Eksplorowanie architektury rozwiązania
Przyjrzyjmy się architekturze, na której podjęto decyzję o przepływie pracy operacji uczenia maszynowego (MLOps), aby zrozumieć, gdzie i kiedy należy zweryfikować kod.
Uwaga
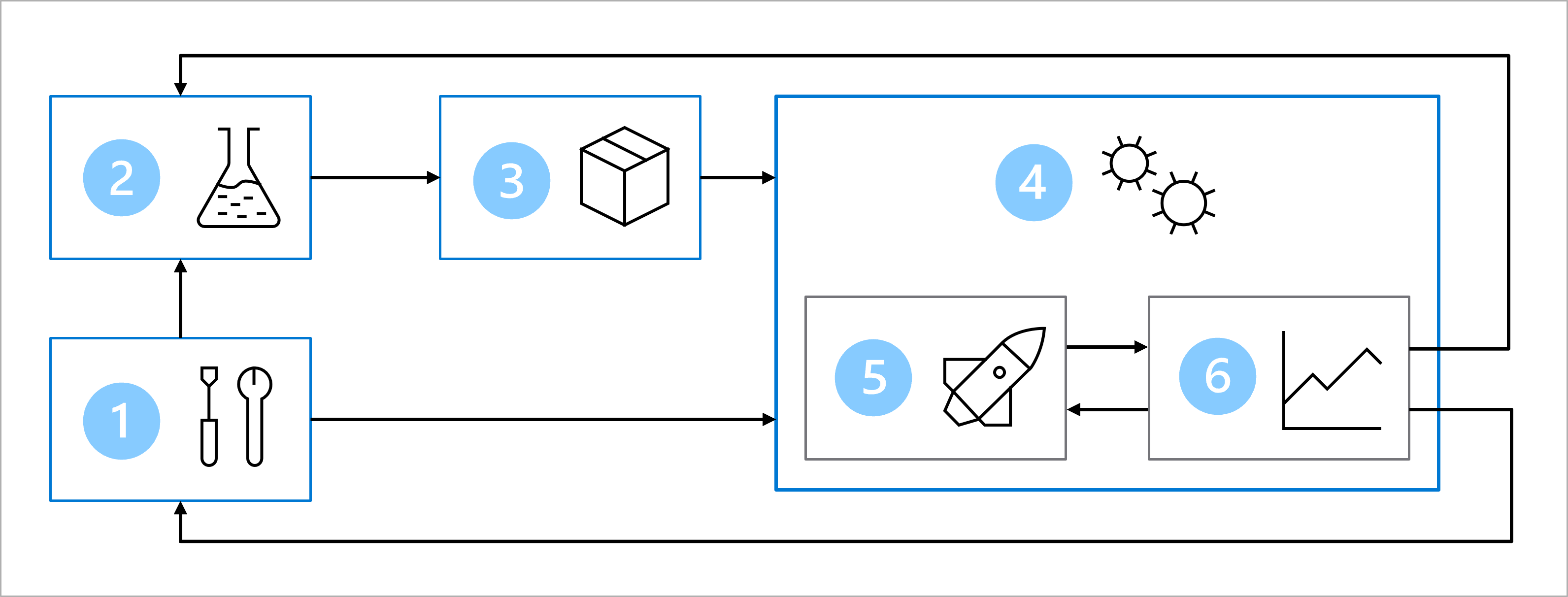
Diagram jest uproszczoną reprezentacją architektury MLOps. Aby wyświetlić bardziej szczegółową architekturę, zapoznaj się z różnymi przypadkami użycia w akceleratorze rozwiązań MLOps (v2).
Głównym celem architektury MLOps jest utworzenie niezawodnego i powtarzalnego rozwiązania. Aby osiągnąć ten cel, architektura obejmuje następujące elementy:
- Konfiguracja: utwórz wszystkie niezbędne zasoby platformy Azure dla rozwiązania.
- Programowanie modelu (pętla wewnętrzna): Eksplorowanie i przetwarzanie danych w celu trenowania i oceniania modelu.
- Ciągła integracja: pakowanie i rejestrowanie modelu.
- Wdrażanie modelu (pętla zewnętrzna): wdrażanie modelu.
- Ciągłe wdrażanie: przetestuj model i podwyższ poziom do środowiska produkcyjnego.
- Monitorowanie: Monitorowanie wydajności modelu i punktu końcowego.
Aby przenieść model z programowania do wdrożenia, potrzebujesz ciągłej integracji. Podczas ciągłej integracji utworzysz pakiet i zarejestrujesz model. Zanim jednak spakujesz model, musisz zweryfikować kod używany do trenowania modelu.
Wraz z zespołem ds. nauki o danych uzgodniono korzystanie z programowania opartego na magistrali. Nie tylko będzie chronić kod produkcyjny, ale także automatycznie weryfikować proponowane zmiany przed scaleniem go z kodem produkcyjnym.
Przyjrzyjmy się przepływowi pracy analityka danych:
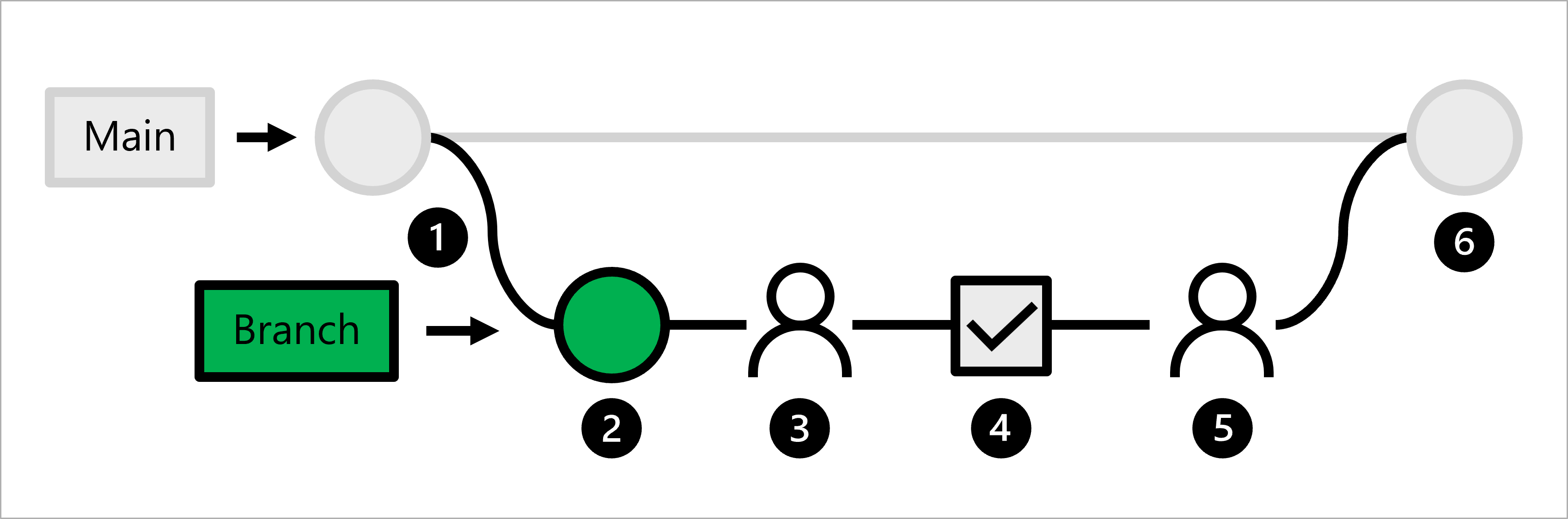
- Kod produkcyjny jest hostowany w gałęzi głównej.
- Analityk danych tworzy gałąź cech na potrzeby tworzenia modeli.
- Analityk danych tworzy żądanie ściągnięcia, aby zaproponować wypychanie zmian do gałęzi głównej.
- Po utworzeniu żądania ściągnięcia zostanie wyzwolony przepływ pracy funkcji GitHub Actions w celu zweryfikowania kodu.
- Gdy kod przejdzie testy lintingu i jednostkowe, główny analityk danych musi zatwierdzić proponowane zmiany.
- Po zatwierdzeniu zmian przez głównego analityka danych żądanie ściągnięcia zostanie scalone, a gałąź główna zostanie odpowiednio zaktualizowana.
Jako inżynier uczenia maszynowego musisz utworzyć przepływ pracy funkcji GitHub Actions, który weryfikuje kod, uruchamiając linter i testy jednostkowe przy każdym utworzeniu żądania ściągnięcia.
Napiwek
Dowiedz się więcej o sposobie pracy z kontrolą źródła dla projektów uczenia maszynowego, w tym programowanie oparte na magistrali i weryfikowanie kodu lokalnie.