Copiar e transformar dados no Lakehouse do Microsoft Fabric usando o Azure Data Factory ou o Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
O Microsoft Fabric Lakehouse é uma plataforma de arquitetura de dados para armazenar, gerenciar e analisar dados estruturados e não estruturados em um único local. Para obter acesso contínuo a dados em todos os mecanismos de computação no Microsoft Fabric, acesse o Lakehouse e as Tabelas Delta para saber mais. Por padrão, os dados são gravados na Tabela Lakehouse em V-Order e você pode acessar a Otimização de tabela do Delta Lake e V-Order para mais informações.
Este artigo descreve como usar a atividade Copy para copiar dados de e para o Lakehouse do Microsoft Fabric e usar o Fluxo de Dados para transformar dados no Microsoft Fabric Lakehouse. Para saber mais, leia o artigo introdutório do Azure Data Factory ou do Azure Synapse Analytics.
Funcionalidades com suporte
Este conector do Lakehouse do Microsoft Fabric tem suporte para os seguintes recursos:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/coletor) | ① ② |
| Fluxo de dados de mapeamento (origem/coletor) | ① |
| Atividade de pesquisa | ① ② |
| Atividade GetMetadata | ① ② |
| Excluir atividade | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado do Microsoft Fabric Lakehouse por meio da interface do usuário
Use as etapas a seguir para criar um serviço vinculado do Microsoft Fabric Lakehouse na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar no workspace do Azure Data Factory ou do Synapse e selecione Serviços Vinculados. Depois, selecione Novo:
Procure o Microsoft Fabric Lakehouse e selecione o conector.
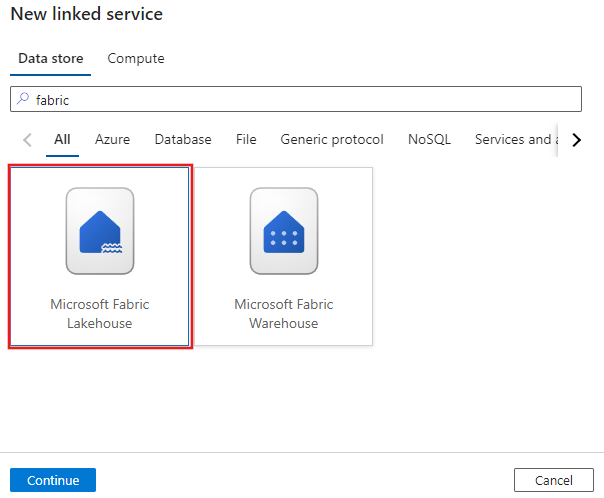
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
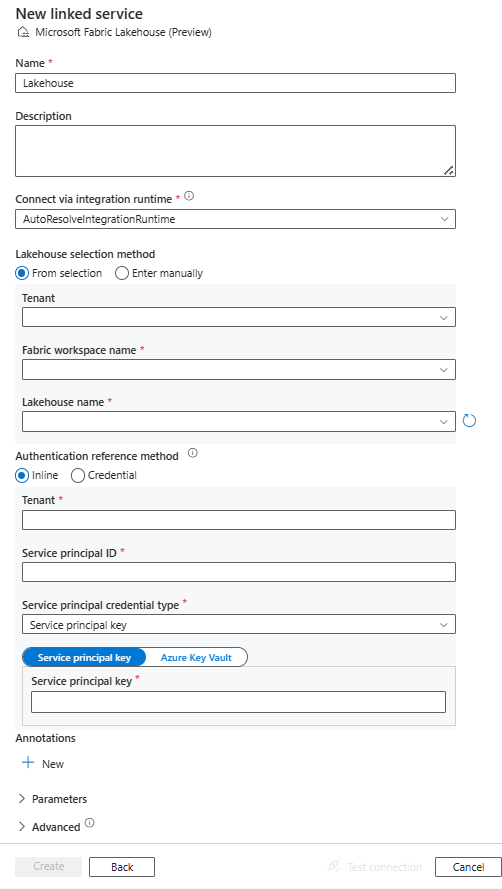
Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas do Microsoft Fabric Lakehouse.
Propriedades do serviço vinculado
O conector do Microsoft Fabric Lakehouse dá suporte aos tipos de autenticação a seguir. Consulte as seções correspondentes para obter detalhes:
Autenticação de entidade de serviço
Para usar a autenticação de entidade de serviço, siga estas etapas.
Registrar um aplicativo com a plataforma Microsoft Identity e adicionar um de segredo do cliente. Em seguida, anote estes valores; ele são usados para definir o serviço vinculado:
- ID do aplicativo (cliente), que é a ID da entidade de serviço no serviço vinculado.
- Valor do segredo do cliente, que é a chave da entidade de serviço no serviço vinculado.
- ID do locatário
Conceda à entidade de serviço, pelo menos, a função Colaborador no workspace do Microsoft Fabric. Siga estas etapas:
Acesse o workspace do Microsoft Fabric e selecione Gerenciar acesso na barra superior. Em seguida, selecione Adicionar pessoas ou grupos.
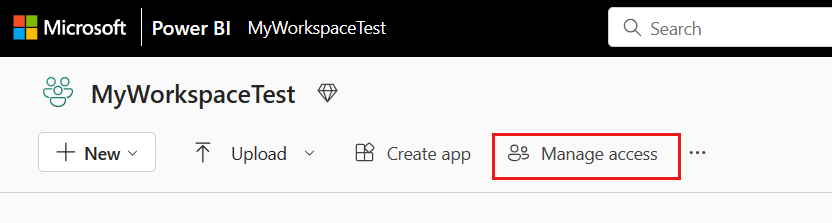
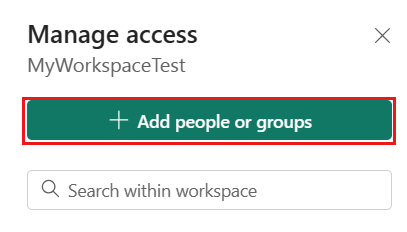
No painel Adicionar pessoas, insira o nome da entidade de serviço e selecione a entidade de serviço na lista suspensa.
Observação
A entidade de serviço não aparecerá na lista Adicionar pessoas a menos que as configurações do locatário do Power BI permitam o acesso das entidades de serviço às APIs do Fabric.
Especifique a função como Colaborador ou superior (administrador, membro) e escolha Adicionar.
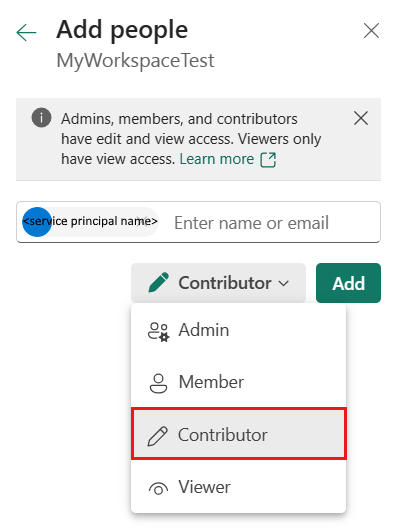
A entidade de serviço será exibida no painel Gerenciar acesso.
Estas propriedades têm suporte para o serviço vinculado:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type precisa ser definida como Lakehouse. | Sim |
| workspaceId | A ID do workspace do Microsoft Fabric. | Sim |
| artifactId | A ID do objeto do Microsoft Fabric Lakehouse. | Sim |
| locatário | Especifique as informações de locatário (domínio nome ou ID do Locatário) em que o aplicativo reside. Recupere-as passando o mouse no canto superior direito do Portal do Azure. | Sim |
| servicePrincipalId | Especifique a ID do cliente do aplicativo. | Sim |
| servicePrincipalCredentialType | O tipo de credencial a ser usada para autenticação da entidade de serviço. Os valores permitidos são ServicePrincipalKey e ServicePrincipalCert. | Sim |
| servicePrincipalCredential | A credencial da entidade de serviço. Ao usar ServicePrincipalKey como o tipo de credencial, especifique o valor do segredo do cliente do aplicativo. Marque este campo como um SecureString para armazená-lo com segurança ou referencie um segredo armazenado no Azure Key Vault. Quando usar ServicePrincipalCert como credencial, faça referência a um certificado no Azure Key Vault e verifique se o tipo de conteúdo do certificado é PKCS nº 12. |
Sim |
| connectVia | O runtime de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Azure Integration Runtime ou um runtime de integração auto-hospedada se o seu armazenamento de dados estiver em uma rede privada. Se não especificado, o Azure Integration Runtime padrão será usado. | Não |
Exemplo: usar a autenticação de chave de entidade de serviço
Você também pode armazenar a chave de entidade de serviço no Azure Key Vault.
{
"name": "MicrosoftFabricLakehouseLinkedService",
"properties": {
"type": "Lakehouse",
"typeProperties": {
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Lakehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
O conector do Lakehouse do Microsoft Fabric dá suporte a dois tipos de conjuntos de dados, que são o Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric e o Conjunto de dados de tabelas do Lakehouse do Microsoft Fabric. Consulte as seções correspondentes para obter detalhes.
- Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric
- Conjunto de dados de tabelas do Lakehouse do Microsoft Fabric
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira Conjuntos de dados.
Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric
O conector do Lakehouse do Microsoft Fabric dá suporte aos formatos de arquivo a seguir. Confira cada artigo para obter configurações baseadas em formato.
Há suporte para as seguintes propriedades nas configurações de location no Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric baseado em formato:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type em location no conjunto de dados precisa ser definida como LakehouseLocation. |
Sim |
| folderPath | O caminho para uma pasta. Se você quiser usar um caractere curinga para filtrar a pasta, ignore essa configuração e especifique-o nas configurações de origem da atividade. | Não |
| fileName | O nome do arquivo sob o folderPath fornecido. Se você quiser usar um caractere curinga para filtrar os arquivos, ignore essa configuração e especifique-o nas configurações de origem da atividade. | Não |
Exemplo:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "LakehouseLocation",
"fileName": "<file name>",
"folderPath": "<folder name>"
},
"columnDelimiter": ",",
"compressionCodec": "gzip",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ]
}
}
Conjunto de dados de tabelas do Lakehouse do Microsoft Fabric
As propriedades a seguir têm suporte para o conjunto de dados de tabela do Microsoft Fabric Lakehouse:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como LakehouseTable. | Sim |
| esquema | Nome do esquema. Se esse campo não for especificado, o valor padrão será dbo. |
Não |
| tabela | O nome da sua tabela. O nome da tabela deve ter pelo menos um caractere, sem '/' ou '\', sem ponto à direita e sem espaços à esquerda ou à direita. | Sim |
Exemplo:
{
"name": "LakehouseTableDataset",
"properties": {
"type": "LakehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"schema": [< physical schema, optional, retrievable during authoring >]
}
}
Propriedades da atividade de cópia
As propriedades de atividade de cópia para o Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric e o Conjunto de dados de tabelas do Lakehouse do Microsoft Fabric são diferentes. Consulte as seções correspondentes para obter detalhes.
- Arquivos do Lakehouse do Microsoft Fabric na atividade Copy
- Tabela do Lakehouse do Microsoft Fabric na atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, confira Copiar configurações de atividade e Pipelines e atividades.
Arquivos do Lakehouse do Microsoft Fabric na atividade Copy
Para usar o tipo de Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric como uma origem ou coletor na atividade Copy, acesse as seções a seguir para obter as configurações detalhadas.
Arquivos do Microsoft Fabric Lakehouse como um tipo de origem
O conector do Lakehouse do Microsoft Fabric dá suporte aos formatos de arquivo a seguir. Confira cada artigo para obter configurações baseadas em formato.
Você tem várias opções para copiar dados do Lakehouse do Microsoft Fabric usando o Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric:
- Copiar do caminho especificado no conjunto de dados.
- Para filtrar usando caracteres curinga em relação ao caminho da pasta ou nome do arquivo, confira
wildcardFolderPathewildcardFileName. - Copie os arquivos definidos em um determinado arquivo de texto como conjunto de arquivos, confira
fileListPath.
As propriedades a seguir estão nas configurações de storeSettings na origem de cópia baseada em formato ao usar o Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type em storeSettings precisa ser definida como LakehouseReadSettings. |
Sim |
| Localize os arquivos a serem copiados: | ||
| OPÇÃO 1: caminho estático |
Copiar do caminho de pasta/arquivo especificado no conjunto de dados. Se quiser copiar todos os arquivos de uma pasta, especifique também wildcardFileName como *. |
|
| OPÇÃO 2: curinga - wildcardFolderPath |
O caminho da pasta com caracteres curinga para filtrar as pastas de origem. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único); use ^ para escape se o nome de pasta atual tiver curinga ou esse caractere interno de escape. Veja mais exemplos em Exemplos de filtro de pastas e arquivos. |
Não |
| OPÇÃO 2: curinga - wildcardFileName |
O nome do arquivo com caracteres curinga sob o folderPath/wildcardFolderPath fornecido para filtrar os arquivos de origem. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único); use ^ para escape se o nome de arquivo real tiver curinga ou esse caractere interno de escape. Veja mais exemplos em Exemplos de filtro de pastas e arquivos. |
Sim |
| OPÇÃO 3: uma lista de arquivos - fileListPath |
Indica a cópia de um determinado conjunto de arquivos. Aponte para um arquivo de texto que inclui a lista de arquivos que você deseja copiar com um arquivo por linha, que é o caminho relativo para o caminho configurado no conjunto de dados. Ao utilizar essa opção, não especifique o nome do arquivo no conjunto de dados. Veja mais exemplos em Exemplos de lista de arquivos. |
Não |
| Configurações adicionais: | ||
| recursiva | Indica se os dados são lidos recursivamente das subpastas ou somente da pasta especificada. Quando recursiva é definida como true e o coletor é um armazenamento baseado em arquivo, uma pasta vazia ou subpasta não é copiada ou criada no coletor. Os valores permitidos são true (padrão) e false. Essa propriedade não se aplica quando você configura fileListPath. |
Não |
| deleteFilesAfterCompletion | Indica se os arquivos binários serão excluídos do repositório de origem após a movimentação com êxito para o repositório de destino. A exclusão do arquivo é feita por arquivo, portanto, quando a atividade Copy falhar, você observa que alguns arquivos já foram copiados para o destino e excluídos da origem, enquanto outros ainda permanecem no repositório de origem. Essa propriedade só é válida no cenário de cópia de arquivos binários. O valor padrão é false. |
Não |
| modifiedDatetimeStart | Filtro de arquivos com base no atributo: Última Modificação. Os arquivos serão selecionados se a hora da última modificação for maior ou igual a modifiedDatetimeStart e menor que modifiedDatetimeEnd. A hora é aplicada ao fuso horário de UTC no formato "2018-12-01T05:00:00Z". As propriedades podem ser NULL, o que significa que nenhum filtro de atributo de arquivo é aplicado ao conjunto de dados. Quando modifiedDatetimeStart tem o valor de data e hora, mas modifiedDatetimeEnd for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado é maior ou igual ao valor de data e hora. Quando modifiedDatetimeEnd tem o valor de data e hora, mas modifiedDatetimeStart for NULL, isso significa que serão selecionados os arquivos cujo último atributo modificado é menor que o valor de data e hora.Essa propriedade não se aplica quando você configura fileListPath. |
Não |
| modifiedDatetimeEnd | Mesmo que acima. | Não |
| enablePartitionDiscovery | Para arquivos que são particionados, especifique se deseja analisar as partições do caminho do arquivo e incluí-las como outras colunas de origem. Os valores permitidos são false (padrão) e true. |
No |
| partitionRootPath | Quando a descoberta de partição estiver habilitada, especifique o caminho raiz absoluto para ler as pastas particionadas como colunas de dados. Se não for especificado, será por padrão, – Quando você usa o caminho do arquivo no conjunto de dados ou na lista de arquivos na origem, o caminho raiz da partição é o caminho configurado no conjunto de dados. - Quando você utiliza o filtro da pasta curinga, o caminho raiz da partição é o subcaminho antes do primeiro curinga. Por exemplo, supondo que você configure o caminho no conjunto de dados como "root/folder/year=2020/month=08/day=27": - Se você especificar o caminho da raiz da partição como "root/folder/year=2020", a atividade de Cópia gerará mais duas colunas month e day com valor "08" e "27", respectivamente, além das colunas dentro dos arquivos.- Se o caminho da raiz da partição não for especificado, nenhuma coluna extra será gerada. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | Não |
Exemplo:
"activities": [
{
"name": "CopyFromLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "LakehouseReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Arquivos do Microsoft Fabric Lakehouse como um tipo de coletor
O conector do Lakehouse do Microsoft Fabric dá suporte aos formatos de arquivo a seguir. Confira cada artigo para obter configurações baseadas em formato.
Há suporte para as seguintes propriedades nos Arquivos do Lakehouse do Microsoft Fabric nas configurações de storeSettings no coletor de cópia baseado em formato:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type em storeSettings precisa ser definida como LakehouseWriteSettings. |
Sim |
| copyBehavior | Define o comportamento de cópia quando a fonte for de arquivos de um armazenamento de dados baseado em arquivo. Valores permitidos são: – PreserveHierarchy (padrão): Preserva a hierarquia de arquivos na pasta de destino. O caminho relativo do arquivo de origem para a pasta de origem é idêntico ao caminho relativo do arquivo de destino para a pasta de destino. – FlattenHierarchy: Todos os arquivos da pasta de origem estão no primeiro nível da pasta de destino. Os arquivos de destino têm os nomes gerados automaticamente. – MergeFiles: Mescla todos os arquivos da pasta de origem em um arquivo. Se o nome do arquivo for especificado, o nome do arquivo mesclado será o nome especificado. Caso contrário, ele será um nome de arquivo gerado automaticamente. |
Não |
| blockSizeInMB | Especifique o tamanho do bloco em MB usado para gravar dados no Lakehouse do Microsoft Fabric. Saiba mais sobre Blobs de blocos. O valor permitido é entre 4 MB e 100 MB. Por padrão, o ADF determina automaticamente o tamanho do bloco com base no tipo de armazenamento de origem e nos dados. Para cópia não binária no Lakehouse do Microsoft Fabric, o tamanho do bloco padrão é de 100 MB, de modo a ajustar no máximo 4,75 TB de dados. Talvez não seja ideal quando os dados não forem grandes, especialmente ao usar o runtime de integração auto-hospedada com rede deficiente, resultando em tempo limite de operação ou problema de desempenho. É possível especificar explicitamente um tamanho de bloco, verificando se blockSizeInMB*50000 está grande o suficiente para armazenar os dados, caso contrário, haverá falha na execução da atividade de cópia. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | Não |
| metadata | Defina metadados personalizados ao copiar para o coletor. Cada objeto sob a matriz metadata representa uma coluna extra. O name define o nome chave dos metadados e value indica o valor de dados dessa chave. Se o recurso preservar atributos for usado, os metadados especificados serão unificados/substituídos pelos metadados do arquivo de origem.Os valores de dados permitidos são: - $$LASTMODIFIED: uma variável reservada indica armazenar a hora da última modificação dos arquivos de origem. Aplicar à fonte baseada em arquivo somente com formato binário.- Expressão - Valor estático |
Não |
Exemplo:
"activities": [
{
"name": "CopyToLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "LakehouseWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
}
]
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
}
}
}
]
Exemplos de filtro de pasta e arquivo
Esta seção descreve o comportamento resultante do caminho da pasta e do nome de arquivo com filtros curinga.
| folderPath | fileName | recursiva | Estrutura da pasta de origem e resultado do filtro (os arquivos em negrito são recuperados) |
|---|---|---|---|
Folder* |
(Vazio, usar padrão) | false | FolderA Arquivo1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Folder* |
(Vazio, usar padrão) | true | FolderA Arquivo1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Folder* |
*.csv |
false | FolderA Arquivo1.csv Arquivo2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Folder* |
*.csv |
true | FolderA Arquivo1.csv Arquivo2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB Arquivo6.csv |
Exemplos de lista de arquivos
Esta seção descreve o comportamento resultante do uso do caminho da lista de arquivos na origem da atividade de cópia.
Supondo que você tenha a seguinte estrutura de pasta de origem e queira copiar os arquivos em negrito:
| Exemplo de estrutura de origem | Conteúdo em FileListToCopy.txt | Configuração ADF |
|---|---|---|
| filesystem FolderA Arquivo1.csv Arquivo2.json Subpasta1 File3.csv File4.json File5.csv Metadados FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
No conjunto de dados: - Caminho da pasta: FolderANa origem da atividade de cópia: - Caminho da lista de arquivos: Metadata/FileListToCopy.txt O caminho da lista de arquivos aponta para um arquivo de texto no mesmo armazenamento de dados que inclui a lista de arquivos que você deseja copiar, um arquivo por linha, com o caminho relativo do caminho configurado no conjunto de dados. |
Alguns exemplos de recursive e copyBehavior
Esta seção descreve o comportamento resultante da operação de cópia para diferentes combinações de valores recursive e copyBehavior.
| recursiva | copyBehavior | Estrutura de pasta de origem | Destino resultante |
|---|---|---|---|
| true | preserveHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a mesma estrutura da origem: Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
| true | flattenHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a seguinte estrutura: Pasta1 nome gerado automaticamente para o Arquivo1 nome gerado automaticamente para o Arquivo2 nome gerado automaticamente para o Arquivo3 nome gerado automaticamente para o Arquivo4 nome gerado automaticamente para o Arquivo5 |
| true | mergeFiles | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a seguinte estrutura: Pasta1 Os conteúdos de Arquivo1 + Arquivo2 + Arquivo3 + Arquivo4 + Arquivo5 são mesclados em um arquivo com um nome de arquivo gerado automaticamente. |
| false | preserveHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a seguinte estrutura: Pasta1 Arquivo1 Arquivo2 A Subpasta1 com Arquivo3, Arquivo4 e Arquivo5 não é selecionada. |
| false | flattenHierarchy | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a seguinte estrutura: Pasta1 nome gerado automaticamente para o Arquivo1 nome gerado automaticamente para o Arquivo2 A Subpasta1 com Arquivo3, Arquivo4 e Arquivo5 não é selecionada. |
| false | mergeFiles | Pasta1 Arquivo1 Arquivo2 Subpasta1 Arquivo3 Arquivo4 Arquivo5 |
A Pasta1 de destino é criada com a seguinte estrutura: Pasta1 Os conteúdos de Arquivo1 + Arquivo2 são mesclados em um arquivo com um nome de arquivo gerado automaticamente. nome gerado automaticamente para o Arquivo1 A Subpasta1 com Arquivo3, Arquivo4 e Arquivo5 não é selecionada. |
Tabela do Lakehouse do Microsoft Fabric na atividade Copy
Para usar o Conjunto de dados de tabelas do Lakehouse Microsoft Fabric como um conjunto de dados de origem ou coletor na atividade Copy, acesse as seções a seguir para obter as configurações detalhadas.
Tabela do Microsoft Fabric Lakehouse como um tipo de origem
Para copiar dados do Lakehouse do Microsoft Fabric usando o Conjunto de dados de tabelas do Lakehouse Microsoft Fabric, defina o tipo de propriedade na origem da atividade Copy como LakehouseTableSource. As propriedades a seguir têm suporte na seção de origem da atividade Copy:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da origem da atividade Copy deve ser definida como LakehouseTableSource. | Sim |
| timestampAsOf | O carimbo de data/hora para consultar um instantâneo mais antigo. | Não |
| versionAsOf | A versão para consultar um instantâneo mais antigo. | Não |
Exemplo:
"activities":[
{
"name": "CopyFromLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "LakehouseTableSource",
"timestampAsOf": "2023-09-23T00:00:00.000Z",
"versionAsOf": 2
},
"sink": {
"type": "<sink type>"
}
}
}
]
Tabela do Microsoft Fabric Lakehouse como um tipo de coletor
Para copiar dados para o Lakehouse do Microsoft Fabric usando o Conjunto de dados de tabelas do Lakehouse Microsoft Fabric, defina a tipo de propriedade no coletor da atividade Copy como LakehouseTableSink. As seguintes propriedades têm suporte na seção coletor da atividade Copy:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da origem da atividade Copy deve ser definida como LakehouseTableSink. | Sim |
Observação
Os dados são gravados na Tabela Lakehouse em V-Order por padrão. Para mais informações, acesse Otimização de tabela do Delta Lake e V-Order.
Exemplo:
"activities":[
{
"name": "CopyToLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption ": "Append"
}
}
}
]
Propriedades do fluxo de dados de mapeamento
Ao transformar dados no fluxo de dados de mapeamento, é possível ler e gravar em arquivos ou tabelas no Lakehouse do Microsoft Fabric. Consulte as seções correspondentes para obter detalhes.
- Arquivos do Lakehouse do Microsoft Fabric no fluxo de dados de mapeamento
- Tabela do Lakehouse do Microsoft Fabric no fluxo de dados de mapeamento
Para obter mais informações, confira transformação de origem e transformação do coletor nos fluxos de dados de mapeamento.
Arquivos do Lakehouse do Microsoft Fabric no fluxo de dados de mapeamento
Para usar o Conjunto de dados de arquivos do Lakehouse do Microsoft Fabric como um conjunto de dados de origem ou coletor no fluxo de dados de mapeamento, acesse as seções a seguir para obter as configurações detalhadas.
Arquivos do Microsoft Fabric Lakehouse como um tipo de origem do coletor
O conector do Lakehouse do Microsoft Fabric dá suporte aos formatos de arquivo a seguir. Confira cada artigo para obter configurações baseadas em formato.
Para usar o conector baseado em arquivo do Fabric Lakehouse no tipo de conjunto de dados embutido, você precisa escolher o tipo de conjunto de dados embutido correto para seus dados. Você pode usar DelimitedText, Avro, JSON, ORC ou Parquet dependendo do formato de dados.
Tabela do Lakehouse do Microsoft Fabric no fluxo de dados de mapeamento
Para usar o Conjunto de dados de tabelas do Lakehouse do Microsoft Fabric como um conjunto de dados de origem ou coletor no fluxo de dados de mapeamento, acesse as seções a seguir para obter as configurações detalhadas.
Tabela do Microsoft Fabric Lakehouse como um tipo de origem
Não há propriedades configuráveis nas opções de origem.
Observação
No momento, o suporte à CDA para a origem da tabela do Lakehouse não está disponível.
Tabela do Microsoft Fabric Lakehouse como um tipo de coletor
As seguintes propriedades têm suporte na seção de coletor dos Fluxos de Dados de Mapeamento:
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Método Update | Ao selecionar "Permitir inserção" sozinho ou gravar em uma nova tabela delta, o destino recebe todas as linhas de entrada, independentemente das políticas de linha definidas. Se seus dados contiverem linhas de outras políticas de linha, elas precisarão ser excluídas usando uma transformação de filtro anterior. Quando todos os métodos de atualização são selecionados, uma mesclagem é executada, na qual as linhas são inseridas/excluídas/upserted/atualizadas de acordo com o conjunto de políticas de linha usando uma transformação de Alterar Linha. |
sim |
true ou false |
insertable deletable upsertable Pode ser atualizado |
| Gravação otimizada | Obtenha uma taxa de transferência mais alta para a operação de gravação por meio da otimização do modo aleatório interno em executores do Spark. Como resultado, é possível notar menos partições e arquivos de tamanho maior | não |
true ou false |
optimizedWrite: true |
| Compactar automaticamente | Após a conclusão de qualquer operação de gravação, o Spark executará automaticamente o comando OPTIMIZE para reorganizar os dados, resultando em mais partições, se necessário, para melhor leitura do desempenho no futuro |
não |
true ou false |
autoCompact: true |
| Esquema de mesclagem | A opção Mesclar esquema permite a evolução do esquema, ou seja, todas as colunas presentes no fluxo de entrada atual, mas não na tabela Delta de destino, são automaticamente adicionadas ao seu esquema. Essa opção tem suporte em todos os métodos de atualização. | não |
true ou false |
mergeSchema: true |
Exemplo: coletor de tabela do Microsoft Fabric Lakehouse
sink(allowSchemaDrift: true,
validateSchema: false,
input(
CustomerID as string,
NameStyle as string,
Title as string,
FirstName as string,
MiddleName as string,
LastName as string,
Suffix as string,
CompanyName as string,
SalesPerson as string,
EmailAddress as string,
Phone as string,
PasswordHash as string,
PasswordSalt as string,
rowguid as string,
ModifiedDate as string
),
deletable:false,
insertable:true,
updateable:false,
upsertable:false,
optimizedWrite: true,
mergeSchema: true,
autoCompact: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CustomerTable
Para o conector baseado em tabela do Fabric Lakehouse no tipo de conjunto de dados embutido, você só precisa usar o Delta como tipo de conjunto de dados. Isso permitirá que você leia e escreva dados de tabelas do Fabric Lakehouse.
Pesquisar propriedades de atividade
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Propriedades de atividade GetMetadata
Para saber detalhes sobre as propriedades, verifique Atividade GetMetadata
Excluir propriedades da atividade
Para saber mais detalhes sobre as propriedades, marque Excluir atividade
Conteúdo relacionado
Para obter uma lista dos armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os Armazenamentos de dados com suporte.