Interakcyjne zapytania usługi HDInsight
Zapytania interakcyjne są zwykle implementowane w scenariuszu ścieżki zimnej, w którym masz dane w formacie tabelarycznym i chcesz szybko zadawać pytania i uzyskiwać interaktywną odpowiedź przy użyciu składni JĘZYKA SQL. Na poniższym diagramie przedstawiono architekturę rozwiązania dla wszystkich rozwiązań ścieżki zimnej i ścieżki gorącej usługi HDInsight oraz przedstawiono sposób obsługi interakcyjnych zapytań za pośrednictwem protokołu LLAP hive w warstwie obsługującej. Dane mogą być pozyskiwane za pośrednictwem programu Hive, zapytania interakcyjne są przetwarzane za pośrednictwem programu Hive LLAP, a umieszczenie danych wyjściowych może być obsługiwane dla aplikacji podrzędnych, takich jak power BI.
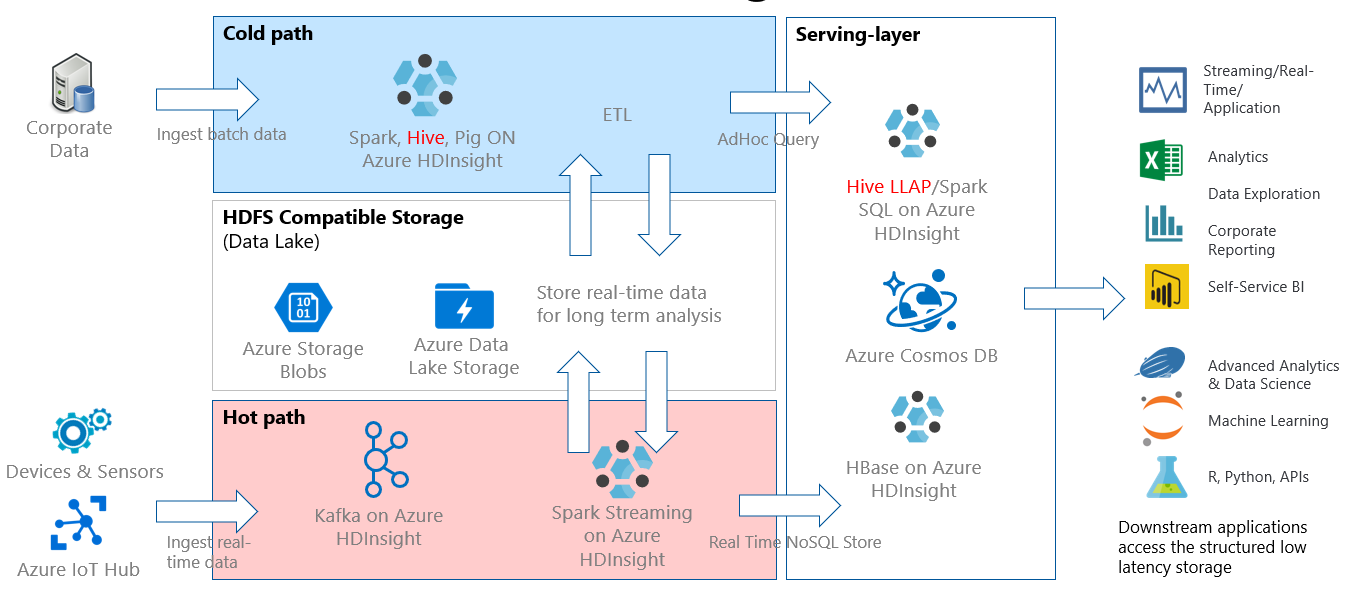
Architektura interakcyjnego zapytania
Teraz przyjrzyjmy się architekturze Zapytania interakcyjnego.
Użytkownicy zapytań interakcyjnych mogą wybierać spośród różnych klientów ODBC lub JDBC do uruchamiania zapytań względem danych biznesowych, takich jak Data Analytics Studio, Zeppelin Notebooks i Visual Studio Code. Po przesłaniu zapytania HiveQL przez klienta zapytanie dociera do serwera HiveServer, który jest odpowiedzialny za planowanie zapytań, optymalizację, a także przycinanie zabezpieczeń. Program Hive działa przez podzielenie zadań analitycznych między rozproszone węzły w klastrze. Zapytania są podzielone na podzadania i wysyłane do węzłów, które przetwarzają poszczególne podzadania, a te podzadania są podzielone jeszcze bardziej, a każde z tych zadań odczytuje dane z bazowej warstwy magazynu danych biznesowych. Architektura jest zoptymalizowana ze względu na użycie demonów LLAP "zawsze włączone", które unikają czasów uruchamiania, a także udostępnionej pamięci podręcznej w pamięci, która przechowuje dane pobrane z magazynu i udostępnia dane we wszystkich węzłach.
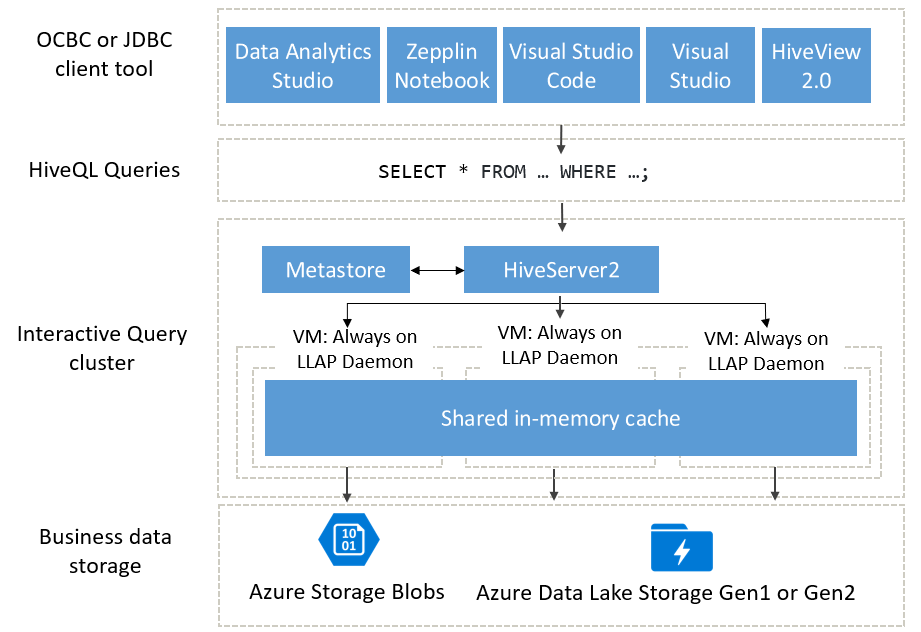
Dyski półprzewodnikowe (SSD) używane przez klastry Interactive Query łączą zarówno pamięć RAM, jak i SSD w gigantyczną pulę pamięci, która jest używana przez pamięć podręczną. Dzięki tej kombinacji zasobów typowy profil serwera może buforować 4 razy więcej danych, umożliwiając przetwarzanie większych zestawów danych i obsługę większej liczby użytkowników. Pamięć podręczna interakcyjnych zapytań uwzględnia zmiany danych bazowych w magazynie zdalnym (Azure Storage), więc jeśli bazowe dane zmienią się i użytkownik wyśle zapytanie, zaktualizowane dane zostaną załadowane w pamięci bez konieczności wykonywania dodatkowych kroków użytkownika.