Przeprowadzanie testów porównawczych w bazie danych HBase
Yahoo! Cloud Serving Benchmark (YCSB) to specyfikacja typu open source i pakiet programów do oceny względnej wydajności systemów zarządzania bazami danych NoSQL. W tym ćwiczeniu uruchomisz test porównawczy na wydajność dwóch klastrów HBase, z których jedna korzysta z funkcji przyspieszonych zapisów. Twoim zadaniem jest zrozumienie różnic wydajności między dwiema opcjami. Ćwiczenie wymagań wstępnych
Jeśli chcesz wykonać kroki w ćwiczeniu, upewnij się, że masz następujące elementy:
- Subskrypcja platformy Azure z autoryzacją do tworzenia klastra HBase usługi HDInsight.
- Dostęp do klienta SSH, takiego jak Putty(Windows) /Terminal (książka dla komputerów Mac)
Aprowizuj klaster HBase usługi HDInsight za pomocą portalu zarządzania Azure
Aby aprowizować bazę danych HBase usługi HDInsight przy użyciu nowego środowiska w portalu zarządzania Platformy Azure, wykonaj poniższe kroki.
Przejdź do portalu Azure Portal. Zaloguj się przy użyciu poświadczeń konta platformy Azure.
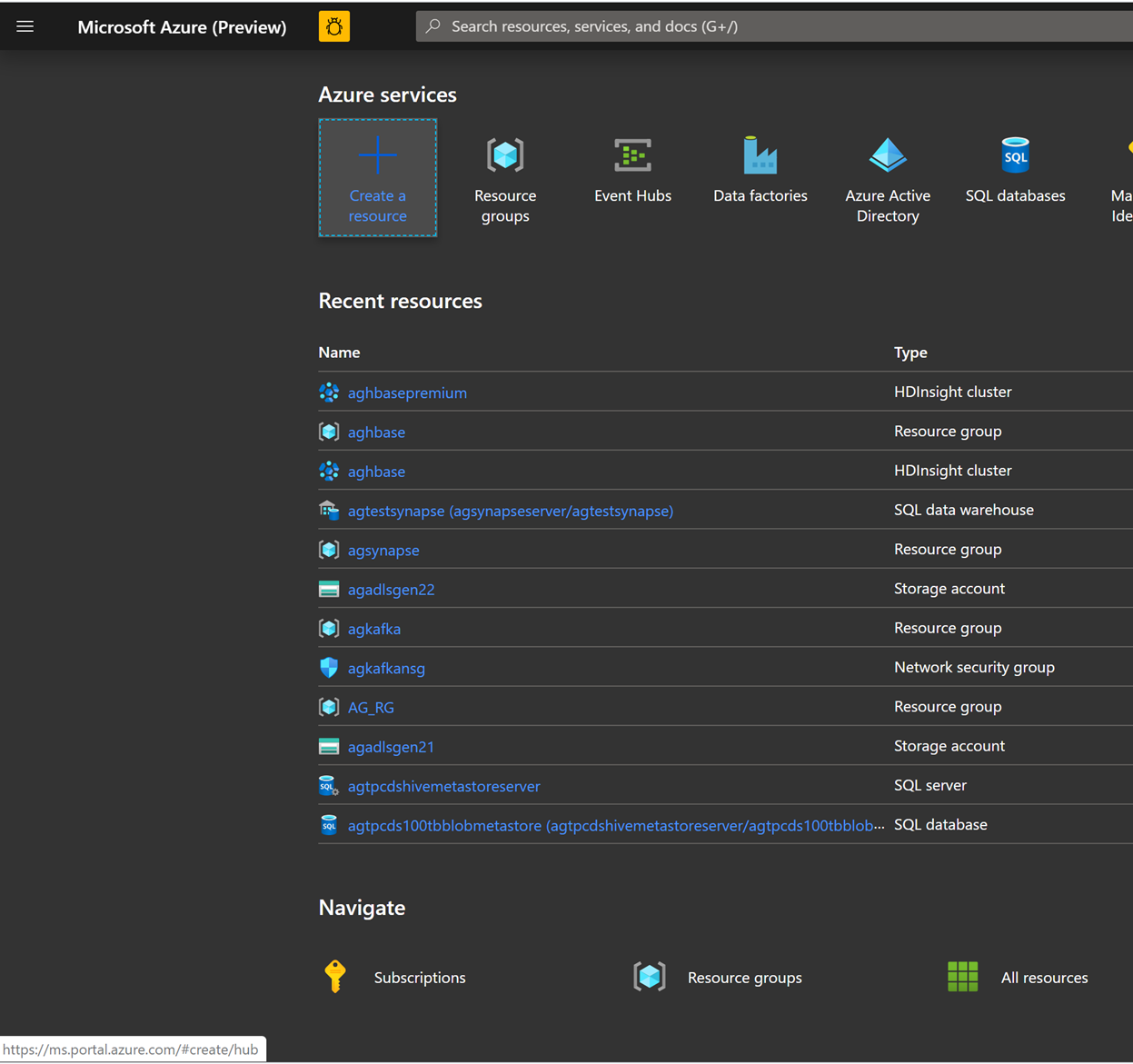
Zaczniemy od utworzenia konta magazynu blokowych obiektów blob w warstwie Premium. Na nowej stronie kliknij pozycję Konto magazynu.
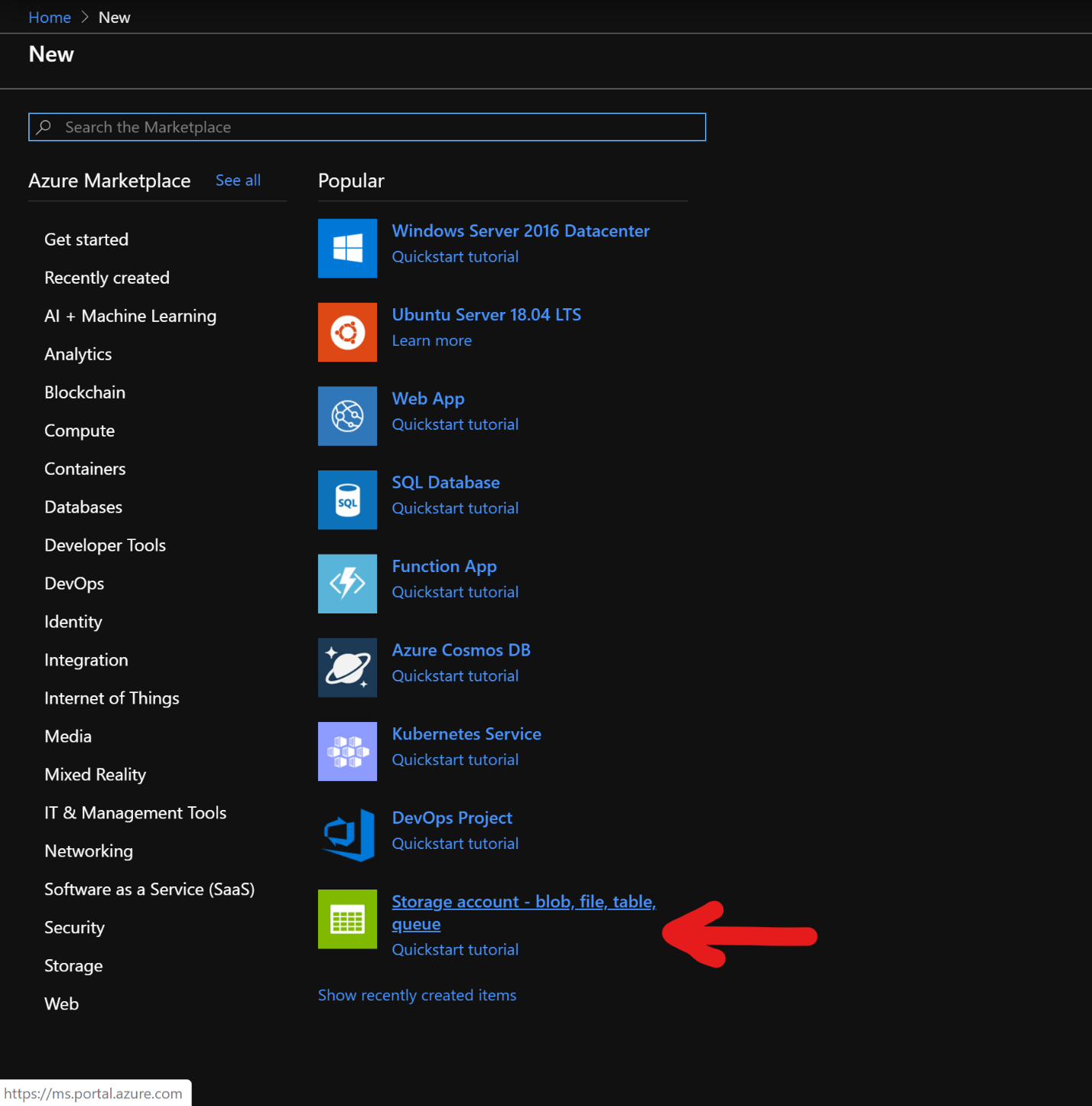
Na stronie Tworzenie konta magazynu wypełnij poniższe pola
Subskrypcja: powinna być wypełniana automatycznie ze szczegółami subskrypcji
Grupa zasobów: wprowadź grupę zasobów do przechowywania wdrożenia bazy danych HBase w usłudze HDInsight
Nazwa konta magazynu: wprowadź nazwę konta magazynu do użycia w klastrze Premium.
Region: wprowadź nazwę regionu wdrożenia (upewnij się, że klaster i konto magazynu znajdują się w tym samym regionie)
Wydajność: Premium
Rodzaj konta: BlockBlobStorage
Replikacja: magazyn lokalnie nadmiarowy (LRS)
Nazwa użytkownika dziennika klastra: wprowadź nazwę użytkownika dla administratora klastra (default:admin)
Pozostaw domyślne wszystkie inne karty i kliknij pozycję Przejrzyj i utwórz , aby utworzyć konto magazynu.
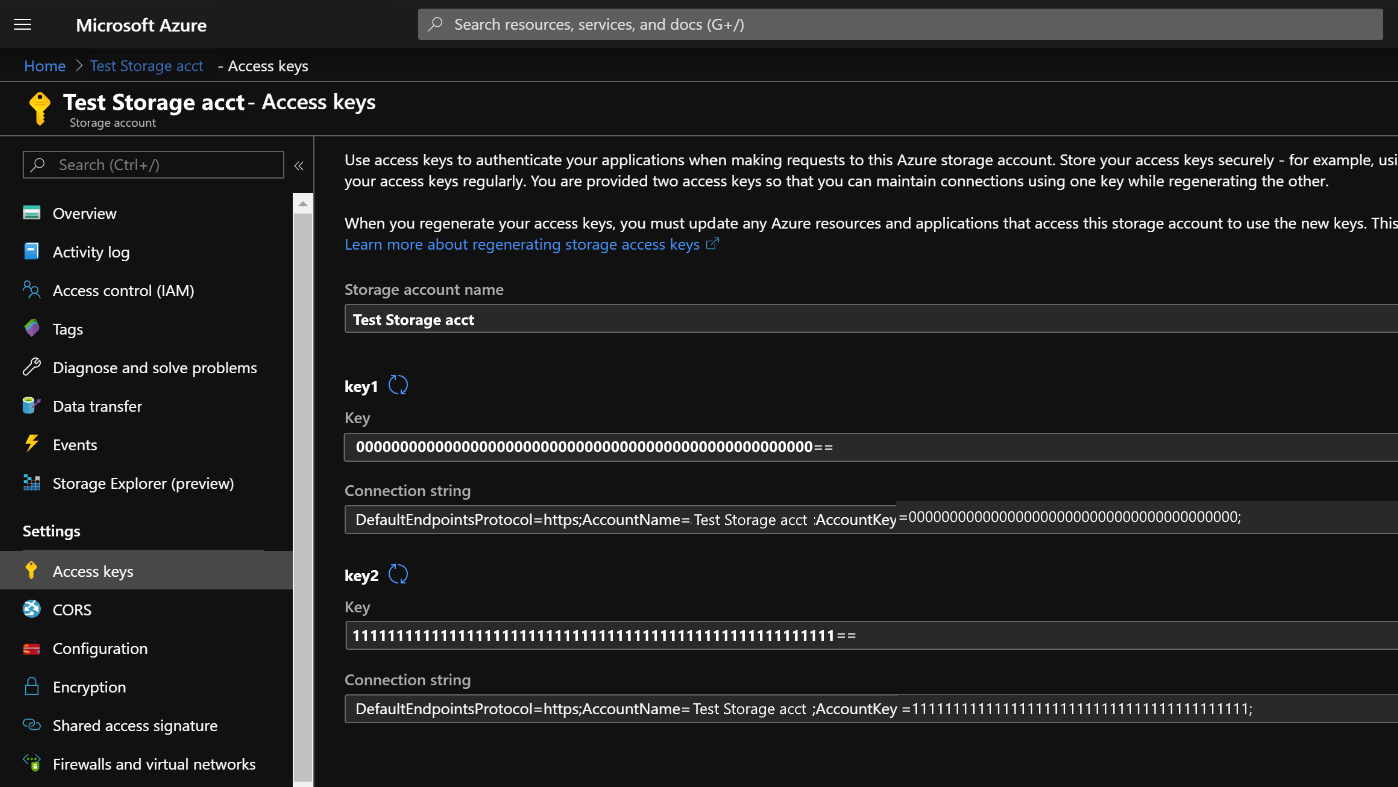
Po utworzeniu konta magazynu kliknij pozycję Klucze dostępu po lewej stronie i skopiuj klucz1. Użyjemy tego w dalszej części procesu tworzenia klastra.
Teraz zacznijmy wdrażać klaster HBase usługi HDInsight z przyspieszonymi zapisami. Wybieranie pozycji Utwórz zasób —> Analiza —> HDInsight
Na karcie Podstawy wypełnij poniższe pola w celu utworzenia klastra HBase.
Subskrypcja: powinna być wypełniana automatycznie ze szczegółami subskrypcji
Grupa zasobów: wprowadź grupę zasobów do przechowywania wdrożenia bazy danych HBase w usłudze HDInsight
Nazwa klastra: wprowadź nazwę klastra. Jeśli nazwa klastra jest dostępna, pojawi się zielony znacznik.
Region: wprowadź nazwę regionu wdrożenia
Typ klastra: Typ klastra — HBase. Wersja — HBase 2.0.0 (HDI 4.0)
Nazwa użytkownika dziennika klastra: wprowadź nazwę użytkownika dla administratora klastra (default:admin)
Hasło logowania do klastra: wprowadź hasło do logowania klastra (default:sshuser)
Potwierdź hasło logowania do klastra: Potwierdź hasło wprowadzone w ostatnim kroku
Nazwa użytkownika protokołu Secure Shell(SSH): wprowadź użytkownika logowania SSH (default:sshuser)
Użyj hasła logowania klastra dla protokołu SSH: zaznacz pole wyboru, aby użyć tego samego hasła zarówno dla logowań SSH, jak i identyfikatorów logowania systemu Ambari itp.

Kliknij przycisk Dalej:Magazyn, aby uruchomić kartę Magazyn i wypełnić poniższe pola
Podstawowy typ magazynu: Azure Storage.
Metoda wyboru: wybierz przycisk radiowy Użyj klucza dostępu
Nazwa konta magazynu: wprowadź nazwę utworzonego wcześniej konta magazynu blokowych obiektów blob w warstwie Premium
Klucz dostępu: wprowadź skopiowany wcześniej klucz dostępu key1
Kontener: usługa HDInsight powinna zaproponować domyślną nazwę kontenera. Możesz wybrać tę opcję lub utworzyć własną nazwę.
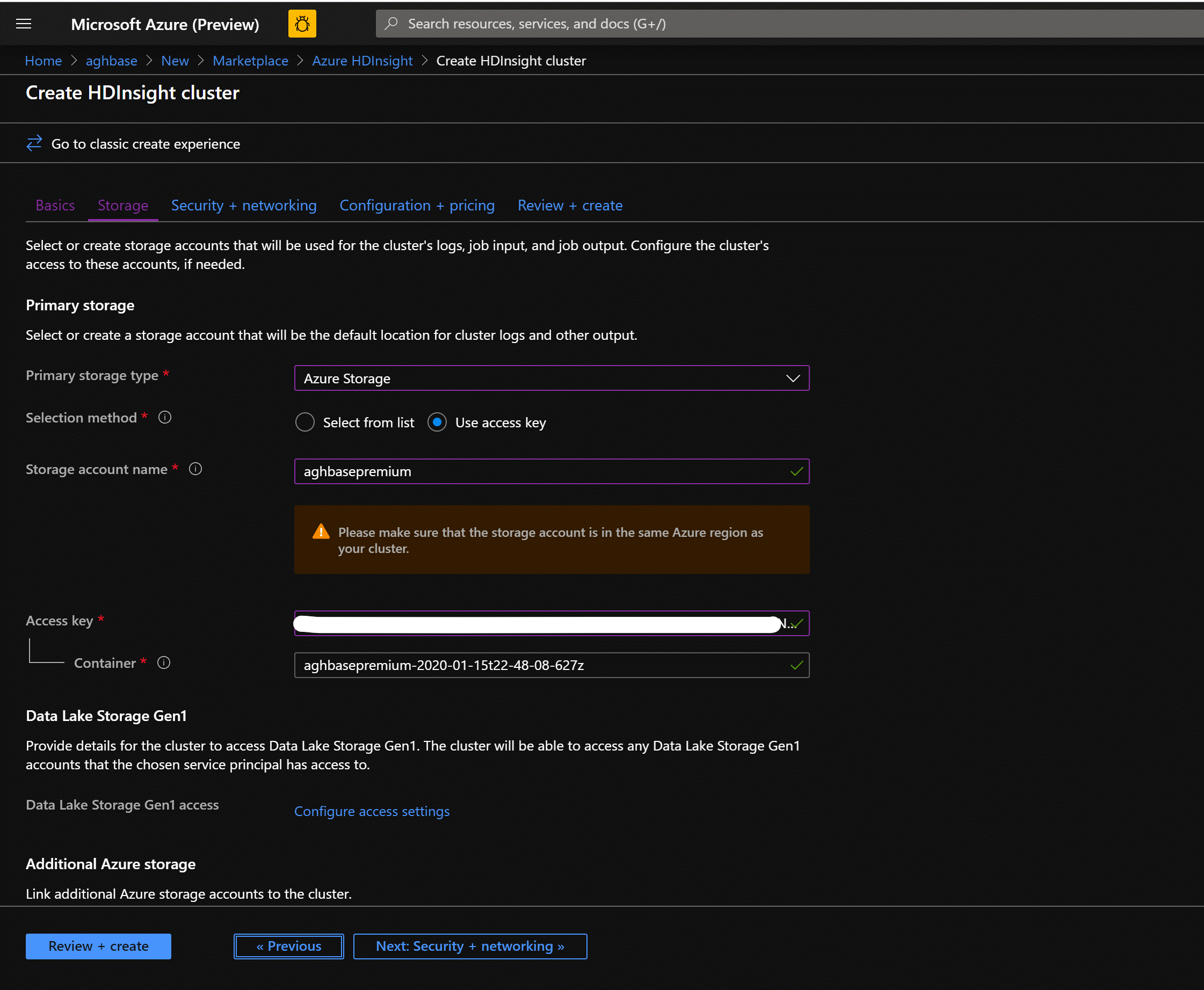
Pozostaw pozostałe opcje nietknięte i przewiń w dół, aby zaznaczyć pole wyboru Włącz przyspieszone zapisy bazy danych HBase. (Pamiętaj, że później utworzymy drugi klaster bez przyspieszonych zapisów przy użyciu tych samych kroków, ale z tym polem nie jest zaznaczone).
Pozostaw blok Zabezpieczenia i sieć do ustawień domyślnych bez zmian i przejdź do karty Konfiguracja i cennik.
Na karcie Konfiguracja i cennik zwróć uwagę , że sekcja Konfiguracja węzła zawiera teraz wiersz Pozycje o nazwie Dyski Premium na węzeł roboczy.
Wybierz węzeł Region do 10 i Rozmiar węzła do DS14v2 (możesz wybrać mniejszą liczbę maszyn wirtualnych i mniejszą jednostkę SKU maszyny wirtualnej, ale upewnij się, że oba klastry mają identyczną liczbę węzłów i jednostkę SKU maszyny wirtualnej, aby zapewnić równoważność w porównaniu)
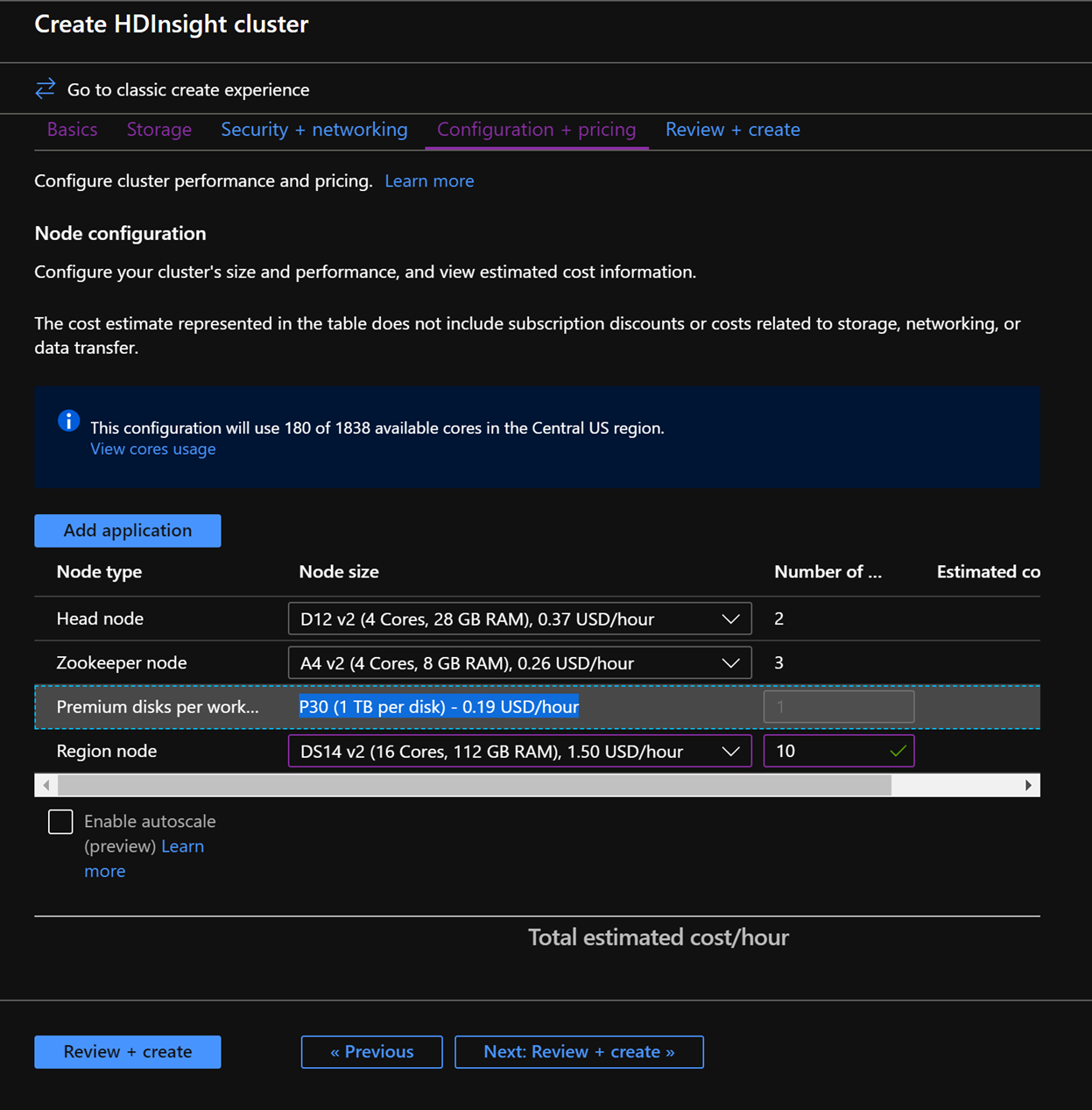
Kliknij przycisk Dalej: Przejrzyj i utwórz
Na karcie Przeglądanie i tworzenie upewnij się, że w sekcji Magazyn włączono przyspieszone zapisy bazy danych HBase.
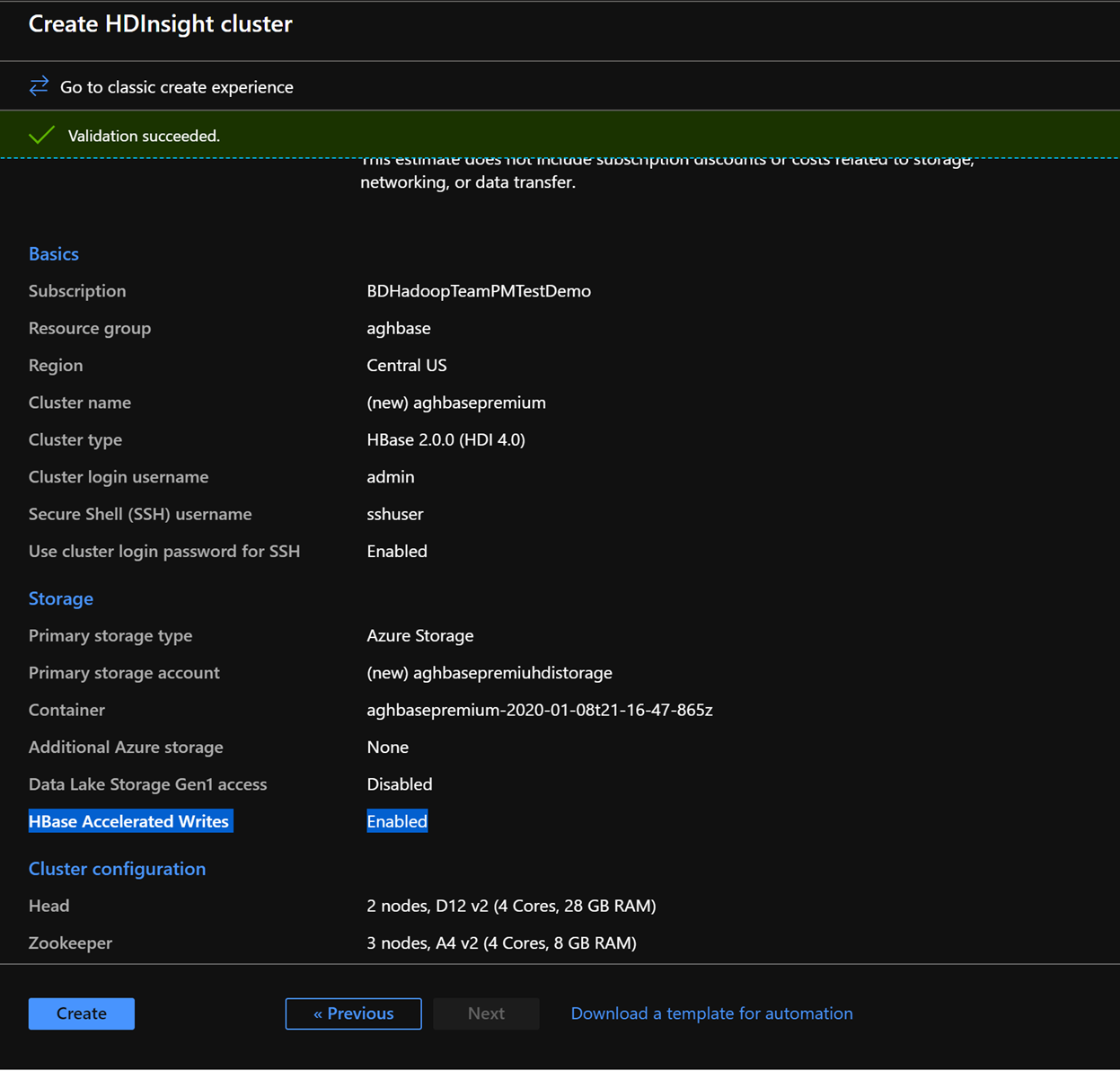
Kliknij przycisk Utwórz , aby rozpocząć wdrażanie pierwszego klastra z przyspieszonymi zapisami.
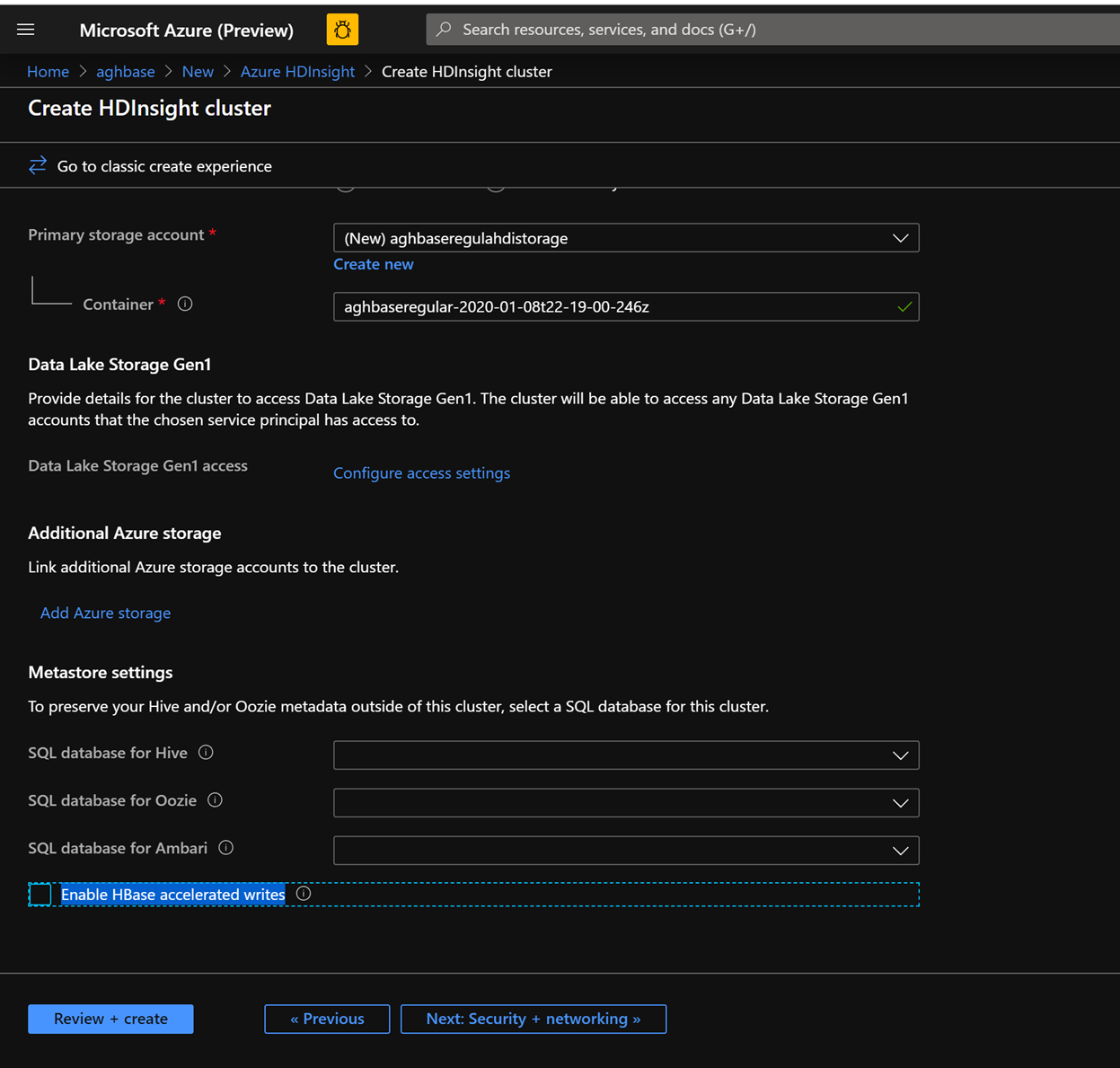
Powtórz te same kroki, aby utworzyć drugi klaster HBase usługi HDInsight, tym razem bez przyspieszonych zapisów. Zanotuj poniższe zmiany
Użyj normalnego konta usługi Blob Storage, które jest zalecane domyślnie
Pozostaw pole wyboru Włącz przyspieszone zapisy niezaznaczone na karcie Magazyn.
Na karcie Konfiguracja i cennik dla tego klastra zwróć uwagę, że sekcja Konfiguracja węzła nie ma dysków Premium na element wiersza węzła procesu roboczego.
Wybierz węzeł Region do 10 i Rozmiar węzła na D14v2.( Zwróć również uwagę na brak typów maszyn wirtualnych serii DS, takich jak wcześniej. (Można wybrać mniejszą liczbę maszyn wirtualnych i mniejszą jednostkę SKU maszyny wirtualnej, ale upewnij się, że oba klastry mają identyczną liczbę węzłów i jednostkę SKU maszyny wirtualnej w celu zapewnienia parzystości w porównaniu)
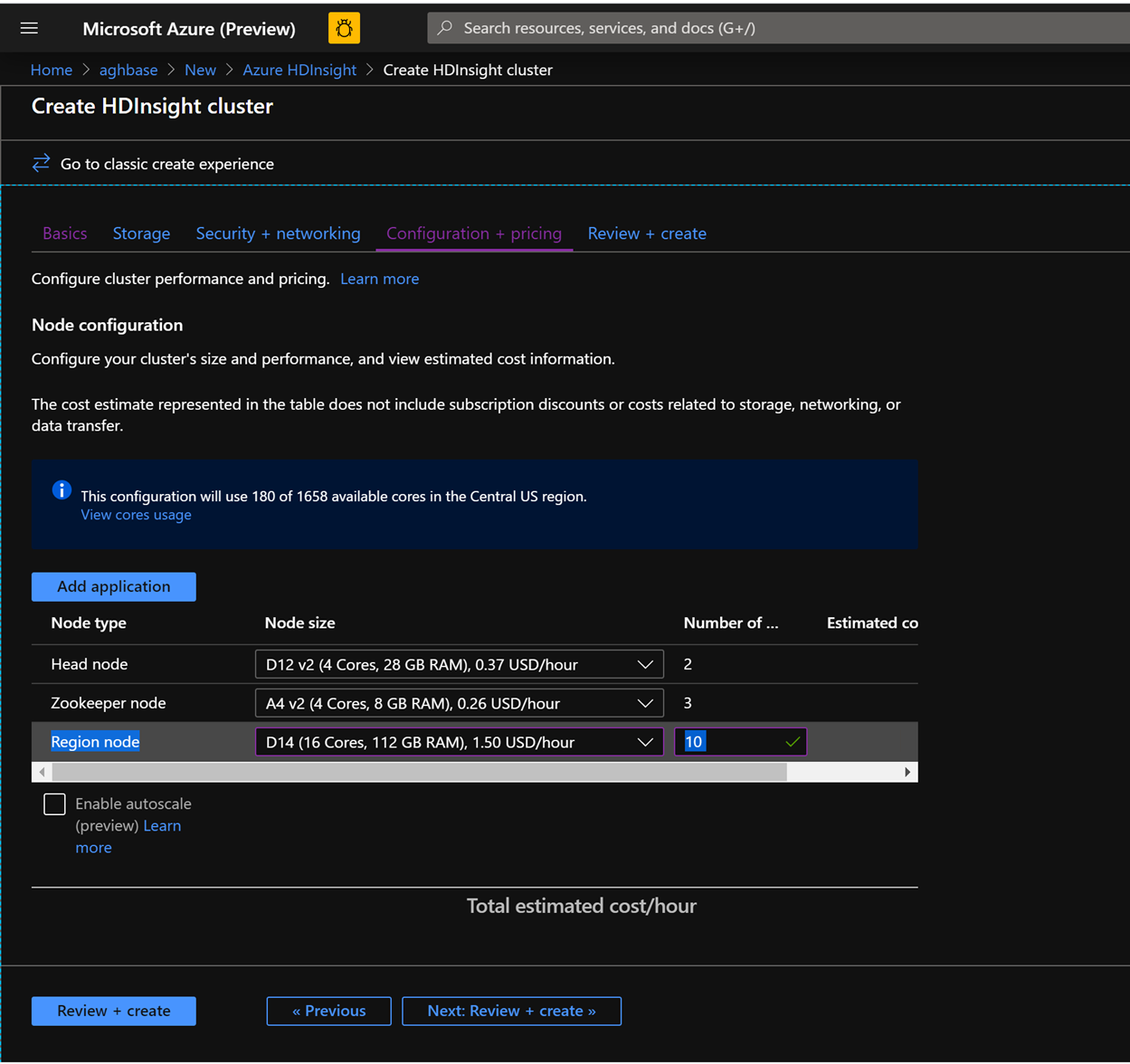
Kliknij przycisk Utwórz , aby rozpocząć wdrażanie drugiego klastra bez przyspieszonych zapisów.
Po zakończeniu wdrażania klastra w następnej sekcji skonfigurujemy i uruchomimy testy YCSB w obu tych klastrach.

Uruchamianie testów YCSB
Zaloguj się do powłoki usługi HDInsight
Kroki konfigurowania i uruchamiania testów YCSB w obu klastrach są identyczne.
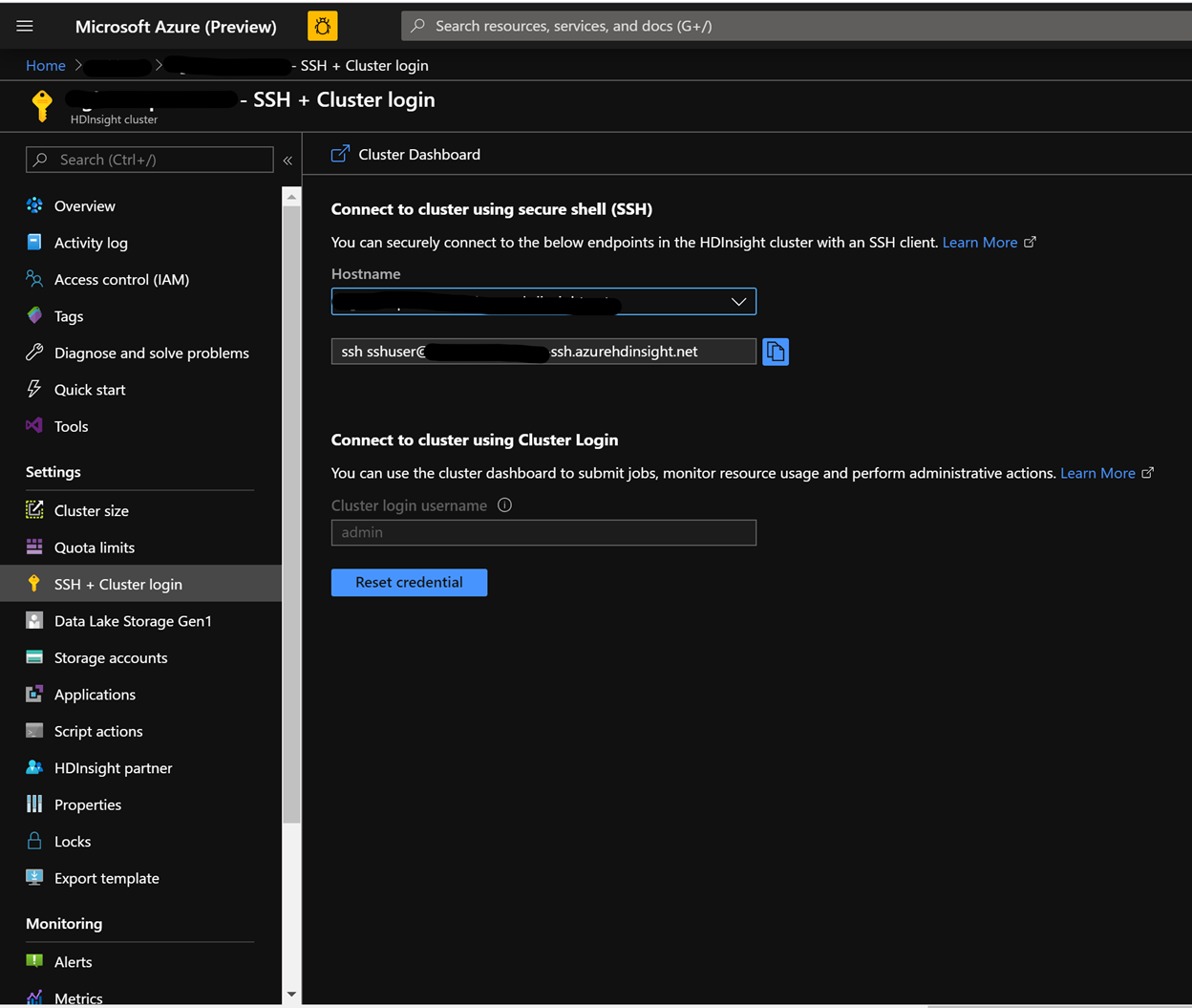
Na stronie klastra w witrynie Azure Portal przejdź do logowania SSH i klastra, a następnie użyj ścieżki Hostname i SSH, aby połączyć się z klastrem. Ścieżka powinna mieć następujący format.
sshuser<>@<clustername.azurehdinsight.net>
Tworzenie tabeli
Uruchom poniższe kroki, aby utworzyć tabele bazy danych HBase, które będą używane do ładowania zestawów danych
Uruchom powłokę HBase i ustaw parametr dla liczby podziałów tabeli. Ustaw podziały tabeli (10 * liczba serwerów regionów)
Utwórz tabelę HBase, która będzie używana do uruchamiania testów
Zamykanie powłoki HBase
hbase(main):018:0> n_splits = 100 hbase(main):019:0> create 'usertable', 'cf', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}} hbase(main):020:0> exit
Pobieranie repozytorium YSCB
Pobierz repozytorium YCSB z poniższego miejsca docelowego
$ curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gzRozpakuj folder, aby uzyskać dostęp do zawartości
$ tar xfvz ycsb-0.17.0.tar.gzSpowoduje to utworzenie folderu ycsb-0.17.0. Przenieś do tego folderu
Uruchamianie dużego obciążenia zapisu w obu klastrach
Użyj poniższego polecenia, aby zainicjować duże obciążenie zapisu przy użyciu poniższych parametrów
workloads/workloada : wskazuje, że należy uruchomić dołączanie obciążenia/obciążenia
tabela: Wypełnij nazwę utworzonej wcześniej tabeli HBase
columnfamily: Wypełnij wartość nazwy kolektora HBase z utworzonej tabeli
recordcount: liczba rekordów do wstawienia( używamy 1 miliona)
threadcount: liczba wątków( może być różna, ale musi być stała w eksperymentach)
-cp /etc/hbase/conf: Wskaźnik do ustawień konfiguracji bazy danych HBase
-s | tee -a: podaj nazwę pliku, aby zapisać dane wyjściowe.
bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat
Uruchom duże obciążenie zapisu, aby załadować 1 milion wierszy do utworzonej wcześniej tabeli HBase.
Uwaga
Ignoruj ostrzeżenia, które mogą zostać wyświetlone po przesłaniu polecenia.
Przykładowe wyniki bazy danych HBase usługi HDInsight z przyspieszonymi zapisami
Uruchom następujące polecenie:
```CMD $ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.dat ```Przeczytaj wyniki:
```CMD 2020-01-10 16:21:40:213 10 sec: 15451 operations; 1545.1 current ops/sec; est completion in 10 minutes [INSERT: Count=15452, Max=120319, Min=1249, Avg=2312.21, 90=2625, 99=7915, 99.9=19551, 99.99=113855] 2020-01-10 16:21:50:213 20 sec: 34012 operations; 1856.1 current ops/sec; est completion in 9 minutes [INSERT: Count=18560, Max=305663, Min=1230, Avg=2146.57, 90=2341, 99=5975, 99.9=11151, 99.99=296703] .... 2020-01-10 16:30:10:213 520 sec: 972048 operations; 1866.7 current ops/sec; est completion in 15 seconds [INSERT: Count=18667, Max=91199, Min=1209, Avg=2140.52, 90=2469, 99=7091, 99.9=22591, 99.99=66239] 2020-01-10 16:30:20:214 530 sec: 988005 operations; 1595.7 current ops/sec; est completion in 7 second [INSERT: Count=15957, Max=38847, Min=1257, Avg=2502.91, 90=3707, 99=8303, 99.9=21711, 99.99=38015] ... ... 2020-01-11 00:22:06:192 564 sec: 1000000 operations; 1792.97 current ops/sec; [CLEANUP: Count=8, Max=80447, Min=5, Avg=10105.12, 90=268, 99=80447, 99.9=80447, 99.99=80447] [INSERT: Count=8512, Max=16639, Min=1200, Avg=2042.62, 90=2323, 99=6743, 99.9=11487, 99.99=16495] [OVERALL], RunTime(ms), 564748 [OVERALL], Throughput(ops/sec), 1770.7012685303887 [TOTAL_GCS_PS_Scavenge], Count, 871 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3116 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.5517505152740692 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 871 [TOTAL_GC_TIME], Time(ms), 3116 [TOTAL_GC_TIME_%], Time(%), 0.5517505152740692 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 10105.125 [CLEANUP], MinLatency(us), 5 [CLEANUP], MaxLatency(us), 80447 [CLEANUP], 95thPercentileLatency(us), 80447 [CLEANUP], 99thPercentileLatency(us), 80447 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 2248.752362 [INSERT], MinLatency(us), 1120 [INSERT], MaxLatency(us), 498687 [INSERT], 95thPercentileLatency(us), 3623 [INSERT], 99thPercentileLatency(us), 7375 [INSERT], Return=OK, 1000000 ```Zapoznaj się z wynikiem testu. Niektóre przykładowe obserwacje z powyższych wyników mogą obejmować:
- Test wziął 538663 (8,97 minut) milisekund do uruchomienia
- Return=OK, 1000000 wskazuje, że wszystkie 1 miliony danych wejściowych zostały pomyślnie zapisane, **
- Przepływność zapisu wynosiła 1856 operacji na sekundę
- 95% wkładek miało opóźnienie 3389 milisekund
- Kilka wstawień zajęło więcej czasu, być może zostały zablokowane przez serwera regionów z powodu dużego obciążenia
Przykładowe wyniki bazy danych HBase usługi HDInsight bez przyspieszonych zapisów
Uruchom następujące polecenie:
$ bin/ycsb load hbase12 -P workloads/workloada -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloada.datPrzeczytaj wyniki:
2020-01-10 23:58:20:475 2574 sec: 1000000 operations; 333.72 current ops/sec; [CLEANUP: Count=8, Max=79679, Min=4, Avg=9996.38, 90=239, 99=79679, 99.9 =79679, 99.99=79679] [INSERT: Count=1426, Max=39839, Min=6136, Avg=9289.47, 90=13071, 99=27535, 99.9=38655, 99.99=39839] [OVERALL], RunTime(ms), 2574273 [OVERALL], Throughput(ops/sec), 388.45918828344935 [TOTAL_GCS_PS_Scavenge], Count, 908 [TOTAL_GC_TIME_PS_Scavenge], Time(ms), 3208 [TOTAL_GC_TIME_%_PS_Scavenge], Time(%), 0.12461770760133055 [TOTAL_GCS_PS_MarkSweep], Count, 0 [TOTAL_GC_TIME_PS_MarkSweep], Time(ms), 0 [TOTAL_GC_TIME_%_PS_MarkSweep], Time(%), 0.0 [TOTAL_GCs], Count, 908 [TOTAL_GC_TIME], Time(ms), 3208 [TOTAL_GC_TIME_%], Time(%), 0.12461770760133055 [CLEANUP], Operations, 8 [CLEANUP], AverageLatency(us), 9996.375 [CLEANUP], MinLatency(us), 4 [CLEANUP], MaxLatency(us), 79679 [CLEANUP], 95thPercentileLatency(us), 79679 [CLEANUP], 99thPercentileLatency(us), 79679 [INSERT], Operations, 1000000 [INSERT], AverageLatency(us), 10285.497832 [INSERT], MinLatency(us), 5568 [INSERT], MaxLatency(us), 1307647 [INSERT], 95thPercentileLatency(us), 18751 [INSERT], 99thPercentileLatency(us), 33759 [INSERT], Return=OK, 1000000Porównaj wyniki:
Parametr Jednostka Przy przyspieszonych zapisach Bez przyspieszonych zapisów [OVERALL], RunTime(ms) Milisekundy 567478 2574273 [GENERAL], Przepływność (ops/s) Operacje/s 1770 388 [INSERT], Operacje Liczba operacji 1000000 1000000 [INSERT], 95thPercentileLatency(us) Mikrosekundach 3623 18751 [INSERT], 99thPercentileLatency(us) Mikrosekundach 7375 33759 [INSERT], Return=OK Liczba rekordów 1000000 1000000 Oto kilka przykładowych obserwacji, które można wykonać z porównań:
- [OVERALL], RunTime(ms) : całkowity czas wykonywania w milisekundach
- [GENERAL], Przepływność (ops/s) : liczba operacji na sekundę we wszystkich wątkach
- [INSERT], Operacje: Łączna liczba operacji wstawiania, ze skojarzoną średnią, minimalną, maksymalną, 95. i 99. opóźnieniem percentylu poniżej
- [INSERT], 95thPercentileLatency(us): 95% operacji INSERT ma punkt danych poniżej tej wartości
- [INSERT], 99thPercentileLatency(us): 99% operacji INSERT ma punkt danych poniżej tej wartości
- [INSERT], Return=OK: Rekord OK wskazuje, że wszystkie operacje INSERT zakończyły się powodzeniem wraz z liczbą
Rozważ wypróbowanie szeregu innych obciążeń roboczych, aby dokonać porównań. Oto kilka przykładów:
Głównie odczyt (95% odczytu i 5% zapisu): obciążenieb
bin/ycsb run hbase12 -P workloads/workloadb -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadb.datTylko do odczytu (100% odczytu i 0% zapisu): workloadc
bin/ycsb run hbase12 -P workloads/workloadc -p table=usertable -p columnfamily=cf -p recordcount=1000000 -p operationcount=100000 -p threadcount=4 -cp /etc/hbase/conf -s | tee -a workloadc.dat