Ćwiczenie: trenowanie modelu uczenia maszynowego
Zebrano dane czujników z urządzeń produkcyjnych, które są w dobrej kondycji i te, które zakończyły się niepowodzeniem. Teraz chcesz użyć narzędzia Model Builder do wytrenowania modelu uczenia maszynowego, który przewiduje, czy maszyna zakończy się niepowodzeniem, czy nie. Korzystając z uczenia maszynowego w celu zautomatyzowania monitorowania tych urządzeń, możesz zaoszczędzić pieniądze firmy, zapewniając większą czasową i niezawodną konserwację.
Dodawanie nowego elementu modelu uczenia maszynowego (ML.NET)
Aby rozpocząć proces trenowania, musisz dodać nowy element modelu uczenia maszynowego (ML.NET) do nowej lub istniejącej aplikacji .NET.
Tworzenie biblioteki klas języka C#
Ponieważ zaczynasz od podstaw, utwórz nowy projekt biblioteki klas języka C#, w którym dodasz model uczenia maszynowego.
Uruchom program Visual Studio.
W oknie uruchamiania wybierz pozycję Utwórz nowy projekt.
W oknie dialogowym Tworzenie nowego projektu wprowadź bibliotekę klas na pasku wyszukiwania.
Wybierz pozycję Biblioteka klas z listy opcji. Upewnij się, że język to C# i wybierz przycisk Dalej.
W polu tekstowym Nazwa projektu wprowadź wartość PredictiveMaintenance. Pozostaw wartości domyślne dla wszystkich innych pól i wybierz pozycję Dalej.
Wybierz pozycję .NET 6.0 (wersja zapoznawcza) z listy rozwijanej Framework , a następnie wybierz pozycję Utwórz , aby utworzyć szkielet biblioteki klas języka C#.

Dodawanie uczenia maszynowego do projektu
Gdy projekt biblioteki klas zostanie otwarty w programie Visual Studio, nadszedł czas, aby dodać do niego uczenie maszynowe.
W programie Visual Studio Eksplorator rozwiązań kliknij prawym przyciskiem myszy projekt.
Wybierz pozycję Dodaj>model uczenia maszynowego.
Z listy nowych elementów w oknie dialogowym Dodawanie nowego elementu wybierz pozycję Model uczenia maszynowego (ML.NET).
W polu tekstowym Nazwa użyj nazwy PredictiveMaintenanceModel.mbconfig dla modelu i wybierz pozycję Dodaj.


Po kilku sekundach do projektu zostanie dodany plik o nazwie PredictiveMaintenanceModel.mbconfig .
Wybieranie scenariusza
Po pierwszym dodaniu modelu uczenia maszynowego do projektu zostanie otwarty ekran Konstruktor modelu. Teraz nadszedł czas, aby wybrać swój scenariusz.
W przypadku użycia próbujesz określić, czy maszyna jest uszkodzona, czy nie. Ponieważ istnieją tylko dwie opcje i chcesz określić stan, w którym znajduje się maszyna, scenariusz klasyfikacji danych jest najbardziej odpowiedni.
W kroku Scenariusz ekranu konstruktora modelu wybierz scenariusz klasyfikacji danych. Po wybraniu tego scenariusza natychmiast przejdź do kroku Środowisko .

Wybieranie środowiska
W przypadku scenariuszy klasyfikacji danych obsługiwane są tylko środowiska lokalne korzystające z procesora CPU.
- W kroku Środowisko ekranu konstruktora modelu domyślnie wybierana jest opcja Lokalna (procesor CPU). Pozostaw wybrane środowisko domyślne.
- Wybierz pozycję Następny krok.

Ładowanie i przygotowywanie danych
Po wybraniu scenariusza i środowiska szkoleniowego nadszedł czas na załadowanie i przygotowanie zebranych danych przy użyciu narzędzia Model Builder.
Przygotowywanie danych
Otwórz plik w wybranym edytorze tekstów.
Oryginalne nazwy kolumn zawierają znaki nawiasu specjalnego. Aby zapobiec problemom z analizowaniem danych, usuń znaki specjalne z nazw kolumn.
Oryginalny nagłówek:
UDI,Product ID,Type,Air temperature [K],Process temperature [K],Rotational speed [rpm],Torque [Nm],Tool wear [min],Machine failure,TWF,HDF,PWF,OSF,RNFZaktualizowany nagłówek:
UDI,Product ID,Type,Air temperature,Process temperature,Rotational speed,Torque,Tool wear,Machine failure,TWF,HDF,PWF,OSF,RNFZapisz plik ai4i2020.csv ze zmianami.
Wybierz typ źródła danych
Zestaw danych konserwacji predykcyjnej jest plikiem CSV.
W kroku Dane ekranu konstruktora modelu wybierz pozycję Plik (csv, tsv, txt) dla pozycji Typ źródła danych.
Podaj lokalizację danych
Wybierz przycisk Przeglądaj i użyj Eksploratora plików, aby podać lokalizację zestawu danych ai4i2020.csv.
Wybieranie kolumny etykiety
Wybierz pozycję Niepowodzenie maszyny z listy rozwijanej Kolumna, aby przewidzieć (etykietę).

Wybieranie zaawansowanych opcji danych
Domyślnie wszystkie kolumny, które nie są etykietą, są używane jako funkcje. Niektóre kolumny zawierają nadmiarowe informacje, a inne nie informują o prognozie. Użyj zaawansowanych opcji danych, aby zignorować te kolumny.
Wybierz pozycję Zaawansowane opcje danych.
W oknie dialogowym Zaawansowane opcje danych wybierz kartę Ustawienia kolumny.
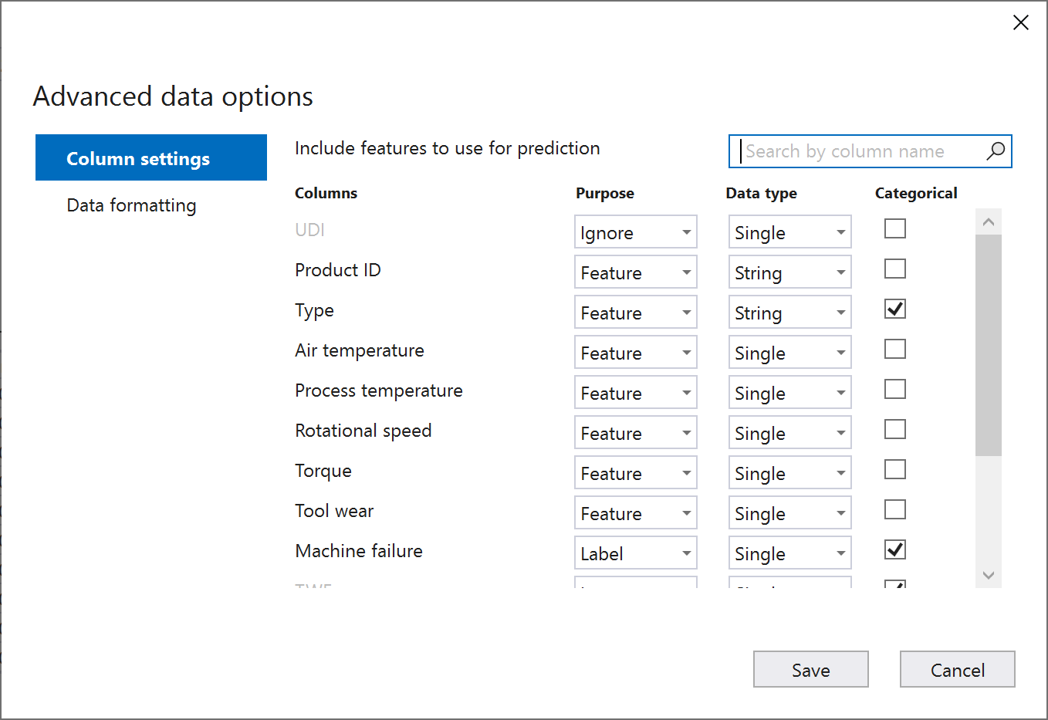
Skonfiguruj ustawienia kolumny w następujący sposób:
Kolumny Purpose Typ danych Podzielone na kategorie UDI Ignoruj Pojedynczy Identyfikator produktu Funkcja String Typ Funkcja String X Temperatura powietrza Funkcja Pojedynczy Temperatura procesu Funkcja Pojedynczy Prędkość rotacji Funkcja Pojedynczy Obrócić Funkcja Pojedynczy Zużycie narzędzi Funkcja Pojedynczy Awaria maszyny Etykieta Pojedynczy X TWF Ignoruj Pojedynczy X HDF Ignoruj Pojedynczy X PWF Ignoruj Pojedynczy X OSF Ignoruj Pojedynczy X RNF Ignoruj Pojedynczy X Wybierz pozycję Zapisz.
W kroku Dane ekranu konstruktora modelu wybierz pozycję Następny krok.

Szkolenie modelu
Trenowanie modelu przy użyciu narzędzia Model Builder i rozwiązania AutoML.
Ustawianie czasu trenowania
Narzędzie Model Builder automatycznie ustawia czas trenowania na podstawie rozmiaru pliku. W tym przypadku, aby ułatwić konstruktorowi modeli eksplorowanie większej liczby modeli, podaj większą liczbę czasu trenowania.
- Na ekranie Trenowanie konstruktora modelu ustaw wartość Czas trenowania (w sekundach) na 30.
- Wybierz Szkolenie.
Śledzenie procesu trenowania

Po rozpoczęciu procesu trenowania narzędzie Model Builder eksploruje różne modele. Proces trenowania jest śledzony w wynikach trenowania i w oknie danych wyjściowych programu Visual Studio. Wyniki trenowania zawierają informacje o najlepszym modelu, który został znaleziony w całym procesie trenowania. Okno danych wyjściowych zawiera szczegółowe informacje, takie jak nazwa używanego algorytmu, czas trenowania oraz metryki wydajności dla tego modelu.
Ta sama nazwa algorytmu może być wyświetlana wiele razy. Dzieje się tak, ponieważ oprócz próby różnych algorytmów narzędzie Model Builder próbuje różnych konfiguracji hiperparametrów dla tych algorytmów.
Ocenianie modelu
Użyj metryk i danych oceny, aby sprawdzić, jak dobrze działa model.
Sprawdzanie modelu
Krok Ocena na ekranie Konstruktor modelu umożliwia sprawdzenie metryk i algorytmów oceny wybranych dla najlepszego modelu. Pamiętaj, że wyniki różnią się od wyników wymienionych w tym module, ponieważ wybrany algorytm i hiperparametry mogą się różnić.
Testowanie modelu
W sekcji Wypróbuj model kroku Ocena możesz podać nowe dane i ocenić wyniki przewidywania.

Sekcja Przykładowe dane to miejsce, w którym podajesz dane wejściowe dla modelu w celu przewidywania. Każde pole odpowiada kolumnom używanym do trenowania modelu. Jest to wygodny sposób sprawdzania, czy model działa zgodnie z oczekiwaniami. Domyślnie narzędzie Model Builder wstępnie wypełnia przykładowe dane pierwszym wierszem z zestawu danych.
Przetestujmy model, aby sprawdzić, czy generuje oczekiwane wyniki.
W sekcji Przykładowe dane wprowadź następujące dane. Pochodzi on z wiersza w zestawie danych z identyfikatorem UID 161.
Kolumna Wartość Identyfikator produktu L47340 Typ L Temperatura powietrza 298.4 Temperatura procesu 308.2 Prędkość rotacji 1282 Obrócić 60.7 Zużycie narzędzi 216 Wybierz pozycję Przewidywanie.
Ocena wyników przewidywania
W sekcji Wyniki zostanie wyświetlone przewidywanie wykonane przez model oraz poziom zaufania do tego przewidywania.
Jeśli przyjrzysz się kolumnie Błąd komputera identyfikatora UID 161 w zestawie danych, zauważysz, że wartość to 1. Jest to taka sama jak przewidywana wartość z najwyższym zaufaniem w sekcji Wyniki .
Jeśli chcesz, możesz kontynuować wypróbowanie modelu z różnymi wartościami wejściowymi i oceniać przewidywania.
Gratulacje! Wytrenowaliśmy model w celu przewidywania awarii maszyny. W następnej lekcji dowiesz się więcej o użyciu modelu.