Integrowanie zapytań LLAP platformy Apache Spark i programu Hive
W poprzedniej lekcji przyjrzeliśmy się dwóm sposobom wykonywania zapytań dotyczących danych statycznych przechowywanych w klastrze interaktywnych zapytań — Data Analytics Studio i notesie Zeppelin. Ale co zrobić, jeśli chcesz przesyłać strumieniowo świeże dane nieruchomości do klastrów przy użyciu platformy Spark, a następnie wysyłać do nich zapytania przy użyciu programu Hive? Ponieważ usługi Hive i Spark mają dwa różne magazyny metadanych, wymagają łącznika do mostka między nimi — a łącznikiem magazynu Apache Hive (HWC) jest ten most. Biblioteka łącznika magazynu Hive umożliwia łatwiejsze pracę z platformami Apache Spark i Apache Hive dzięki obsłudze zadań, takich jak przenoszenie danych między ramkami danych platformy Spark i tabelami Hive, a także kierowanie danych przesyłanych strumieniowo platformy Spark do tabel programu Hive. Nie skonfigurujemy łącznika w naszym scenariuszu, ale ważne jest, aby wiedzieć, że opcja istnieje.
Platforma Apache Spark ma interfejs API przesyłania strumieniowego ze strukturą, który zapewnia możliwości przesyłania strumieniowego niedostępne w usłudze Apache Hive. Począwszy od usługi HDInsight 4.0, platformy Apache Spark 2.3.1 i Apache Hive 3.1.0 mają oddzielne magazyny metadanych, co utrudniało współdziałanie. Łącznik magazynu Hive ułatwia jednoczesne używanie platformy Spark i programu Hive. Biblioteka łącznika magazynu Hive ładuje dane z demonów LLAP do funkcji wykonawczych platformy Spark równolegle, dzięki czemu jest ona wydajniejsza i skalowalna niż użycie standardowego połączenia JDBC z platformy Spark do programu Hive.
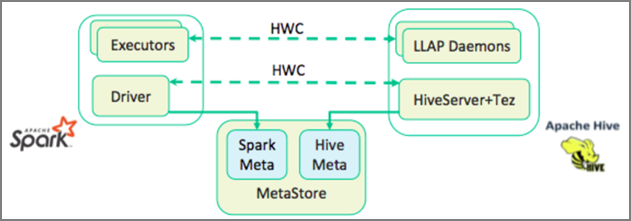
Niektóre operacje obsługiwane przez łącznik magazynu Hive to:
- Opisywanie tabeli
- Tworzenie tabeli dla zoptymalizowanych danych kolumnowych wierszy (ORC) sformatowanych
- Wybieranie danych programu Hive i pobieranie ramki danych
- Zapisywanie ramki danych w usłudze Hive w partii
- Wykonywanie instrukcji aktualizacji programu Hive
- Odczytywanie danych tabeli z programu Hive, przekształcanie ich na platformie Spark i zapisywanie ich w nowej tabeli Programu Hive
- Zapisywanie ramki danych lub strumienia Spark w usłudze Hive przy użyciu technologii HiveStreaming
Po wdrożeniu klastra Spark i klastra zapytań interakcyjnych skonfigurujesz ustawienia klastra Spark w narzędziu Ambari, które jest narzędziem internetowym uwzględnionym we wszystkich klastrach usługi HDInsight. Aby otworzyć aplikację Ambari, przejdź do https:// servername.azurehdinsight.net w przeglądarce internetowej, w której nazwa _serwera to nazwa klastra interakcyjnego zapytań.
Następnie, aby zapisać dane przesyłane strumieniowo platformy Spark do tabel, należy utworzyć tabelę programu Hive i rozpocząć zapisywanie w niej danych. Następnie uruchom zapytania dotyczące danych przesyłanych strumieniowo, możesz użyć dowolnego z następujących elementów:
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy