Formato de Excel no Azure Data Factory e no Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Siga este artigo quando desejar analisar os arquivos Excel. O serviço é compatível com ".xls" e ".xlsx".
O formato de Excel é compatível com os seguintes conectores: Amazon S3, Armazenamento compatível com Amazon S3, Blob do Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Arquivos do Azure, Sistema de arquivos, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage e SFTP. É compatível como origem, mas não como coletor.
Observação
O formato “.xls” não é compatível com o uso de HTTP.
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre Conjuntos de Dados. Esta seção fornece uma lista das propriedades compatíveis com o conjunto de dados Excel.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como Excel. | Sim |
| local | Configurações de local dos arquivos. Cada conector baseado em arquivo tem seu próprio tipo de local e propriedades com suporte em location. |
Sim |
| sheetName | O nome da planilha do Excel para ler os dados. | Especifique sheetName ou sheetIndex |
| sheetIndex | O índice da planilha do Excel para ler dados, começando em 0. | Especifique sheetName ou sheetIndex |
| range | O intervalo de células na planilha fornecida para localizar os dados seletivos, por exemplo: - Não especificado: lê a planilha inteira como uma tabela da primeira linha e coluna não vazias - A3: lê uma tabela a partir da célula especificada, detecta dinamicamente todas as linhas abaixo e todas as colunas à direita- A3:H5: lê este intervalo fixo como uma tabela- A3:A3: lê esta única célula |
Não |
| firstRowAsHeader | Especifica se deve tratar a primeira linha na planilha/intervalo fornecido como uma linha de cabeçalho com nomes de colunas. Os valores permitidos são true e false (padrão). |
Não |
| nullValue | Especifica a representação de cadeia de caracteres do valor nulo. O valor padrão pode ser uma cadeia de caracteres vazia. |
Não |
| compactação | Grupo de propriedades para configurar a compactação de arquivo. Configure esta seção quando desejar fazer compactação/descompactação durante a execução da atividade. | Não |
| type (em compression ) |
O codec de compactação utilizado para ler/gravar arquivos JSON. Os valores permitidos são bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy ou lz4. O padrão é não compactado. Observação a atividade Copy atualmente não dá suporte a "snappy" e "lz4" e o fluxo de dados de mapeamento não dá suporte a "ZipDeflate", "TarGzip" e "Tar". Observação ao usar a atividade Copy para descompactar arquivo(s) ZipDeflate e gravar no armazenamento de dados de coletor baseado em arquivo, os arquivos são extraídos para a pasta: <path specified in dataset>/<folder named as source zip file>/. |
Não. |
| nível (em compression ) |
A taxa de compactação. Os valores permitidos são Ideal ou Mais rápida. - Mais rápida: a operação de compactação deve ser concluída o mais rápido possível, mesmo se o arquivo resultante não for compactado da maneira ideal. - Ideal: a operação de compactação deve ser concluída da maneira ideal, mesmo se a operação demorar mais tempo para ser concluída. Para saber mais, veja o tópico Nível de compactação . |
Não |
Veja abaixo um exemplo de conjunto de dados Excel no Armazenamento de Blobs do Azure:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades compatíveis com a origem Excel.
Excel como origem
As propriedades a seguir têm suporte na seção de *origem* da atividade Copy.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da origem da atividade de cópia deve ser definida como ExcelSource. | Sim |
| storeSettings | Um grupo de propriedades sobre como ler dados de um armazenamento de dados. Cada conector baseado em arquivo tem suas próprias configurações de leitura com suporte em storeSettings. |
Não |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Mapeamento de propriedades de fluxo de dados
Nos fluxos de dados de mapeamento, é possível ler o formato Excel nos seguintes armazenamentos de dados: Armazenamento de Blobs do Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3 e SFTP. É possível apontar para arquivos Excel usando o conjunto de dados Excel ou um conjunto de dados embutido.
Propriedades da origem
A tabela abaixo lista as propriedades compatíveis de uma origem Excel. Você pode editar essas propriedades na guia Opções de origem. Ao usar o conjunto de dados embutido, é possível ver as configurações de arquivo adicionais, que são iguais às propriedades descritas na seção Propriedades do conjunto.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Caminhos curinga | Todos os arquivos correspondentes ao caminho curinga serão processados. Substitui a pasta e o caminho do arquivo definido no conjunto de dados. | não | String[] | wildcardPaths |
| Caminho raiz da partição | Para dados de arquivo particionados, é possível inserir um caminho raiz de partição para ler pastas particionadas como colunas | não | String | partitionRootPath |
| Lista de arquivos | Se sua fonte estiver apontando para um arquivo de texto que lista os arquivos a serem processados | não |
true ou false |
fileList |
| Coluna para armazenar o nome do arquivo | Criar uma nova coluna com o nome e o caminho do arquivo de origem | não | String | rowUrlColumn |
| Após a conclusão | Exclua ou mova os arquivos após o processamento. O caminho do arquivo inicia a partir da raiz do contêiner | não | Excluir: true ou false Mover ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrar pela última modificação | Escolher filtrar arquivos com base na última alteração | não | Carimbo de data/hora | modifiedAfter modifiedBefore |
| Permitir nenhum arquivo encontrado | Se for true, um erro não será gerado caso nenhum arquivo for encontrado | não |
true ou false |
ignoreNoFilesFound |
Exemplo de origem
A imagem abaixo é um exemplo de uma configuração de origem Excel nos fluxos de dados de mapeamento usando o modo de conjunto de dados.
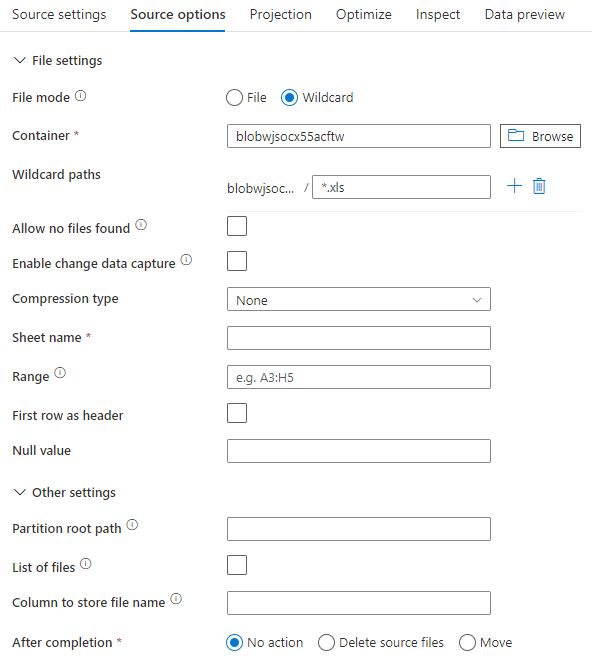
O script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
Se você usar o conjunto de dados embutido, verá as seguintes opções de origem no fluxo de dados de mapeamento.
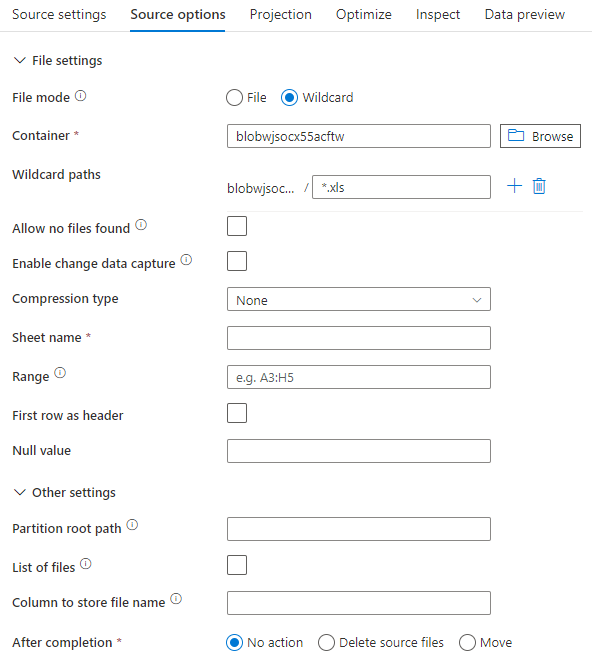
O script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Observação
O fluxo de dados de mapeamento não dá suporte à leitura de arquivos protegidos do Excel, pois esses arquivos podem conter avisos de confidencialidade ou impor restrições de acesso específicas que limitam o acesso ao conteúdo.
Como processar arquivos muito grandes do Excel
O conector do Excel não dá suporte à leitura de streaming para a atividade Copy e precisa carregar o arquivo inteiro na memória para que os dados sejam lidos. Para importar o esquema, visualizar os dados ou atualizar um conjunto de dados do Excel, os dados precisam ser retornados antes do tempo limite da solicitação HTTP (100s). Para arquivos grandes do Excel, talvez essas operações não sejam concluídas dentro desse período, causando um erro de tempo limite. Caso deseje mover arquivos grandes do Excel (>100 MB) para outro armazenamento de dados, use uma das seguintes opções para resolver essa limitação:
- Use o SHIR (runtime de integração auto-hospedada) e a atividade Copy para mover o arquivo grande do Excel para outro armazenamento de dados com o SHIR.
- Divida o arquivo grande do Excel em vários menores e use a atividade Copy para mover a pasta que contém os arquivos.
- Use uma atividade de fluxo de dados para mover o arquivo grande do Excel para outro armazenamento de dados. O fluxo de dados dá suporte à leitura de streaming para Excel e pode mover/transferir arquivos grandes rapidamente.
- Converta manualmente o arquivo grande do Excel em formato CSV e use uma atividade Copy para mover o arquivo.