Ocena różnych typów klastrowania
Trenowanie modelu klastrowania
Istnieje wiele algorytmów, których można użyć do klastrowania. Jednym z najczęściej używanych algorytmów jest klaster K-Średnich , który w najprostszej formie składa się z następujących kroków:
- Wartości funkcji są wektoryzowane w celu zdefiniowania współrzędnych nwymiarowych (gdzie n jest liczbą cech). W przykładzie kwiatu mamy dwie cechy: liczbę płatków i liczbę liści. Dlatego wektor funkcji ma dwie współrzędne, których możemy użyć do koncepcyjnego wykreślenia punktów danych w dwuwymiarowej przestrzeni.
- Decydujesz, ile klastrów chcesz użyć do grupowania kwiatów — wywołaj tę wartość k. Aby na przykład utworzyć trzy klastry, należy użyć wartości k równej 3. Następnie punkty k są kreśline na losowych współrzędnych. Punkty te stają się centralnymi punktami dla każdego klastra, więc są nazywane centroidami.
- Każdy punkt danych (w tym przypadku kwiat) jest przypisany do najbliższego centroidu.
- Każdy centroid jest przenoszony do środka przypisanych do niego punktów danych na podstawie średniej odległości między punktami.
- Po przeniesieniu centroid punkty danych mogą być teraz bliżej innego centroidu, więc punkty danych są ponownie przypisywane do klastrów na podstawie nowego najbliższego centroidu.
- Kroki przenoszenia centroidu i lokalizacji klastra są powtarzane do momentu, aż klastry staną się stabilne lub zostanie osiągnięta wstępnie określona maksymalna liczba iteracji.
Poniższa animacja przedstawia ten proces:

Klastrowanie hierarchiczne
Klastrowanie hierarchiczne to inny typ algorytmu klastrowania, w którym same klastry należą do większych grup, które należą do jeszcze większych grup itd. Wynikiem jest to, że punkty danych mogą być klastrami o różnym stopniu dokładności: z dużą liczbą bardzo małych i precyzyjnych grup lub niewielką liczbą większych grup.
Jeśli na przykład stosujemy klastering do znaczenia słów, możemy uzyskać grupę zawierającą przymiotniki specyficzne dla emocji ("zły", "szczęśliwy" itd.). Ta grupa należy do grupy zawierającej wszystkie przymiotniki związane z człowiekiem ("szczęśliwy", "przystojny", "młody"), która należy do jeszcze wyższej grupy zawierającej wszystkie przymiotniki ("happy", "zielony", "przystojny", "twardy", itd.).
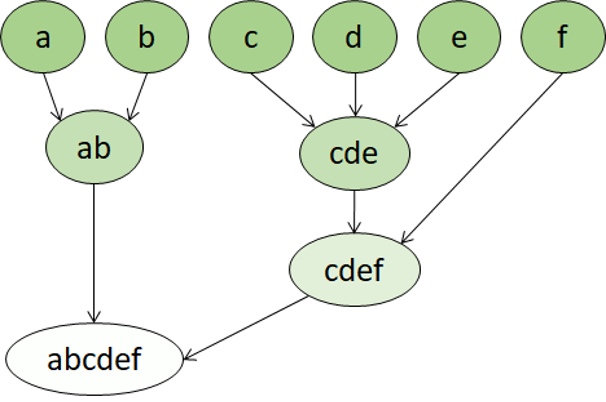
Klastrowanie hierarchiczne jest przydatne nie tylko w przypadku podziału danych na grupy, ale także zrozumienia relacji między tymi grupami. Główną zaletą klastrowania hierarchicznego jest to, że nie wymaga wcześniejszego zdefiniowania liczby klastrów. I czasami może zapewnić bardziej czytelne wyniki niż podejścia niehierarchiczne. Główne wady są takie, że te podejścia mogą trwać dłużej niż w przypadku prostszych metod obliczeniowych, a czasami nie są odpowiednie dla dużych zestawów danych.