Eksplorowanie architektury rozwiązania
Poprawmy architekturę operacji uczenia maszynowego (MLOps), aby zrozumieć cel tego, co próbujemy osiągnąć.
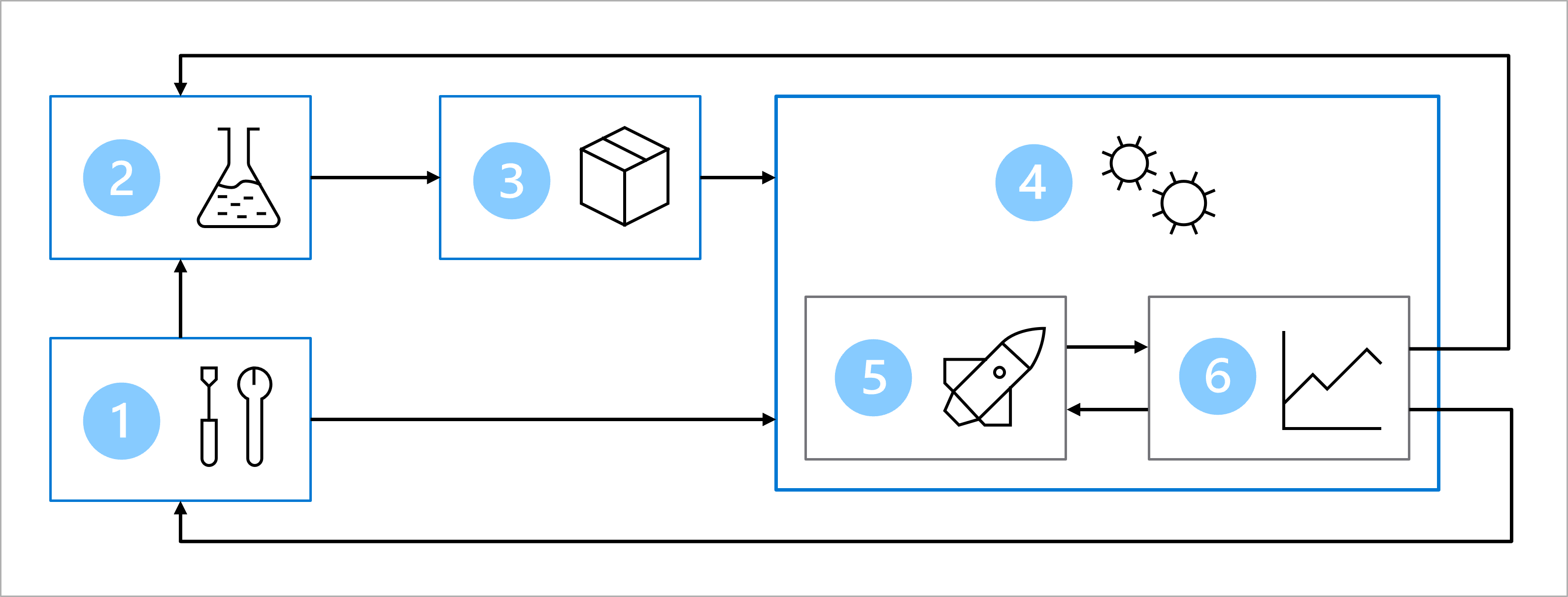
Wyobraź sobie, że wraz z zespołem ds. nauki o danych i programistycznym uzgodniono następującą architekturę w celu trenowania, testowania i wdrażania modelu klasyfikacji cukrzycy:
Uwaga
Diagram jest uproszczoną reprezentacją architektury MLOps. Aby wyświetlić bardziej szczegółową architekturę, zapoznaj się z różnymi przypadkami użycia w akceleratorze rozwiązań MLOps (v2).
Architektura obejmuje następujące elementy:
- Konfiguracja: utwórz wszystkie niezbędne zasoby platformy Azure dla rozwiązania.
- Programowanie modelu (pętla wewnętrzna): Eksplorowanie i przetwarzanie danych w celu trenowania i oceniania modelu.
- Ciągła integracja: pakowanie i rejestrowanie modelu.
- Wdrażanie modelu (pętla zewnętrzna): wdrażanie modelu.
- Ciągłe wdrażanie: przetestuj model i podwyższ poziom do środowiska produkcyjnego.
- Monitorowanie: Monitorowanie wydajności modelu i punktu końcowego.
Zespół ds. nauki o danych jest odpowiedzialny za opracowywanie modeli. Zespół deweloperów oprogramowania jest odpowiedzialny za zintegrowanie wdrożonego modelu z aplikacją internetową używaną przez praktyków do oceny, czy pacjent ma cukrzycę. Odpowiadasz za przyjęcie modelu od opracowywania modeli do wdrożenia modelu.
Oczekujesz, że zespół ds. nauki o danych stale proponuje zmiany skryptów używanych do trenowania modelu. Za każdym razem, gdy nastąpi zmiana skryptu trenowania, należy ponownie wytrenować model i ponownie wdrożyć model w istniejącym punkcie końcowym.
Chcesz zezwolić zespołowi nauki o danych na eksperymentowanie bez dotykania kodu gotowego do produkcji. Chcesz również upewnić się, że każdy nowy lub zaktualizowany kod automatycznie przechodzi przez uzgodnione kontrole jakości. Po zweryfikowaniu kodu w celu wytrenowania modelu użyjesz zaktualizowanego skryptu szkoleniowego, aby wytrenować nowy model i wdrożyć go.
Aby śledzić zmiany i weryfikować kod przed zaktualizowaniem kodu produkcyjnego, należy pracować z gałęziami. Uzgodniliśmy zespół ds. nauki o danych, że za każdym razem, gdy chcą wprowadzić zmianę , utworzy gałąź funkcji, aby utworzyć kopię kodu i wprowadzić zmiany w kopii.
Każdy analityk danych może utworzyć gałąź funkcji i pracować w niej. Po zaktualizowaniu kodu i uzyskaniu nowego kodu produkcyjnego należy utworzyć żądanie ściągnięcia. W żądaniu ściągnięcia będzie ona widoczna dla innych osób, jakie są proponowane zmiany, co daje innym możliwość przejrzenia i omówienia zmian.
Za każdym razem, gdy żądanie ściągnięcia zostanie utworzone, chcesz automatycznie sprawdzić, czy kod działa, i czy jakość kodu jest do standardów organizacji. Po zakończeniu testów jakości przez głównego analityka danych musi przejrzeć zmiany i zatwierdzić aktualizacje przed scaleniem żądania ściągnięcia, a kod w gałęzi głównej można odpowiednio zaktualizować.
Ważne
Nikt nigdy nie powinien mieć prawa wypychać zmian do gałęzi głównej. Aby zabezpieczyć kod, zwłaszcza kod produkcyjny, należy wymusić, że gałąź główna może być aktualizowana tylko za pośrednictwem żądań ściągnięcia, które muszą zostać zatwierdzone.