Testowanie i trenowanie zestawów danych
Dane używane do trenowania modelu są często nazywane zestawem danych treningowych. Widzieliśmy to już w akcji. Frustrująco, kiedy używamy modelu w świecie rzeczywistym, po trenowaniu nie wiemy, jak dobrze będzie działać nasz model. Ta niepewność wynika z faktu, że nasz zestaw danych szkoleniowych różni się od danych w świecie rzeczywistym.
Co to jest nadmierne dopasowanie?
Model jest nadmiernie dopasowany , jeśli działa lepiej na danych treningowych niż w przypadku innych danych. Nazwa odnosi się do faktu, że model został dopasowany tak dobrze, że jest zapamiętany szczegóły zestawu treningowego, zamiast znajdować szerokie reguły, które będą stosowane do innych danych. Nadmierne dopasowanie jest powszechne, ale nie pożądane. Na koniec dnia zależy nam tylko na tym, jak dobrze działa nasz model na rzeczywistych danych.
Jak możemy uniknąć nadmiernego dopasowania?
Możemy uniknąć nadmiernego dopasowania na kilka sposobów. Najprostszym sposobem jest posiadanie prostszego modelu lub użycie zestawu danych, który jest lepszą reprezentacją tego, co jest widoczne w świecie rzeczywistym. Aby zrozumieć te metody, rozważ scenariusz, w którym dane rzeczywiste wyglądają następująco:
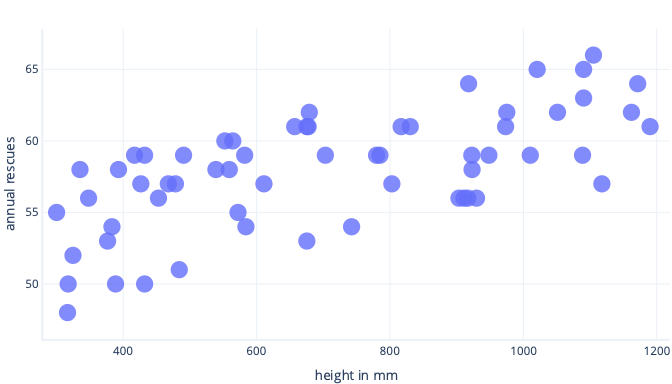
Załóżmy, że zbieramy informacje o zaledwie pięciu psach i używamy ich jako zestawu danych treningowych, aby dopasować złożoną linię. Jeśli to zrobimy, możemy to bardzo dobrze dopasować:
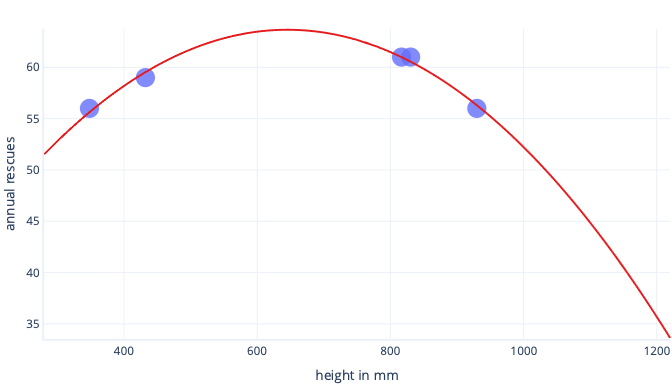
Gdy jest on używany w świecie rzeczywistym, okaże się jednak, że sprawia, że przewidywania, które okazują się błędne:
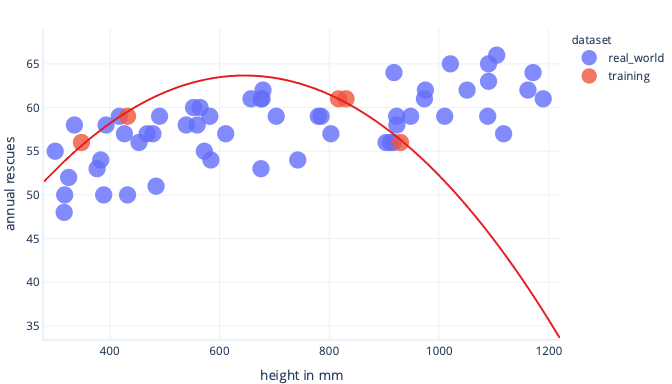
Jeśli mamy bardziej reprezentatywny zestaw danych i prostszy model, linia, do których się dopasowujemy, okazuje się lepiej (choć nie idealna) przewidywania:
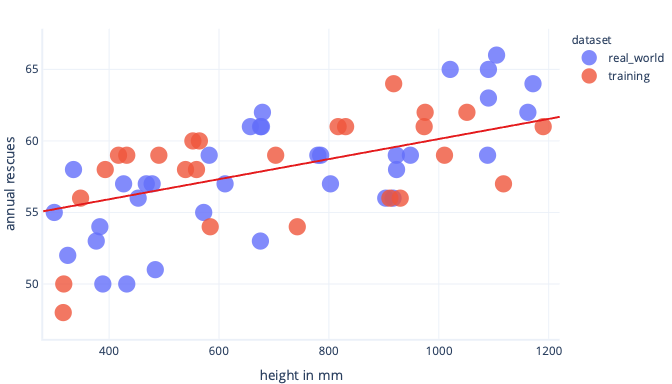
Bezpłatny sposób, w jaki możemy uniknąć nadmiernego dopasowania, to zatrzymanie trenowania po tym, jak model nauczył się ogólnych zasad, ale zanim model będzie nadmiernie dopasowany. Wymaga to jednak wykrycia, kiedy zaczynamy nadmiernie dopasować nasz model. Możemy to zrobić przy użyciu testowego zestawu danych.
Co to jest testowy zestaw danych?
Zestaw danych testowych, nazywany również zestawem danych weryfikacji, jest zestawem danych podobnych do zestawu danych treningowych. W rzeczywistości zestawy danych testowych są zwykle tworzone przez utworzenie dużego zestawu danych i podzielenie go. Jedna część jest nazywana zestawem danych trenowania, a druga jest nazywana zestawem danych testowych.
Zadaniem zestawu danych trenowania jest trenowanie modelu; Widzieliśmy już szkolenie. Zadaniem zestawu danych testowych jest sprawdzenie, jak dobrze działa model; nie przyczynia się bezpośrednio do trenowania.
OK, ale co to jest punkt?
Punkt testowego zestawu danych jest dwa razy.
Po pierwsze, jeśli wydajność testu przestanie się poprawiać podczas trenowania, możemy zatrzymać; nie ma sensu kontynuować. Jeśli będziemy kontynuować, możemy zachęcić model do zapoznania się ze szczegółowymi informacjami na temat zestawu danych treningowych, które nie znajdują się w zestawie danych testowych, co jest nadmiernym dopasowaniem.
Po drugie, możemy użyć testowego zestawu danych po trenowaniu. Daje to nam wskazanie, jak dobrze będzie działać ostateczny model, gdy zobaczy "rzeczywiste" dane, których wcześniej nie widział.
Co to oznacza dla funkcji kosztów?
Gdy używamy zarówno zestawów danych szkoleniowych, jak i testowych, kończymy obliczanie dwóch funkcji kosztów.
Pierwsza funkcja kosztu korzysta z zestawu danych trenowania, tak jak widzieliśmy wcześniej. Ta funkcja kosztu jest stosowana do optymalizatora i używana do trenowania modelu.
Druga funkcja kosztu jest obliczana przy użyciu testowego zestawu danych. Służymy do sprawdzania, jak dobrze model może działać w świecie rzeczywistym. Wynik funkcji kosztu nie jest używany do trenowania modelu. Aby to obliczyć, wstrzymujemy trenowanie, przyjrzymy się, jak dobrze działa model w zestawie danych testowych, a następnie wznowimy trenowanie.