Conectar o Apache Flink® no HDInsight no AKS com os Hubs de Eventos do Azure para Apache Kafka®
Observação
Desativaremos o Microsoft Azure HDInsight no AKS em 31 de janeiro de 2025. Para evitar o encerramento abrupto das suas cargas de trabalho, você precisará migrá-las para o Microsoft Fabric ou para um produto equivalente do Azure antes de 31 de janeiro de 2025. Os clusters restantes em sua assinatura serão interrompidos e removidos do host.
Somente o suporte básico estará disponível até a data de desativação.
Importante
Esse recurso está atualmente na visualização. Os Termos de uso complementares para versões prévias do Microsoft Azure incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, confira Informações sobre a versão prévia do Azure HDInsight no AKS. Caso tenha perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para ver mais atualizações sobre a Comunidade do Azure HDInsight.
Um caso de uso bem conhecido para o Apache Flink é a análise de fluxo. A escolha popular de muitos usuários para usar os fluxos de dados, que são ingeridos usando o Apache Kafka. As instalações típicas do Flink e do Kafka começam com fluxos de eventos sendo enviados por push para o Kafka, que podem ser consumidos por trabalhos do Flink. Os Hubs de Eventos do Azure fornecem um ponto de extremidade do Apache Kafka em um hub de eventos, que permite que os usuários se conectem ao hub de eventos usando o protocolo Kafka.
Nesse artigo, exploramos como conectar os Hubs de Eventos do Azure com o Apache Flink no HDInsight no AKS e abordamos o seguinte
- Criar um namespace dos Hubs de Eventos
- Como criar um HDInsight no cluster do AKS com o Apache Flink
- Executar o produtor Flink
- Jar do Pacote para Apache Flink
- Envio e validação de trabalho
Criar namespace do Hubs de Eventos do Azure e um hub de eventos.
Para criar o namespace e os Hubs de Eventos dos Hubs de Eventos, consulte aqui


Configurar o cluster Flink no HDInsight no AKS
Ao usar o HDInsight existente no pool de clusters do AKS, você pode criar um cluster do Flink
Execute o produtor do Flink adicionando o bootstrap.servers e as informações
producer.configbootstrap.servers={YOUR.EVENTHUBS.FQDN}:9093 client.id=FlinkExampleProducer sasl.mechanism=PLAIN security.protocol=SASL_SSL sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="$ConnectionString" \ password="{YOUR.EVENTHUBS.CONNECTION.STRING}";Substitua
{YOUR.EVENTHUBS.CONNECTION.STRING}pela cadeia de conexão do seu namespace dos Hubs de Eventos. Para ver as instruções sobre como obter uma cadeia de conexão, consulteComo obter cadeia de conexão para Hubs de Eventos.Por exemplo,
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="Endpoint=sb://mynamespace.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=XXXXXXXXXXXXXXXX";
Empacotando o JAR para Flink
Pacote com.example.app;
package contoso.example; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.io.FileReader; import java.util.Properties; public class AzureEventHubDemo { public static void main(String[] args) throws Exception { // 1. get stream execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); ParameterTool parameters = ParameterTool.fromArgs(args); String input = parameters.get("input"); Properties properties = new Properties(); properties.load(new FileReader(input)); // 2. generate stream input DataStream<String> stream = createStream(env); // 3. sink to eventhub KafkaSink<String> sink = KafkaSink.<String>builder().setKafkaProducerConfig(properties) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("topic1") .setValueSerializationSchema(new SimpleStringSchema()) .build()) .build(); stream.sinkTo(sink); // 4. execute the stream env.execute("Produce message to Azure event hub"); } public static DataStream<String> createStream(StreamExecutionEnvironment env){ return env.generateSequence(0, 200) .map(new MapFunction<Long, String>() { @Override public String map(Long in) { return "FLINK PRODUCE " + in; } }); } }Adicione o trecho de código para executar o Produtor de Flink.
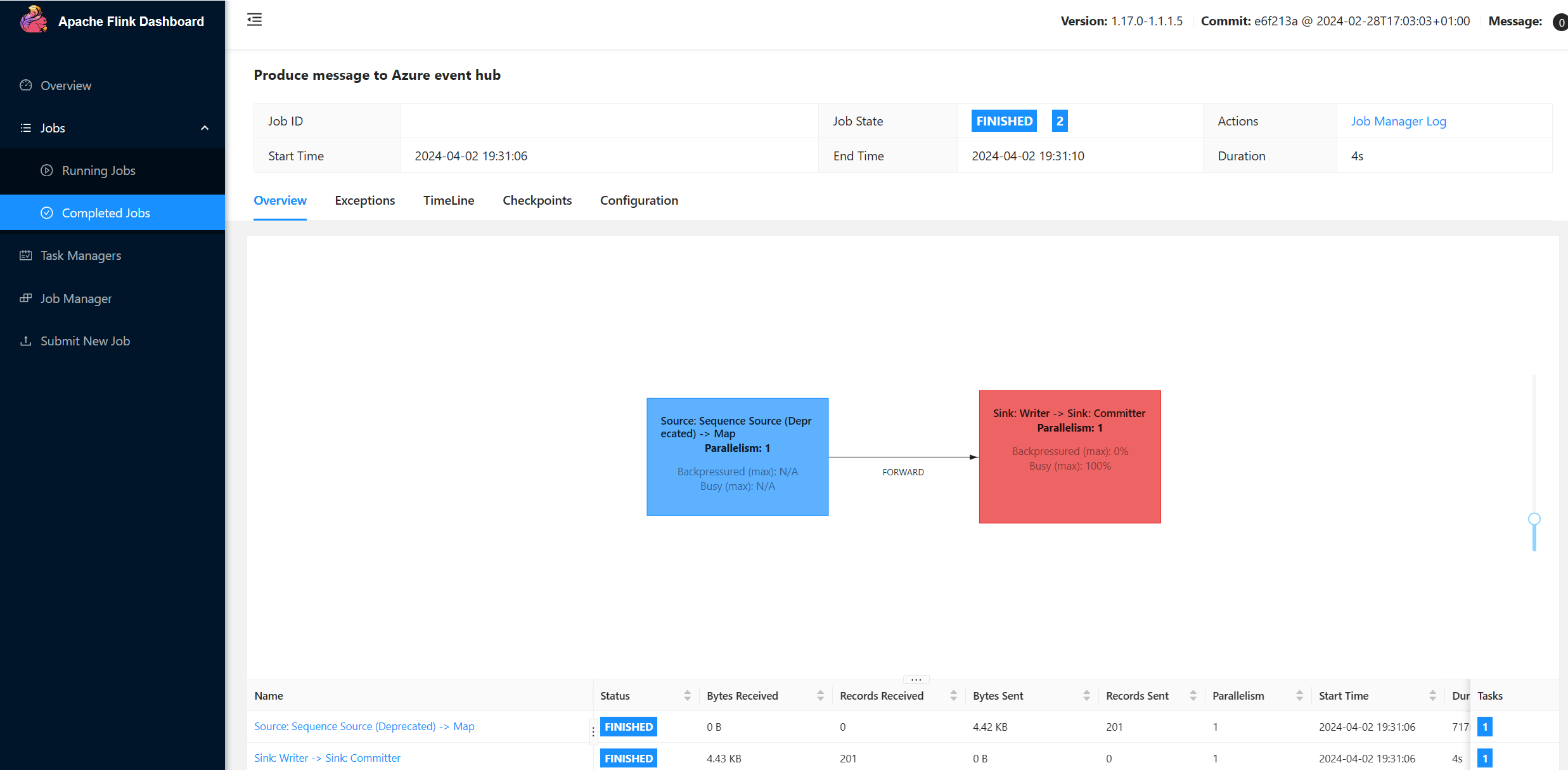
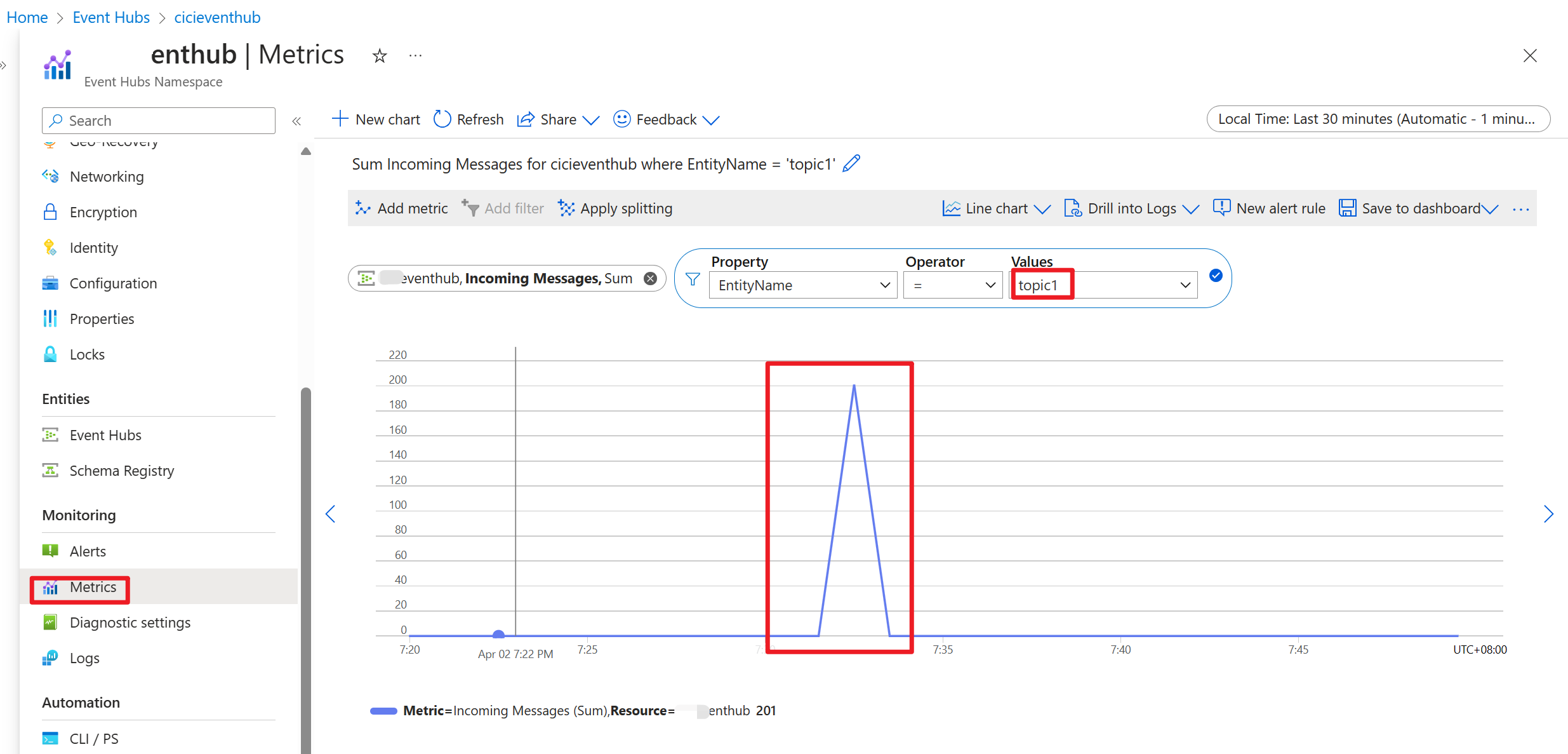
Depois que o código é executado, os eventos são armazenados no tópico "topic1"


Referência
- Site do Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e nomes de projetos de código aberto associados são marcas registradas da Apache Software Foundation (ASF).