Indeksowanie dowolnych danych przy użyciu interfejsu API wypychania usługi Azure AI Search
Interfejs API REST to najbardziej elastyczny sposób wypychania danych do indeksu usługi Azure AI Search. Możesz użyć dowolnego języka programowania lub interaktywnie z dowolną aplikacją, która może publikować żądania JSON w punkcie końcowym.
W tym miejscu dowiesz się, jak efektywnie korzystać z interfejsu API REST i eksplorować dostępne operacje. Następnie przyjrzysz się kodowi platformy .NET Core i dowiesz się, jak zoptymalizować dodawanie dużych ilości danych za pośrednictwem interfejsu API.
Obsługiwane operacje interfejsu API REST
Istnieją dwa obsługiwane interfejsy API REST udostępniane przez wyszukiwanie sztucznej inteligencji. Interfejsy API wyszukiwania i zarządzania. Ten moduł koncentruje się na interfejsach API REST wyszukiwania, które zapewniają operacje na pięciu funkcjach wyszukiwania:
| Funkcja | Operacje |
|---|---|
| Indeks | Tworzenie, usuwanie, aktualizowanie i konfigurowanie. |
| Dokument | Pobierz, dodaj, zaktualizuj i usuń. |
| Indeksator | Konfigurowanie źródeł danych i planowanie ograniczonych źródeł danych. |
| Skillset | Pobieranie, tworzenie, usuwanie, wyświetlanie listy i aktualizowanie. |
| Mapa synonimów | Pobieranie, tworzenie, usuwanie, wyświetlanie listy i aktualizowanie. |
Jak wywołać interfejs API REST wyszukiwania
Jeśli chcesz wywołać dowolny z interfejsów API wyszukiwania, musisz:
- Użyj punktu końcowego HTTPS (za pośrednictwem domyślnego portu 443) dostarczonego przez usługę wyszukiwania, musisz uwzględnić wersję interfejsu API w identyfikatorze URI.
- Nagłówek żądania musi zawierać atrybut api-key .
Aby znaleźć punkt końcowy, wersję interfejsu API i klucz api-key, przejdź do witryny Azure Portal.

W portalu przejdź do usługi wyszukiwania, a następnie wybierz pozycję Eksplorator wyszukiwania. Punkt końcowy interfejsu API REST znajduje się w polu Adres URL żądania. Pierwszą częścią adresu URL jest punkt końcowy (na przykład https://azsearchtest.search.windows.net), a ciąg zapytania zawiera api-version wartość (na przykład api-version=2023-07-01-Preview).

Aby znaleźć element api-key po lewej stronie, wybierz pozycję Klucze. Podstawowy lub pomocniczy klucz administratora może być używany, jeśli używasz interfejsu API REST do wykonywania innych czynności niż tylko wykonywanie zapytań względem indeksu. Jeśli wszystko, czego potrzebujesz, to przeszukać indeks, możesz utworzyć i użyć kluczy zapytań.
Aby dodać, zaktualizować lub usunąć dane w indeksie, musisz użyć klucza administratora.
Dodawanie danych do indeksu
Użyj żądania HTTP POST przy użyciu funkcji indeksów w tym formacie:
POST https://[service name].search.windows.net/indexes/[index name]/docs/index?api-version=[api-version]
Treść żądania musi poinformować punkt końcowy REST o akcji do wykonania w dokumencie, który dokument ma również zastosować akcję oraz jakie dane mają być używane.
Kod JSON musi mieć następujący format:
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
| Akcja | opis |
|---|---|
| przekaż | Podobnie jak w przypadku operacji upsert w języku SQL, dokument zostanie utworzony lub zastąpiony. |
| Scalania | Scalaj aktualizuje istniejący dokument z określonymi polami. Scalanie zakończy się niepowodzeniem, jeśli nie można odnaleźć dokumentu. |
| mergeOrUpload | Scalanie aktualizuje istniejący dokument z określonymi polami i przekazuje go, jeśli dokument nie istnieje. |
| usuwanie | Usuwa cały dokument. Wystarczy określić key_field_name. |
Jeśli żądanie zakończy się pomyślnie, interfejs API zwróci kod stanu 200.
Uwaga
Aby uzyskać pełną listę wszystkich kodów odpowiedzi i komunikatów o błędach, zobacz Dodawanie, aktualizowanie lub usuwanie dokumentów (interfejs API REST usługi Azure AI Search)
W tym przykładzie kod JSON przekazuje rekord klienta w poprzedniej lekcji:
{
"value": [
{
"@search.action": "upload",
"id": "5fed1b38309495de1bc4f653",
"firstName": "Sims",
"lastName": "Arnold",
"isAlive": false,
"age": 35,
"address": {
"streetAddress": "Sumner Place",
"city": "Canoochee",
"state": "Palau",
"postalCode": "1558"
},
"phoneNumbers": [
{
"phoneNumber": {
"type": "home",
"number": "+1 (830) 465-2965"
}
},
{
"phoneNumber": {
"type": "home",
"number": "+1 (889) 439-3632"
}
}
]
}
]
}
Możesz dodać dowolną liczbę dokumentów w tablicy wartości. Jednak w celu uzyskania optymalnej wydajności rozważ dzielenie dokumentów na partie w żądaniach maksymalnie 1000 dokumentów lub 16 MB całkowitego rozmiaru.
Indeksowanie dowolnych danych przy użyciu platformy .NET Core
Aby uzyskać najlepszą wydajność, użyj najnowszej Azure.Search.Document biblioteki klienta, obecnie w wersji 11. Bibliotekę klienta można zainstalować za pomocą narzędzia NuGet:
dotnet add package Azure.Search.Documents --version 11.4.0
Sposób działania indeksu opiera się na sześciu kluczowych czynnikach:
- Warstwa usługi wyszukiwania oraz liczba włączonych replik i partycji.
- Złożoność schematu indeksu. Zmniejsz liczbę właściwości (z możliwością wyszukiwania, tworzenia aspektów, sortowania) każdego pola.
- Liczba dokumentów w każdej partii, najlepszy rozmiar będzie zależeć od schematu indeksu i rozmiaru dokumentów.
- Jak wielowątkowane jest twoje podejście.
- Obsługa błędów i ograniczania przepustowości. Użyj strategii ponawiania prób wycofywania wykładniczego.
- Gdzie znajdują się dane, spróbuj zaindeksować dane tak blisko indeksu wyszukiwania. Na przykład uruchom przekazywanie z poziomu środowiska platformy Azure.
Wypracowanie optymalnego rozmiaru partii
Ponieważ najlepszym rozmiarem partii jest kluczowy czynnik zwiększający wydajność, przyjrzyjmy się podejściu w kodzie.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Podejście polega na zwiększeniu rozmiaru partii i monitorze czasu odebrania prawidłowej odpowiedzi. Pętle kodu z zakresu od 100 do 1000 w 100 krokach dokumentu. Dla każdego rozmiaru partii zwraca on rozmiar dokumentu, czas uzyskania odpowiedzi i średni czas na MB. Uruchomienie tego kodu daje wyniki w następujący sposób:
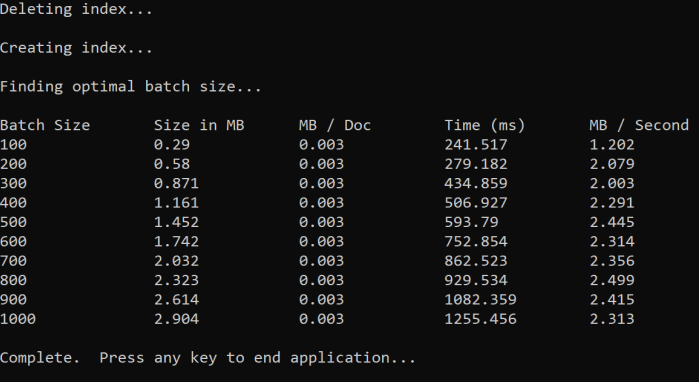
W powyższym przykładzie najlepszy rozmiar partii dla przepływności wynosi 2,499 MB na sekundę, 800 dokumentów na partię.
Implementowanie strategii ponawiania prób wykładniczego wycofywania
Jeśli indeks zacznie ograniczać żądania z powodu przeciążeń, odpowiada na 503 (żądanie odrzucone z powodu dużego obciążenia) lub 207 (niektóre dokumenty nie powiodły się w partii). Musisz poradzić sobie z tymi odpowiedziami i dobrą strategią jest wycofywanie. Wycofywanie oznacza wstrzymanie przez jakiś czas przed ponowną próbą żądania. Jeśli zwiększysz ten czas dla każdego błędu, będziesz wykładniczo cofać.
Przyjrzyj się temu kodowi:
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Kod śledzi nieudane dokumenty w partii. Jeśli wystąpi błąd, czeka na opóźnienie, a następnie podwaja opóźnienie dla następnego błędu.
Na koniec istnieje maksymalna liczba ponownych prób, a jeśli ta maksymalna liczba zostanie osiągnięta, program istnieje.
Używanie wątków w celu zwiększenia wydajności
Aplikację do przekazywania dokumentów można ukończyć, przeczesując powyższą strategię wycofywania za pomocą podejścia wątkowego. Oto przykładowy kod:
public static async Task IndexDataAsync(SearchClient searchClient, List<Hotel> hotels, int batchSize, int numThreads)
{
int numDocs = hotels.Count;
Console.WriteLine("Uploading {0} documents...\n", numDocs.ToString());
DateTime startTime = DateTime.Now;
Console.WriteLine("Started at: {0} \n", startTime);
Console.WriteLine("Creating {0} threads...\n", numThreads);
// Creating a list to hold active tasks
List<Task<IndexDocumentsResult>> uploadTasks = new List<Task<IndexDocumentsResult>>();
for (int i = 0; i < numDocs; i += batchSize)
{
List<Hotel> hotelBatch = hotels.GetRange(i, batchSize);
var task = ExponentialBackoffAsync(searchClient, hotelBatch, i);
uploadTasks.Add(task);
Console.WriteLine("Sending a batch of {0} docs starting with doc {1}...\n", batchSize, i);
// Checking if we've hit the specified number of threads
if (uploadTasks.Count >= numThreads)
{
Task<IndexDocumentsResult> firstTaskFinished = await Task.WhenAny(uploadTasks);
Console.WriteLine("Finished a thread, kicking off another...");
uploadTasks.Remove(firstTaskFinished);
}
}
// waiting for the remaining results to finish
await Task.WhenAll(uploadTasks);
DateTime endTime = DateTime.Now;
TimeSpan runningTime = endTime - startTime;
Console.WriteLine("\nEnded at: {0} \n", endTime);
Console.WriteLine("Upload time total: {0}", runningTime);
double timePerBatch = Math.Round(runningTime.TotalMilliseconds / (numDocs / batchSize), 4);
Console.WriteLine("Upload time per batch: {0} ms", timePerBatch);
double timePerDoc = Math.Round(runningTime.TotalMilliseconds / numDocs, 4);
Console.WriteLine("Upload time per document: {0} ms \n", timePerDoc);
}
Ten kod używa asynchronicznych wywołań do funkcji ExponentialBackoffAsync , która implementuje strategię wycofywania. Wywołasz funkcję przy użyciu wątków, na przykład liczbę rdzeni procesora. Gdy zostanie użyta maksymalna liczba wątków, kod czeka na zakończenie dowolnego wątku. Następnie tworzy nowy wątek do momentu przekazania wszystkich dokumentów.