Wprowadzenie
Klastrowanie to proces grupowania obiektów z podobnymi obiektami. Na przykład na poniższej ilustracji mamy kolekcję współrzędnych 2D, które zostały zgrupowane w trzy kategorie — w lewym górnym rogu (żółty), dolny (czerwony) i w prawym górnym rogu (niebieski).
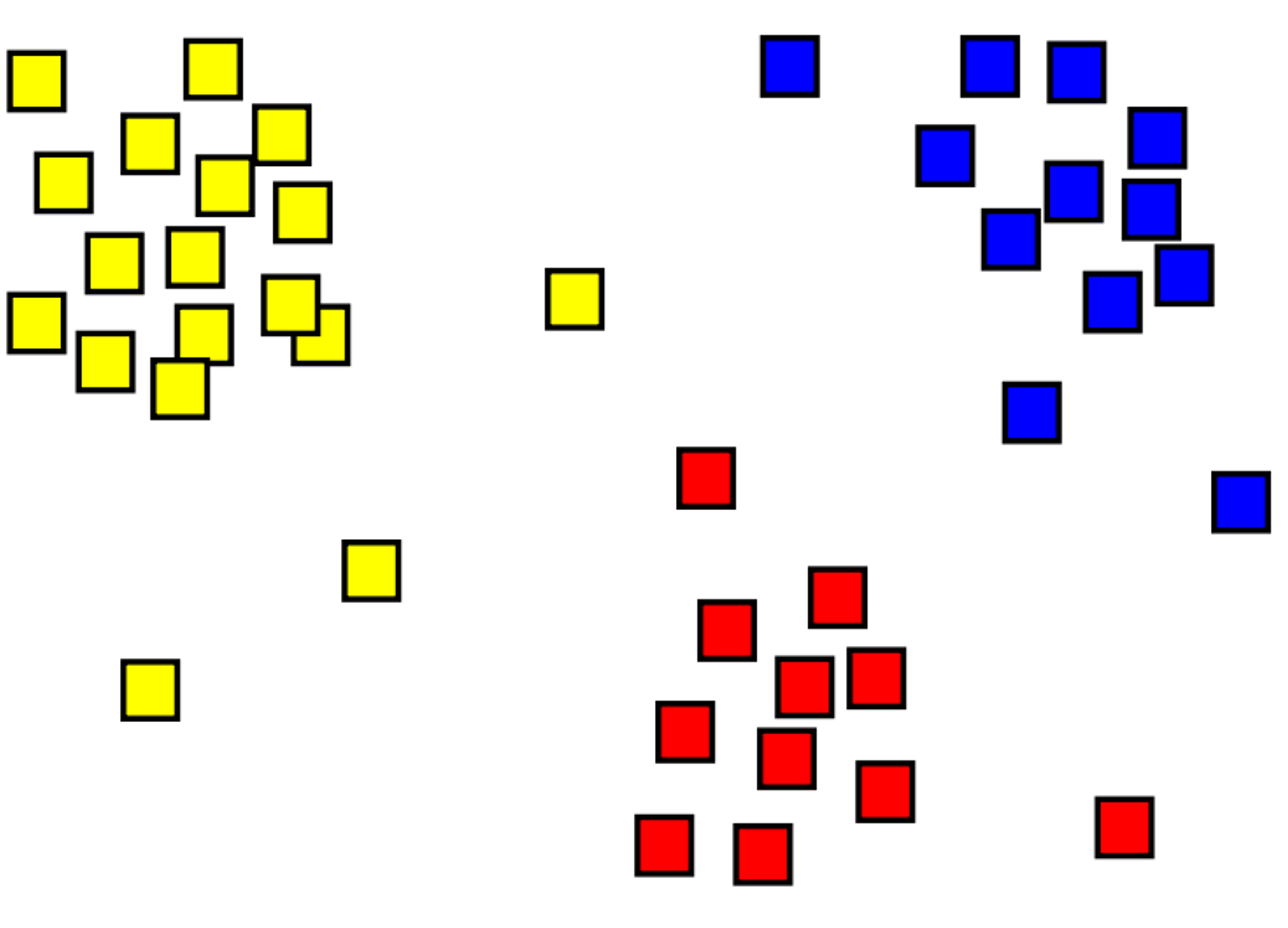
Główną różnicą między modelami klastrowania i klasyfikacji jest to, że klastrowanie jest metodą nienadzorowaną , w której trenowanie odbywa się bez etykiet. Modele klastrowania identyfikują przykłady, które mają podobną kolekcję funkcji. Na powyższym obrazie przykłady, które znajdują się w podobnej lokalizacji, są zgrupowane razem.
Klastrowanie jest powszechne i przydatne do eksplorowania nowych danych, w których wzorce między punktami danych, takie jak kategorie wysokiego poziomu, nie są jeszcze znane. Jest on używany w wielu dziedzinach, które muszą automatycznie oznaczać złożone dane, w tym analizę sieci społecznościowych, łączność mózgową, filtrowanie spamu itd.