Opis bazy danych Apache HBase
Apache HBase to baza danych NoSQL typu open source oparta na platformie Apache Hadoop. Baza HBase zapewnia dostęp losowy i silną spójność dla dużych ilości danych bez struktury i częściowo ustrukturyzowanych w bez schematowej bazie danych zorganizowanej według rodzin kolumn. Klastry HBase usługi HDInsight 4.0 są dostarczane z bazą danych Apache HBase 2.1.6 i Apache Phoenix 5.
Z perspektywy użytkownika baza HBase jest podobna do bazy danych. Dane są przechowywane w wierszach i kolumnach tabeli, a dane w wierszu są grupowane według rodziny kolumn. HBase jest bezschematową bazą danych, co oznacza, że ani kolumny, ani typy danych w nich przechowywanych nie muszą być zdefiniowane przed użyciem. Kod typu open source zapewnia skalowanie liniowe, umożliwiając obsługę petabajtów danych na tysiącach węzłów.
Baza HBase ma następujące funkcje, które sprawiają, że są unikatowe
Spójne odczyty i zapisy
Operacje o małych opóźnieniach
Automatyczne fragmentowanie
Automatyczne przełączanie serwera regionów w tryb failover
Integracja z usługą Hadoop/HDFS/MapReduce
Interfejs API klienta Języka Java
Obsługuje funkcję Thrift i REST dla frontonów innych niż java
Blokuj pamięć podręczną i filtry Bloom
Usługa Azure HDInsight HBase z usługą Apache Phoenix oferuje następujące dodatkowe korzyści
Interfejsy SQL i Brak interfejsów SQL
Elastyczne planowanie pojemności
Globalna dystrybucja i replikacja za pomocą sieci platformy Azure
Rozdzielenie zasobów obliczeniowych i magazynu
Ściśle zintegrowana z funkcjami zabezpieczeń usługi HDInsight Enterprise
Przyspieszone zapisy bazy danych HBase w usłudze HDInsight dla operacji odczytu i zapisu o bardzo małych opóźnieniach
Apache Phoenix dla bazy danych SQL w czasie rzeczywistym, takich jak wykonywanie zapytań
Korzystanie z usługi Azure HDInsight z bazą HBase umożliwia uruchamianie baz danych NoSQL na dużą skalę. Jako inżynierowie danych dla firmy Contoso należy uruchomić testy porównawcze, aby zrozumieć wydajność i skalę bazy danych HBase usługi HDInsight przed użyciem platformy do scenariuszy produkcyjnych o krytycznym znaczeniu.
Baza HBase w usłudze HDInsight działa z rozdzieleniem zasobów obliczeniowych i magazynu. Klastry HBase usługi HDInsight są skonfigurowane do przechowywania danych bezpośrednio w usłudze Azure Storage, co zapewnia małe opóźnienia i zwiększoną elastyczność w zakresie wydajności i kosztów. Ta właściwość umożliwia klientom tworzenie interaktywnych witryn internetowych, które współpracują z dużymi zestawami danych. Aby tworzyć usługi, które przechowują dane czujników i danych telemetrycznych z milionów punktów końcowych, oraz do analizowania tych danych za pomocą zadań hadoop. Bazy danych HBase i Hadoop są dobrymi punktami wyjścia dla projektów danych big data na platformie Azure. Usługi mogą umożliwić aplikacjom czasu rzeczywistego pracę z dużymi zestawami danych. Implementacje bazy danych HBase w usłudze HDInsight używają architektury HBase skalowanej w poziomie w celu zapewnienia automatycznego fragmentowania tabel. Zapewnia również silną spójność operacji odczytu i zapisu oraz automatycznego trybu failover. Wydajność jest zwiększona dzięki buforowaniu w pamięci operacji odczytu i przesyłaniu strumieniowemu o wysokiej przepustowości obejmującemu operacje zapisu. Klaster bazy danych HBase można utworzyć w sieci wirtualnej. Aby uzyskać szczegółowe informacje, zobacz temat Create HDInsight clusters on Azure Virtual Network (Tworzenie klastrów usługi HDInsight w usłudze Azure Virtual Network).
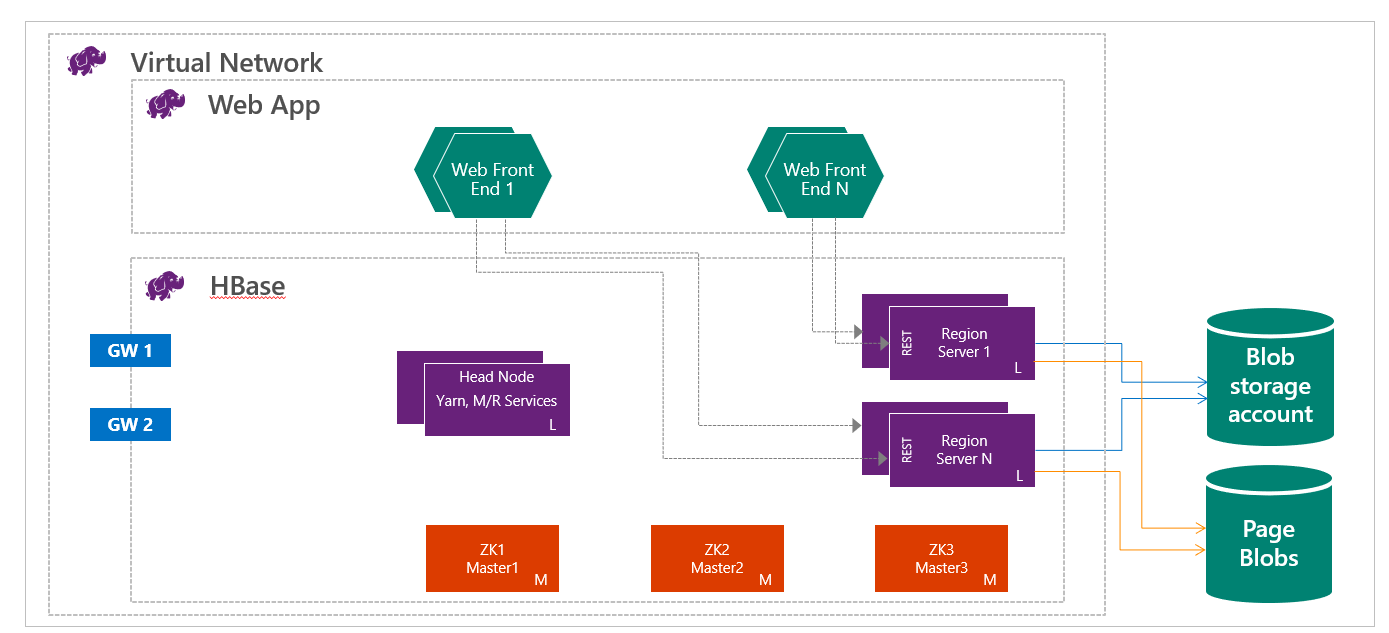
Jako inżynier danych musisz określić najbardziej odpowiedni rodzaj klastra usługi HDInsight w celu utworzenia rozwiązania. Użyjesz klastrów HBase w usłudze HDInsight dla bazy danych NoSQL, która skaluje liniowo, osiągając ogromną przepływność, zapewnia odczyty o małych opóźnieniach i nieograniczony magazyn po ułamku kosztów.
Poniżej przedstawiono kluczowe scenariusze korzystania z bazy danych HBase w usłudze HDInsight.
Magazyn par klucz-wartość
Baza HBase jest zwykle używana jako magazyn klucz-wartość i nadaje się do zarządzania systemami komunikatów.
Dane czujników
Baza HBase jest przydatna do przechwytywania danych zbieranych przyrostowo z różnych źródeł, w tym analizy społecznościowej, szeregów czasowych, aktualizowania interaktywnych pulpitów nawigacyjnych za pomocą trendów i liczników oraz zarządzania systemami dzienników inspekcji.
Zapytania w czasie rzeczywistym
Apache Phoenix to aparat zapytań SQL dla bazy danych Apache HBase. Jest on dostępny jako sterownik JDBC i umożliwia wykonywanie zapytań w tabelach HBase i zarządzanie nimi przy użyciu języka SQL.
HBase jako platforma
Aplikacje mogą działać w bazie danych HBase, wykorzystując ją jako magazyn danych. Przykłady obejmują aplikacje Phoenix, OpenTSDB, Kiji i Titan. Aplikacje można również integrować z bazą danych HBase. Przykłady to Apache Hive, Apache Pig, Solr, Apache Flume, Apache Impala, Apache Spark, Ganglia i Apache Drill.
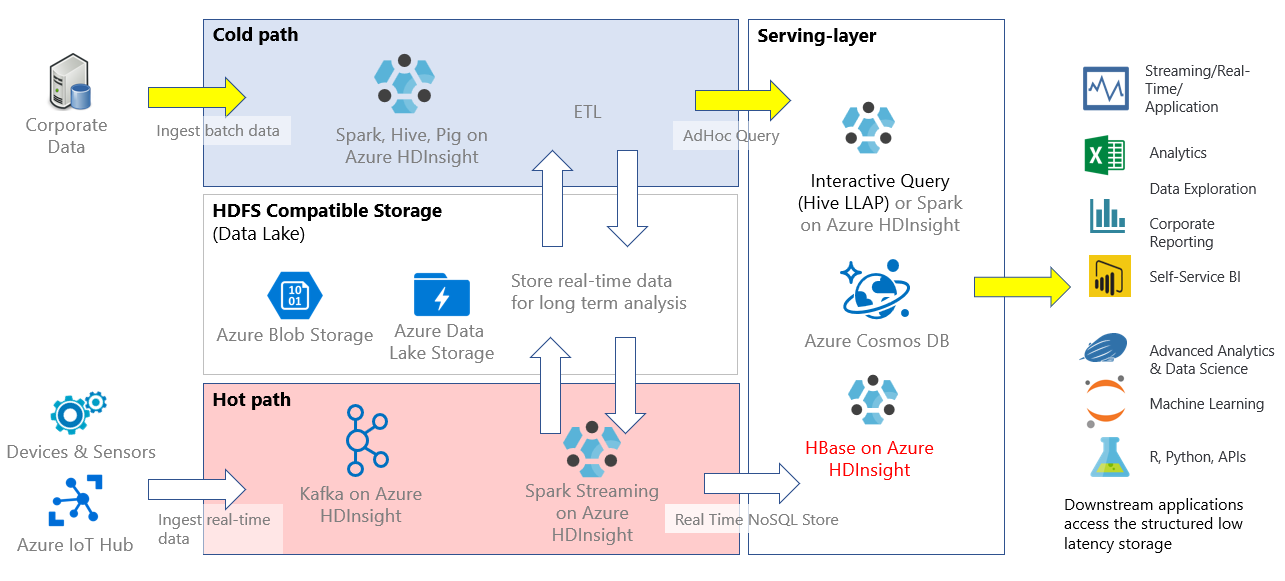
W usłudze HDInsight baza HBase może być używana jako aplikacja autonomiczna lub wdrażana wraz z innymi aplikacjami do analizy danych big data, takimi jak Spark, Hadoop, Hive lub Kafka.
Model danych HBase przechowuje częściowo ustrukturyzowane dane o różnych typach danych, różne rozmiary kolumn i rozmiar pola. Układ modelu danych HBase ułatwia partycjonowanie i dystrybucję danych w klastrze. Model danych HBase składa się z kilku składników logicznych — kluczy wierszy, rodziny kolumn, nazwy tabeli, sygnatury czasowej itp.
Klucz wiersza służy do unikatowego identyfikowania wierszy w tabelach HBase. W usłudze HDInsight można zapisać dane w bazie HBase bezpośrednio przy użyciu wielu dostępnych interfejsów API, takich jak HBase REST, HBase RPC, Phoenix Query Server, ładowanie zbiorcze bazy danych HBase, lub użyć integracji z kilkoma strukturami danych big data, takimi jak Apache Spark, Hive itp.
Możesz użyć funkcji przyspieszonych zapisów bazy danych HBase, aby umożliwić wysoką przepływność zapisu. Aby dowiedzieć się więcej na temat architektury bazy danych HBase i najlepszych rozwiązań, zapoznaj się z książką HBase.