Tworzenie klastra Spark
W obszarze roboczym usługi Azure Databricks można utworzyć co najmniej jeden klaster przy użyciu portalu usługi Azure Databricks.
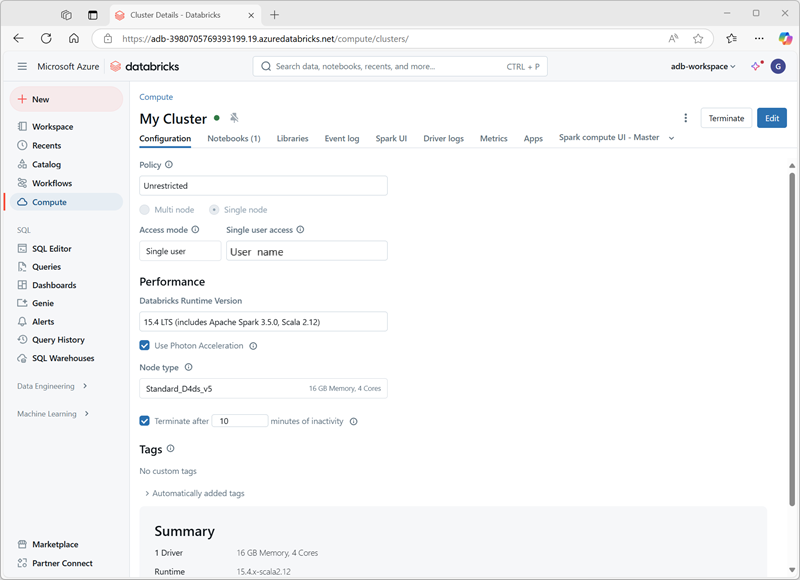
Podczas tworzenia klastra można określić ustawienia konfiguracji, w tym:
- Nazwa klastra.
- Tryb klastra, który może być:
- Standardowa: odpowiednie dla obciążeń pojedynczego użytkownika, które wymagają wielu węzłów roboczych.
- Wysoka współbieżność: nadaje się do obciążeń, w których wielu użytkowników będzie jednocześnie używać klastra.
- Pojedynczy węzeł: nadaje się do małych obciążeń lub testowania, gdzie wymagany jest tylko jeden węzeł roboczy.
- Wersja środowiska Databricks Runtime do użycia w klastrze, która określa wersję platformy Spark i poszczególnych składników, takich jak Python, Scala i inne, które zostaną zainstalowane.
- Typ maszyny wirtualnej używanej dla węzłów procesu roboczego w klastrze.
- Minimalna i maksymalna liczba węzłów roboczych w klastrze.
- Typ maszyny wirtualnej używanej dla węzła sterownika w klastrze.
- Określa, czy klaster obsługuje skalowanie automatyczne w celu dynamicznego zmieniania rozmiaru klastra.
- Jak długo klaster może pozostać bezczynny przed automatycznym zamknięciem.
Jak platforma Azure zarządza zasobami klastra
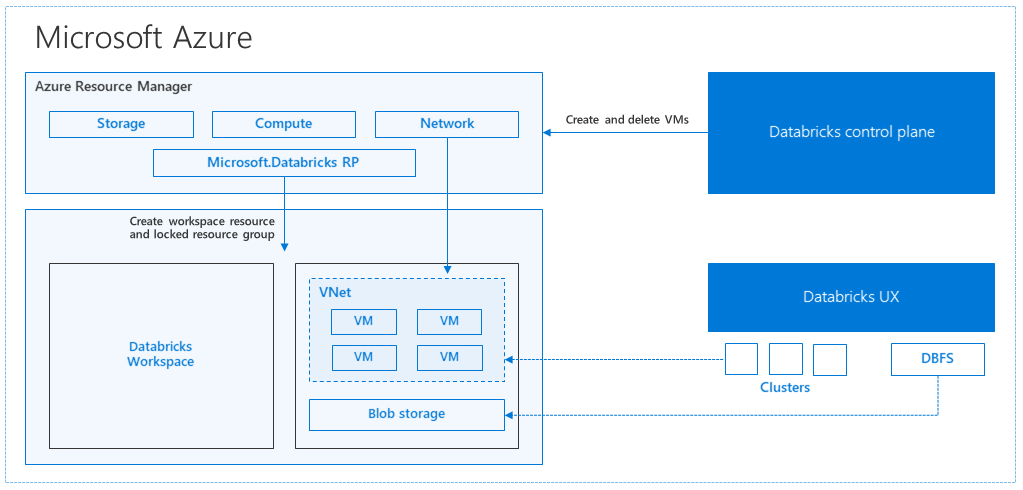
Podczas tworzenia obszaru roboczego usługi Azure Databricks urządzenie usługi Databricks jest wdrażane jako zasób platformy Azure w ramach subskrypcji. Podczas tworzenia klastra w obszarze roboczym należy określić typy i rozmiary maszyn wirtualnych do użycia zarówno dla węzłów sterownika, jak i węzłów roboczych, a także inne opcje konfiguracji, ale usługa Azure Databricks zarządza wszystkimi innymi aspektami klastra.
Urządzenie usługi Databricks jest wdrażane na platformie Azure jako zarządzana grupa zasobów w ramach subskrypcji. Ta grupa zasobów zawiera maszyny wirtualne sterowników i procesów roboczych dla klastrów oraz inne wymagane zasoby, w tym sieć wirtualną, grupę zabezpieczeń i konto magazynu. Wszystkie metadane klastra, takie jak zaplanowane zadania, są przechowywane w usłudze Azure Database z replikacją geograficzną w celu zapewnienia odporności na uszkodzenia.
Wewnętrznie usługa Azure Kubernetes Service (AKS) służy do uruchamiania płaszczyzny sterowania i płaszczyzn danych usługi Azure Databricks za pośrednictwem kontenerów działających na najnowszej generacji sprzętu platformy Azure (Maszyn wirtualnych Dv3), z dyskami SSD NvMe, które mogą zwiększyć opóźnienie 100us na maszynach wirtualnych platformy Azure o wysokiej wydajności z przyspieszoną siecią. Usługa Azure Databricks korzysta z tych funkcji platformy Azure, aby zwiększyć wydajność platformy Spark. Gdy usługi w zarządzanej grupie zasobów będą gotowe, możesz zarządzać klastrem usługi Databricks za pomocą interfejsu użytkownika usługi Azure Databricks oraz za pomocą funkcji, takich jak automatyczne skalowanie i automatyczne kończenie.
Uwaga
Istnieje również możliwość dołączenia klastra do puli węzłów bezczynnych w celu skrócenia czasu uruchamiania klastra. Aby uzyskać więcej informacji, zobacz Pule w dokumentacji usługi Azure Databricks.