Korzystanie z rozwiązania Apache Phoenix w bazie HBase usługi HDInsight
Klastry HBase w usłudze HDInsight są dostarczane z usługą Apache Phoenix. Apache Phoenix to warstwa relacyjnej relacyjnej bazy danych typu open source oparta na bazie danych Apache HBase. Rozwiązanie Apache Phoenix umożliwia korzystanie z zapytań przypominających język SQL w bazie HBase. Używa sterowników JDBC poniżej, aby umożliwić użytkownikom tworzenie, usuwanie i zmienianie tabel SQL. Można również indeksować, tworzyć widoki i sekwencje oraz pojedynczo i zbiorczo wyświetlać wiersze upsert. Firma Phoenix używa natywnej kompilacji noSQL zamiast kompilowania zapytań przy użyciu usługi MapReduce, umożliwiając tworzenie aplikacji o małych opóźnieniach na bazie HBase. Firma Phoenix dodaje współprocesory do obsługi uruchamiania kodu dostarczonego przez klienta w przestrzeni adresowej serwera, wykonując kod kolokowany z danymi. Takie podejście minimalizuje transfer danych klienta/serwera. Aby uzyskać więcej informacji, zobacz dokumentację platformy Apache Phoenix.
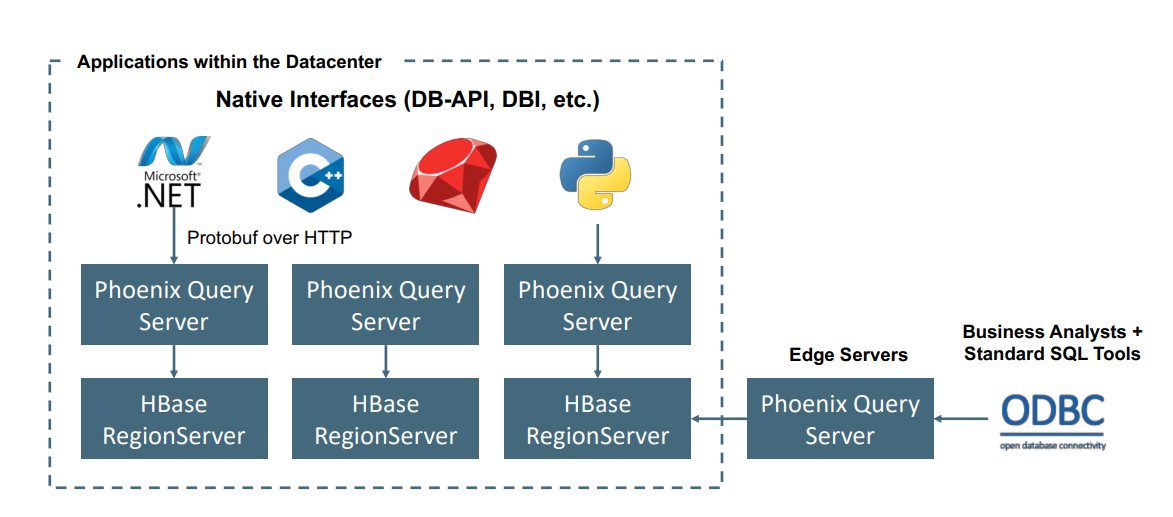
Usługa Apache Phoenix w usłudze HDInsight HBase jest zwykle używana do włączania samoobsługowej analizy i wyodrębniania szczegółowych informacji, jak pokazano poniżej. Rozwiązanie Phoenix może podłączyć dowolne narzędzie do analizy biznesowej zgodnej z odBC i włączyć analizę SQL ad hoc w bazie danych HBase.
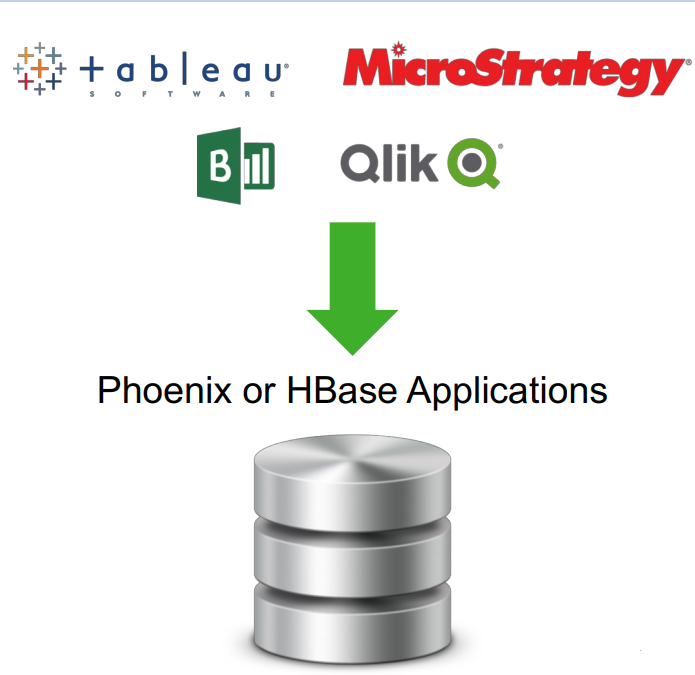
Łączenie baz danych Apache HBase i Phoenix może służyć jako magazyn danych modyfikowalnych. Aparat zapytań apache Phoenix w bazie HBase zawiera pewne ważne funkcje.
Indeksy pomocnicze
Dostęp do rekordów w bazie HBase jest uzyskiwany przy użyciu klucza wiersza podstawowego przy użyciu pojedynczego indeksu, który jest posortowany leksykograficznie w kluczu wiersza podstawowego. Jeśli próbujesz uzyskać dostęp do rekordów w jakikolwiek inny sposób niż wiersz podstawowy, może to prowadzić do nieefektywnego skanowania wszystkich danych w tabeli HBase. Rozwiązanie Apache Phoenix umożliwia tworzenie indeksów pomocniczych dla kolumn i wyrażeń w celu utworzenia alternatywnych kluczy wierszy w celu umożliwienia wyszukiwania punktów lub skanowania zakresu wzdłuż tego nowego indeksu. Aby uzyskać więcej informacji, zobacz dokumentację indeksów pomocniczych apache Phoenix.
Polecenie CREATE INDEX służy do tworzenia indeksów pomocniczych w bazie HBase, jak pokazano poniżej.
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Widoki
Ograniczenie liczby tabel fizycznych w bazie HBase i z kolei ograniczenie liczby regionów jest zalecaną strategią. Widoki w phoenix pomagają w tym poleceniu, umożliwiając tworzenie wielu tabel wirtualnych współużytkowanych tej samej podstawowej tabeli fizycznej w bazie HBase. Aby uzyskać więcej informacji, zobacz dokumentację widoków Apache Phoenix.
Biorąc pod uwagę poniższą definicję tabeli w bazie HBase.
CREATE TABLE product_metrics (
metric_type CHAR(1),
created_by VARCHAR,
created_date DATE,
metric_id INTEGER
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Możesz zdefiniować następujący widok.
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS SELECT * FROM product_metric WHERE metric_type = 'm';
Transakcje
Mimo że baza HBase działa tylko z transakcjami na poziomie wiersza, apache Phoenix umożliwia wykonywanie transakcji między tabelami i wierszami z pełną obsługą acid dzięki integracji z platformą Apache Tephra.
Aby uzyskać więcej informacji, zobacz dokumentację transakcji Apache Phoenix
Poniższy przykład tworzy tabelę o nazwie my_table, a następnie zmienia tabelę w celu włączenia transakcji.
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Tabele z solą
Hotspotting serwera regionów w bazie HBase może wystąpić podczas sekwencyjnych zapisów, jeśli klucze wierszy zwiększają się monotonicznie. Apache Phoenix może złagodzić hotspotting, zapewniając sposób na sprzężenie klucza wiersza z bajtem solnym dla określonej tabeli. Aby uzyskać więcej informacji, zapoznaj się z dokumentacją usługi Apache Phoenix Salted Table.
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Pomiń skanowanie
W przypadku danego zestawu wierszy usługa Apache Phoenix używa funkcji Pomiń skanowanie w celu skanowania wewnątrz wiersza w celu uzyskania lepszej wydajności. Pomiń skanowanie korzysta z filtru HBase SEEK_NEXT_USING_HINT. Przechowuje informacje o tym, jaki zestaw kluczy/zakresów kluczy są wyszukiwane w każdej kolumnie. Następnie pobiera klucz (przekazany do niego podczas oceny filtru) i określa, czy znajduje się on w jednej z kombinacji lub zakresu, czy nie. Jeśli nie, dowiedzieć się, który następny najwyższy klucz do skoku. Aby uzyskać więcej informacji, zobacz dokumentację dotyczącą pomijania skanowania w usłudze Apache Phoenix.
Optymalizacja wydajności w systemie Apache Phoenix jest opcjonalną żądaną funkcją i jest głównie zależna od optymalizacji wydajności bazy danych HBase poniżej. Optymalizacja wydajności jest złożonym tematem i wykracza poza zakres tego kursu. Jeśli jednak cię interesuje, zapoznaj się z dokumentacją dotyczącą najlepszych rozwiązań dotyczących wydajności usługi Apache Phoenix.