Poznaj platformę Apache Spark
Apache Spark to rozproszona struktura przetwarzania danych, która umożliwia analizę danych na dużą skalę, koordynując pracę między wieloma węzłami przetwarzania w klastrze.
Jak działa platforma Spark
Aplikacje platformy Apache Spark działają jako niezależne zestawy procesów w klastrze koordynowane przez obiekt SparkContext w głównym programie (nazywanym programem sterowników). Obiekt SparkContext łączy się z menedżerem klastra, który przydziela zasoby między aplikacjami przy użyciu implementacji usługi Apache Hadoop YARN. Po nawiązaniu połączenia platforma Spark uzyskuje funkcje wykonawcze w węzłach w klastrze w celu uruchomienia kodu aplikacji.
Element SparkContext uruchamia główną funkcję i operacje równoległe w węzłach klastra, a następnie zbiera wyniki operacji. Węzły odczytują i zapisują dane z systemu plików i do systemu plików i buforują przekształcone dane w pamięci jako odporne rozproszone zestawy danych (RDD).
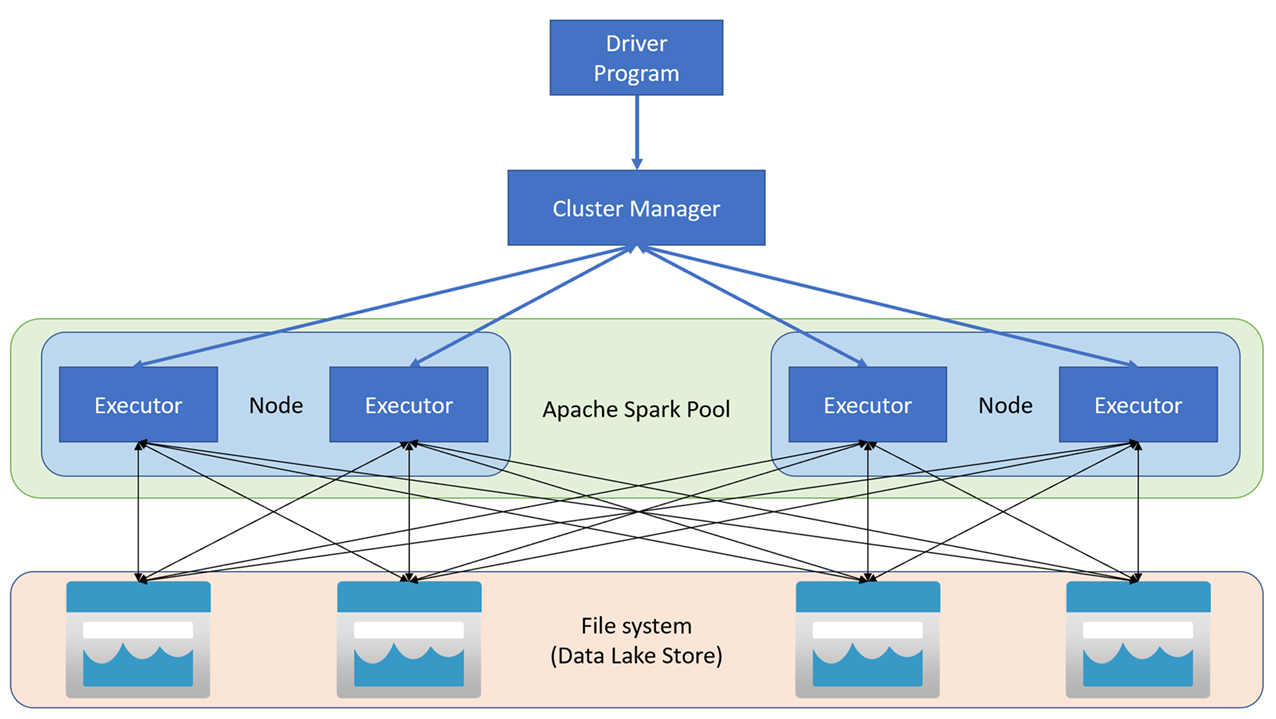
Obiekt SparkContext jest odpowiedzialny za konwertowanie aplikacji na skierowany graf acykliczny (DAG). Wykres składa się z poszczególnych zadań, które są wykonywane w ramach procesu wykonawczego w węzłach. Poszczególne aplikacje uzyskują własne procesy wykonawcze, które istnieją przez cały czas działania aplikacji i pozwalają uruchamiać zadania w wielu wątkach.
Pule platformy Spark w usłudze Azure Synapse Analytics
W usłudze Azure Synapse Analytics klaster jest implementowany jako pula Spark, która zapewnia środowisko uruchomieniowe dla operacji platformy Spark. Jedną lub więcej pul platformy Spark można utworzyć w obszarze roboczym usługi Azure Synapse Analytics przy użyciu witryny Azure Portal lub w usłudze Azure Synapse Studio. Podczas definiowania puli Platformy Spark można określić opcje konfiguracji dla puli, w tym:
- Nazwa puli spark.
- Rozmiar maszyny wirtualnej używanej dla węzłów w puli, w tym możliwość używania węzłów z przyspieszonym sprzętem z obsługą procesora GPU.
- Liczba węzłów w puli i określa, czy rozmiar puli jest stały, czy poszczególne węzły mogą być dynamicznie skalowane w trybie online w celu automatycznego skalowania klastra. W tym przypadku można określić minimalną i maksymalną liczbę aktywnych węzłów.
- Wersja środowiska uruchomieniowego platformy Spark, która ma być używana w puli, która określa wersje poszczególnych składników, takich jak Python, Java i inne, które są instalowane.
Napiwek
Aby uzyskać więcej informacji na temat opcji konfiguracji puli platformy Spark, zobacz Konfiguracje puli platformy Apache Spark w usłudze Azure Synapse Analytics w dokumentacji usługi Azure Synapse Analytics .
Pule platformy Spark w obszarze roboczym usługi Azure Synapse Analytics są bezserwerowe — uruchamiają się na żądanie i zatrzymują się po bezczynności.