Rozwiązywanie problemów z zapytaniami, które wydają się nigdy nie kończyć w programie SQL Server
W tym artykule opisano kroki rozwiązywania problemu polegające na tym, że masz zapytanie, które wydaje się nigdy nie zostać ukończone, lub ukończenie jego ukończenia może potrwać wiele godzin lub dni.
Co to jest niekończące się zapytanie?
Ten dokument koncentruje się na zapytaniach, które nadal są wykonywane lub kompilowane, czyli ich procesor CPU nadal rośnie. Nie ma zastosowania do zapytań, które są zablokowane lub oczekują na jakiś zasób, który nigdy nie jest zwalniany (procesor pozostaje stały lub zmienia się bardzo mało).
Ważne
Jeśli zapytanie pozostanie do zakończenia jego wykonywania, zostanie zakończone. Może to potrwać zaledwie kilka sekund lub może potrwać kilka dni.
Termin niekończący się jest używany do opisywania postrzegania zapytania, które nie kończy się w rzeczywistości, zapytanie zostanie ostatecznie ukończone.
Identyfikowanie niekończącego się zapytania
Aby określić, czy zapytanie jest stale wykonywane, czy zablokowane w wąskim gardło, wykonaj następujące kroki:
Uruchom poniższe zapytanie:
DECLARE @cntr int = 0 WHILE (@cntr < 3) BEGIN SELECT TOP 10 s.session_id, r.status, r.wait_time, r.wait_type, r.wait_resource, r.cpu_time, r.logical_reads, r.reads, r.writes, r.total_elapsed_time / (1000 * 60) 'Elaps M', SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1, ((CASE r.statement_end_offset WHEN -1 THEN DATALENGTH(st.TEXT) ELSE r.statement_end_offset END - r.statement_start_offset) / 2) + 1) AS statement_text, COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid)) + N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text, r.command, s.login_name, s.host_name, s.program_name, s.last_request_end_time, s.login_time, r.open_transaction_count, atrn.name as transaction_name, atrn.transaction_id, atrn.transaction_state FROM sys.dm_exec_sessions AS s JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st LEFT JOIN (sys.dm_tran_session_transactions AS stran JOIN sys.dm_tran_active_transactions AS atrn ON stran.transaction_id = atrn.transaction_id) ON stran.session_id =s.session_id WHERE r.session_id != @@SPID ORDER BY r.cpu_time DESC SET @cntr = @cntr + 1 WAITFOR DELAY '00:00:05' ENDSprawdź przykładowe dane wyjściowe.
Kroki rozwiązywania problemów w tym artykule mają zastosowanie w szczególności, gdy zauważysz dane wyjściowe podobne do następujących, w których procesor CPU zwiększa się proporcjonalnie wraz z upływem czasu bez znaczących czasów oczekiwania. Należy pamiętać, że w tym przypadku zmiany
logical_readsnie są istotne, ponieważ niektóre żądania T-SQL powiązane z procesorem CPU mogą w ogóle nie wykonywać żadnych operacji odczytu logicznego (na przykład wykonywania obliczeń lubWHILEpętli).session_id status cpu_time logical_reads wait_time wait_type 56 uruchomiono 7038 101000 0 NULL 56 runnable 12040 301000 0 NULL 56 uruchomiono 17020 523000 0 NULL Ten artykuł nie ma zastosowania, jeśli obserwujesz scenariusz oczekiwania podobny do poniższego, w którym procesor CPU nie zmienia się lub zmienia się bardzo nieznacznie, a sesja czeka na zasób.
session_id status cpu_time logical_reads wait_time wait_type 56 zawieszony 0 3 8312 LCK_M_U 56 zawieszony 0 3 13318 LCK_M_U 56 zawieszony 0 5 18331 LCK_M_U
Aby uzyskać więcej informacji, zobacz Diagnozowanie oczekiwań lub wąskich gardeł.
Długi czas kompilacji
W rzadkich przypadkach można zauważyć, że procesor CPU stale rośnie w czasie, ale nie jest napędzany przez wykonywanie zapytań. Zamiast tego może to być spowodowane nadmiernie długą kompilacją (analizowanie i kompilowanie zapytania). W takich przypadkach sprawdź kolumnę danych wyjściowych transaction_name i poszukaj wartości sqlsource_transform. Ta nazwa transakcji wskazuje kompilację.
Zbieranie danych diagnostycznych
- SQL Server 2008 — SQL Server 2014 (wcześniejsze niż SP2)
- SQL Server 2014 (po sp2) i SQL Server 2016 (przed dodatkiem SP1)
- SQL Server 2016 (po sp1) i SQL Server 2017
- SQL Server 2019 i nowsze wersje
Aby zebrać dane diagnostyczne przy użyciu programu SQL Server Management Studio (SSMS), wykonaj następujące kroki:
Przechwyć szacowany kod XML planu wykonywania zapytania.
Przejrzyj plan zapytania, aby sprawdzić, czy istnieją oczywiste wskazania, skąd może pochodzić spowolnienie. Typowe przykłady:
- Skanowanie tabeli lub indeksu (spójrz na szacowane wiersze).
- Zagnieżdżone pętle sterowane przez ogromny zewnętrzny zestaw danych tabeli.
- Zagnieżdżone pętle z dużą gałęzią w wewnętrznej części pętli.
- tabel.
- Funkcje na
SELECTliście, które zajmują dużo czasu na przetworzenie każdego wiersza.
Jeśli zapytanie działa szybko w dowolnym momencie, możesz przechwycić "szybkie" wykonania rzeczywistego planu wykonywania XML do porównania.
Metoda przeglądania zebranych planów
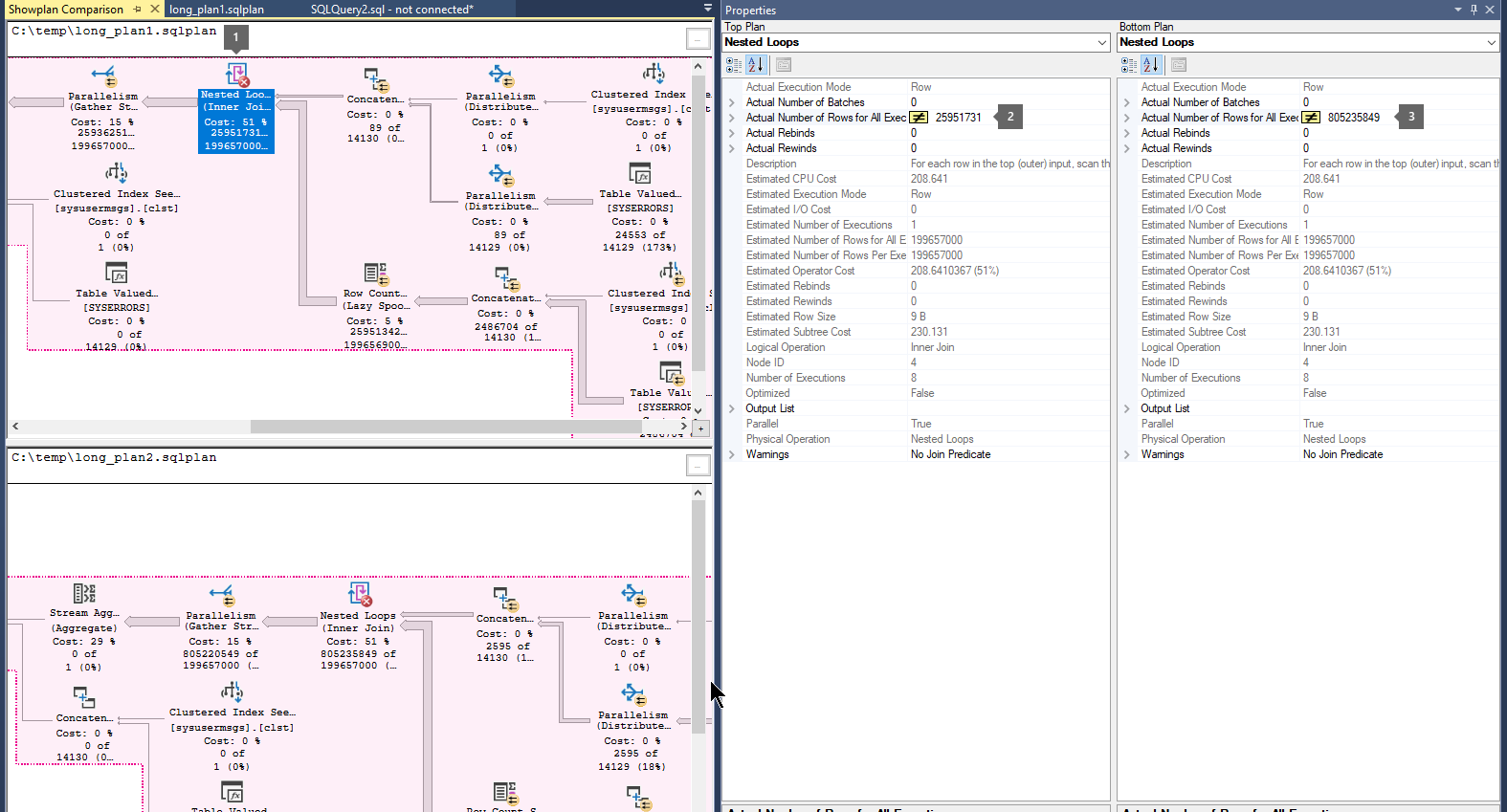
W tej sekcji przedstawiono sposób przeglądania zebranych danych. Będzie ona używać wielu planów zapytań XML (przy użyciu rozszerzenia *.sqlplan) zebranych w programie SQL Server 2016 SP1 i nowszych kompilacjach i wersjach.
Wykonaj następujące kroki, aby porównać plany wykonywania:
Otwórz wcześniej zapisany plik planu wykonywania zapytania (.sqlplan).
Kliknij prawym przyciskiem myszy pusty obszar planu wykonania i wybierz pozycję Porównaj showplan.
Wybierz drugi plik planu zapytania, który chcesz porównać.
Poszukaj grubych strzałek, które wskazują dużą liczbę wierszy przepływających między operatorami. Następnie wybierz operator przed strzałką lub po nim i porównaj liczbę rzeczywistych wierszy w dwóch planach.
Porównaj drugie i trzecie plany, aby sprawdzić, czy największy przepływ wierszy występuje w tych samych operatorach.
Oto przykład:

Rozwiązanie
Upewnij się, że statystyki są aktualizowane dla tabel używanych w zapytaniu.
Wyszukaj brakujące zalecenie dotyczące indeksu w planie zapytania i zastosuj dowolne.
Zastąp ponownie zapytanie, aby uprościć je:
- Użyj bardziej selektywnych
WHEREpredykatów, aby zmniejszyć ilość przetwarzanych danych z góry. - Rozbić go od siebie.
- Wybierz niektóre części w tabelach tymczasowych i dołącz je później.
- Usuń
TOPwartości ,EXISTSiFAST(T-SQL) w zapytaniach uruchamianych przez bardzo długi czas ze względu na cel wiersza optymalizatora. Alternatywnie możesz użyćDISABLE_OPTIMIZER_ROWGOALwskazówki. Aby uzyskać więcej informacji, zobacz Row Goals Gone Rogue. - Unikaj używania typowych wyrażeń tabel (CTE) w takich przypadkach, jak łączą instrukcje w jednym dużym zapytaniu.
- Użyj bardziej selektywnych
Spróbuj użyć wskazówek dotyczących zapytań , aby utworzyć lepszy plan:
HASH JOINlubMERGE JOINwskazówkaFORCE ORDERaluzjaFORCESEEKaluzjaRECOMPILE- UŻYJ
PLAN N'<xml_plan>', jeśli masz szybki plan zapytania, który możesz wymusić
Użyj magazynu zapytań (QDS), aby wymusić dobry plan, jeśli taki plan istnieje i czy wersja programu SQL Server obsługuje magazyn zapytań.
Diagnozowanie oczekiwań lub wąskich gardeł
Ta sekcja jest zawarta tutaj jako odwołanie w przypadku, gdy problem nie jest długotrwałym zapytaniem kierującym procesorEM CPU. Można go użyć do rozwiązywania problemów z zapytaniami, które są długotrwałe z powodu oczekiwania.
Aby zoptymalizować zapytanie oczekujące na wąskie gardła, zidentyfikuj czas oczekiwania i miejsce wąskiego gardła (typ oczekiwania). Po potwierdzeniu typu oczekiwania zmniejsz czas oczekiwania lub całkowicie zlikwiduj oczekiwanie.
Aby obliczyć przybliżony czas oczekiwania, odejmij czas procesora CPU (czas procesu roboczego) od czasu, który upłynął w zapytaniu. Zazwyczaj czas procesora CPU to rzeczywisty czas wykonywania, a pozostała część okresu istnienia zapytania oczekuje.
Przykłady obliczania przybliżonego czasu trwania oczekiwania:
| Czas upływu (ms) | Czas procesora CPU (ms) | Czas oczekiwania (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Identyfikowanie wąskiego gardła lub oczekiwania
Aby zidentyfikować historyczne długotrwałe zapytania (na przykład >20% ogólnego czasu oczekiwania, czyli czas oczekiwania), uruchom następujące zapytanie. To zapytanie używa statystyk wydajności dla buforowanych planów zapytań od początku programu SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCAby zidentyfikować aktualnie wykonywane zapytania z oczekiwaniami dłuższymi niż 500 ms, uruchom następujące zapytanie:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Jeśli możesz zebrać plan zapytania, sprawdź wartości WaitStats z właściwości planu wykonywania w programie SSMS:
- Uruchom zapytanie z włączonym uwzględnij rzeczywisty plan wykonania .
- Kliknij prawym przyciskiem myszy operator najbardziej po lewej stronie na karcie Plan wykonania
- Wybierz pozycję Właściwości , a następnie właściwość WaitStats .
- Sprawdź wartości WaitTimeMs i WaitType.
Jeśli znasz scenariusze PSSDiag/SQLdiag lub SQL LogScout LightPerf/GeneralPerf, rozważ użycie jednej z nich do zbierania statystyk wydajności i identyfikowania oczekujących zapytań w wystąpieniu programu SQL Server. Zebrane pliki danych można zaimportować i przeanalizować dane wydajności za pomocą narzędzia SQL Nexus.
Odwołania pomagające wyeliminować lub zmniejszyć oczekiwania
Przyczyny i rozwiązania dla każdego typu oczekiwania różnią się. Nie ma jednej ogólnej metody rozpoznawania wszystkich typów oczekiwania. Poniżej przedstawiono artykuły umożliwiające rozwiązywanie typowych problemów z typem oczekiwania:
- Omówienie i rozwiązywanie problemów z blokowaniem (LCK_M_*)
- Omówienie i rozwiązywanie problemów z blokowaniem usługi Azure SQL Database
- Rozwiązywanie problemów z niską wydajnością programu SQL Server spowodowanych problemami we/wy (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Rozwiązywanie problemu ze wstawianiem ostatniej strony PAGELATCH_EX w programie SQL Server
- Pamięć udziela wyjaśnień i rozwiązań (RESOURCE_SEMAPHORE)
- Rozwiązywanie problemów z powolnymi zapytaniami, które wynikają z typu oczekiwania ASYNC_NETWORK_IO
- Rozwiązywanie problemów z wysokim typem oczekiwania HADR_SYNC_COMMIT z zawsze włączonymi grupami dostępności
- Jak to działa: CMEMTHREAD i debugowanie
- Wykonywanie równoległości czeka na działanie (CXPACKET i CXCONSUMER)
- OCZEKIWANIE NA PULĘ WĄTKÓW
Opisy wielu typów oczekiwania i wskazywanych przez nie elementów można znaleźć w tabeli Typy oczekiwania.