Kiedy należy używać zapytania interakcyjnego usługi HDInsight?
Jako analityk biznesowy musisz określić najbardziej odpowiedni rodzaj klastra usługi HDInsight, który ma zostać utworzony w celu utworzenia rozwiązania. Klastry zapytań interakcyjnych udostępniają wiele funkcji i opcji współdziałania, które sprawiają, że unikatowo korzystne dla analityków biznesowych zaznajomionych z językiem SQL. Doskonale sprawdza się w przypadku użytkowników, którzy chcą pracować z narzędziami do analizy biznesowej i wymagają szybkich interakcyjnych zapytań. Istnieją inne korzyści, takie jak obsługa różnych formatów plików, współbieżności i niepodzielnych, spójnych, izolowanych i trwałych (ACID). Nie wspominając już o integracji z platformą Apache Ranger w celu uzyskania szczegółowej kontroli na poziomie wiersza i kolumny nad danymi.
Uwaga
Zawartość tego modułu dotyczy klastrów zapytań interakcyjnych utworzonych dla usługi HDInsight 4.0, która używa programu Hive 3.1 i LLAP, znanego również jako Hive LLAP.
Masz duży zestaw danych, który jest gotowy do odpytowania
Klastry zapytań interakcyjnych najlepiej nadają się do obsługi dużych zestawów danych, które można wykonywać zapytania zgodnie z rzeczywistym użyciem lub przy minimalnych przekształceniach. Sytuacje, w których będziesz wykonywać różne zapytania dotyczące danych i potrzebujesz natychmiastowych odpowiedzi. Klastry zapytań interakcyjnych nie są zoptymalizowane pod kątem wykonywania długotrwałych obliczeń wsadowych. Zapytanie interakcyjne obsługuje następujące formaty plików: ORC, Parquet, CSV, Avro, JSON, text i tsv.
Wymagana jest funkcja przypominająca język SQL
Jeśli musisz wykonać interakcyjne i ad hoc zapytania dotyczące opóźnienia podrzędnego dla danych big data, które znajdują się w usłudze Azure Storage i Usłudze Azure Data Lake Storage, a wolisz środowisko podobne do języka SQL, klastry zapytań interakcyjnych w usłudze Azure HDInsight są doskonałym wyborem. Jako analityk biznesowy doskonale znasz tabele SQL i tworzysz zapytania przy użyciu języka SQL. Apache Hadoop to zaawansowane narzędzie do przeprowadzania analizy danych big data. Korzystanie z platformy MapReduce i jej interfejsów API języka Java w usłudze Apache Hadoop może być dla Ciebie blokowane, jeśli umiejętności programistyczne w języku Java są trochę zardzewiałe. W takim przypadku zapytanie interakcyjne w usłudze HDInsight jest lepiej dopasowane, ponieważ jest oparte na usłudze Apache Hadoop, ale jest prostsze dla każdego, kto ma doświadczenie w korzystaniu z języka SQL. Zapytanie interakcyjne używa tabel Hive przypominających sql do przetwarzania danych i języka zapytań przypominającego sql o nazwie HiveQL w celu wykonywania zapytań dotyczących danych. Korzystanie z technologii Hive jest mniej złożone niż przetwarzanie danych przy użyciu technologii MapReduce w usłudze Apache Hadoop. Usługa Hive przyspiesza i wydajniejsze wdrażanie rozwiązań w firmie.
Szybkie interakcyjne zapytania z inteligentnym buforowaniem
Klastry zapytań interakcyjnych używają inteligentnych technik buforowania w celu warstwowania danych w dynamicznej pamięci RAM, lokalnych węzłów klastra SSD i zdalnych systemów magazynowania, takich jak Azure Blob i Azure Data Lake Storage, w celu uzyskania interaktywnych i szybkich wyników zapytań dotyczących danych big data. Dobrym przykładem zaawansowanej techniki buforowania jest dynamiczna pamięć podręczna tekstu, która konwertuje dane CSV na zoptymalizowany format w pamięci na bieżąco, więc buforowanie jest dynamiczne, a zapytania określają, jakie dane są buforowane. Ta funkcja oznacza, że nie trzeba najpierw ładować i przekształcać danych. Dane można przekazać do usługi Azure Storage w oryginalnym formacie i rozpocząć wykonywanie względem niego zapytań. Oznacza to również, że zapytania są bardziej wydajne przy drugim uruchomieniu. Po pierwszym wykonaniu zapytania dane są odczytywane z warstwy magazynu danych biznesowych w usłudze Azure Storage lub Azure Data Lake Gen2. Następnie dane są buforowane do udostępnionej pamięci podręcznej w pamięci w klastrze. Następnym razem, gdy zapytanie zostanie uruchomione, dane są po prostu pobierane z udostępnionej pamięci podręcznej w pamięci i oszczędzasz czas, nie pobierając danych z warstwy magazynu zdalnego.
Uruchamianie zapytań przy użyciu popularnych narzędzi
Zapytanie interakcyjne ułatwia pracę z danymi big data przy użyciu narzędzi analizy biznesowej, które znasz, takich jak Microsoft Power BI i Tableau. W analizie danych big data organizacje coraz bardziej obawiają się, że ich użytkownicy końcowi nie otrzymują wystarczającej wartości z systemów analitycznych, ponieważ często jest to zbyt trudne i wymaga używania nieznanych i trudnych narzędzi do uczenia się w celu uruchomienia analizy. Interakcyjne zapytanie usługi HDInsight rozwiązuje ten problem, wymagając minimalnego, aby żadne nowe szkolenia użytkownika nie pobierały szczegółowych informacji z danych. Użytkownicy mogą pisać zapytania HiveQL podobne do JĘZYKA SQL w narzędziach, których już używają. Te narzędzia obejmują programy Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, Data Analytics Studio i Hive ODBC. Nie można wykonywać zapytań w klastrze Interactive Query przy użyciu konsoli Hive, Templeton, klasycznego interfejsu wiersza polecenia platformy Azure lub programu Azure PowerShell.
Wymagana jest spójność transakcji i współbieżność
Wraz z wprowadzeniem szczegółowego zarządzania zasobami, opróżnianie i udostępnianie danych buforowanych między zapytaniami i użytkownikami, interakcyjne zapytanie obsługuje równoczesnych użytkowników z łatwością. Usługa HDInsight obsługuje tworzenie wielu klastrów w udostępnionym magazynie platformy Azure. Magazyn metadanych Hive pomaga osiągnąć wysoki stopień współbieżności. Współbieżność można skalować, dodając więcej węzłów klastra lub dodając więcej klastrów wskazujących te same podstawowe dane i metadane. Zapytanie interakcyjne obsługuje również transakcje bazy danych, które są niepodzielne, spójne, izolowane i trwałe (ACID). Transakcje ACID gwarantują, że transakcja, nawet jeśli zawiera wiele operacji, jest zawarta w jednej jednostce. W związku z tym, jeśli jakakolwiek pojedyncza operacja w transakcji zakończy się niepowodzeniem, cała operacja może zostać wycofana, co zapewnia spójność i dokładność danych.
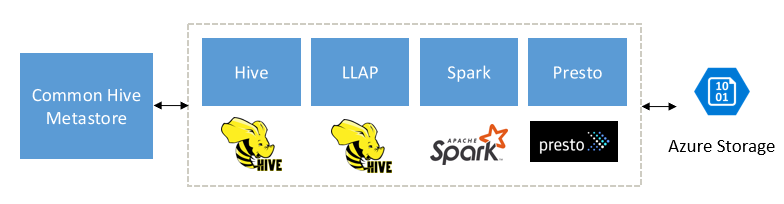
Opracowane w celu uzupełnienia aparatów Spark, Hive, Presto i innych aparatów danych big data
Zapytanie interakcyjne usługi HDInsight zaprojektowano tak, aby dobrze współdziałało z popularnymi aparatami danych big data, takimi jak Apache Spark, Hive, Presto i nie tylko. Ten typ zapytania jest szczególnie przydatny, ponieważ użytkownicy mogą wybrać dowolne z tych narzędzi do uruchamiania analizy. Dzięki architekturze udostępnionych danych i metadanych usługi HDInsight dla tabel zewnętrznych użytkownicy mogą tworzyć wiele klastrów z tym samym lub innym aparatem wskazującym te same dane bazowe i metadane. Ta funkcja jest zaawansowaną koncepcją, ponieważ nie jest już ograniczona przez jedną technologię do analizy.