Opis sposobu uruchamiania narzędzia Slurm za pomocą usługi Azure CycleCloud
Po ukończeniu tej lekcji powinno być możliwe użycie narzędzia Slurm w usłudze Azure CycleCloud.
Włączanie narzędzia Slurm w usłudze CycleCloud
Klaster obliczeń o wysokiej wydajności (HPC) można wdrożyć przy użyciu usługi Azure CycleCloud, wykonując następujące kroki:
Połącz się z wdrożonym wystąpieniem usługi Azure CycleCloud i uwierzytelnij się.
Na stronie Tworzenie nowego klastra przejrzyj dostępne opcje, a następnie w sekcji Harmonogramy wybierz pozycję Slurm.

Na karcie Informacje na stronie Nowy klaster Slurm podaj nazwę klastra Slurm w polu tekstowym Nazwa klastra.
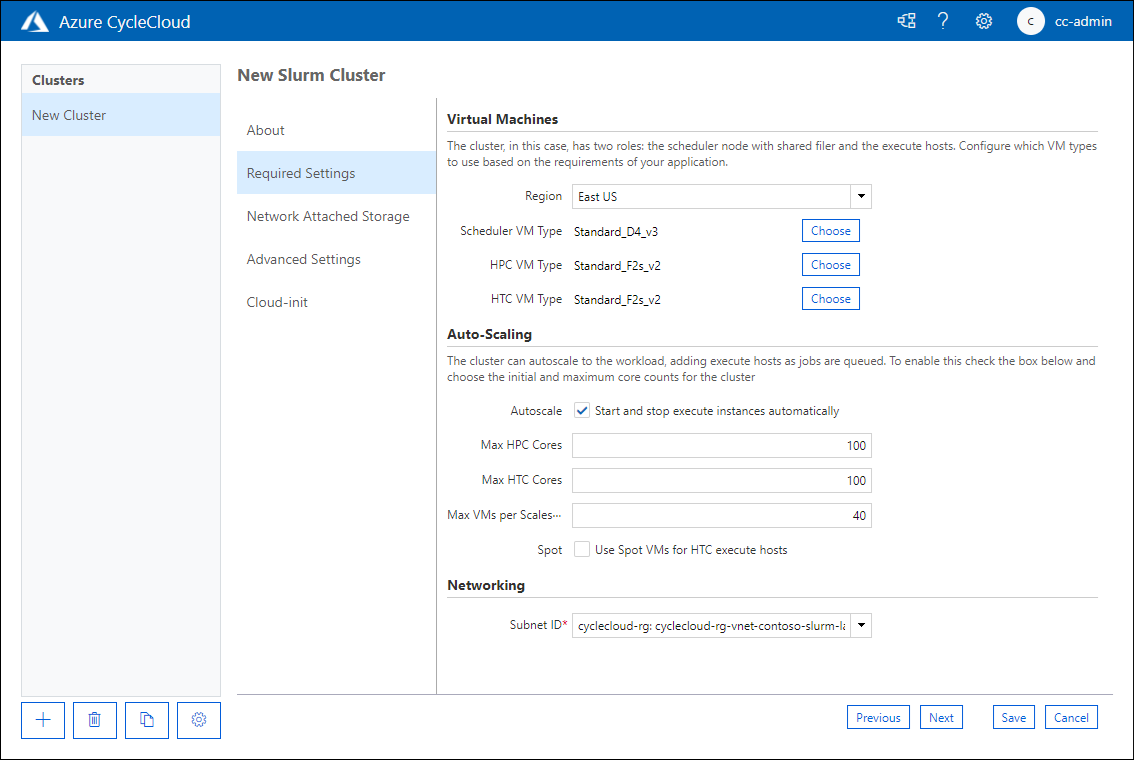
Na karcie Wymagane ustawienia na stronie Nowy klaster slurm skonfiguruj następujące ustawienia w polu tekstowym Nazwa klastra:
- Region: określa, które centrum danych będzie hostować węzły klastra.
- Typ maszyny wirtualnej harmonogramu: umożliwia określenie jednostki SKU maszyny wirtualnej maszyny wirtualnej, która będzie hostować harmonogram zadań.
- Typ maszyny wirtualnej HPC: umożliwia określenie jednostki SKU maszyny wirtualnej maszyny wirtualnej, która będzie hostować obciążenia partycji HPC.
- Typ maszyny wirtualnej HTC: umożliwia określenie jednostki SKU maszyny wirtualnej maszyny wirtualnej, która będzie hostować obciążenia partycji HTC.
- Autoskalowanie: umożliwia włączenie lub wyłączenie uruchamiania i zatrzymywania wystąpień maszyn wirtualnych, które hostują węzły partycji, gdy te węzły są wymagane lub nie są już wymagane.
- Maksymalna liczba rdzeni HPC: maksymalna liczba rdzeni procesora CPU, które można przydzielić do partycji HPC podczas skalowania automatycznego.
- Maksymalna liczba rdzeni HTC: maksymalna liczba rdzeni procesora CPU, które można przydzielić do partycji HTC podczas skalowania automatycznego.
- Maksymalna liczba maszyn wirtualnych na zestaw skalowania: maksymalna liczba maszyn wirtualnych, których można użyć do hostowania obciążeń partycji.
- Użyj wystąpień typu spot: określa, czy chcesz zezwolić na używanie wystąpień typu spot platformy Azure. Mimo że wystąpienia typu spot są znacznie tańsze do uruchomienia, można je usunąć bez ostrzeżenia, co może mieć wpływ na wykonywanie zadania.
- Identyfikator podsieci: podsieć sieci wirtualnej platformy Azure, która będzie hostować maszyny wirtualne węzła klastra.
Na stronie Magazyn dołączony do sieci skonfiguruj, czy na potrzeby instalacji magazynu dołączonego do sieci użyjesz opcji wbudowanego lub zewnętrznego systemu plików NFS. Po wybraniu pozycji Builtin węzeł harmonogramu jest skonfigurowany jako serwer NFS, który działa jako punkt instalacji dla innych węzłów. Jeśli określisz zewnętrzny system plików NFS, możesz podać szczegóły urządzenia magazynu dołączonego do sieci, takiego jak Azure NetApp Files, HPC Cache lub specjalnie skonfigurowana maszyna wirtualna z serwerem NFS.
Na stronie Ustawienia zaawansowane można określić następujące ustawienia:
- Wersja narzędzia Slurm: wybierz wersję slurm, która ma być używana z klastrem.
- Ewidencjonowanie zadań: określ, czy chcesz włączyć ewidencjonowanie zadań i ustawienia, które chcesz przechowywać w danych księgowych.
- Zasady zamykania: możesz wybrać między kończeniem wystąpienia lub cofnięciem przydziału wystąpienia.
- Poświadczenia: poświadczenia do nawiązania połączenia z skojarzą subskrypcją platformy Azure.
- System operacyjny harmonogramu: wybierz, który system operacyjny Linux jest używany do hostowania harmonogramu.
- SYSTEM operacyjny HPC: określ, który system operacyjny Linux jest używany do hostowania harmonogramu.
- Inicjowanie klastra harmonogramu: w tym miejscu określisz niestandardowe instrukcje dotyczące zastosowania do maszyny wirtualnej harmonogramu.
- HTC Cluster Init: określ niestandardowe instrukcje dotyczące stosowania do węzłów HTC.
- Sieć zaawansowana: ta opcja umożliwia włączenie zwrotnego serwera proxy, czy można uzyskać dostęp do węzła głównego z adresów internetowych i czy można uzyskać dostęp do węzłów wykonywania z Internetu.

Strona Cloud-init umożliwia przekazywanie niestandardowych ustawień konfiguracji do węzłów maszyn wirtualnych po ich wdrożeniu.



Ustawienia pamięci
Usługa CycleCloud automatycznie ustawia ilość dostępnej pamięci dla programu Slurm do użycia w celach planowania. Ponieważ ilość dostępnej pamięci może ulec nieznacznej zmianie z powodu różnych opcji jądra systemu Linux, a system operacyjny i maszyna wirtualna mogą używać niewielkiej ilości pamięci, która w przeciwnym razie będzie dostępna dla zadań, usługa CycleCloud automatycznie zmniejsza ilość pamięci w konfiguracji Slurm. Domyślnie usługa CycleCloud przechowuje pięć procent zgłoszonej dostępnej pamięci na maszynie wirtualnej, ale tę wartość można zastąpić w szablonie klastra, ustawiając slurm.dampen_memory wartość procentową pamięci do wstrzymania. Aby na przykład wstrzymać 20 procent pamięci maszyny wirtualnej, użyj:
slurm.dampen_memory=20
Konfigurowanie partycji Slurm
Domyślny szablon dostarczany z usługą Azure CycleCloud ma dwie partycje (HPC i HTC) i można zdefiniować niestandardowe tablice węzłów mapujące bezpośrednio na partycje Slurm. Aby na przykład utworzyć partycję procesora GPU, dodaj następującą sekcję do szablonu klastra:
[[nodearray gpu]]
MachineType = $GPUMachineType
ImageName = $GPUImageName
MaxCoreCount = $MaxGPUExecuteCoreCount
Interruptible = $GPUUseLowPrio
AdditionalClusterInitSpecs = $ExecuteClusterInitSpecs
[[[configuration]]]
slurm.autoscale = true
# Set to true if nodes are used for tightly-coupled multi-node jobs
slurm.hpc = false
[[[cluster-init cyclecloud/slurm:execute:2.0.1]]]
[[[network-interface eth0]]]
AssociatePublicIpAddress = $ExecuteNodesPublic
Edytowanie istniejących klastrów Slurm
W przypadku modyfikowania i stosowania zmian do istniejącego klastra Slurm należy ponownie skompilować slurm.conf plik i zaktualizować istniejące węzły w klastrze. Można to zrobić przy użyciu skryptu, który jest obecny w klastrach Slurm wdrożonych w usłudze Azure cyclecloud przy użyciu specjalnego skryptu o nazwie cyclecloud_slurm.sh. Skrypt znajduje się w /opt/cycle/slurm katalogu w węźle harmonogramu Slurm. Po wprowadzeniu jakichkolwiek zmian w klastrze uruchom następujący skrypt jako katalog główny z parametrem apply_changes . Jeśli na przykład/opt/cycle/slurm/cyclecloud_slurm.sh apply_changes wprowadzisz zmiany wpływające na węzły, które uczestniczą w partycji interfejsu MPI (Message Passing Interface).
Wyłączanie automatycznego skalowania dla węzłów lub partycji
Skalowanie automatyczne dla uruchomionego klastra Slurm można wyłączyć, edytując slurm.conf plik bezpośrednio. Można wykluczyć pojedyncze węzły lub całe partycje z automatycznego skalowania.
Aby wykluczyć węzeł lub wiele węzłów z autoskalowania, dodaj SuspendExcNodes=<listofnodes> go do pliku konfiguracji Slurm. Aby na przykład wykluczyć węzły 1 i 2 z partycji HPC, dodaj następujące polecenie do /sched/slurm.conf a następnie uruchom ponownie usługę slurmctld:
SuspendExcNodes=hpc-pg0-[1-2]
Aby wykluczyć partycje, należy również zmodyfikować /sched/slurm.conf plik. Aby na przykład wykluczyć partycję HPC z autoskalowania, dodaj następujący wiersz do slurm.conf i uruchom ponownie usługę slurmctld :
SuspendExcParts=hpc