Usar os recursos estendidos do servidor de histórico de Apache Spark para depurar e diagnosticar aplicativos Spark
Este artigo mostra como usar os recursos estendidos do servidor de histórico de Apache Spark para depurar e diagnosticar aplicativos Spark concluídos ou em execução. A extensão inclui uma guia dados, uma guia Grafo e uma guia diagnóstico. Na guia dados, você pode verificar os dados de entrada e de saída do trabalho do Spark. Na guia Grafo, você pode verificar o fluxo de dados e reproduzir o grafo do trabalho. Na guia diagnóstico, você pode consultar os recursos de distorção de dados, distorção de tempo e análise de uso de executor.
Obter acesso ao servidor de histórico do Spark
O servidor de histórico do Spark é a interface do usuário da Web para aplicativos Spark concluídos e em execução. Você pode abri-lo do portal do Azure ou de uma URL.
Abra a interface do usuário da Web do servidor de histórico do Spark no portal do Azure
No portal do Azure, abra o cluster Spark. Para obter mais informações, consulte Listar e mostrar clusters.
Em Painéis de cluster, selecione Servidor de histórico do Spark. Quando solicitado, insira as credenciais de administrador para o cluster Spark.
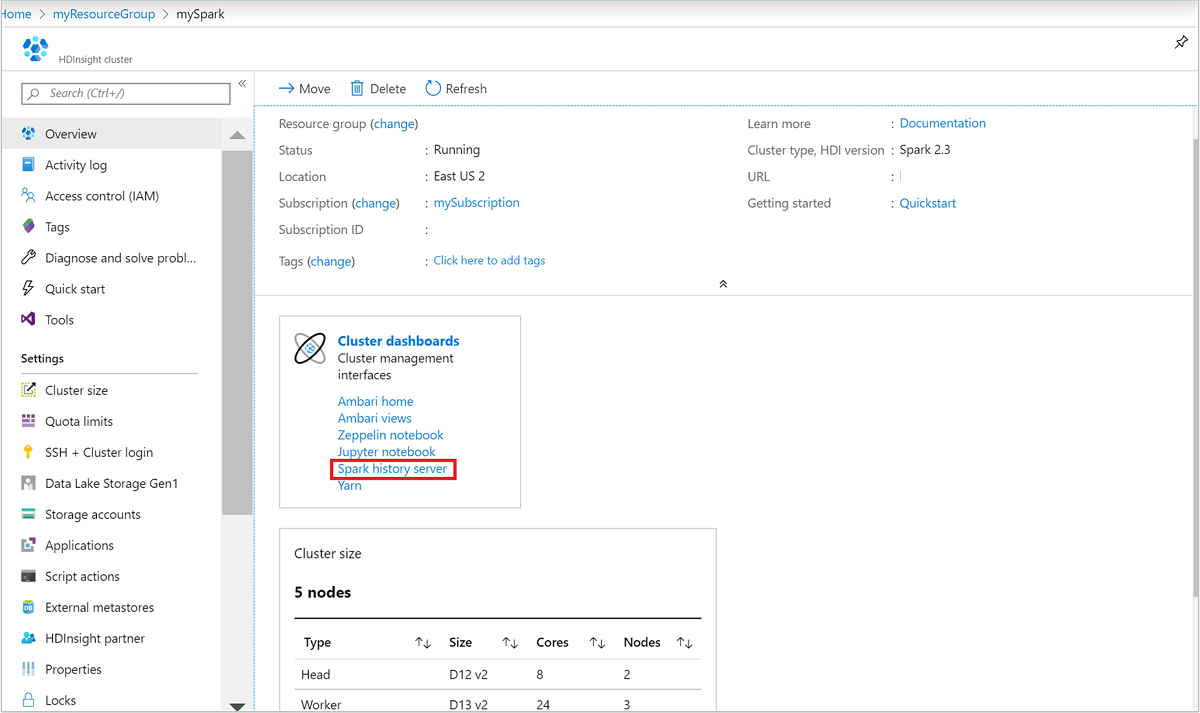 no portal do Azure." border="true":::
no portal do Azure." border="true":::
Abrir a interface do usuário da Web do servidor de histórico do Spark usando uma URL
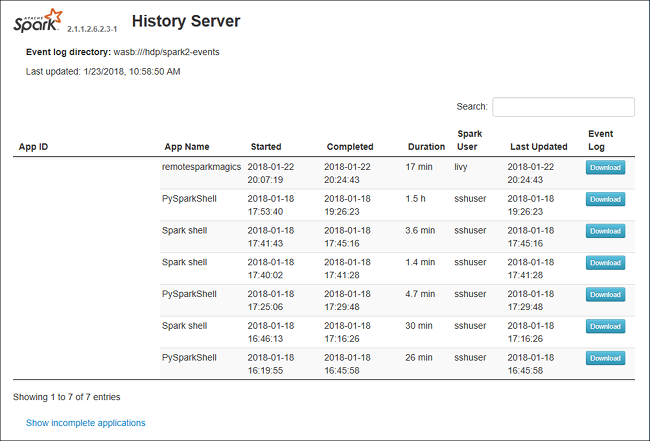
Abra o servidor de histórico do Spark navegando até https://CLUSTERNAME.azurehdinsight.net/sparkhistory, em que CLUSTERNAME é o nome do cluster Spark.
A interface do usuário da Web do servidor de histórico do Spark pode ser semelhante a esta imagem:
Usar a guia dados no servidor de histórico do Spark
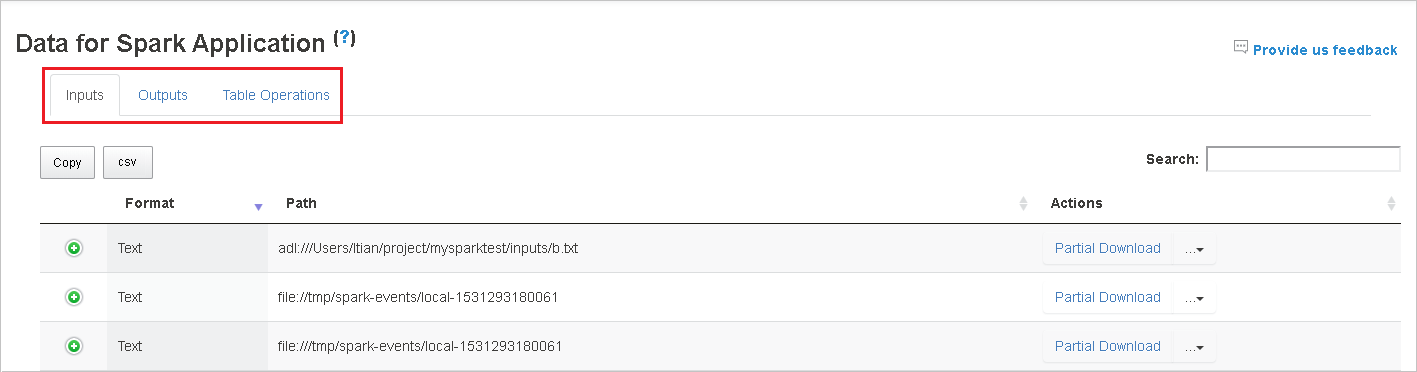
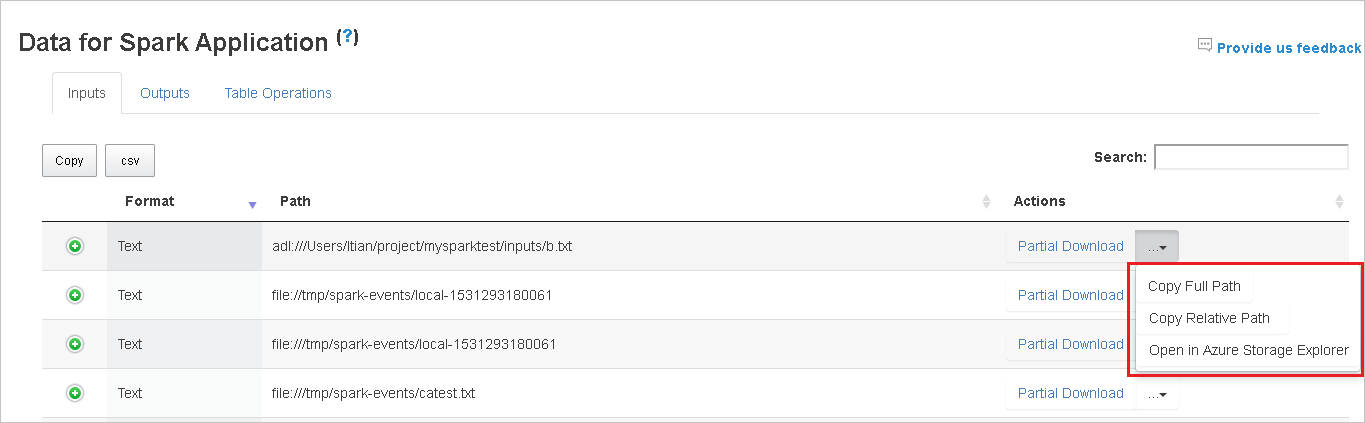
Selecione a ID do trabalho e, em seguida, selecione dados no menu de ferramentas para ver a exibição de dados.
Examine as entradas, as saídas e as operações de tabelas selecionando as guias as guias individuais.
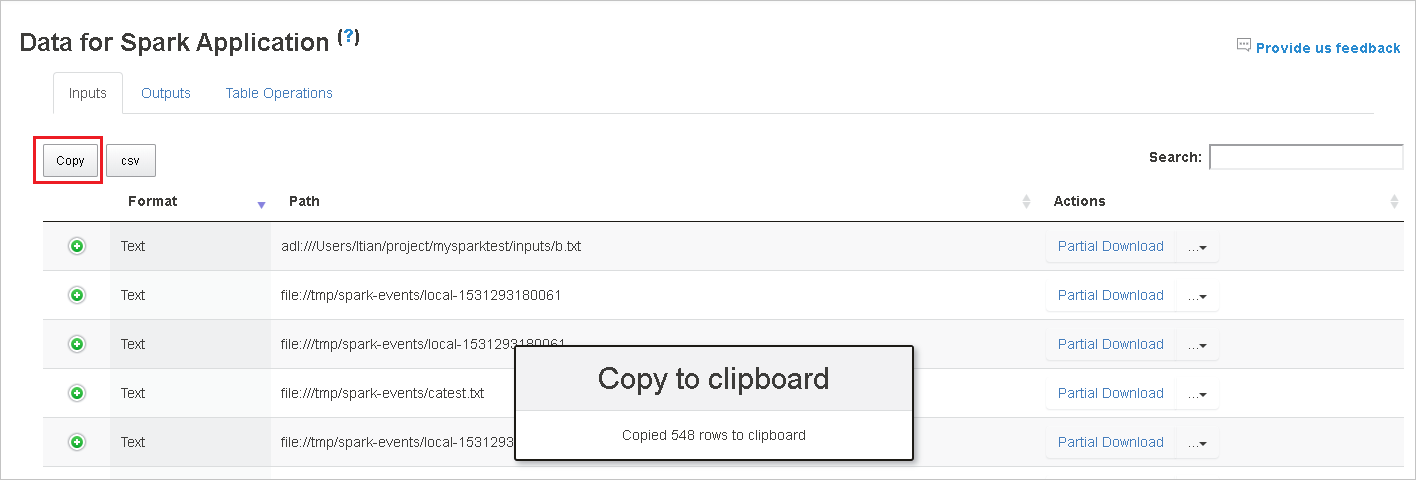
Copie todas as linhas selecionando o botão copiar.
Salve todos os dados como um arquivo .csv selecionando o botão CSV.
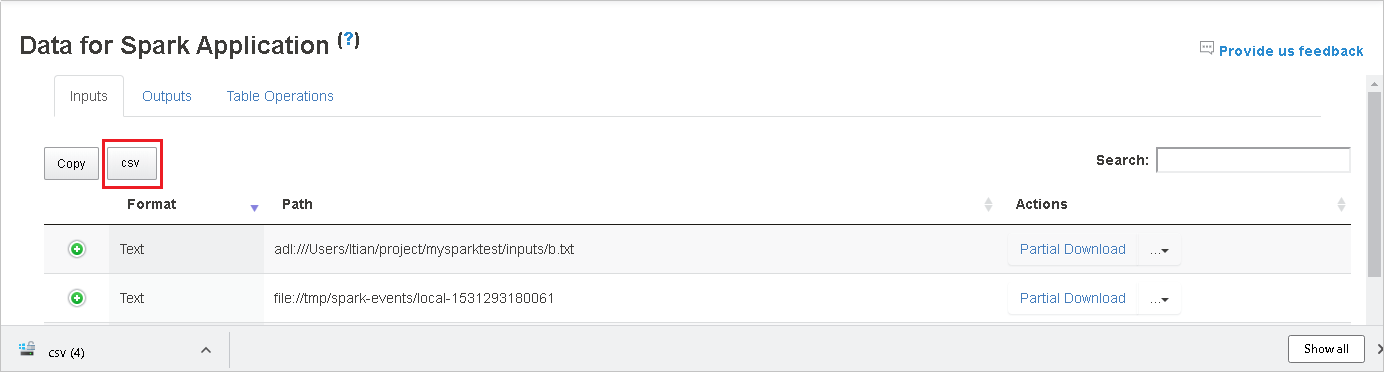
Pesquise os dados inserindo palavras-chave no campo de pesquisa. Os resultados da pesquisa serão exibidos imediatamente.
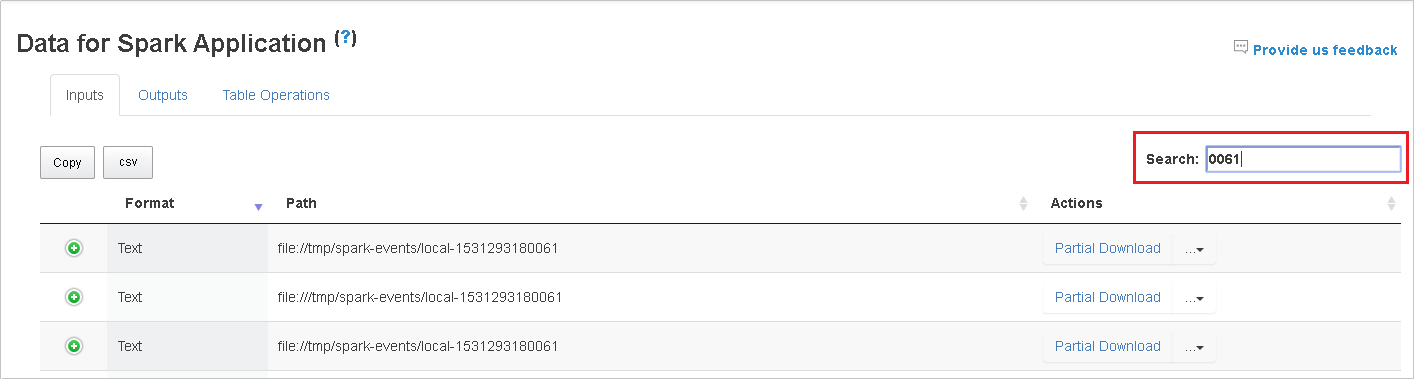
Selecione o cabeçalho da coluna para classificar a tabela. Selecione o sinal de adição para expandir uma linha para mostrar mais detalhes. Selecione o sinal de menos para recolher uma linha.
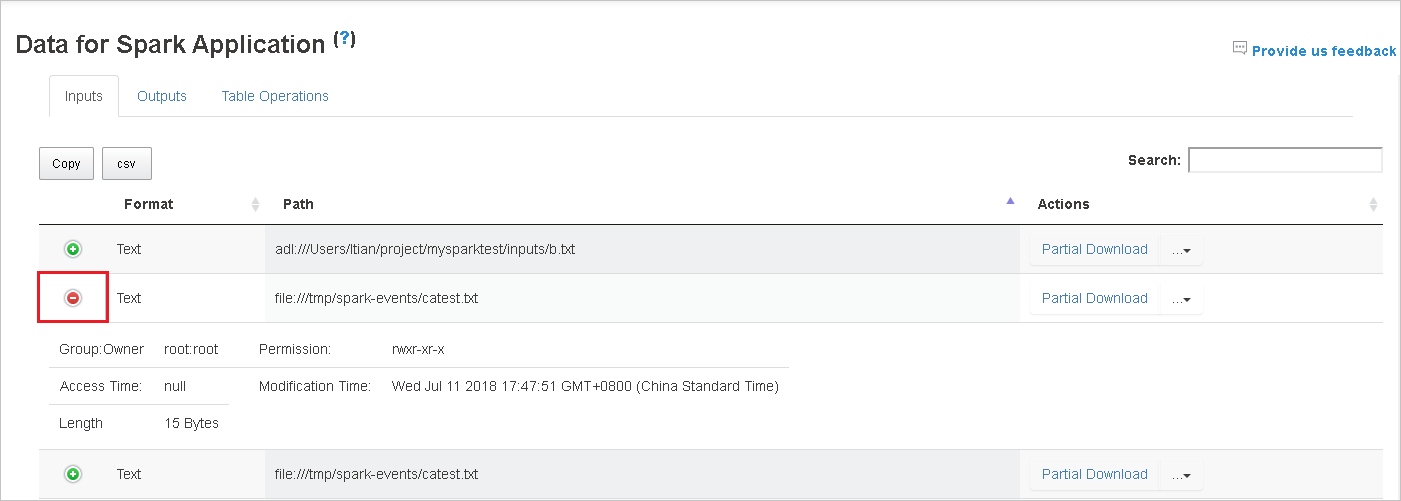
Baixe um único arquivo selecionando o botão download parcial à direita. O arquivo selecionado será baixado localmente. Se o arquivo não existir mais, isso abrirá uma nova guia para mostrar as mensagens de erro.
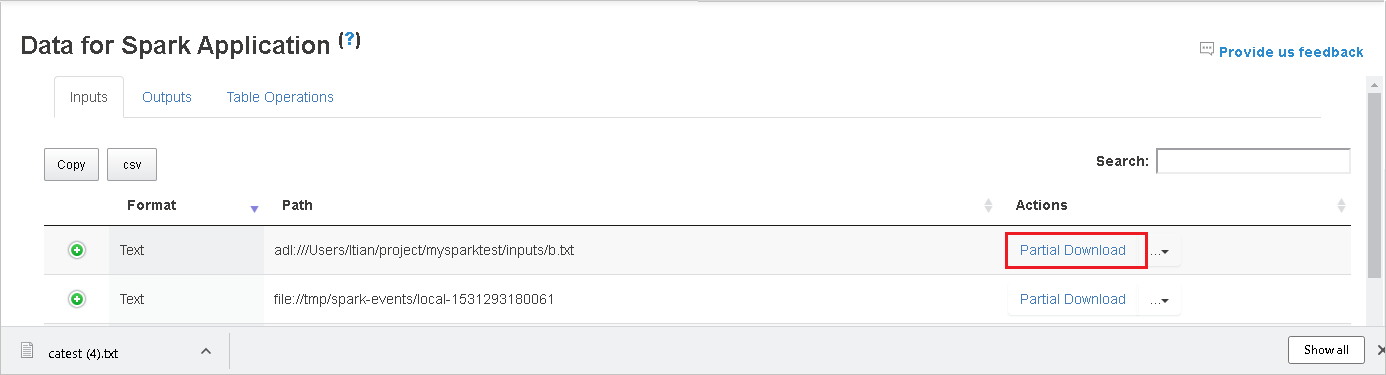
Copie um caminho completo ou um caminho relativo selecionando a opção Copiar caminho completo ou Copiar caminho relativo, que se expande no menu de download. Para arquivos Azure Data Lake Storage, selecione abrir no Gerenciador de Armazenamento do Azure para iniciar o Gerenciador de Armazenamento do Azure e localizar a pasta de pois de entrar.
Se houver muitas linhas a serem exibidas em uma única página, selecione os números de página na parte inferior da tabela para navegar.

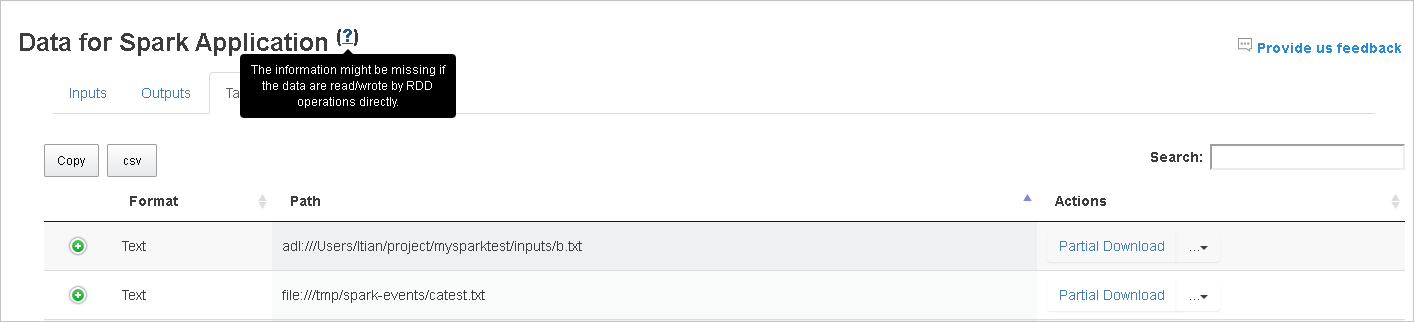
Para obter mais informações, passe o mouse sobre ou selecione o ponto de interrogação ao lado de dados para o aplicativo Spark para mostrar a dica de ferramenta.
Para enviar comentários sobre problemas, selecione fornecer comentários.
Usar a guia grafo no servidor de histórico do Spark
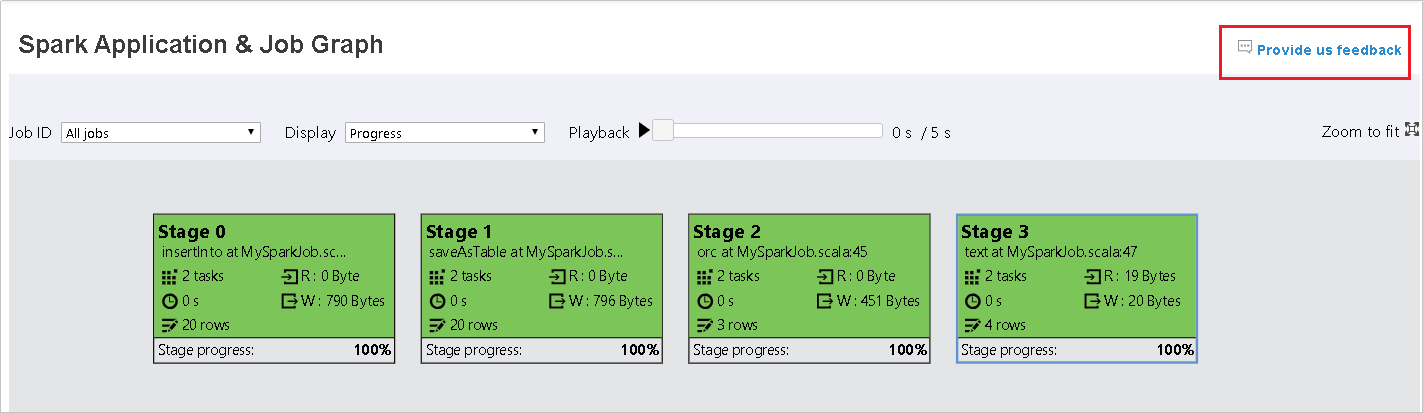
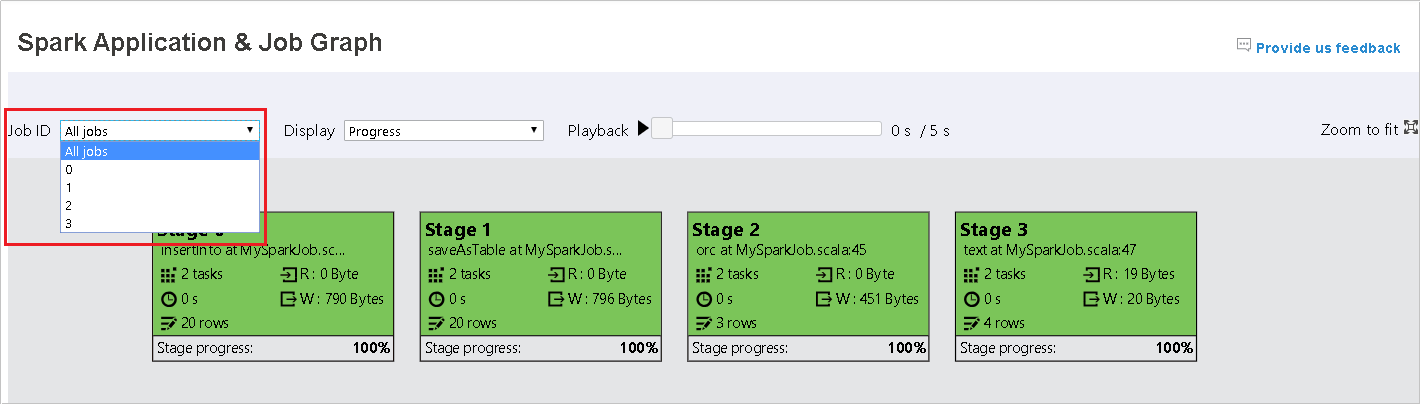
Selecione a ID do trabalho e, em seguida, selecione grafo no menu de ferramentas para ver o grafo do trabalho. Por padrão, o grafo mostrará todos os trabalhos. Filtre os resultados usando o menu suspenso ID do trabalho.
O progresso é selecionado por padrão. Verifique o fluxo de dados selecionando ler ou gravado no menu suspenso exibir.
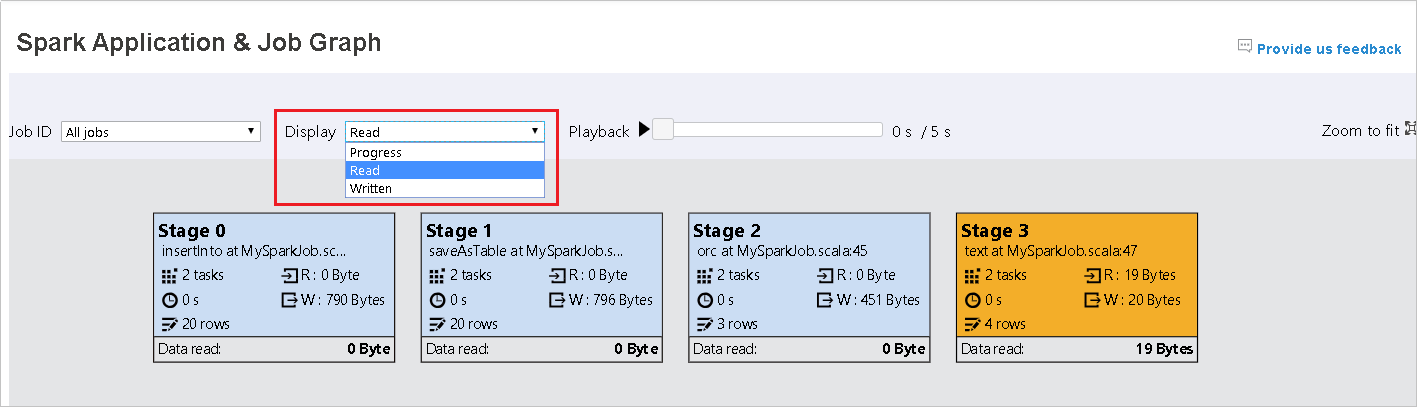
A cor do plano de fundo de cada tarefa corresponde a um mapa de calor.

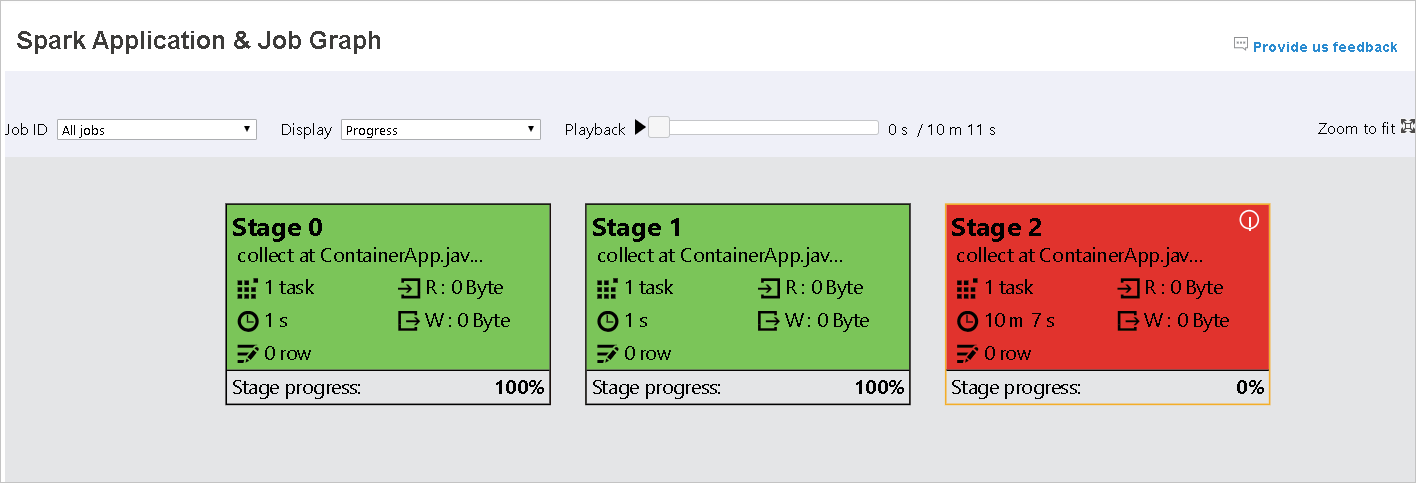
Color DESCRIÇÃO Verde o trabalho foi concluído com êxito. Laranja A tarefa falhou, mas isso não afeta o resultado final do trabalho. Essas tarefas têm instâncias duplicadas ou repetidas que poderão ser bem-sucedidas mais tarde. Azul a tarefa está em execução. Branca a tarefa está aguardando para ser executada ou a fase foi ignorada. Vermelho a tarefa falhou. 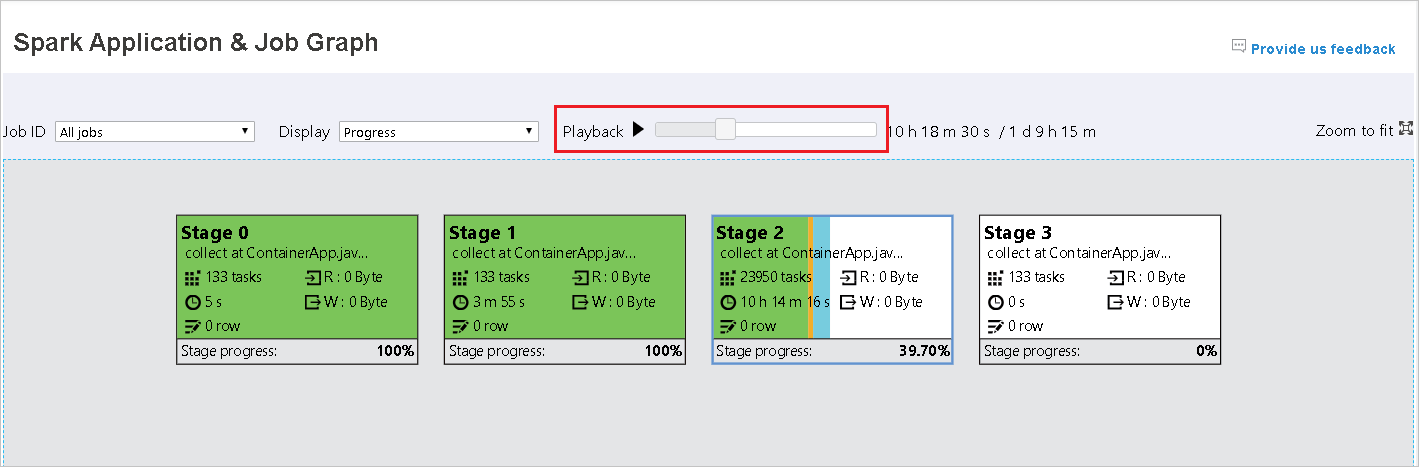
As fases ignoradas são exibidas em branco.
Observação
A reprodução está disponível para trabalhos concluídos. Selecione o botão de reprodução para executar o trabalho de volta. Pare o trabalho a qualquer momento selecionando o botão parar. Quando um trabalho é reproduzido, cada tarefa exibirá seu status por cor. Não há suporte para reprodução de trabalhos incompletos.
Role para ampliar e reduzir o grafo do trabalho ou selecione aplicar zoom para ajustar para fazer com que ele se ajuste à tela.
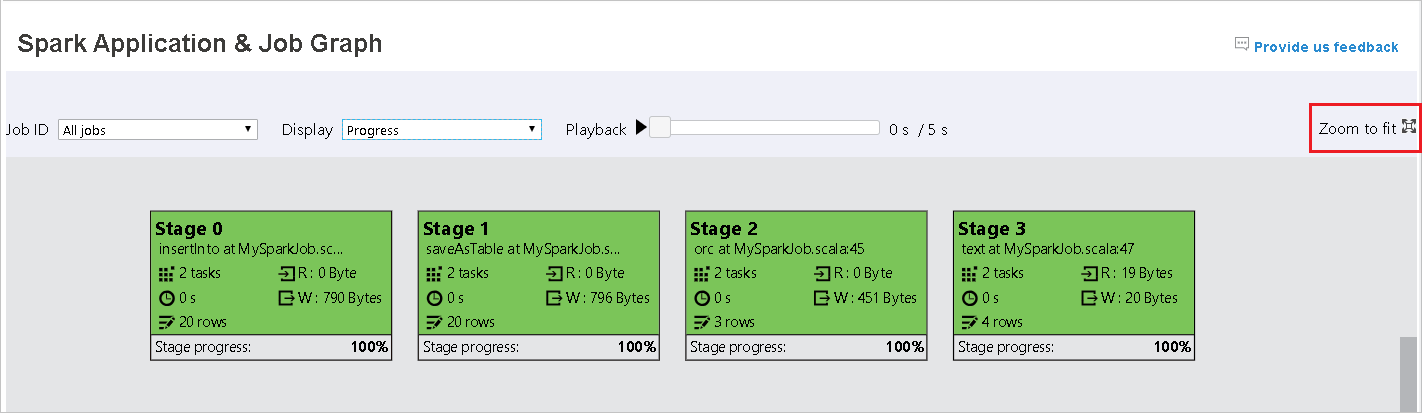
Quando as tarefas falharem, passe o mouse sobre o nó do grafo para ver a dica de ferramenta e selecione a fase para abri-lo em uma nova página.
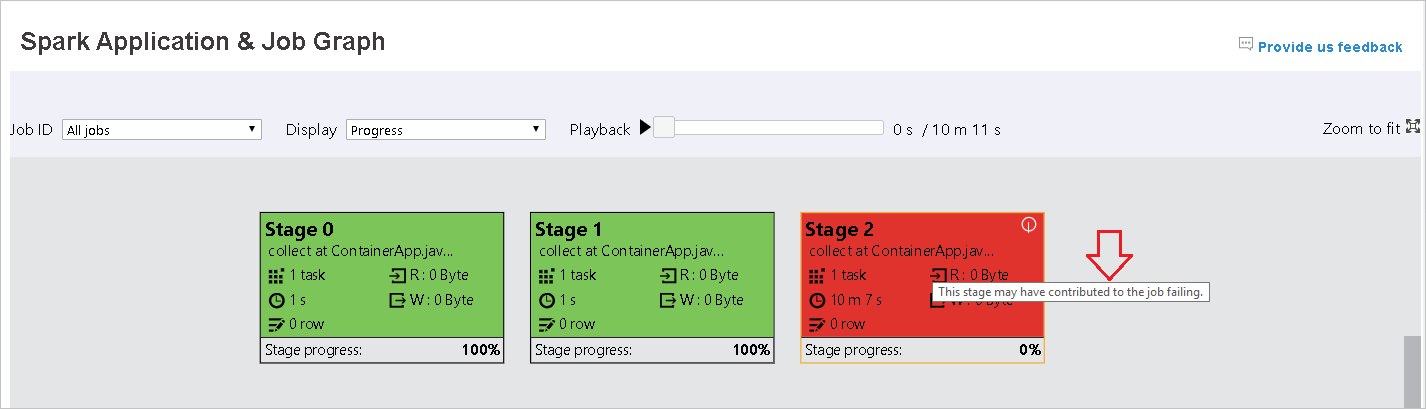
No aplicativo Spark & página grafo de trabalho, as fases exibirão dicas de ferramenta e ícones pequenos se as tarefas atenderem a essas condições:
Distorção de dados: tamanho da leitura de dados tamanho médio da leitura de todas as tarefas nesta fase * 2 >e tamanho de leitura de dados > 10 MB.
Distorção de tempo: tempo de execução > tempo médio de execução de todas as tarefas nesta fase * 2 e tempo de execução > 2 minutos.
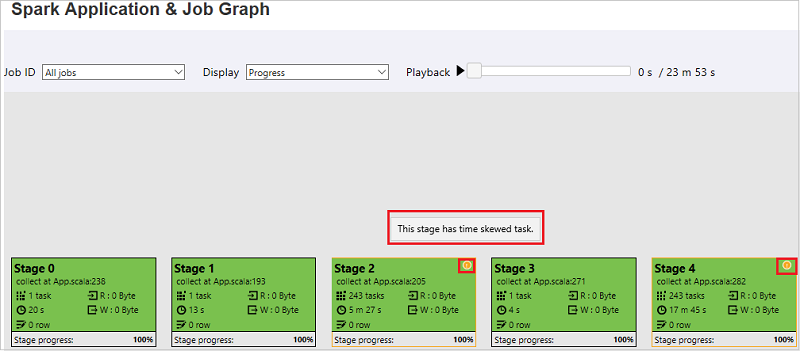
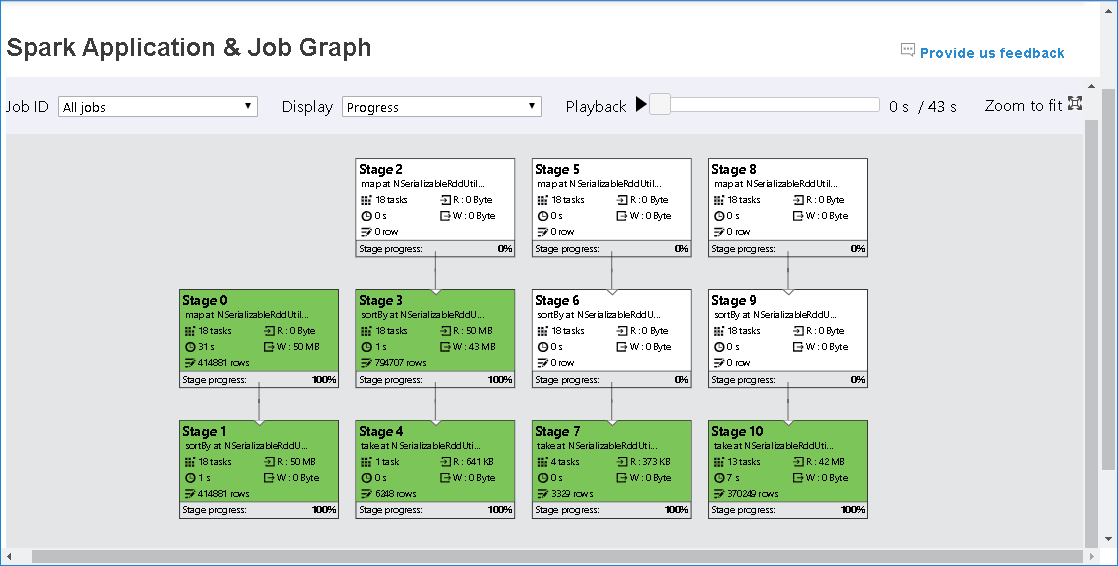
O nó do grafo do trabalho exibirá as seguintes informações sobre cada fase:
ID
Nome ou descrição
Número total de tarefas
Leitura de dados: a soma do tamanho de entrada e o tamanho de leitura em ordem aleatória
Gravação de dados: a soma do tamanho de saída e o tamanho de gravação de ordem aleatória
Tempo de execução: o tempo entre a hora de início da primeira tentativa e a hora de conclusão da última tentativa
Contagem de linhas: a soma dos registros de entrada, registros de saída, registros de leitura aleatória e registros de gravação aleatória
Progresso
Observação
Por padrão, o nó do grafo do trabalho exibirá informações da última tentativa de cada fase (exceto pelo tempo de execução da fase). Mas durante a reprodução, o nó do grafo de trabalho mostrará informações sobre cada tentativa.
Observação
Para tamanhos de leitura de dados e gravação de dados, usamos 1MB = 1000 KB = 1000 * 1000 bytes.
Envie comentários sobre problemas selecionando fornecer comentários.
Usar a guia diagnóstico no servidor de histórico do Apache Spark
Selecione a ID do trabalho e, em seguida, selecione diagnóstico no menu de ferramentas para ver a exibição de diagnóstico do trabalho. A guia diagnóstico inclui distorção de dados, distorção de tempo e análise de uso do executor.
Examine a distorção de dados, a distorção de tempo e a análise de uso do executor selecionando as respectivas guias.
Distorção de dados
Selecione a guia distorção de dados. As tarefas distorcidas correspondentes são exibidas com base nos parâmetros especificados.
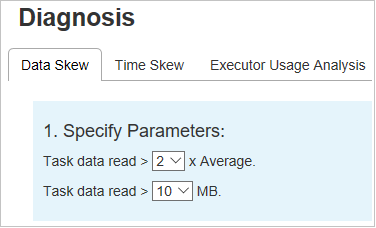
Especificar parâmetros
A seção especificar parâmetros exibe os parâmetros, que são usados para detectar a distorção de dados. A regra padrão é: a leitura dos dados da tarefa é maior que três vezes a média da leitura de dados da tarefa lida e a leitura de dados da tarefa é superior a 10 MB. Se quiser definir sua regra para tarefas com distorção, você poderá escolher seus parâmetros. As seções distorção e gráfico de distorção serão atualizadas de acordo.
Fase distorcida
A seção fase distorcida exibe as fases que têm tarefas distorcidas que atendem aos critérios especificados. Se houver mais de uma tarefa distorcida em uma fase, a seção fase distorcida exibirá apenas a tarefa mais distorcida (ou seja, os maiores dados para distorção de dados).
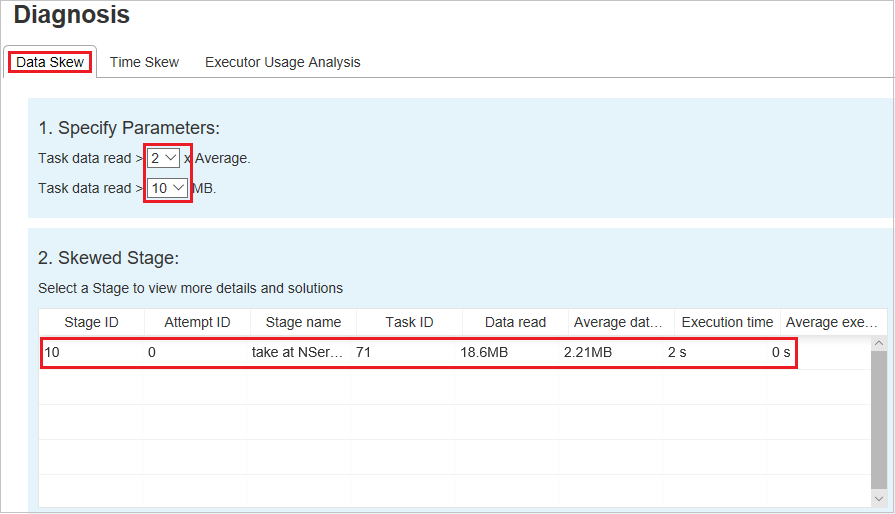
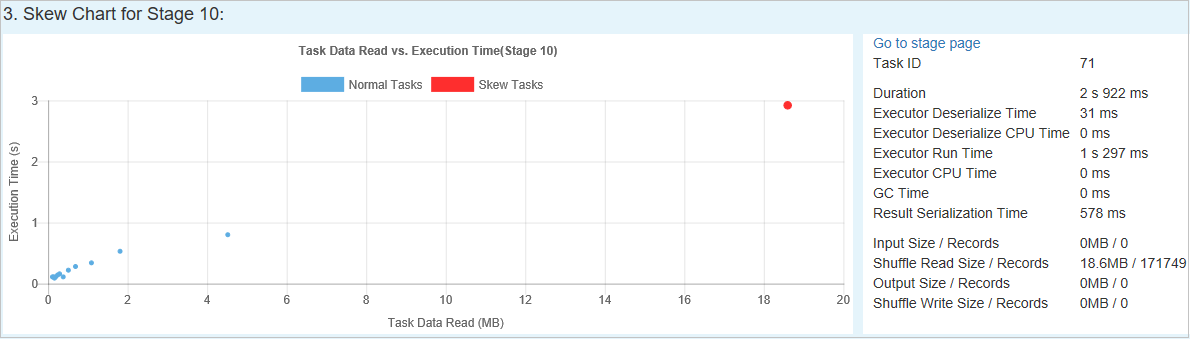
Gráfico de distorção
Quando você seleciona uma linha na tabela de fase de distorção, o gráfico de distorção exibe mais detalhes de distribuições de tarefas com base de leitura de dados e no tempo de execução. As tarefas distorcidas são marcadas em vermelho e as normais são marcadas em azul. Para não afetar o desempenho, o gráfico exibe até 100 tarefas de amostra. Os detalhes da tarefa são exibidos no painel inferior direito.
Distorção de tempo
A guia Distorção de Tempo exibe tarefas distorcidas com base no tempo de execução da tarefa.
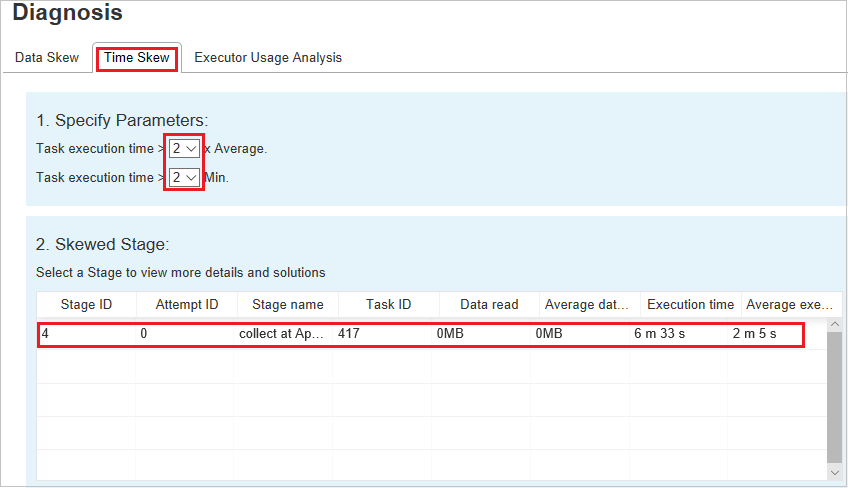
Especificar parâmetros
A seção especificar parâmetros exibe os parâmetros, que são usados para detectar a distorção de tempo. A regra padrão é: o tempo de execução da tarefa é maior do que três vezes o tempo médio de execução e o tempo de execução da tarefa é maior que 30 segundos. Você pode alterar os parâmetros com base em suas necessidades. A fase distorcida e o gráfico de distorção exibem as informações sobre as fases e as tarefas correspondentes, assim como na guia distorção de dados.
Quando você seleciona distorção de tempo, o resultado filtrado é exibido na seção fase distorcida, de acordo com os parâmetros definidos na seção especificar parâmetros. Quando você seleciona um item na seção de fase distorcida, o gráfico correspondente é rascunho na terceira seção e os detalhes da tarefa são exibidos no painel inferior direito.
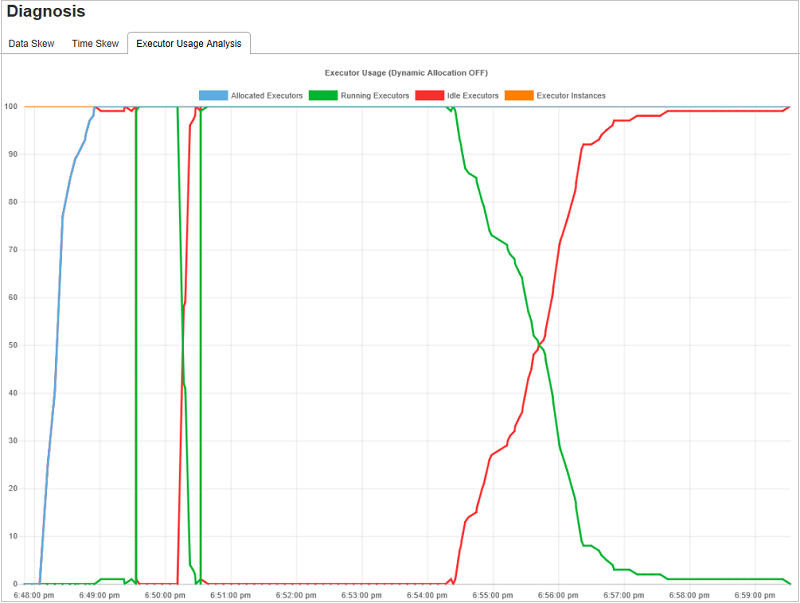
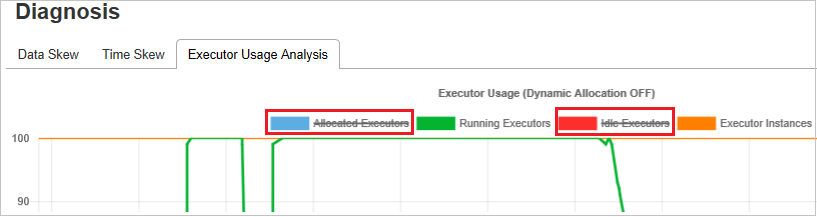
Gráficos de análise de uso do executor
O grafo de uso do executor exibe a alocação real do executor do trabalho e o status de execução.
Quando você seleciona aálise de uo do executor, quatro curvas diferentes sobre o uso do executor serão traçadas: executores alocados, executores em execução, executores ociosos e máximo de instâncias de executor. Cada executor adicionado ou o evento removido do executoraumentará ou diminuirá os executores alocados. Você pode verificar a linha do tempo do evento na guiatrabalhos para obter mais comparações.
Selecione o ícone colorido para selecionar ou desmarcar o conteúdo correspondente em todos os rascunhos.
Perguntas frequentes
Como fazer reverter para a versão da Comunidade?
Para reverter para a versão da comunidade, execute as seguintes etapas.
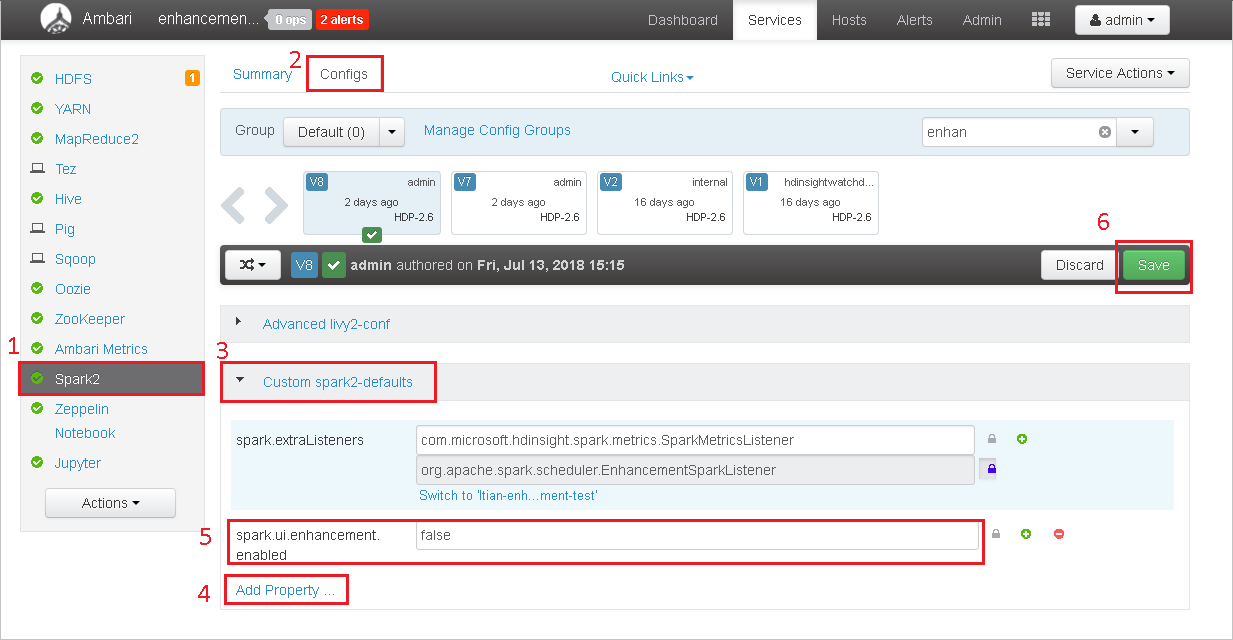
Abra o cluster no Ambari.
Navegue até configurações>do Spark2.
Selecione spark2-defaults personalizados.
Selecione adicionar propriedade... .
Adicione Spark. UI. Enhancement. Enabled = Falsee, em seguida, salve-o.
A propriedade define falsos agora.
Selecione Salvar para salvar a configuração.
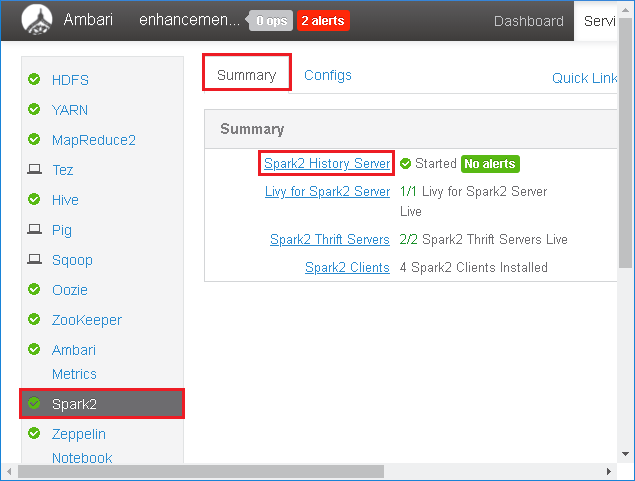
Selecione Spark2 no painel esquerdo. Em seguida, na guia resumo, selecione servidor de histórico Spark2.
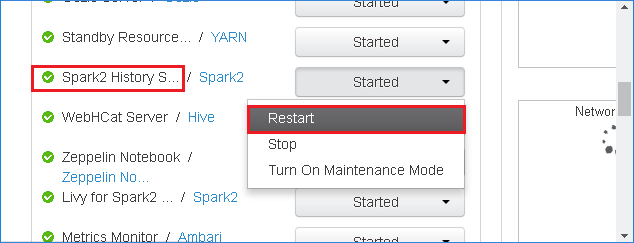
Para reiniciar o servidor de histórico do Spark, selecione o botão iniciado à direita do Spark2 History Servere, em seguida, selecione reiniciar no menu suspenso.
Atualize a interface do usuário da Web do servidor de histórico do Spark. Ele será revertido para a versão da Comunidade.
Como fazer carregar um evento do servidor de histórico do Spark para relatá-lo como um problema?
Se você encontrar um erro no servidor de histórico do Spark, execute as etapas a seguir para relatar o evento.
Baixe o evento selecionando baixar na interface do usuário da Web do servidor de histórico do Spark.
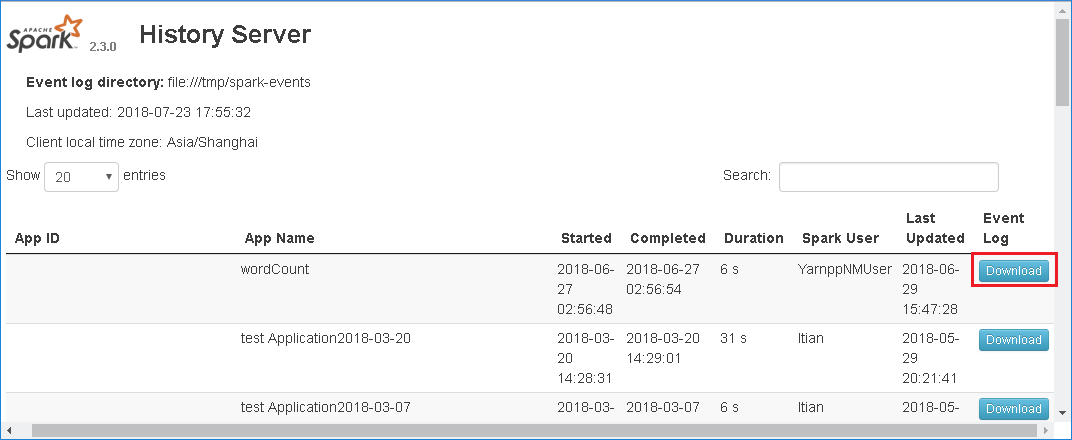
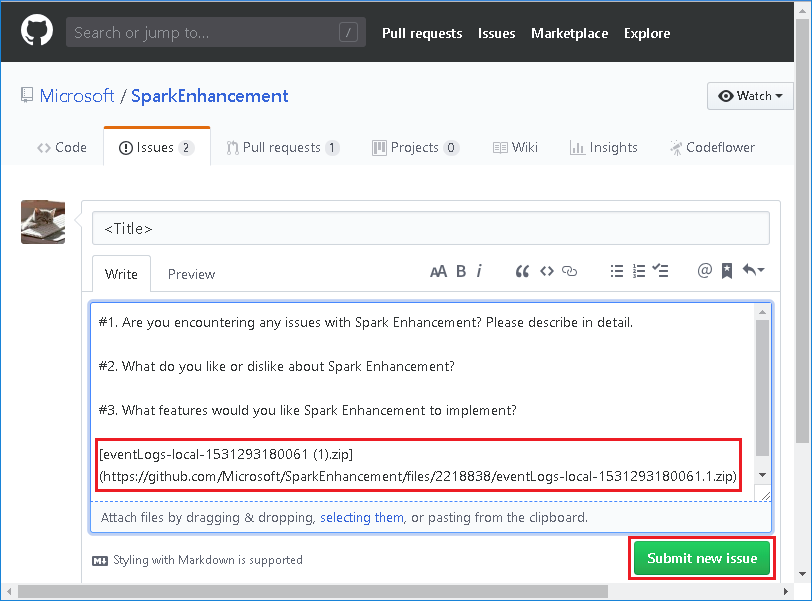
Selecione fornecer comentários no aplicativo Spark & página grafo de trabalho.
Forneça o título e uma descrição do erro. Em seguida, arraste o arquivo. zip para o campo de edição e selecione enviar novo problema.
Como fazer atualizar um arquivo. jar em um cenário de hotfix?
Se você quiser atualizar com um hotfix, use o seguinte script, que irá atualizar spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Uso
upgrade_spark_enhancement.sh https://${jar_path}
Exemplo
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Usar o arquivo de bash do portal do Azure
Inicie o portal do Azuree, em seguida, selecione o cluster.
Conclua uma ação de script com os parâmetros a seguir.
Propriedade Valor Tipo de script - Personalizado Nome UpgradeJar URI do script Bash https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shTipo(s) de nó Cabeçalho, função de trabalho Parâmetros https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar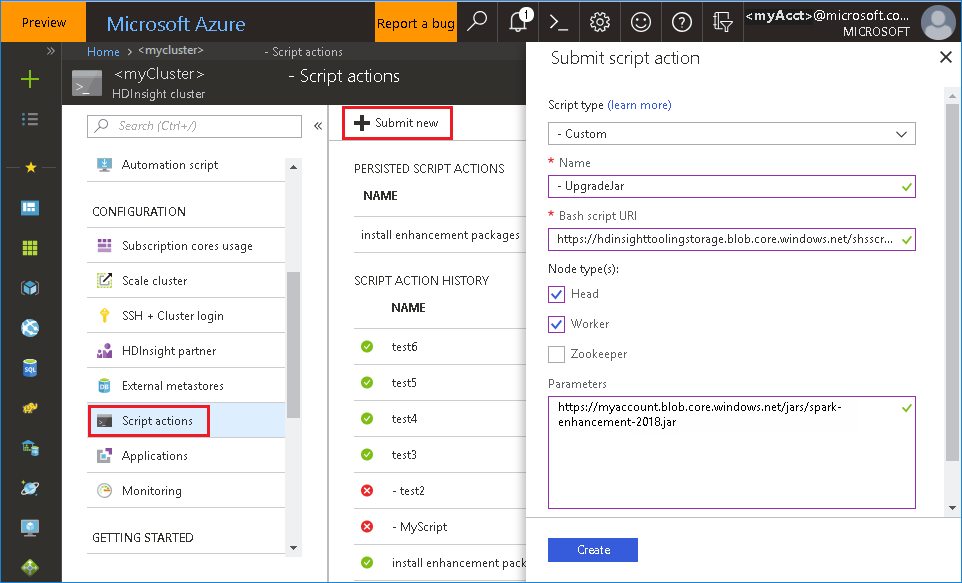
Problemas conhecidos
Atualmente, o servidor de histórico do Spark funciona apenas para Spark 2,3 e 2,4.
Os dados de entrada e saída que usam RDD não serão exibidos na guia dados.
Próximas etapas
- Gerenciar recursos para um cluster do Apache Spark no HDInsight
- Definir as configurações do Apache Spark
Sugestões
Se você tiver algum comentário ou surgir algum problema ao usar essa ferramenta, envie um email para (hdivstool@microsoft.com).