O que é a Observabilidade da Rede de Contêineres?
A Observabilidade da Rede de Contêineres é um recurso do conjunto Serviços Avançados de Rede de Contêineres. Ela fornece a você ferramentas de diagnóstico e monitoramento de nível superior, oferecendo visibilidade incomparável em suas cargas de trabalho em contêineres. Essas ferramentas permitem que você identifique e solucione problemas de rede com facilidade, garantindo o desempenho ideal para seus aplicativos.
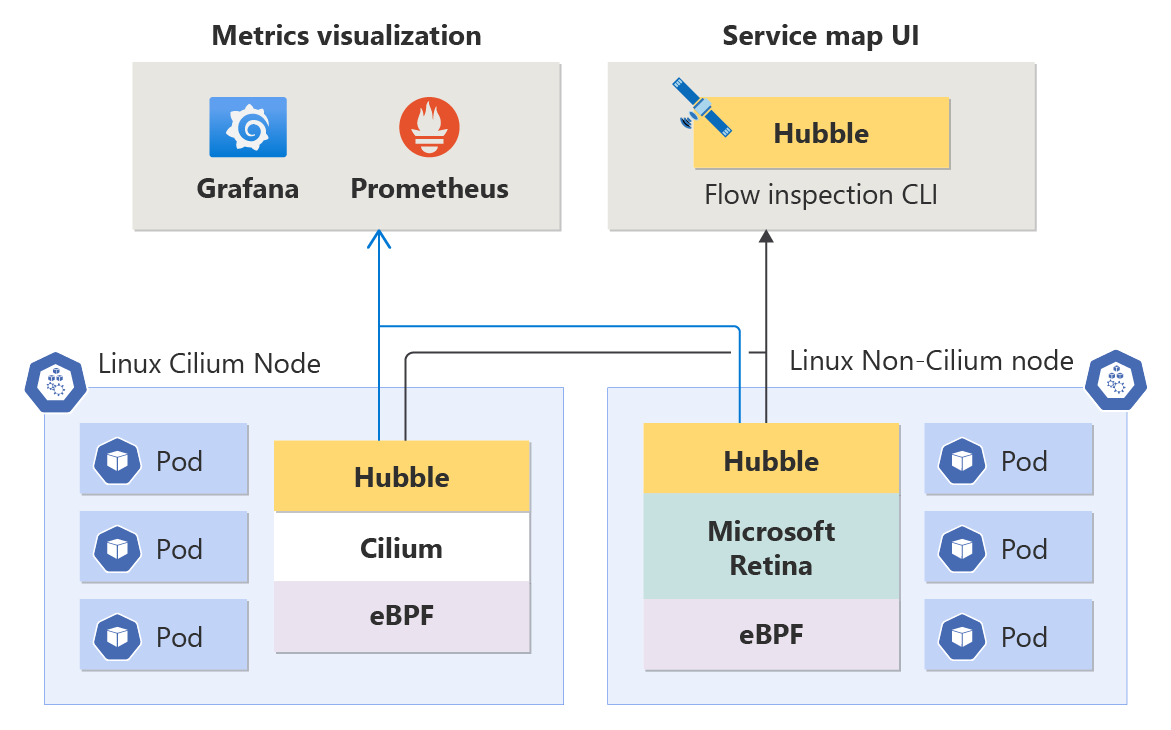
A Observabilidade da Rede de Contêineres é compatível com todas as cargas de trabalho Linux, integrando-se perfeitamente com o Hubble, independentemente de o plano de dados subjacente ser Cilium ou não-Cilium (ambos têm suporte), garantindo flexibilidade para suas necessidades de rede de contêiner.
Observação
Para cenários de plano de dados Cilium, a Observabilidade da Rede de Contêineres está disponível a partir da versão 1.29 do Kubernetes. A Observabilidade da Rede de Contêineres tem suporte em todas as distribuições Linux, incluindo o Azure Linux, a partir da versão 2.0.
Recursos da Observabilidade da Rede de Contêineres
A Observabilidade da Rede de Contêineres oferece as seguintes funcionalidades para monitorar problemas relacionados à rede em seu cluster:
Métricas no nível do nó: entender a integridade da rede de contêiner no nível do nó é crucial para manter o desempenho ideal do aplicativo. Essas métricas fornecem insights sobre volume de tráfego, pacotes removidos, número de conexões etc. por nó. As métricas são armazenadas no formato Prometheus e, como tal, você pode exibi-las no Grafana.
Métricas do Hubble (Métricas de nível de pod e DNS): essas métricas do Prometheus incluem informações de pod de origem e de destino, permitindo que você identifique problemas relacionados à rede em um nível detalhado. As métricas abrangem volume de tráfego, pacotes removidos, redefinições de TCP, fluxos de pacote L4/L7 etc. Há também métricas DNS (atualmente apenas para planos de dados não Cilium), abrangendo erros DNS e respostas ausentes de solicitações DNS.
Logs de fluxo do Hubble: os logs de fluxo fornecem visibilidade detalhada da atividade de rede do cluster. Todas as comunicações de e para pods são registradas, permitindo que você investigue problemas de conectividade ao longo do tempo. Os logs de fluxo ajudam a responder perguntas como: o servidor recebeu a solicitação do cliente? Qual é a latência de ida e volta entre a solicitação do cliente e a resposta do servidor?
CLI do Hubble: a CLI (Interface de Linha de Comando) do Hubble pode recuperar logs de fluxo em todo o cluster com filtragem e formatação personalizáveis.
Interface do usuário do Hubble: a interface do usuário do Hubble é uma interface baseada em navegador simples para explorar a atividade de rede do cluster. Ele cria um grafo de conexão de serviço com base em logs de fluxo e exibe logs de fluxo para o namespace selecionado. Os usuários são responsáveis por provisionar e gerenciar a infraestrutura necessária para executar a interface do usuário do Hubble.
Benefícios Chave da Observabilidade da Rede de Contêineres
Independente de CNI: com suporte em todas as variantes de CNI do Azure, incluindo kubenet.
Cilium e não Cilium: fornece uma experiência uniforme e integrada em planos de dados Cilium e não Cilium.
Observabilidade de rede baseada em eBPF: aproveita o eBPF (extended Berkeley Packet Filter) para obter desempenho e escalabilidade para identificar possíveis gargalos e problemas de congestionamento antes que eles afetem o desempenho do aplicativo. Obtenha insights sobre os principais indicadores de integridade da rede, incluindo volume de tráfego, pacotes removidos e informações de conexão.
Visibilidade detalhada da atividade de rede: entenda como seus aplicativos estão se comunicando entre si por meio de logs de fluxo de rede detalhados.
Opções de armazenamento e visualização de métricas simplificadas: escolha entre:
- Prometheus e Grafana gerenciados pelo Azure: o Azure gerencia a infraestrutura e a manutenção, permitindo que os usuários se concentrem em configurar métricas e visualizar métricas.
- Traga seu próprio (BYO) Prometheus e Grafana: os usuários implantam e configuram suas próprias instâncias e gerenciam a infraestrutura subjacente.
Métricas
Métricas no nível do nó
As métricas a seguir são agregadas por nó. Todas as métricas incluem etiquetas:
clusterinstance(nome do nó)
Para cenários de plano de dados Cilium, a Observabilidade da Rede de Contêineres fornece métricas apenas para Linux, o Windows atualmente está sem suporte. O Cilium expõe várias métricas, incluindo as seguintes usadas pela Observabilidade da Rede de Contêineres.
| Nome da métrica | Descrição | Etiquetas adicionais | Linux | Windows |
|---|---|---|---|---|
| cilium_forward_count_total | Número total de pacotes encaminhados | direction |
✅ | ❌ |
| cilium_forward_bytes_total | Número total de bytes encaminhados | direction |
✅ | ❌ |
| cilium_drop_count_total | Número total de pacotes descartados | direction, reason |
✅ | ❌ |
| cilium_drop_bytes_total | Número total de bytes descartados | direction, reason |
✅ | ❌ |
Métricas de nível de pod (Métricas do Hubble)
As métricas a seguir são agregadas por pod (as informações do nó são preservadas). Todas as métricas incluem etiquetas:
clusterinstance(nome do nó)sourceoudestination
Para tráfego de saída, haverá uma etiqueta source com nome/namespace do pod de origem.
Para tráfego de entrada, haverá uma etiqueta destination com nome/namespace do pod de destino.
| Nome da métrica | Descrição | Etiquetas adicionais | Linux | Windows |
|---|---|---|---|---|
| hubble_dns_queries_total | Total de solicitações DNS por consulta | source ou destination, query, qtypes (tipo de consulta) |
✅ | ❌ |
| hubble_dns_responses_total | Total de respostas DNS por consulta/resposta | source ou destination, query, qtypes (tipo de consulta), rcode (código de retorno), ips_returned (número de IPs) |
✅ | ❌ |
| hubble_drop_total | Número total de pacotes descartados | source ou destination, protocol, reason |
✅ | ❌ |
| hubble_tcp_flags_total | Número total de pacotes TCP por sinalizador. | source ou destination, flag |
✅ | ❌ |
| hubble_flows_processed_total | Total de fluxos de rede processados (tráfego L4/L7) | source ou destination, protocol, verdict, type, subtype |
✅ | ❌ |
Limitações
- As métricas no nível do pod estão disponíveis apenas no Linux.
- Há suporte para o plano de dados Cilium a partir do Kubernetes versão 1.29.
- As etiquetas de métrica podem ter poucas diferenças entre clusters Cilium e não Cilium.
- Para clusters baseados em Cilium, as métricas DNS estão disponíveis apenas para pods que têm Políticas de Rede Cilium (CNP) configuradas em seus clusters.
- Logs de fluxo não estão disponíveis atualmente na nuvem desconectada.
- A retransmissão do Hubble pode falhar se um dos agentes de nó do Hubble cair e pode causar interrupções na CLI do Hubble.
Escala
O Prometheus e o Grafana gerenciados pelo Azure impõem limitações de escala específicas ao serviço. Para obter mais informações, confira Extrair métricas do Prometheus em escala no Azure Monitor.
Preços
Importante
Os Serviços Avançados de Rede de Contêineres são uma oferta paga. Para obter mais informações sobre o preço, consulte Serviços Avançados de Rede de Contêineres – Preço.
Próximas etapas
- Para criar um cluster do AKS com Observabilidade da Rede de Contêineres, consulte Configurar a Observabilidade da Rede de Contêineres para o Serviço de Kubernetes do Azure (AKS).

Azure Kubernetes Service