Wprowadzenie do magazynu zdarzeń
Aby utworzyć magazyn zdarzeń, musisz pracować nad obszarem roboczym z pojemnością sieci szkieletowej, która obsługuje możliwości usługi Intelligence Fabric w czasie rzeczywistym. Następnie możesz utworzyć co najmniej jeden magazyn zdarzeń dla danych.
Magazyn zdarzeń zawiera co najmniej jedną bazę danych KQL, w której można tworzyć tabele, procedury składowane, zmaterializowane widoki i inne elementy do zarządzania danymi. Po utworzeniu magazynu zdarzeń można użyć domyślnej bazy danych KQL lub utworzyć nową.
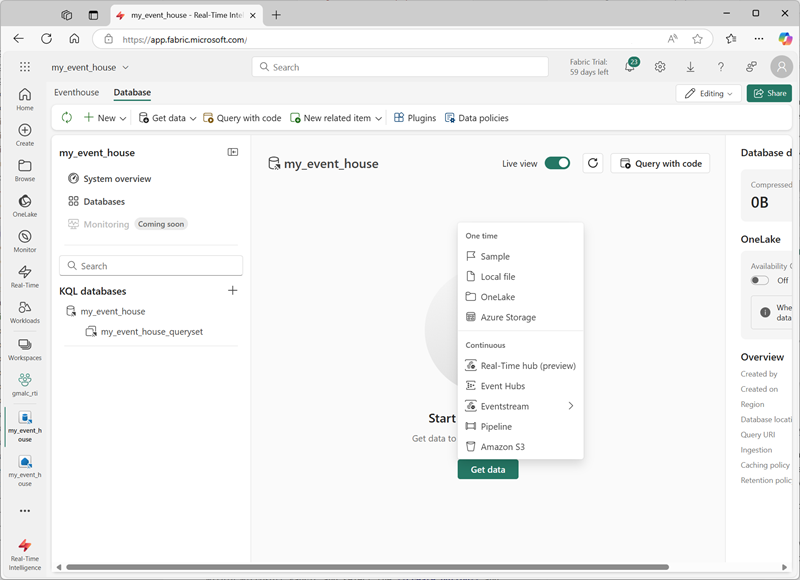
Aby pobrać dane do bazy danych KQL w magazynie zdarzeń, zazwyczaj importujesz je z lokalizacji statycznej (np. pliku lokalnego, usługi OneLake, usługi Azure Storage lub przykładowego zestawu danych) lub ze źródła czasu rzeczywistego (takiego jak usługa Azure Event Hubs lub strumień zdarzeń sieci Szkieletowej).
Uwaga
Możesz włączyć opcję OneLake dla bazy danych lub dla poszczególnych tabel, które zawiera, dzięki czemu dane z tych tabel są dostępne w usłudze OneLake.
Wykonywanie zapytań dotyczących tabel w bazie danych KQL
Aby wykonać zapytanie o dane w tabelach w bazie danych KQL, możesz napisać kod język zapytań Kusto (KQL) lub użyć ograniczonego podzestawu instrukcji Języka zapytań strukturalnych (SQL).
Aby ułatwić tworzenie zapytań, centra zdarzeń obejmują obsługę co najmniej jednego zestawu zapytań KQL, co upraszcza tworzenie zapytań, zapewniając przykładową składnię i narzędzia do kodowania. Podano domyślny zestaw zapytań i w razie potrzeby można utworzyć więcej.
Składnia języka KQL jest intuicyjna i zwięzła oraz zawiera szeroką gamę funkcji i wyrażeń, które ułatwiają wydajną analizę złożonych danych.
Najprostsze zapytanie KQL składa się po prostu z nazwy tabeli. Aby na przykład pobrać wszystkie dane z tabeli o nazwie Automotive, można uruchomić następujące zapytanie:
Automotive
To zapytanie KQL jest odpowiednikiem wyrażenia SELECT * FROM AutomotiveSQL .
Biorąc pod uwagę potencjalnie ogromny rozmiar tabel opartych na niezwiązanych strumieniach danych w czasie rzeczywistym, użycie prostego zapytania o nazwę tabeli jest nietypowe. Jeśli chcesz pobrać próbkę danych z tabeli, możesz użyć słowa kluczowego take , jak pokazano poniżej:
Automotive
| take 100
To zapytanie zwraca 100 wierszy z tabeli Automotive (podobnie jak sql SELECT TOP 100 * FROM Automotive). Zwróć uwagę na użycie znaku w | każdym nowym wierszu, aby oddzielić klauzule zapytania.
Poniżej przedstawiono niektóre typowe zapytania i ich odpowiedniki SQL
Pobieranie określonych kolumn
Automotive
| project trip_id, pickup_datetime, fare_amount
SELECT trip_id, pickup_datetime, fare_amount
FROM Automotive
Filtruj wiersze
Automotive
| where fare_amount > 20
| project trip_id, pickup_datetime, fare_amount
SELECT trip_id, pickup_datetime, fare_amount
FROM Automotive
WHERE fare_amount > 20
Sortowanie wyników
Automotive
| where fare_amount > 20
| project trip_id, pickup_datetime, fare_amount
| sort by pickup_datetime desc
SELECT trip_id, pickup_datetime, fare_amount
FROM Automotive
WHERE fare_amount > 20
ORDER BY pickup_datetime DESC
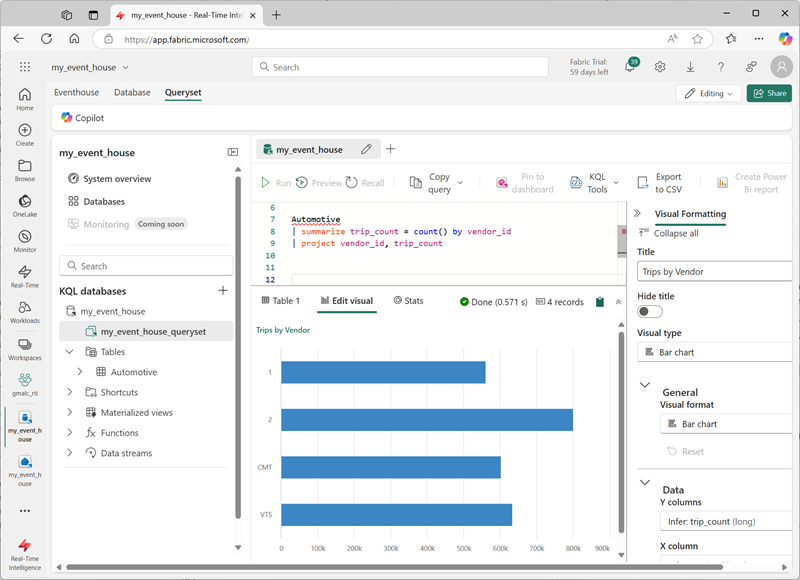
Grupowanie i agregowanie
Automotive
| summarize trip_count = count() by vendor_id
| project vendor_id, trip_count
SELECT vendor_id, COUNT(*) AS trip_count
FROM Automotive
GROUP BY vendor_id
Uwaga
We wszystkich powyższych przykładach można użyć zapytania KQL lub równoważnego zapytania SQL, aby pobrać dane z tabeli w bazie danych KQL. Istnieją zalety każdego języka, a w przypadku bazy danych KQL język KQL jest preferowanym językiem z następujących powodów:
- Prostota: język KQL jest prostszy niż SQL, co ułatwia naukę i używanie.
- Wydajność: język KQL jest zoptymalizowany pod kątem wydajności i może obsługiwać duże ilości danych wydajniej niż SQL.
- Elastyczność: język KQL jest bardziej elastyczny niż SQL, co pozwala użytkownikom na łatwe wykonywanie złożonych zapytań.
- Integracja: język KQL jest zintegrowany z innymi produktami firmy Microsoft, takimi jak Azure Monitor i Azure Sentinel.
Jedną z głównych wad używania języka SQL przez KQL jest to, że nie jest to język macierzysty silnika i musi przejść przez transformator. Ta różnica w języku uniemożliwia publikowanie ich w usłudze Power BI bezpośrednio z zestawu zapytań.
Jednak w niektórych przypadkach sql może być dobrym wyborem z następujących powodów:
- Zgodność: SQL jest powszechnie używanym językiem i jest zgodny z wieloma różnymi systemami baz danych.
- Funkcjonalność: język SQL ma szerszy zakres funkcji i funkcji niż język KQL.
- Programowanie proceduralne: program SQL obsługuje programowanie proceduralne, które umożliwia deweloperom pisanie złożonych skryptów i procedur składowanych.
Wizualizowanie wyników zapytania w zestawie zapytań
Chociaż ostatecznie możesz tworzyć pulpity nawigacyjne w czasie rzeczywistym lub raporty usługi Power BI na podstawie zapytań, może to być przydatne podczas eksplorowania danych w zestawie zapytań w celu utworzenia szybkich wizualizacji danych. W przypadku wielu typowych środowisk deweloperskich notesów zestawy zapytań KQL obejmują możliwość renderowania wyników zapytania jako wykresu.
Korzystanie z narzędzia Copilot w celu ułatwienia zapytań
Aby uzyskać pomoc opartą na sztucznej inteligencji w zakresie wykonywania zapytań KQL, możesz użyć narzędzia Copilot na potrzeby analizy w czasie rzeczywistym.
Gdy administrator włączył funkcję Copilot, zobaczysz opcję na pasku menu zestawu zapytań. Copilot otwiera okienko po stronie głównego interfejsu zapytania. Gdy zadajesz pytanie dotyczące danych, copilot generuje kod KQL, aby odpowiedzieć na swoje pytanie.