Optymalizowanie tabel różnicowych
Platforma Spark to platforma przetwarzania równoległego z danymi przechowywanymi w co najmniej jednym węźle roboczym. Ponadto pliki Parquet są niezmienne, a nowe pliki są zapisywane dla każdej aktualizacji lub usunięcia. Ten proces może spowodować, że platforma Spark przechowuje dane w dużej liczbie małych plików, znanych jako problem z małym plikiem . Oznacza to, że zapytania dotyczące dużych ilości danych mogą działać wolno, a nawet zakończyć się niepowodzeniem.
OptimizeWrite, funkcja
OptimizeWrite to funkcja usługi Delta Lake, która zmniejsza liczbę plików podczas ich zapisywania. Zamiast pisać wiele małych plików, zapisuje mniej większych plików. Pomaga to zapobiec problemowi z małymi plikami i zapewnić, że wydajność nie jest obniżona.
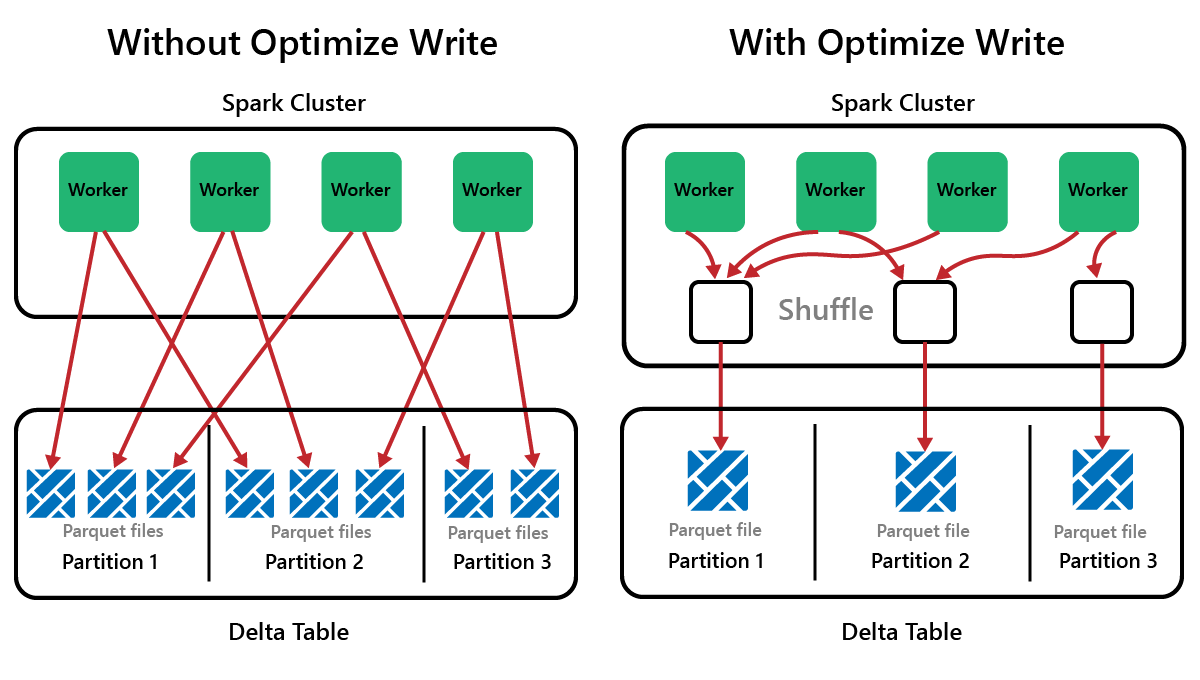
W usłudze Microsoft Fabric OptimizeWrite jest domyślnie włączona. Możesz ją włączyć lub wyłączyć na poziomie sesji platformy Spark:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
Uwaga
OptimizeWrite Można również ustawić we właściwościach tabeli i dla poszczególnych poleceń zapisu.
Optymalizacja
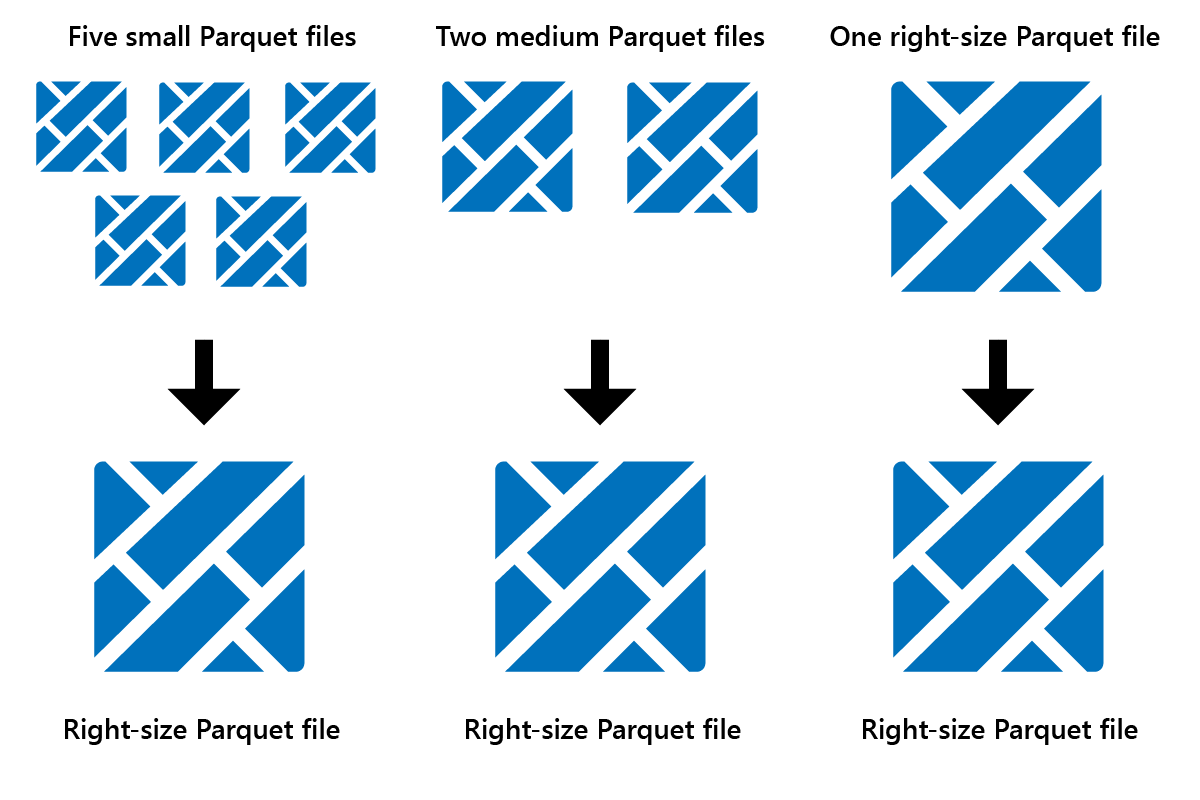
Optymalizacja to funkcja konserwacji tabeli, która konsoliduje małe pliki Parquet w mniej dużych plikach. Po załadowaniu dużych tabel możesz uruchomić polecenie Optimize (Optymalizowanie) w wyniku:
- mniej większych plików
- lepsza kompresja
- efektywna dystrybucja danych między węzłami
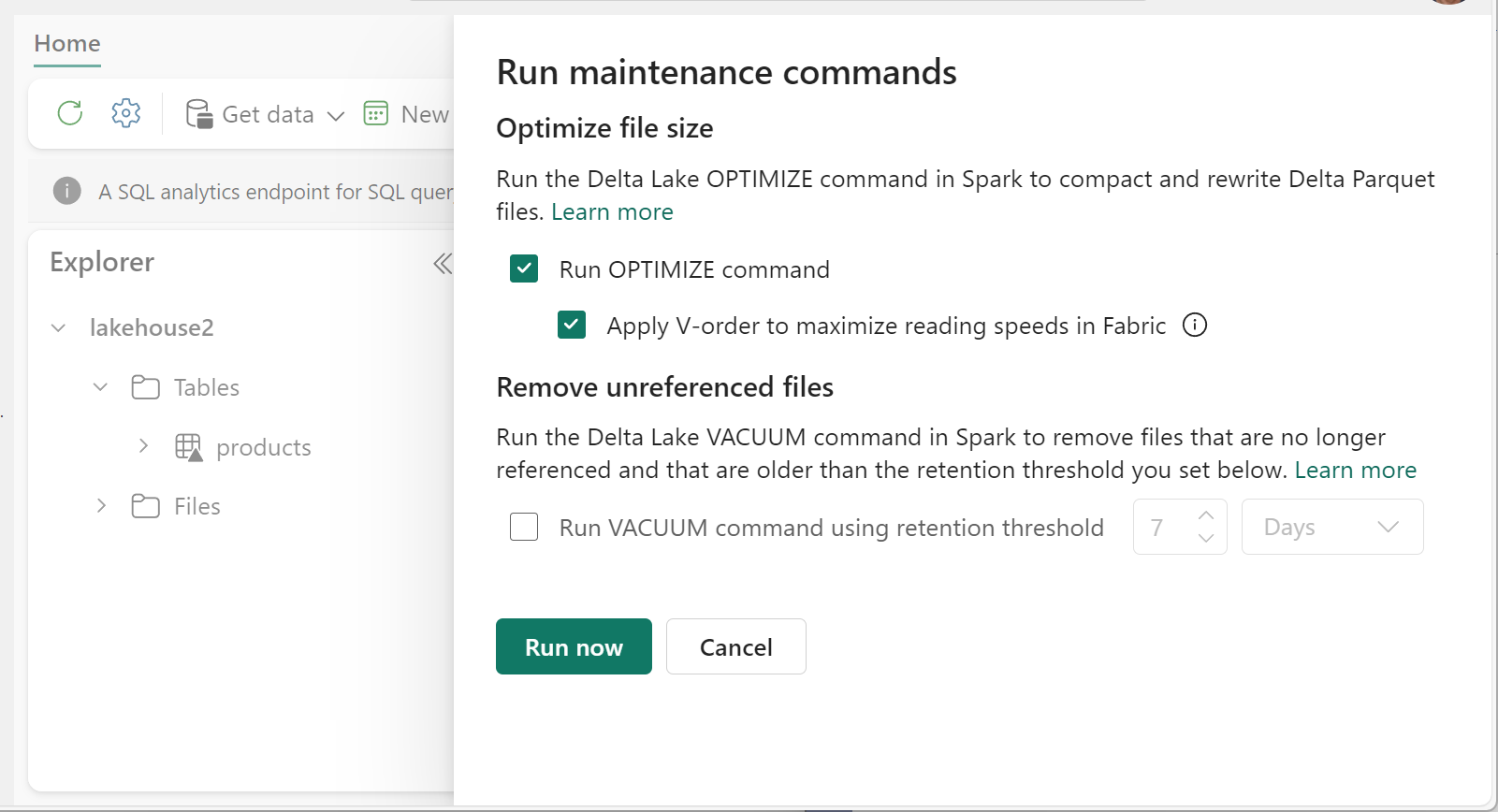
Aby uruchomić polecenie Optimize:
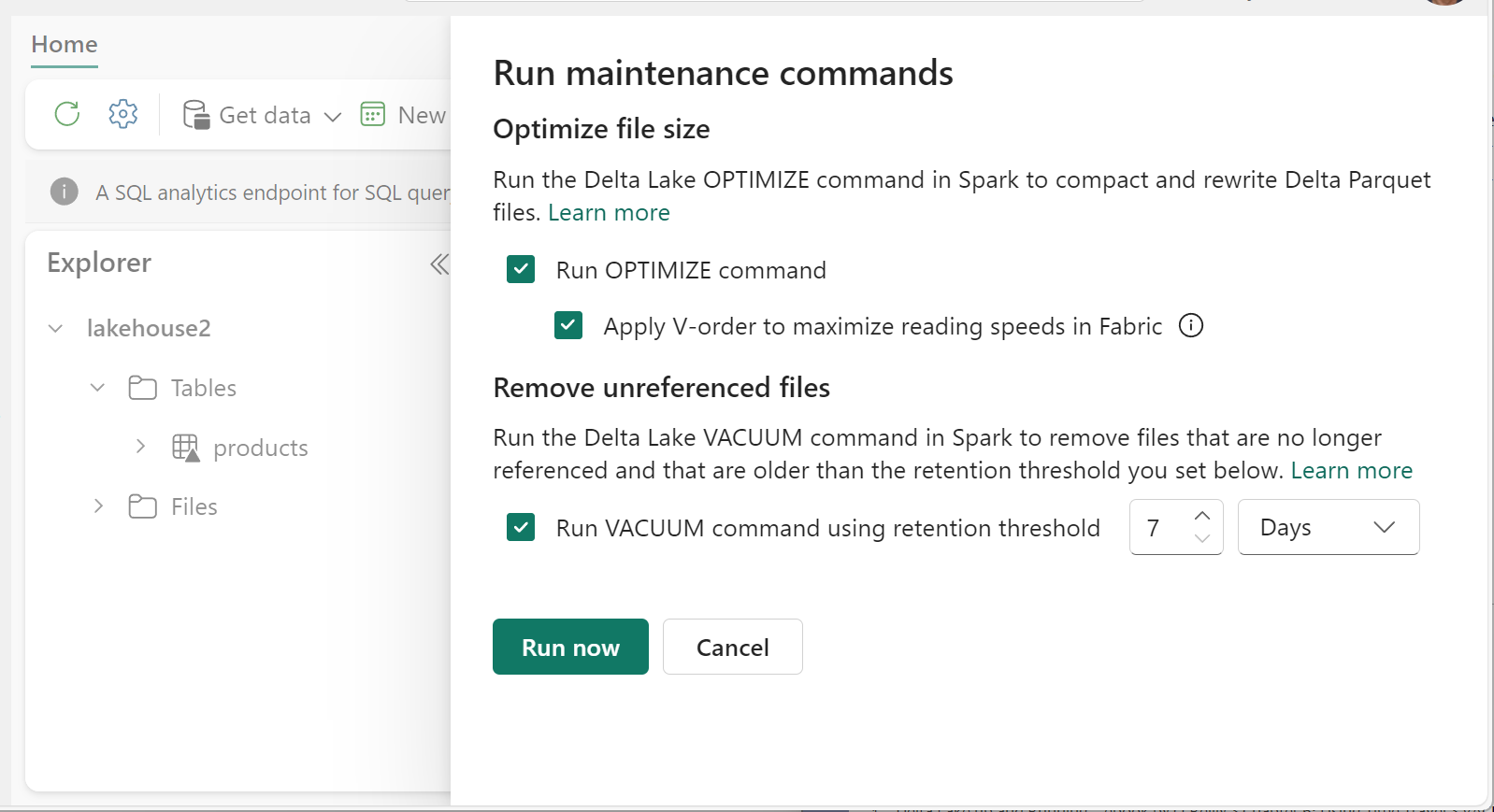
- W eksploratorze lakehouse wybierz pozycję ... obok nazwy tabeli wybierz pozycję Konserwacja.
- Wybierz polecenie Uruchom OPTYMALIZACJĘ.
- Opcjonalnie wybierz pozycję Zastosuj kolejność V, aby zmaksymalizować szybkość odczytu w sieci szkieletowej.
- Wybierz opcję Uruchom teraz.
V-Order, funkcja
Po uruchomieniu polecenia Optimize można opcjonalnie uruchomić polecenie V-Order, które jest przeznaczone dla formatu pliku Parquet w sieci szkieletowej. Funkcja V-Order umożliwia szybkie odczyty z czasem dostępu do danych przypominających pamięć. Zwiększa również efektywność kosztową, ponieważ zmniejsza zasoby sieciowe, dyskowe i procesora CPU podczas odczytu.
Kolejność wirtualna jest domyślnie włączona w usłudze Microsoft Fabric i jest stosowana w miarę zapisywania danych. Wiąże się to z niewielkim obciążeniem około 15% co sprawia, że zapisy są nieco wolniejsze. Jednak kolejność maszyn wirtualnych umożliwia szybsze odczyty z aparatów obliczeniowych usługi Microsoft Fabric, takich jak Power BI, SQL, Spark i inne.
W usłudze Microsoft Fabric aparaty Power BI i SQL korzystają z technologii Microsoft Verti-Scan, która w pełni wykorzystuje optymalizację zamówień wirtualnych w celu przyspieszenia odczytu. Platforma Spark i inne aparaty nie korzystają z technologii VertiScan, ale nadal korzystają z optymalizacji zamówień wirtualnych o około 10% szybszego odczytu, czasami nawet 50%.
Funkcja V-Order działa przez zastosowanie specjalnego sortowania, dystrybucji grup wierszy, kodowania słownika i kompresji w plikach Parquet. Jest on w 100% zgodny z formatem open source Parquet, a wszystkie aparaty Parquet mogą go odczytać.
Kolejność V-Order może nie być przydatna w scenariuszach intensywnie korzystających z zapisu, takich jak przejściowe magazyny danych, w których dane są odczytywane tylko raz lub dwa razy. W takich sytuacjach wyłączenie polecenia V-Order może skrócić całkowity czas przetwarzania pozyskiwania danych.
Zastosuj kolejność wirtualną do poszczególnych tabel przy użyciu funkcji Konserwacja tabeli, uruchamiając OPTIMIZE polecenie .
Vacuum
Polecenie VACUUM umożliwia usunięcie starych plików danych.
Za każdym razem, gdy jest wykonywana aktualizacja lub usuwanie, tworzony jest nowy plik Parquet i wpis w dzienniku transakcji. Stare pliki Parquet są zachowywane w celu umożliwienia podróży w czasie, co oznacza, że pliki Parquet gromadzą się w czasie.
Polecenie VACUUM usuwa stare pliki danych Parquet, ale nie dzienniki transakcji. Po uruchomieniu funkcji VACUUM nie można wrócić wcześniej niż okres przechowywania.
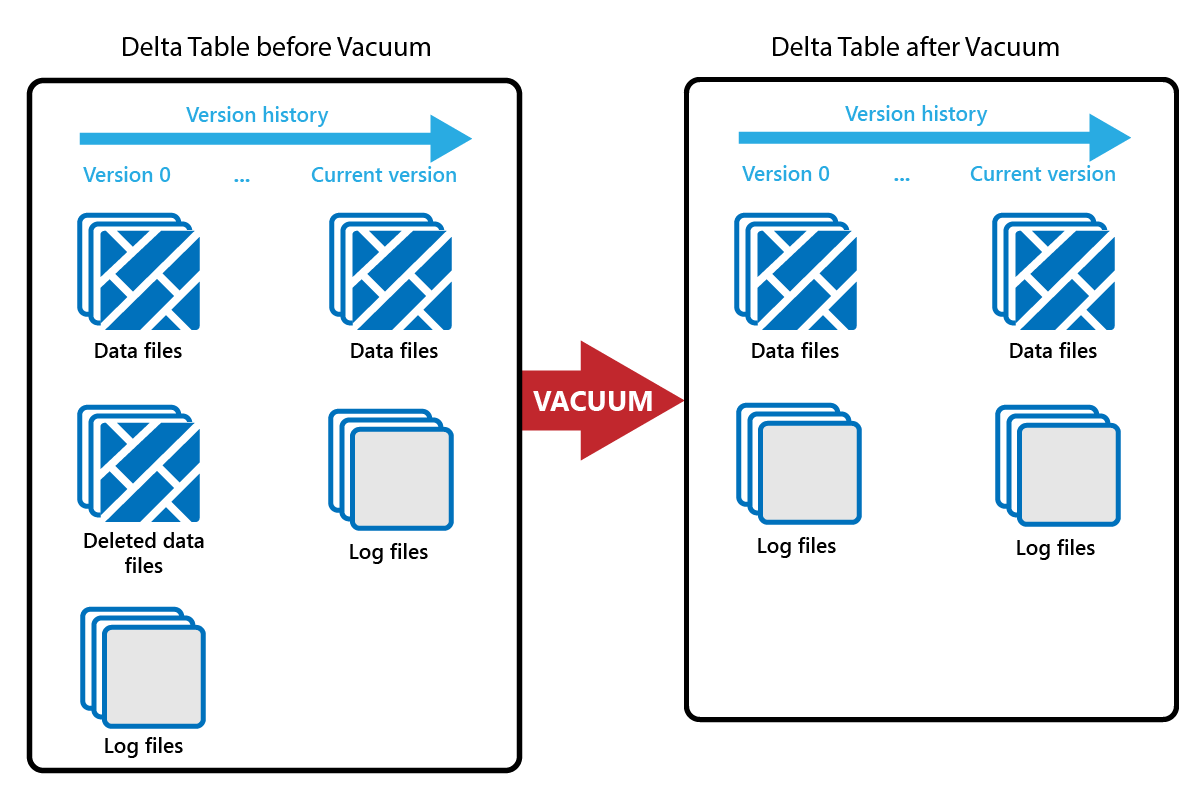
Pliki danych, które nie są obecnie przywoływane w dzienniku transakcji i które są starsze niż określony okres przechowywania, są trwale usuwane przez uruchomienie funkcji VACUUM. Wybierz okres przechowywania na podstawie takich czynników jak:
- Wymagania dotyczące przechowywania danych
- Rozmiar danych i koszty magazynowania
- Częstotliwość zmiany danych
- wymagania prawne,
Domyślny okres przechowywania wynosi 7 dni (168 godzin), a system uniemożliwia korzystanie z krótszego okresu przechowywania.
Narzędzie VACUUM można uruchamiać w trybie ad hoc lub zaplanowane przy użyciu notesów sieci szkieletowej.
Uruchom polecenie VACUUM dla poszczególnych tabel przy użyciu funkcji konserwacji tabeli:
- W eksploratorze lakehouse wybierz pozycję ... obok nazwy tabeli wybierz pozycję Konserwacja.
- Wybierz pozycję Uruchom polecenie VACUUM przy użyciu progu przechowywania i ustaw próg przechowywania.
- Wybierz opcję Uruchom teraz.
Możesz również uruchomić polecenie VACUUM jako polecenie SQL w notesie:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
Funkcja VACUUM zatwierdza dziennik transakcji delty, dzięki czemu można wyświetlić poprzednie uruchomienia w sekcji DESCRIBE HISTORY.
%%sql
DESCRIBE HISTORY lakehouse2.products;
Partycjonowanie tabel różnicowych
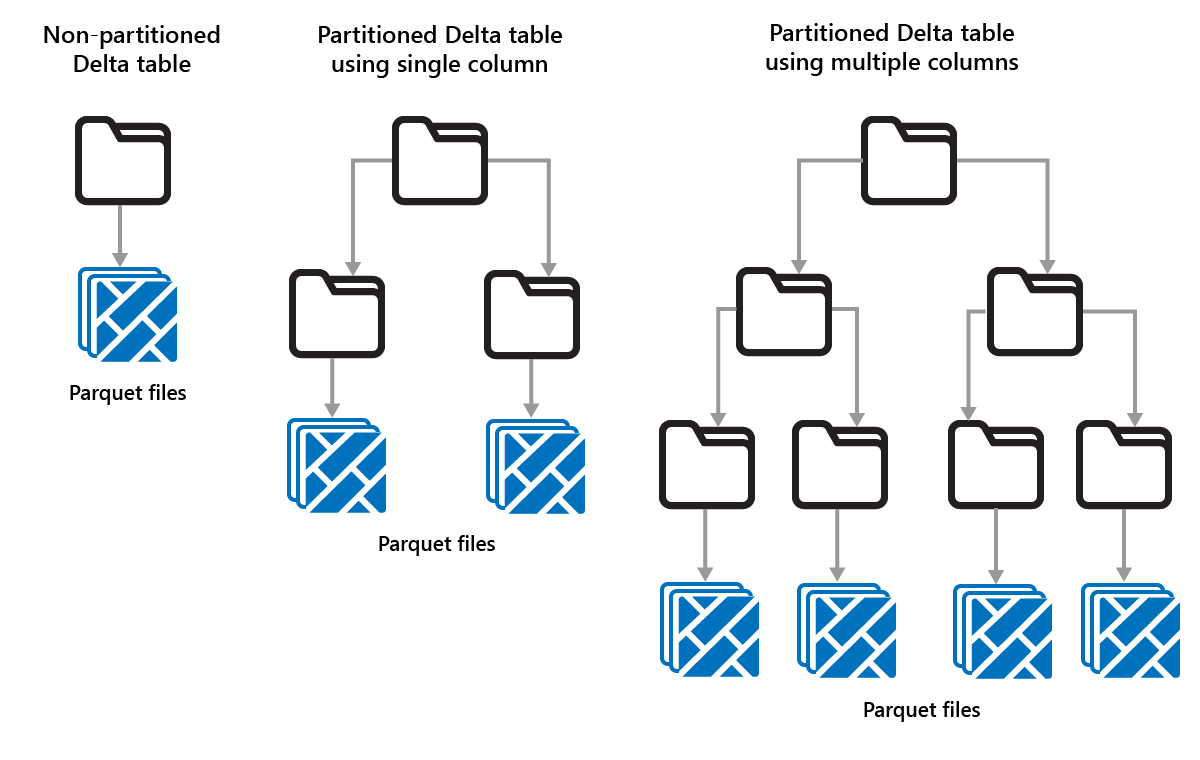
Usługa Delta Lake umożliwia organizowanie danych w partycje. Może to poprawić wydajność, włączając pomijanie danych, co zwiększa wydajność przez pomijanie nieistotnych obiektów danych na podstawie metadanych obiektu.
Rozważ sytuację, w której są przechowywane duże ilości danych sprzedaży. Dane sprzedaży można podzielić na partycje według roku. Partycje są przechowywane w podfolderach o nazwie "year=2021", "year=2022" itp. Jeśli chcesz tylko zgłosić dane sprzedaży na rok 2024, partycje z innych lat można pominąć, co zwiększa wydajność odczytu.
Partycjonowanie małych ilości danych może jednak obniżyć wydajność, ponieważ zwiększa liczbę plików i może zaostrzyć "problem z małymi plikami".
Użyj partycjonowania w przypadku:
- Masz bardzo duże ilości danych.
- Tabele można podzielić na kilka dużych partycji.
Nie używaj partycjonowania w przypadku:
- Woluminy danych są małe.
- Kolumna partycjonowania ma wysoką kardynalność, ponieważ tworzy dużą liczbę partycji.
- Kolumna partycjonowania spowoduje powstanie wielu poziomów.
Partycje są stałym układem danych i nie dostosowują się do różnych wzorców zapytań. Rozważając sposób używania partycjonowania, zastanów się, jak są używane dane i ich stopień szczegółowości.
W tym przykładzie ramka danych zawierająca dane produktu jest partycjonowana według kategorii:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
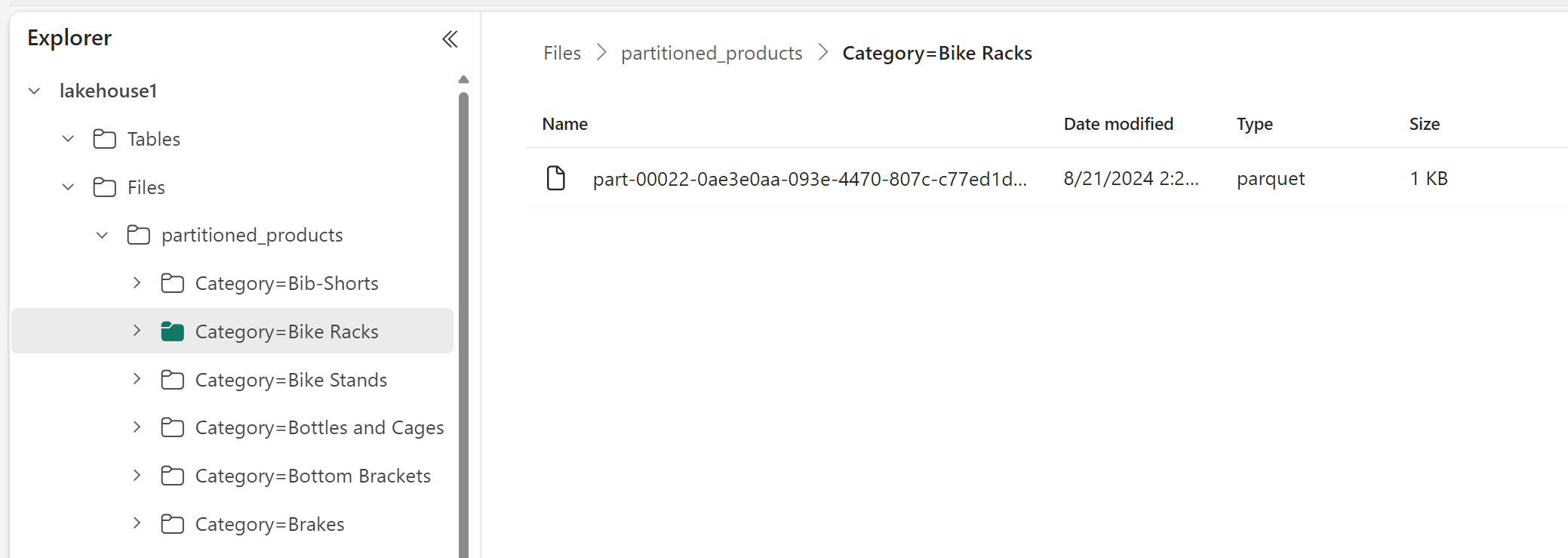
W Eksploratorze usługi Lakehouse można zobaczyć, że dane są tabelą partycjonowaną.
- Istnieje jeden folder dla tabeli o nazwie "partitioned_products".
- Dla każdej kategorii istnieją podfoldery, na przykład "Category=Bike Racks" itp.
Możemy utworzyć podobną tabelę partycjonowaną przy użyciu języka SQL:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);