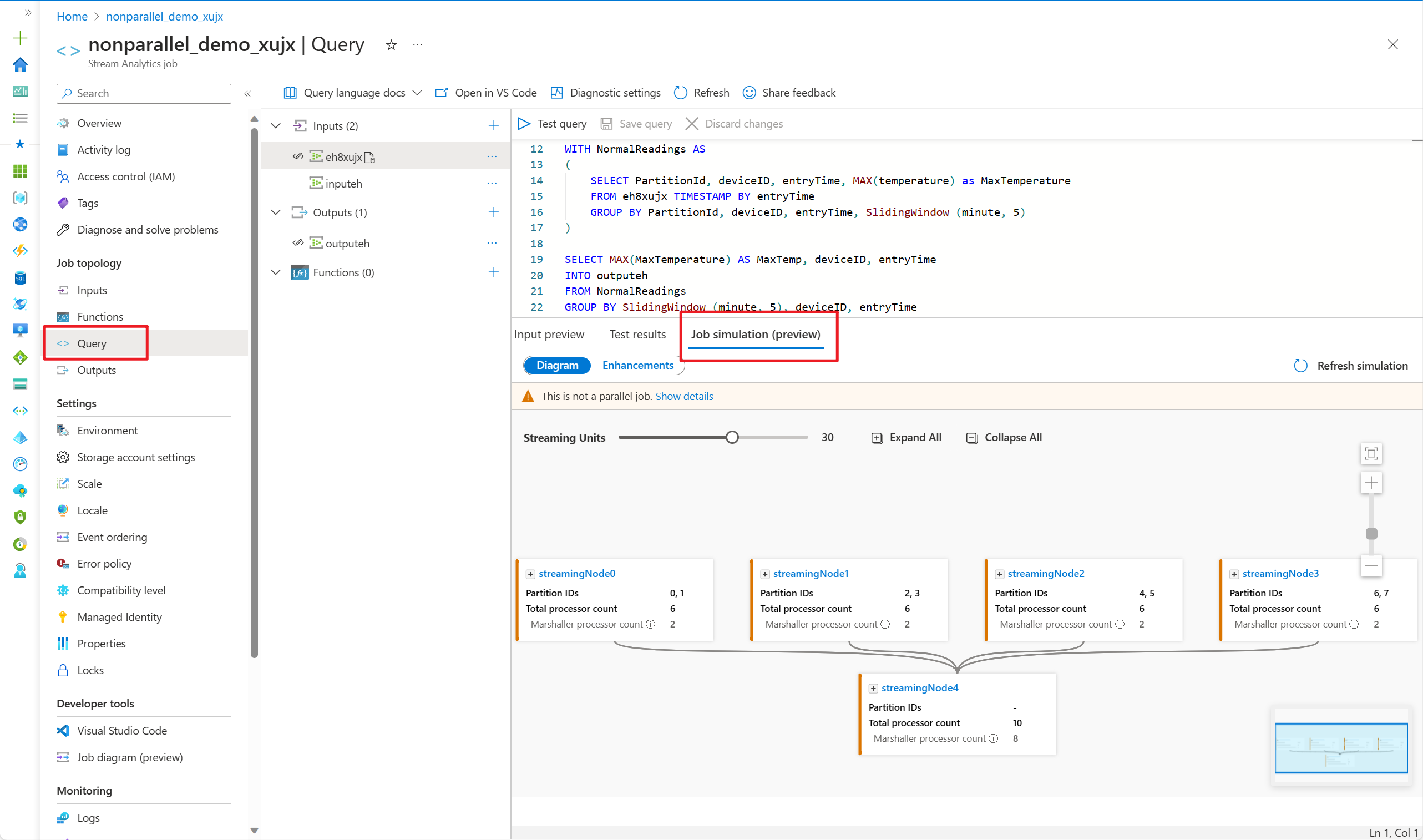
Para este exemplo, adicione PartitionId à linha nº 22 e salve a alteração. Em seguida, você poderá usar a opção Atualizar simulação para obter o novo diagrama.
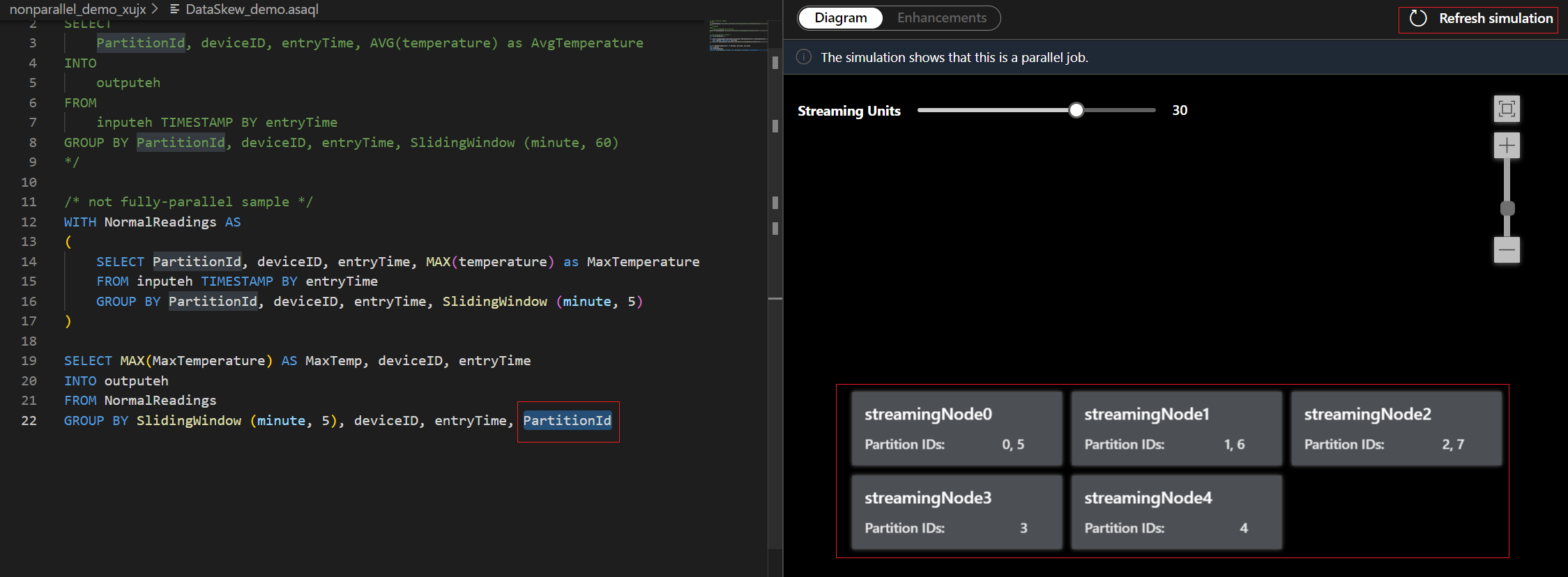
Você também pode ajustar as Unidades de Streaming para estimular a forma como os nós de streaming são alocados com diferentes SUs. Isso lhe dá uma ideia de quantas SUs você precisa para lidar com sua carga de trabalho.






Usar a simulação de trabalho no portal do Azure
- Vá para o editor de consultas no portal do Azure e selecione Simulação de trabalho no painel inferior. Ele simula o trabalho que executa a topologia com base em sua consulta e unidades de streaming predefinidas.
- Selecione Aprimoramentos para exibir as sugestões para melhorar o paralelismo de consulta.
- Ajuste as unidades de streaming para ver quantas SUs você precisava para lidar com a carga de trabalho.
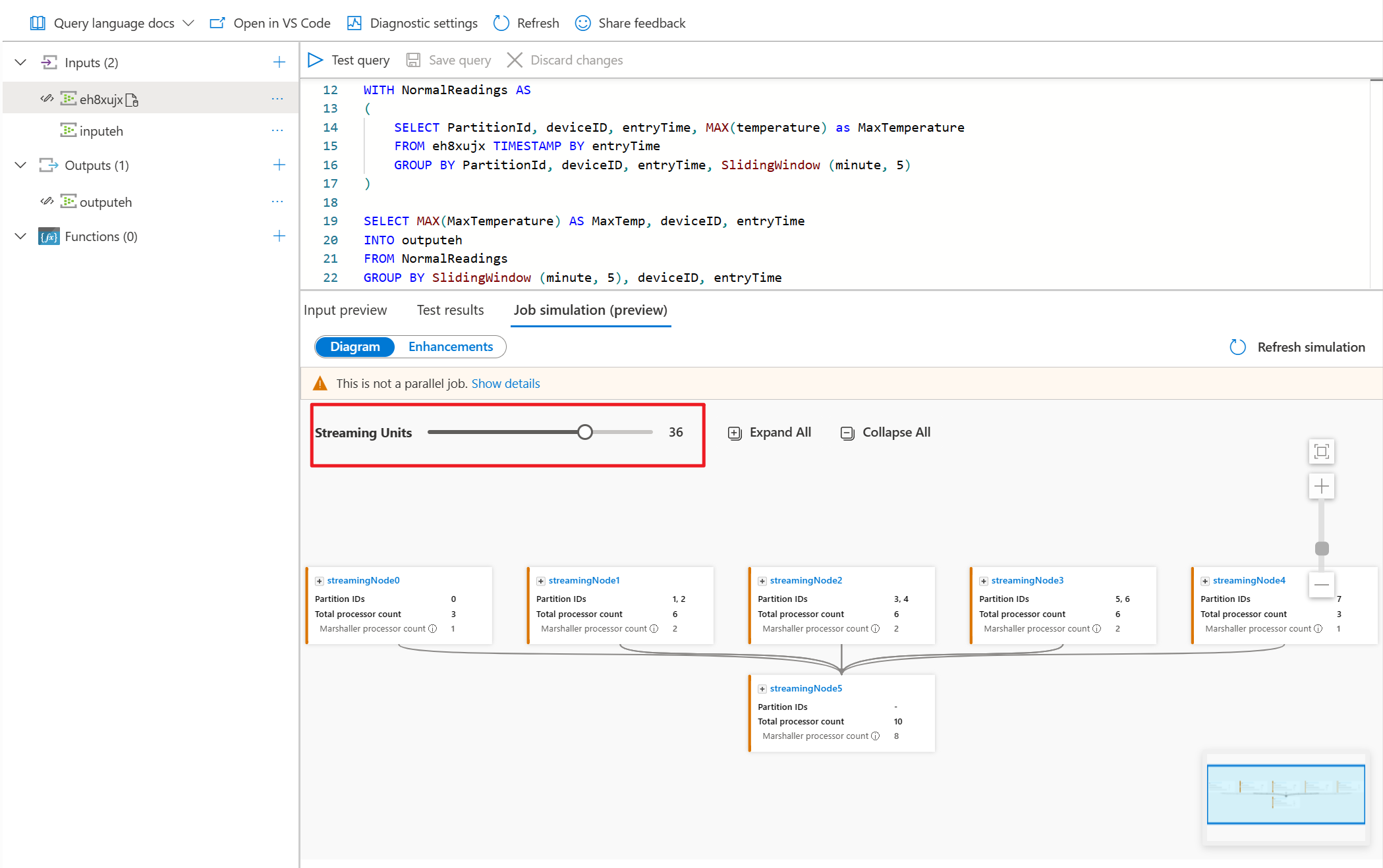



Diagrama no nível do processador
Depois de ajustar as unidades de streaming para simular a topologia do seu trabalho, você poderá expandir qualquer um dos nós de streaming para observar como seus dados estão sendo processados no nível do processador.

O diagrama no nível do processador permite que você:
- observe como as partições de entrada são alocadas e processadas em cada nó de streaming.
- descubra qual é a Deslocamento de tempo para cada processador de computação.
- forneça informações sobre se os processadores de Entrada e Saída estão alinhados em paralelo.
Para mapear o processador com a etapa de consulta, selecione duas vezes no diagrama. Esse recurso ajuda você a localizar as etapas de consulta que fazem a agregação.

Sugestões de aprimoramento
Estas são as explicações de Aprimoramentos:
| Tipo | Significado |
|---|---|
| Partição personalizada sem suporte | Altere a chave de partição 'xxx' de entrada para 'xxx'. |
| Número de partições não correspondentes | A entrada e a saída devem ter o mesmo número de partições. |
| Chaves de partição não correspondentes | A entrada, a saída e cada etapa de consulta devem usar a mesma chave de partição. |
| Número de partições de entrada não correspondentes | Todas as entradas devem ter o mesmo número de partições. |
| Chaves de partição de entrada não correspondentes | Todas as entradas devem usar a mesma chave de partição. |
| Baixo nível de compatibilidade | Atualizar o CompatibilityLevel no arquivo JobConfig.json. |
| Chave de partição de saída não encontrada | Você precisa usar a chave de partição especificada para a saída. |
| Partição personalizada sem suporte | Você só pode usar chaves de partição predefinidas. |
| Etapa de consulta que não usa partição | A consulta não está usando cláusulas PARTITION BY. |
Próximas etapas
Se você quiser saber mais sobre paralelização de consulta e diagrama de trabalho, confira estes tutoriais: