Ćwiczenie — oczyszczanie i przygotowywanie danych
Zanim będzie można przygotować zestaw danych, należy poznać jego zawartość i strukturę. W poprzednim laboratorium zaimportowaliśmy zestaw danych zawierający informacje o punktualnych przylotach dla dużej amerykańskiej linii lotniczej. Te dane obejmują 26 kolumn i tysiące wierszy, przy czym każdy wiersz reprezentuje jeden lot i zawiera informacje takie jak miejsce początkowe lotu, miejsce docelowe i zaplanowany czas odlotu. Dane załadowaliśmy do notesu programu Jupyter i użyliśmy prostego skryptu języka Python, aby utworzyć strukturę DataFrame biblioteki Pandas.
DataFrame to dwuwymiarowa struktura danych oznaczona etykietą. Kolumny w strukturze DataFrame mogą być różnego typu, podobnie jak kolumny w arkuszu kalkulacyjnym lub w tabeli bazy danych. Jest to najczęściej używany obiekt w bibliotece Pandas. W tym ćwiczeniu bardziej szczegółowo przyjrzymy się strukturze DataFrame i danym, które się w niej znajdują.
Przejdź z powrotem do notesu platformy Azure utworzonego w poprzedniej sekcji. Jeśli notes został zamknięty, możesz zalogować się z powrotem do portalu usługi Microsoft Azure Notebooks, otworzyć notes i użyć polecenia Cell ->Run All , aby ponownie uruchomić wszystkie komórki w notesie po jego otwarciu.
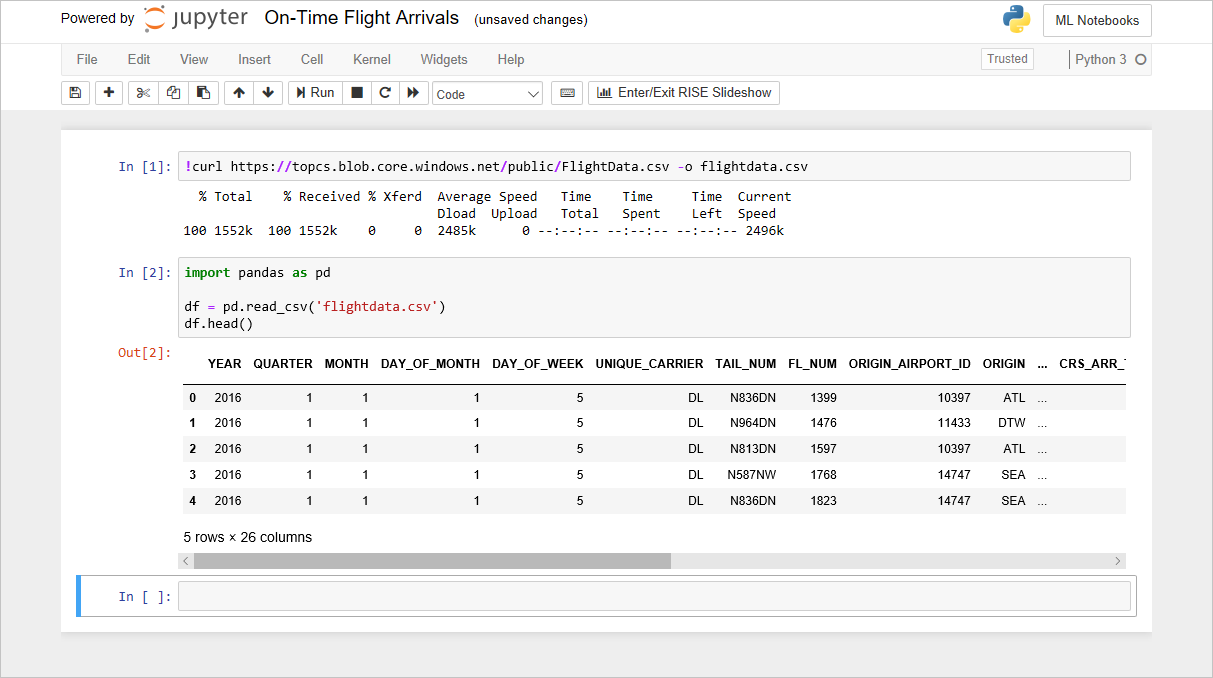
Notes FlightData
Kod, który został dodany do notesu w poprzednim laboratorium, tworzy obiekt DataFrame z pliku flightdata.csv i wywołuje dla niego funkcję DataFrame.head w celu wyświetlenia pierwszych pięciu wierszy. Jedną z pierwszych rzeczy, które zazwyczaj chcemy wiedzieć o zestawie danych, to liczba zawartych w nim wierszy. Aby uzyskać tę liczbę, wpisz następującą instrukcję w pustej komórce na końcu notesu i uruchom go:
df.shapeUpewnij się, że obiekt DataFrame zawiera 11 231 wierszy i 26 kolumn:

Uzyskiwanie liczby wierszy i kolumn
Teraz poświęć chwilę, aby zbadać 26 kolumn w zestawie danych. Zawierają one ważne informacje, takie jak data lotu (YEAR, MONTH i DAY_OF_MONTH), miejsce początkowe i docelowe (ORIGIN i DEST), zaplanowane godziny odlotu i przylotu (CRS_DEP_TIME i CRS_ARR_TIME), różnica między zaplanowaną godziną przylotu i rzeczywistą godziną przylotu w minutach (ARR_DELAY) i czy lot był opóźniony o mniej, czy więcej niż 15 minut (ARR_DEL15).
Oto pełna lista kolumn w tym zestawie danych. Godziny zostały podane w formacie 24-godzinnego czasu wojskowego. Na przykład wartość 1130 jest równa 11:30 i 1500 jest równa 15:00.
Kolumna opis YEAR Rok, w którym odbył się lot QUARTER Kwartał, w którym odbył się lot (1-4) MONTH Miesiąc, w którym odbył się lot (1-12) DAY_OF_MONTH Dzień miesiąca, w którym odbył się lot (1-31) DAY_OF_WEEK Dzień tygodnia, w którym odbył się lot (1 = poniedziałek, 2 = wtorek itd.) UNIQUE_CARRIER Kod linii lotniczych (np. DL) TAIL_NUM Numer na ogonie samolotu FL_NUM Numer lotu ORIGIN_AIRPORT_ID Identyfikator lotniska początkowego ORIGIN Kod lotniska początkowego (ATL, DFW, SEA itd.) DEST_AIRPORT_ID Identyfikator lotniska docelowego DEST Kod lotniska docelowego (ATL, DFW, SEA itd.) CRS_DEP_TIME Zaplanowany czas odlotu DEP_TIME Rzeczywisty czas odlotu DEP_DELAY Liczba minut opóźnienia odlotu DEP_DEL15 0 = odlot opóźniony o mniej niż 15 minut, 1 = odlot opóźniony o 15 minut lub więcej CRS_ARR_TIME Zaplanowany czas przylotu ARR_TIME Rzeczywisty czas przylotu ARR_DELAY Liczba minut opóźnienia przylotu ARR_DEL15 0 = przylot opóźniony o mniej niż 15 minut, 1 = przylot opóźniony o 15 minut lub więcej CANCELLED 0 = lot nie został anulowany, 1 = lot został anulowany DIVERTED 0 = lot nie został przekierowany, 1 = lot został przekierowany CRS_ELAPSED_TIME Zaplanowany czas lotu w minutach ACTUAL_ELAPSED_TIME Rzeczywisty czas lotu w minutach DISTANCE Odległość podróży w milach
Zestaw danych zawiera w przybliżeniu równomierny rozkład dat z całego roku, co jest ważne, ponieważ prawdopodobieństwo opóźnienia lotu z Minneapolis z powodu burzy śnieżnej jest mniejsze w lipcu, niż w styczniu. Jednak ten zestaw danych nie jest jeszcze „czysty” i gotowy do użycia. Napiszmy nieco kodu Pandas, aby go oczyścić.
Jednym z najważniejszych aspektów przygotowywania zestawu danych do użycia w uczeniu maszynowym jest wybór kolumn „cech”, które są istotne z punktu widzenia danych wyjściowych, które próbujesz przewidzieć, oraz odfiltrowanie kolumn, które nie mają wpływu na wyniki, mogą je odchylić w negatywny sposób lub mogą wygenerować współliniowość. Innym ważnym zadaniem jest wyeliminowanie brakujących wartości przez usunięcie wierszy lub kolumn, które je zawierają, lub przez zastąpienie ich znaczącymi wartościami. W tym ćwiczeniu wyeliminujesz nieistotne kolumny i zastąpisz brakujące wartości w pozostałych kolumnach.
Jedną z pierwszych rzeczy, której zazwyczaj szukają analitycy danych w zestawie danych, są brakujące wartości. Istnieje łatwy sposób sprawdzania brakujących wartości w bibliotece Pandas. Aby go zademonstrować, wykonaj następujący kod w komórce na końcu notesu:
df.isnull().values.any()Upewnij się, że wynik to „True”, co oznacza, że w zestawie danych istnieje co najmniej jedna brakująca wartość.

Wyszukiwanie brakujących wartości
W następnym kroku należy dowiedzieć się, gdzie znajdują się te brakujące wartości. W tym celu wykonaj następujący kod:
df.isnull().sum()Upewnij się, że widzisz następujące dane wyjściowe, będące listą zawierającą liczbę brakujących wartości w każdej kolumnie:
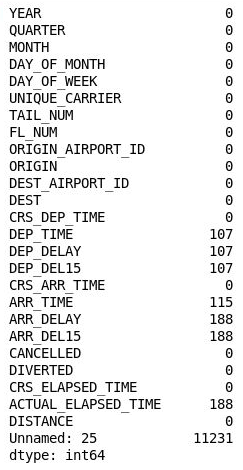
Liczba brakujących wartości w każdej kolumnie
Co ciekawe, 26 kolumna ("Unnamed: 25") zawiera 11 231 brakujących wartości, co odpowiada liczbie wierszy w zestawie danych. Ta kolumna została utworzona przez pomyłkę, ponieważ zaimportowany plik CSV zawiera przecinek na końcu każdego wiersza. Aby wyeliminować tę kolumnę, dodaj do notesu następujący kod i wykonaj go:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Sprawdź dane wyjściowe i upewnij się, że kolumna 26 zniknęła z obiektu DataFrame:
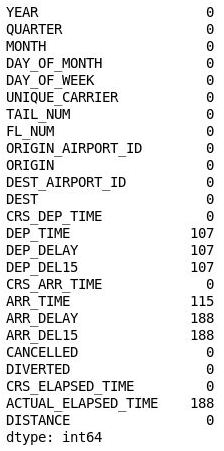
Obiekt DataFrame z usuniętą kolumną 26
Obiekt DataFrame nadal zawiera wiele brakujących wartości, jednak niektóre z nich nie są przydatne, ponieważ zawierające je kolumny nie są istotne dla modelu, który tworzysz. Celem tego modelu jest przewidzenie, czy lot, którego rezerwację rozważasz, dotrze na miejsce o czasie. Jeśli okaże się, że lot prawdopodobnie będzie opóźniony, możesz zechcieć zarezerwować inny lot.
Z tego względu w następnym kroku należy przefiltrować zestaw danych, aby wyeliminować kolumny, które nie są istotne dla modelu predykcyjnego. Na przykład numer na ogonie samolotu prawdopodobnie ma mały wpływ na to, czy przylot będzie na czas, a w momencie rezerwacji biletu nie ma możliwości określenia, czy lot będzie anulowany, przekierowany czy opóźniony. Z kolei zaplanowany czas odlotu może mieć duży wpływ na terminowość przylotów. Ze względu na system piasta-szprychy (hub-and-spoke), który jest używany przez większość linii lotniczych, poranne loty są zazwyczaj bardziej punktualne, niż popołudniowe czy wieczorne. Ponadto na większych lotniskach ruch kumuluje się w ciągu dnia, co zwiększa prawdopodobieństwo, że późniejsze loty będą opóźnione.
Biblioteka Pandas zapewnia prosty sposób na odfiltrowanie kolumn, których nie chcesz używać. Wykonaj następujący kod w nowej komórce na końcu notesu:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()Dane wyjściowe pokazują, że teraz obiekt DataFrame zawiera tylko kolumny, które mają znaczenie dla modelu, oraz że liczba brakujących wartości znacznie spadła:
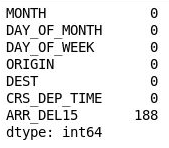
Przefiltrowany obiekt DataFrame
Jedyną kolumną, która zawiera teraz brakujące wartości, jest kolumna ARR_DEL15, w której za pomocą cyfry 0 oznaczono przyloty punktualne, a za pomocą cyfry 1 — przyloty opóźnione. Użyj poniższego kodu, aby wyświetlić pięć pierwszych wierszy z brakującymi wartościami:
df[df.isnull().values.any(axis=1)].head()Biblioteka Pandas przedstawia brakujące wartości przy użyciu skrótu
NaN, który oznacza Not a Number (Nie jest liczbą). Dane wyjściowe pokazują, że w tych wierszach faktycznie brakuje wartości w kolumnie ARR_DEL15: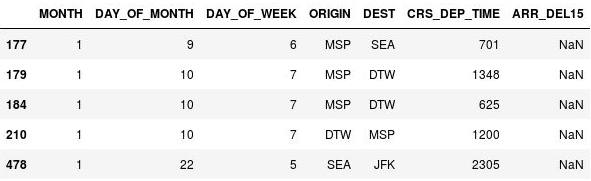
Wiersze z brakującymi wartościami
Powodem, dla którego w tych wierszach brakuje wartości w kolumnie ARR_DEL15, jest to, że odpowiadają one lotom anulowanym lub przekierowanym. Aby usunąć te wiersze, można wywołać metodę dropna na obiekcie DataFrame. Jednak ze względu na to, że lot anulowany bądź przekierowany można uznać za „opóźniony”, użyjemy metody fillna, aby zastąpić brakujące wartości cyfrą 1.
Użyj poniższego kodu, aby zastąpić brakujące wartości w kolumnie ARR_DEL15 cyfrą 1 i wyświetlić wiersze od 177 do 184:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Upewnij się, że wartości
NaNw wierszach 177, 179 i 184 zostały zastąpione cyfrą 1 wskazującą, że przylot był opóźniony: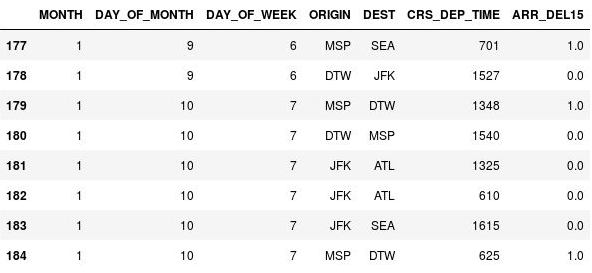
Wartości NaN zastąpione cyfrą 1
Zestaw danych jest teraz „czysty”, co oznacza, że brakujące wartości zostały zastąpione, a lista kolumn została zawężona do tych, które są najbardziej istotne z perspektywy modelu. Jednak to jeszcze nie koniec. Aby zestaw danych był gotowy do użycia w uczeniu maszynowym, trzeba wykonać jeszcze kilka czynności.
Kolumna CRS_DEP_TIME zestawu danych, którego używasz, reprezentuje zaplanowany czas odlotu. Poziom szczegółowości liczb znajdujących się w tej kolumnie — zawiera ona ponad 500 unikatowych wartości — może mieć negatywny wpływ na dokładność modelu uczenia maszynowego. Ten problem można rozwiązać za pomocą techniki o nazwie kwantowanie lub kwantyzacja. Co by się stało, gdybyśmy podzielili każdą liczbę w tej kolumnie przez 100 i zaokrąglili wynik do najbliższej liczby całkowitej? Wartość 1030 stałaby się liczbą 10, wartość 1925 stałaby się liczbą 19 i tak dalej — w tej kolumnie pozostałoby maksymalnie 24 odrębnych wartości. Intuicyjnie ma sens, ponieważ prawdopodobnie nie ma znaczenia, czy lot opuszcza o godzinie 10:30, czy o godzinie 10:40. To ma duże znaczenie, czy odchodzi o godzinie 10:30, czy o godzinie 15:30.
Ponadto kolumny ORIGIN i DEST zestawu danych zawierają kody lotnisk, które reprezentują wartości uczenia maszynowego podzielone na kategorie. Te kolumny muszą zostać przekonwertowane na osobne kolumny zawierające zmienne wskaźnika, czasami nazywane zmiennymi „fikcyjnymi” (ang. dummy). Innymi słowy, kolumnę ORIGIN, która zawiera pięć kodów lotnisk, należy przekonwertować na pięć kolumn — po jednej dla każdego lotniska — przy czym każda kolumna będzie zawierać wartości 1 i 0 wskazujące, czy lot rozpoczął się na lotnisku, który reprezentuje dana kolumna. Z kolumną DEST należy postąpić w podobny sposób.
W tym ćwiczeniu „skwantujesz” godziny odlotów w kolumnie CRS_DEP_TIME i użyjesz metody get_dummies biblioteki Pandas, aby utworzyć kolumny wskaźników z kolumn ORIGIN i DEST.
Użyj następującego polecenia, aby wyświetlić pięć pierwszych wierszy obiektu DataFrame:
df.head()Zauważ, że kolumna CRS_DEP_TIME zawiera wartości z zakresu od 0 do 2359, które reprezentują godziny w formacie czasu wojskowego.
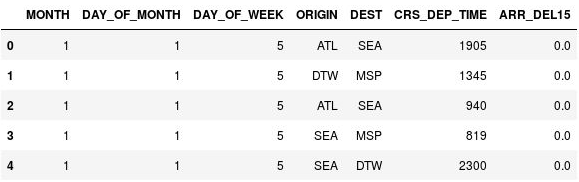
Obiekt DataFrame z nieskwantowanymi godzinami odlotów
Użyj poniższych instrukcji, aby skwantować godziny odlotów:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Upewnij się, że liczby w kolumnie CRS_DEP_TIME należą teraz do zakresu od 0 do 23:
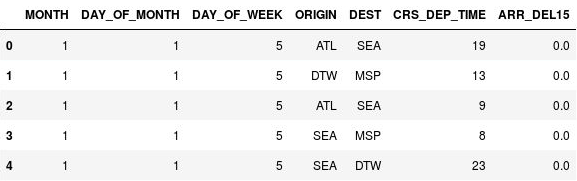
Obiekt DataFrame ze skwantowanymi godzinami odlotów
Teraz użyj poniższych instrukcji, aby wygenerować kolumny wskaźników z kolumn ORIGIN i DEST, porzucając jednocześnie same kolumny ORIGIN i DEST:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Przyjrzyj się wynikowemu obiektowi DataFrame i zauważ, że kolumny ORIGIN i DEST zostały zastąpione kolumnami odpowiadającymi kodom lotnisk z oryginalnych kolumn. Nowe kolumny zawierają wartości 1 i 0 wskazujące, czy dany lot rozpoczął się lub zakończył na danym lotnisku.
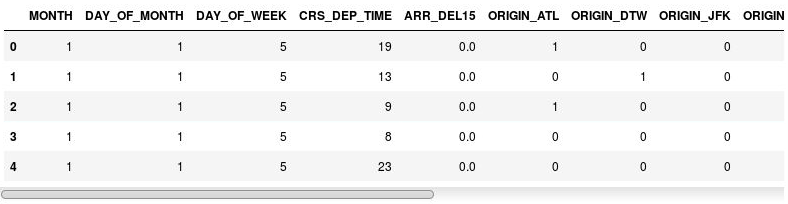
Obiekt DataFrame z kolumnami wskaźników
Użyj polecenia File ->Save and Checkpoint, aby zapisać notes.
Zestaw danych wygląda teraz zupełnie inaczej, niż na początku, ale jest zoptymalizowany pod kątem użycia w procesie uczenia maszynowego.