Transformar dados na Rede Virtual do Azure usando a Atividade Hive no Azure Data Factory
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você pode usar o Azure PowerShell para criar um pipeline do Data Factory que transforma dados usando a atividade Hive em um cluster HDInsight que está em uma Rede Virtual (VNet) do Azure. Neste tutorial, você realizará os seguintes procedimentos:
- Criar um data factory.
- Criar e configurar um Integration Runtime auto-hospedado
- Criar e implantar serviços vinculados.
- Criar e implantar um pipeline que contém uma atividade Hive.
- Iniciar uma execução de pipeline.
- Monitorar a execução de pipeline
- Verificar a saída.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Observação
Recomendamos que você use o módulo Az PowerShell do Azure para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Conta de Armazenamento do Azure. Você cria um script Hive e carrega-o no Armazenamento do Azure. A saída do script Hive é armazenada nessa conta de armazenamento. Nessa amostra, o cluster HDInsight usa essa conta de Armazenamento do Azure como o armazenamento primário.
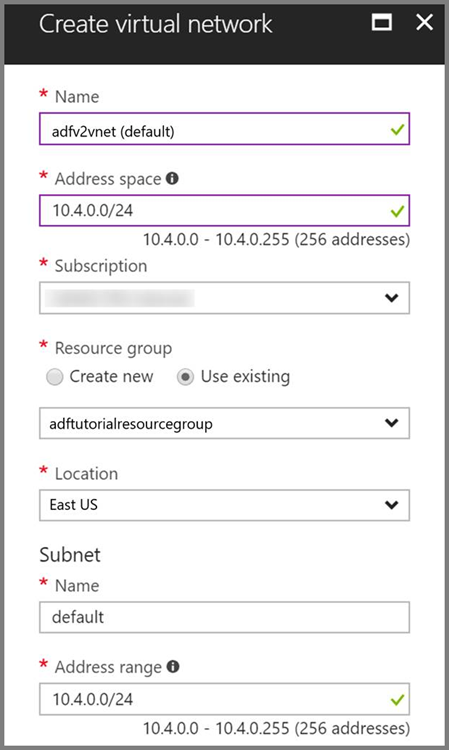
Rede Virtual do Azure. Se você não tem uma Rede Virtual do Azure, crie-a seguindo estas instruções. Nessa amostra, o HDInsight está em uma Rede Virtual do Azure. Aqui está uma amostra de configuração de Rede Virtual do Azure.
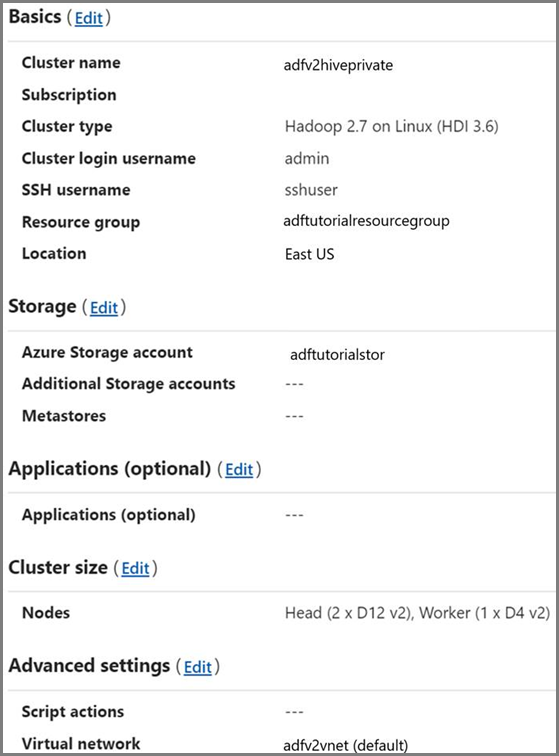
Cluster HDInsight. Crie um cluster HDInsight e ingresse-o na rede virtual criada na etapa anterior seguindo este artigo: Estender o Azure HDInsight usando uma Rede Virtual do Azure. Aqui está uma amostra de configuração do HDInsight em uma Rede Virtual do Azure.
Azure PowerShell. Siga as instruções em Como instalar e configurar o Azure PowerShell.
Carregar o script Hive em sua conta de Armazenamento de Blobs
Crie um arquivo Hive SQL chamado hivescript.hql com o seguinte conteúdo:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableNo seu Armazenamento de Blobs do Azure, crie um contêiner denominado adftutorial se ele não existir.
Crie uma pasta chamada hivescripts.
Carregar o arquivo hivescript.hql na subpasta hivescripts.
Criar uma data factory
Defina o nome do grupo de recursos. Crie um grupo de recursos como parte deste tutorial. No entanto, você pode usar um grupo de recursos existente, se desejar.
$resourceGroupName = "ADFTutorialResourceGroup"Especifique o nome do data factory. Deve ser globalmente exclusivo.
$dataFactoryName = "MyDataFactory09142017"Especifique um nome para o pipeline.
$pipelineName = "MyHivePipeline" #Especifique um nome para o runtime de integração auto-hospedada. Você precisará de um runtime de integração auto-hospedada quando o Data Factory precisar acessar recursos (como o Banco de Dados SQL do Azure) dentro de uma rede virtual.
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"Inicie o PowerShell. Mantenha o Azure PowerShell aberto até o fim deste guia de início rápido. Se você fechar e reabrir, precisará executar os comandos novamente. Para obter uma lista de regiões do Azure no qual o Data Factory está disponível no momento, selecione as regiões que relevantes para você na página a seguir e, em seguida, expanda Análise para localizar Data Factory: Produtos disponíveis por região. Os armazenamentos de dados (Armazenamento do Azure, Banco de Dados SQL do Azure, etc.) e serviços de computação (HDInsight, etc.) usados pelo data factory podem estar em outras regiões.
Execute o comando a seguir e insira o nome de usuário e senha usados para entrar no portal do Azure:
Connect-AzAccountExecute o comando abaixo para exibir todas as assinaturas dessa conta:
Get-AzSubscriptionExecute o comando a seguir para selecionar a assinatura com a qual deseja trabalhar. Substitua SubscriptionId pela ID da assinatura do Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"Crie o grupo de recursos: ADFTutorialResourceGroup caso ele ainda não exista em sua assinatura.
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"Crie o data factory.
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupNameExecute o comando a seguir para ver a saída:
$df
Criar um IR auto-hospedado
Nesta seção, você cria um Integration Runtime auto-hospedado e associa-o a uma VM do Azure na mesma Rede Virtual do Azure em que está o seu cluster HDInsight.
Crie um Integration Runtime auto-hospedado. Use um nome exclusivo no caso exista outro Integration Runtime com o mesmo nome.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHostedEste comando cria um registro lógico do Integration Runtime auto-hospedado.
Use o PowerShell para recuperar as chaves de autenticação para registrar o Integration Runtime auto-hospedado. Copie uma das chaves para registrar o Integration Runtime auto-hospedado.
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-JsonVeja o exemplo de saída:
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }Anote o valor de AuthKey1 sem aspas.
Crie uma VM do Azure e ingresse-a na mesma rede virtual que contém seu cluster HDInsight. Para obter detalhes, consulte Como criar máquinas virtuais. Ingresse-as em uma rede virtual do Azure.
Na VM do Azure, baixe o Integration Runtime auto-hospedado. Use a chave de autenticação obtida na etapa anterior para registrar manualmente o Integration Runtime auto-hospedado.
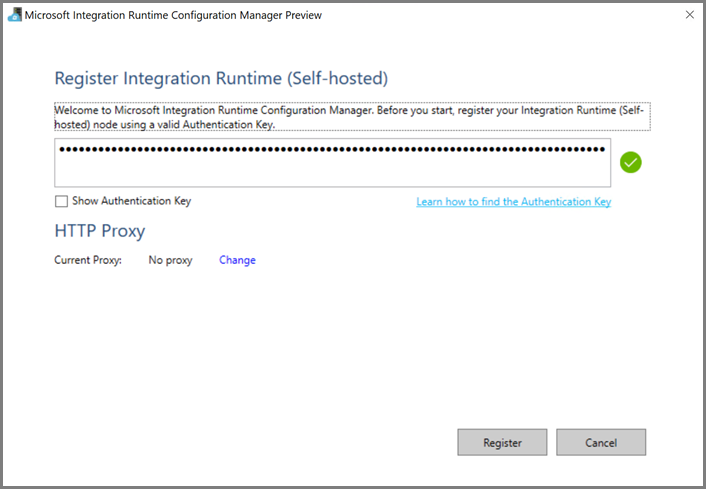
Você verá a seguinte mensagem quando o runtime de integração auto-hospedada for registrado com êxito:
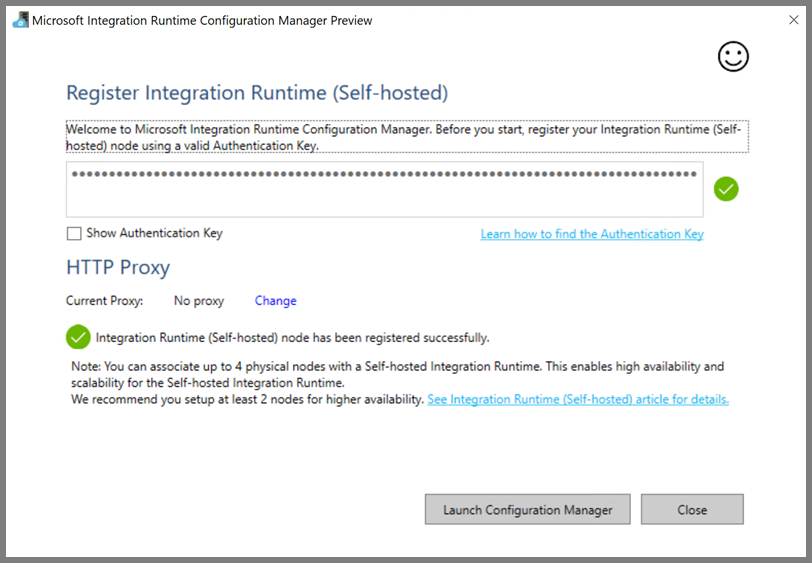
Você verá a seguinte página quando o nó estiver conectado com o serviço de nuvem:
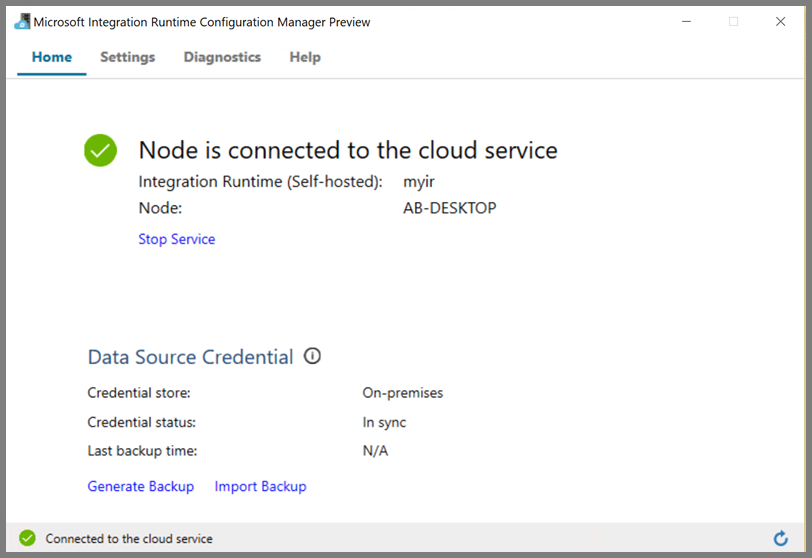
Criar serviços vinculados
Você cria e implanta dois serviços vinculados nesta seção:
- Um serviço vinculado do Armazenamento do Azure que vincula uma conta de Armazenamento do Azure ao data factory. Esse armazenamento é o armazenamento primário usado por seu cluster HDInsight. Nesse caso, podemos também usar essa conta de Armazenamento do Azure para manter o script Hive e a saída do script.
- Um serviço vinculado do HDInsight. O Azure Data Factory envia o script do Hive a este cluster do HDInsight para execução.
Serviço vinculado de armazenamento do Azure
Crie um arquivo JSON usando seu editor preferido, copie a seguinte definição de JSON de um serviço vinculado do Armazenamento do Azure e, em seguida, salve o arquivo como MyStorageLinkedService.json.
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Substitua <accountname> e <accountkey> pelo nome e pela chave da sua conta de Armazenamento do Azure, respectivamente.
Serviço vinculado ao HDInsight
Crie um arquivo JSON usando seu editor preferido, copie a seguinte definição de JSON de um serviço vinculado do Azure HDInsight e, em seguida, salve o arquivo como MyHDInsightLinkedService.json.
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Atualize os valores para as propriedades a seguir na definição de serviço vinculado:
userName. Nome usuário de logon do cluster especificado ao criar o cluster.
password. A senha do usuário.
clusterUri. Especifique a URL de seu cluster do HDInsight no seguinte formato:
https://<clustername>.azurehdinsight.net. Este artigo pressupõe que você tenha acesso ao cluster via Internet. Por exemplo, você pode se conectar ao cluster emhttps://clustername.azurehdinsight.net. Esse endereço usa o gateway público, que não estará disponível se você tiver usado NSGs (Grupos de Segurança de Rede) ou UDRs (rotas definidas pelo usuário) para restringir o acesso da Internet. Para que o Data Factory envie trabalhos para clusters HDInsight na Rede Virtual do Azure, esta precisa ser configurada de modo que a URL possa ser resolvida para o endereço IP do gateway usado pelo HDInsight.No Portal do Azure, abra a Rede Virtual que contém o HDInsight. Abra o adaptador de rede cujo nome começa com
nic-gateway-0. Anote o endereço IP privado dela. Por exemplo, 10.6.0.15.Se sua Rede Virtual do Azure tem um servidor DNS, atualize o registro DNS de modo que a URL do cluster do HDInsight
https://<clustername>.azurehdinsight.netpossa ser resolvida para10.6.0.15. Essa é a abordagem recomendada. Se você não tiver um servidor DNS em sua Rede Virtual do Azure, você poderá usar uma solução alternativa temporária para isso editando o arquivo de hosts (C:\Windows\System32\drivers\etc.) de todas as VMs registradas como nós de Integration Runtime auto-hospedado, adicionando uma entrada como esta:10.6.0.15 myHDIClusterName.azurehdinsight.net
Criar serviços vinculados
No PowerShell, mude para a pasta em que você criou arquivos JSON e execute o seguinte comando para implantar os serviços vinculados:
No PowerShell, alterne para a pasta em que você criou arquivos JSON.
Execute o seguinte comando para criar um serviço vinculado do Armazenamento do Azure.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"Execute o seguinte comando para criar um serviço vinculado do Azure HDInsight.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
Criar um pipeline
Nesta etapa, você cria um pipeline com uma atividade Hive. A atividade executa o script do Hive para retornar dados de uma tabela de exemplo e salvá-los em um caminho que você definiu. Crie um arquivo JSON em seu editor preferido, copie a definição de JSON a seguir de uma definição de pipeline e salve-a como MyHivePipeline.json.
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
Observe os seguintes pontos:
- scriptPath aponta para o caminho para o script Hive na conta de Armazenamento do Azure que você usou para MyStorageLinkedService. O caminho diferencia maiúsculas de minúsculas.
- Output é um argumento usado no script Hive. Use o formato de
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/para apontá-lo para uma pasta existente no seu Armazenamento do Azure. O caminho diferencia maiúsculas de minúsculas.
Mude para a pasta em que você criou arquivos JSON e execute o seguinte comando para implantar o pipeline:
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
Iniciar o pipeline
Iniciar uma execução de pipeline. Ele também captura a ID da execução de pipeline para monitoramento futuro.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineNameExecute o script a seguir para verificar continuamente o status do pipeline de execução até que ele termine.
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"Aqui está a saída da execução de exemplo:
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"Verifique a pasta
outputfolderem busca do novo arquivo criado como resultado da consulta de Hive, ele deve se parecer com a amostra de saída a seguir:8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
Conteúdo relacionado
Neste tutorial, você realizará os seguintes procedimentos:
- Criar um data factory.
- Criar e configurar um Integration Runtime auto-hospedado
- Criar e implantar serviços vinculados.
- Criar e implantar um pipeline que contém uma atividade Hive.
- Iniciar uma execução de pipeline.
- Monitorar a execução de pipeline
- Verificar a saída.
Avance para o tutorial a seguir para saber mais sobre como transformar dados usando um cluster Spark no Azure: