Eksplorowanie architektury rozwiązania
Przed rozpoczęciem zapoznajmy się z architekturą, aby zrozumieć wszystkie wymagania. Przeniesienie modelu do środowiska produkcyjnego oznacza konieczność skalowania rozwiązania i współpracy z innymi zespołami. Wraz z analitykami danych, inżynierami danych i zespołem infrastruktury decydujesz się na użycie następującego podejścia:
- Wszystkie dane będą przechowywane w usłudze Azure Blob Storage, która będzie zarządzana przez inżyniera danych.
- Zespół infrastruktury utworzy niezbędne zasoby platformy Azure, takie jak obszar roboczy usługi Azure Machine Learning.
- Analityk danych skupi się na pętli wewnętrznej: opracowywaniu i trenowaniu modelu.
- Inżynier uczenia maszynowego przejmie wytrenowany model i wdroży go w pętli zewnętrznej.
Wraz z większym zespołem zaprojektowano architekturę w celu osiągnięcia operacji uczenia maszynowego (MLOps).
Uwaga
Diagram jest uproszczoną reprezentacją architektury MLOps. Aby wyświetlić bardziej szczegółową architekturę, zapoznaj się z różnymi przypadkami użycia w akceleratorze rozwiązań MLOps (v2).
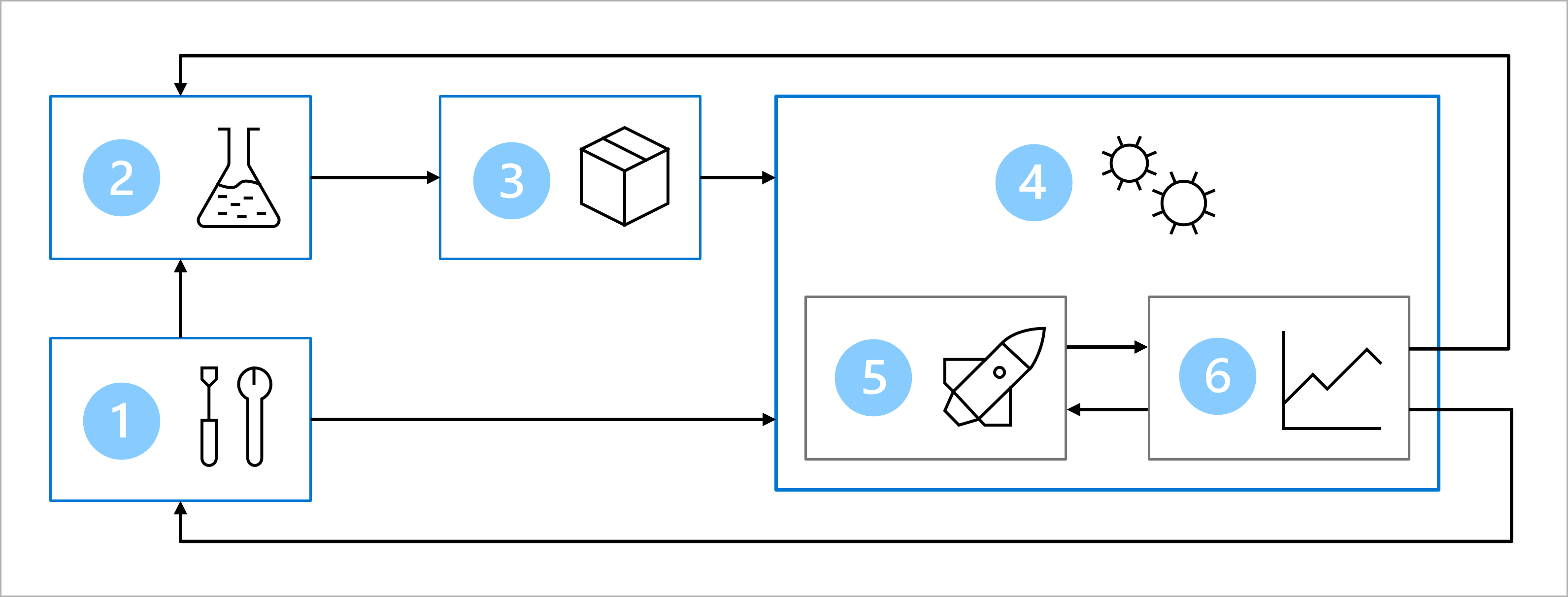
Głównym celem architektury MLOps jest utworzenie niezawodnego i powtarzalnego rozwiązania. Aby osiągnąć ten cel, architektura obejmuje następujące elementy:
- Konfiguracja: utwórz wszystkie niezbędne zasoby platformy Azure dla rozwiązania.
- Programowanie modelu (pętla wewnętrzna): Eksplorowanie i przetwarzanie danych w celu trenowania i oceniania modelu.
- Ciągła integracja: pakowanie i rejestrowanie modelu.
- Wdrażanie modelu (pętla zewnętrzna): wdrażanie modelu.
- Ciągłe wdrażanie: przetestuj model i podwyższ poziom do środowiska produkcyjnego.
- Monitorowanie: Monitorowanie wydajności modelu i punktu końcowego.
W tym momencie w projekcie tworzony jest obszar roboczy usługi Azure Machine Learning, dane są przechowywane w usłudze Azure Blob Storage, a zespół ds. nauki o danych wytrenował model.
Chcesz przejść z wewnętrznej pętli i programowania modelu do pętli zewnętrznej przez wdrożenie modelu w środowisku produkcyjnym. W związku z tym należy przekonwertować dane wyjściowe zespołu nauki o danych na niezawodny i powtarzalny potok w usłudze Azure Machine Learning.
Zapewnienie, że cały kod jest przechowywany jako skrypty i wykonywanie skryptów, ponieważ zadania usługi Azure Machine Learning ułatwią automatyzację trenowania modelu i ponownego trenowania modelu w przyszłości.
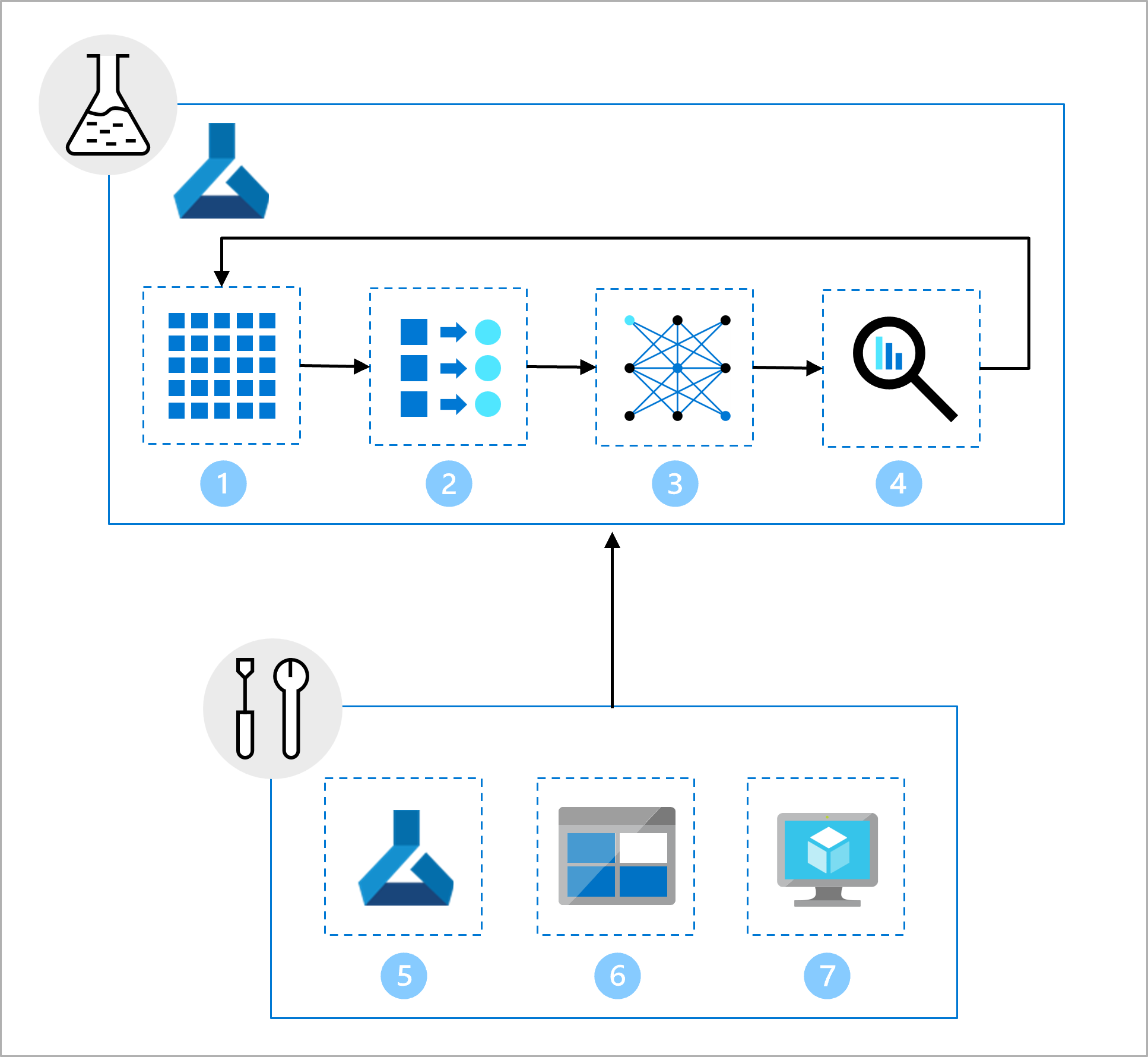
Zespół ds. nauki o danych pracuje nad opracowywaniem modeli. Udostępniają notes Jupyter, który obejmuje następujące zadania:
- Odczytywanie i eksplorowanie danych.
- Wykonywanie inżynierii cech.
- Trenowanie modelu.
- Oceń model.
W ramach konfiguracji zespół ds. infrastruktury utworzył następujące elementy:
- Obszar roboczy programowania (deweloperskiego) usługi Azure Machine Learning, który może być używany przez zespół ds. nauki o danych do eksploracji i eksperymentowania.
- Zasób danych w obszarze roboczym, który odwołuje się do folderu w usłudze Azure Blob Storage, który zawiera dane.
- Zasoby obliczeniowe potrzebne do uruchamiania notesów i skryptów.
Pierwszym zadaniem metodyki MLOps jest przekonwertowanie pracy analityków danych, dzięki czemu można łatwo zautomatyzować tworzenie modelu. Podczas gdy zespół ds. nauki o danych pracował w notesie Jupyter, musisz użyć skryptów i wykonać je przy użyciu zadań usługi Azure Machine Learning. Dane wejściowe zadania to zasób danych utworzony przez zespół infrastruktury, który wskazuje dane znajdujące się w usłudze Azure Blob Storage połączone z obszarem roboczym usługi Azure Machine Learning.